bert
简介
BERT 是一个用 Transformers 作为特征抽取器的深度双向预训练语言理解模型。通过海量语料预训练,得到序列当前最全面的局部和全局特征表示。
bert 名称来自 Bidirectional Encoder Representations from Transformers. Unlike recent language representation models, BERT is designed to pre-train deep bidirectional(相对gpt的单向来说,是双向的) representations by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT representations can be fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial task-specific architecture modifications. PS:ELMo 是基于rnn,在应用到下游任务时,还需要做一些模型结构的变动。有了一个训练好的bert之后,只需要再加一个额外的层,就可以适配各种任务。
模型结构
BERT的基础集成单元是Transformer的Encoder,BERT与Transformer 的编码方式一样。将固定长度的字符串作为输入,数据由下而上传递计算,每一层都用到了self attention,并通过前馈神经网络传递其结果,将其交给下一个编码器。
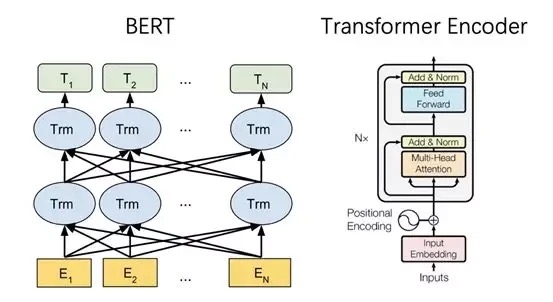
模型输入
输入的第一个字符为[CLS],在这里字符[CLS]表达的意思很简单 - Classification (分类)。
模型输出
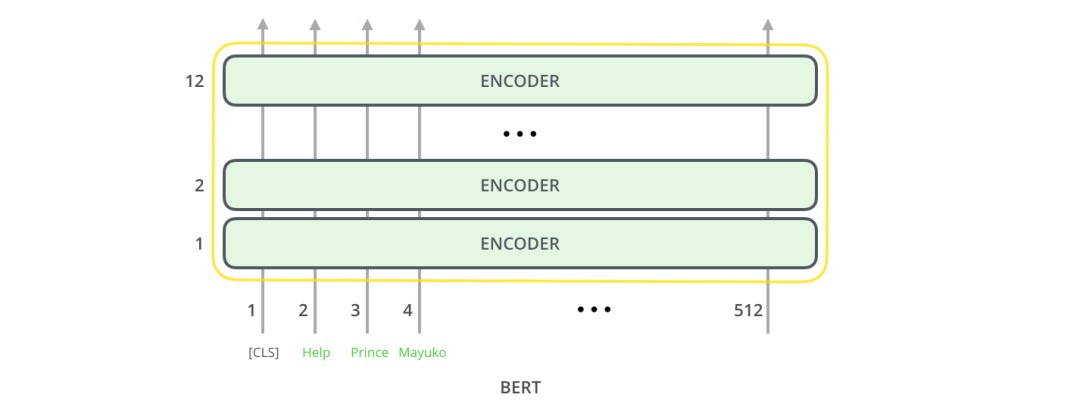
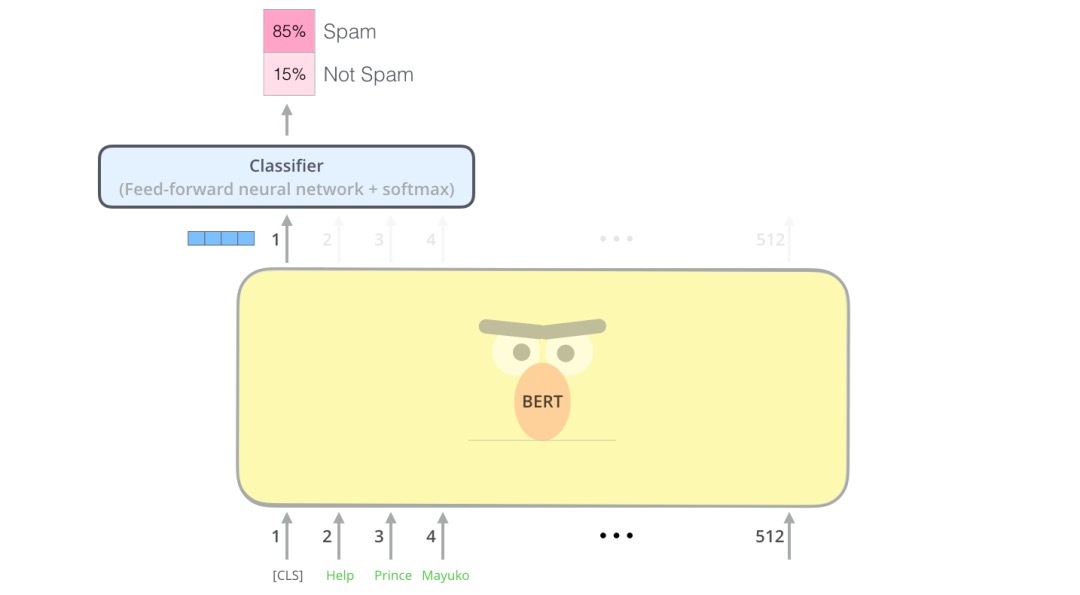
每个位置返回的输出都是一个隐藏层大小的向量(基本版本BERT为768)。以文本分类为例,我们重点关注第一个位置上的输出(第一个位置是分类标识[CLS]) bert 希望它最后的输出代表整个序列的信息。该向量现在可以用作我们选择的分类器的输入,在论文中指出使用单层神经网络作为分类器就可以取得很好的效果。例子中只有垃圾邮件和非垃圾邮件,如果你有更多的label,你只需要增加输出神经元的个数即可,另外把最后的激活函数换成softmax即可。
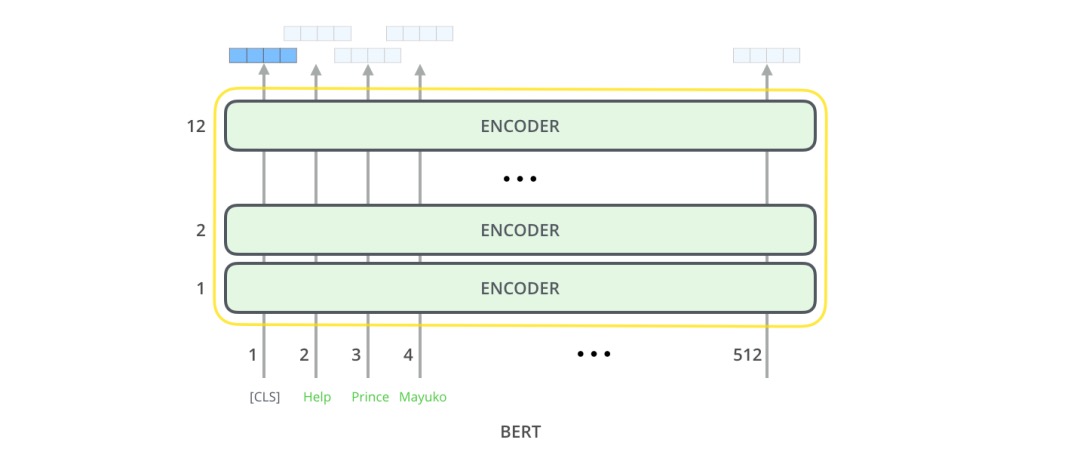
训练方式
