PouchContainer技术分享体会
简介
昨天参加了一趟PouchContainer GA 的分享,刷新了很多思维观念,趁热打铁记录一下。
PouchContainer 的亮点
- 更充分的隔离性,docker容器因为共享内核的缘故,类似
/proc及其依赖的相关的组件无法 正常使用 - 守护进程,一则为了一些依赖系统服务的组件可以正常使用;再则,使得容器 更像一点虚拟机
-
容器与虚拟机混合部署。
- 以前认为的混合部署是 vm 搞vm、container 搞container,彼此互通就行了,且实施方式是由vm 环境 兼容容器。
- PouchContainer 先支持container 后支持runv, 是从容器环境 兼容vm。PouchContainer 兼容vm 的一个重大区别是 都支持镜像发布,这样的混合发布才更有意义。
补充:Pouch 可能借鉴了kata的一些实现。Kata containers跟RunC类似,也是一个符合OCI运行时规范的一种 实现,不同之处是, kata containers整合了Intel的 Clear Containers 和 Hyper.sh 的 runV,给每个容器增加了一个独立的linux内核(不共享宿主机的内核),使容器有更好 的隔离性,安全性。
关于docker的使用
第一个新知道:远程镜像,镜像分发的一个重要问题是大镜像分发比较耗时,解决起来有几个办法
- 缩减镜像,比如提高复用率、压缩镜像等
- 提高速度,比如p2p分发
- 干脆不移动镜像,
docker run的时候直接读取远程镜像,就像在本地一样。
再一个很好奇的事情,mysql、es、hadoop 都docker 化,为什么要将这些服务docker化?
- 分享者多来自云计算或 系统部门,支持很多的业务线,有一键交付一个hadoop 集群的需求
- 业务集群和数据集群混合调度,提高资源利用率(这是个长远目标,都还在实践中)
- mysql 服务可以拆分为三个部分:对外接口;计算服务;存储。三个部分独立后,计算服务可以自由升级,对外接口可以保持不变,存储部分使用CSI。没有体验过msyql 宕机(集群太小) 或者复杂的业务(需要各种版本的mysql)的我,对这个需求挺难理解的。
- hadoop/es 等很多大公司都有自己的维护小组,小公司hadoop 集群一般不怎么变,自然无法理解 一个月一个小迭代升级的运维需求。
P2P下载镜像,一个文件假设100m,按4m一块切分,客户端按块下载。局域网多个主机不一定都需要从第0块开始下载,假设4台主机在一个局域网内,分别下载25块,然后局域网内互传就行,比大家彼此都从第0块下载到100 要快很多。
容器生态
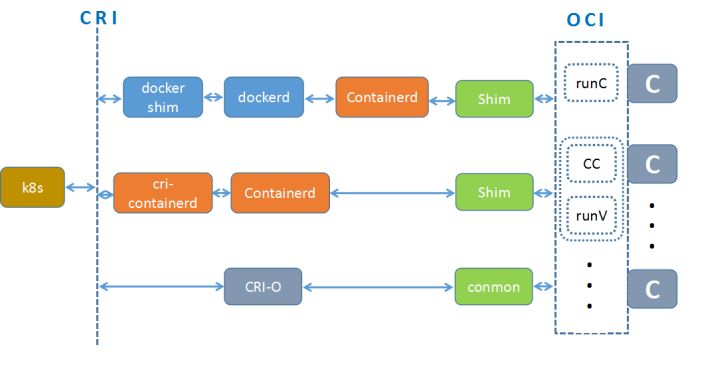
OCI(Open Container Initiative) 致力于建立一个容器运行时和镜像格式的规范,其核心目的在于避免容器生态的分化,确保在不同容器引擎上构建的容器可以相互兼容,runc 是其一个参考实现。包括:runtime spec 和 image spec
容器引擎,或者说容器平台,不仅包含对于容器的生命周期的管理,还包括了对于容器生态的管理,比如docker images、docker volumes、 docker network 等指令。
此处提一下, 容器运行时在不同的角度指向不同,很多地方也都有混用。比如对k8s来说,docker算是container runtime,对docker来说,runc是 container runtime ,不用纠结这些称呼。
为隔离各个容器引擎(比如docker、rkt等)之间的差异,通过统一的接口与各个容器引擎之间进行互动。kubernetes推出 CRI(container runtime interface)。与oci不同,cri不仅定义了容器的生命周期的管理,还引入了k8s中pod的概念,并定义了管理pod的生命周期。cri与kubernetes的概念更加贴合,紧密绑定。
为了进一步与oci进行兼容,kubernetes还孵化了cri-o,成为了架设在cri和oci之间的一座桥梁。看来kubernetes是想直接 抛开docker、rkt 等容器引擎。
paas/cloud native
在与一位大牛的讨论中,笔者听到,k8s 集群管理的服务 基本不访问本地磁盘,此时的存储不再是物理机的存储,而是一个“超级计算机”的存储。程序(对应镜像 + yml)、进程、存储、网络在“超级计算机” 的范畴里都变了形态。
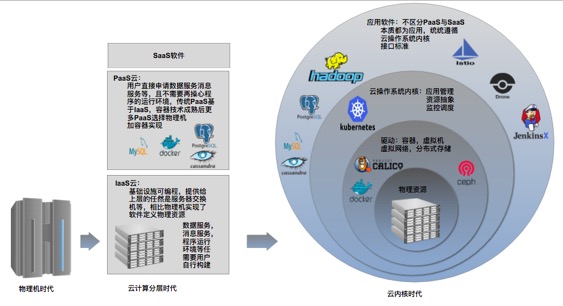
PaaS/cloud native 之后,我们向用户交付的,不再是一个个物理机,而是直接的运行一个服务的能力,就好像物理机提供进程的运行能力一样。服务运行时包含:对外接口;计算;存储,三者独立变化和升级、调度、移动,互不干扰。物理机 从小型机 到大型机, 单机的能