一文读懂深度学习:从神经元到BERT相比语言模型任务只做预测下一个位置的单词,想要训练包含更多信息的语言模型,就需要让语言模型完成更复杂的任务,BERT 主要完成完形填空和句对预测的任务,即两个 loss:一个是 Masked Language Model,另一个是 Next Sentence Prediction。PS: gpt可以视为将训练目标改为用最后一个输出向量预测下一个单词的bert?
Masked Language Model
MLM是为了训练深度双向语言表示向量,BERT 用了一个非常直接的方式,遮住句子里某些单词,让编码器预测这个单词是什么。
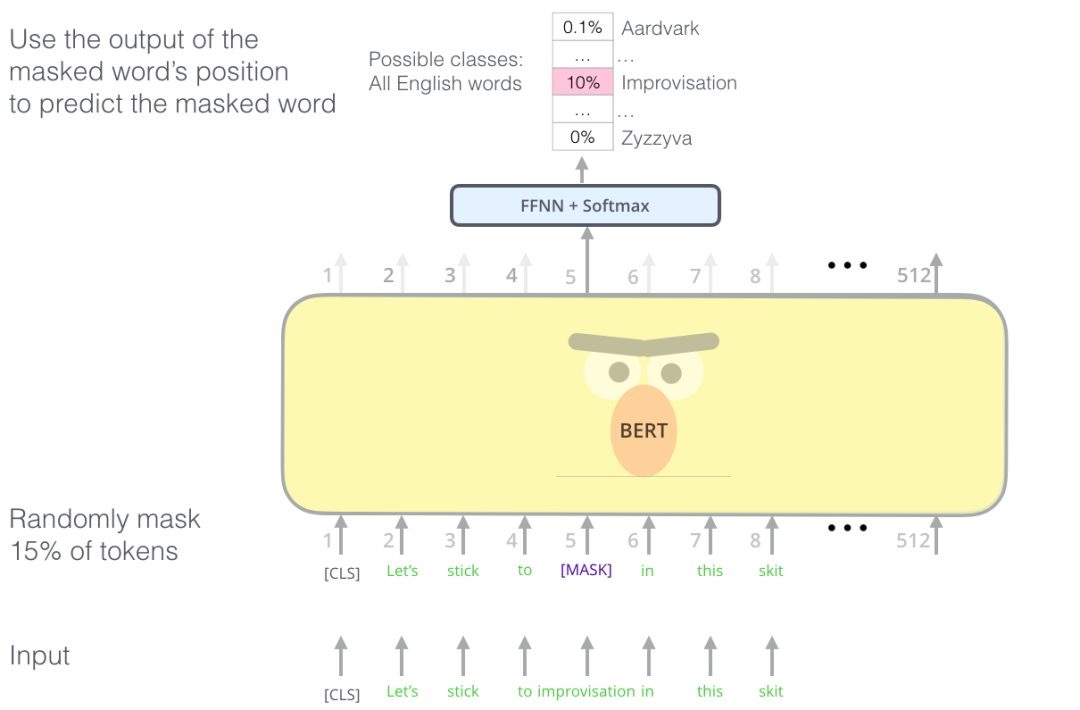
BERT 具体训练方法为:随机遮住 15%的单词作为训练样本。
- 其中 80%用 masked token 来代替。
- 10%用随机的一个词来替换。
- 10%保持这个词不变。
直观上来说,只有 15%的词被遮盖的原因是性能开销,双向编码器比单向编码器训练要慢;选 80% mask,20%具体单词的原因是在 pretrain 的时候做了 mask,在特定任务微调如分类任务的时候,并不对输入序列做 mask,会产生 gap,任务不一致;10%用随机的一个词来替换,10%保持这个词不变的原因是让编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个 token 的表示向量,做了一个折中。

PS:训练时,自己知道自己mask 了哪个词,所以也是无监督了。
Next Sentence Prediction
预训练一个二分类的模型,来学习句子之间的关系。预测下一个句子的方法对学习句子之间关系很有帮助。
训练方法:正样本和负样本比例是 1:1,50%的句子是正样本,即给定句子 A 和 B,B 是 A 的实际语境下一句;负样本:在语料库中随机选择的句子作为 B。通过两个特定的 token[CLS]和[SEP]来串接两个句子,该任务在[CLS]位置输出预测。

Fine-tune
BERT的论文为我们介绍了几种BERT可以处理的NLP任务:
- 短文本相似

- 文本分类
- QA机器人
- 语义标注
- 特征提取 ==> rag 里的emebedding。 比如说我们自己训练一个类似BERT的模型,通过周围的词来预测完形填空试卷,“____是法国的首都”,通过一个模型训练词的上下文联系性之后,形成特定的词向量表。
针对不同任务,BERT 采用不同部分的输出做预测,分类任务利用[CLS]位置的 embedding,NER 任务利用每个 token 的输出 embedding。PS:最后一层的输出 选用[cls] 对应的embedding 或多个emebedding 套个FFNN + softmax,二分类或多分类任务就都可以解决了。可以认为bert 对输入的文本做了一个编码。
与GPT
在参数量不大的早期,GPT和BERT分别代表了生成模型和理解模型,并且同样参数量级下,GPT的casual attention在理解任务上完全不敌BERT的full attention。但是随着参数和数据的Scaling Up,迎来了GPT-3时刻:生成和理解任务统一并远远超越了BERT。我觉得包括几点:
- GPT 自回归的设计(casual attention+next token prediction)能非常高效地利用预料中每一个 token,为 Transformer 提供训练梯度,BERT 的 “完形填空” 任务的预料利用效率可能只有不到 20%。
- GPT 的设计,适合高效地对接所有的文本语料,进行数据 Scaling Up,构建世界模型。
- 生成任务比理解更难,Scaling Limit 更高,并且通过 “生成” 带动了 “理解”,实现了生成和理解的统一和超越。
类比于人,“理解” 就是 “听和读”,“生成” 就是 “说和写”。费曼学习法被公认为世界上最高效的学习方法之一,它核心理念是 “如果你不能简单地把一个知识解释清楚,那就说明你还没有真正理解它。” 为了能讲清楚,它必须先理解清楚,这是人类的 “生成” 带动 “理解” 的例子。“生成是理解的最高级形式”。只有当模型建立了一个足够完善的世界模型,它才能在概率空间中坍缩出那个唯一正确的 Next Token。
在视觉领域,理解与生成长期依赖两套完全不同的体系:理解模型多以 ViT 及其自监督变体为主,生成模型则以 Diffusion 为核心,二者在网络结构与训练目标上都不统一。这与 NLP 形成鲜明对比——GPT 只凭一个简单的 Next Token Prediction 就同时逼出了理解与生成能力,并随着规模扩展出强通用智能。目前 CV 也在寻找“视觉版 NTP”:包括 Masked Image Modeling、自回归式视觉 token 生成、多模态统一建模,以及 Transformer 化的扩散模型等方向,都在尝试用一个通用框架同时解决理解与生成。但迄今仍没有出现一个像 NTP 那样优雅、高效、可大规模扩展的单一任务。
其它
WordPiece 分词会切词根, 切词根的目的是,很多词根是复用的,这样能减少此表大小(以3w 左右的词典,不然英文单词不只3w)
工市:zero-shot 是gpt明显区别于 bert的关键(gpt 预训练+prompt,bert 预训练+微调)因为 bert 的设计原因,适应下游具体任务是微调阶段获得的,不是通过预训练阶段,所以 bert 并没有再预训练阶段变大,甚至很多工作是想办法将预训练模型变小,获得一个又小又好的模型。而 gpt 在持续增大的过程中发现性能也在提升,更是在后来发现了大模型的专属Scaling Law,如摩尔定律一般指导大模型的演进。
留下评论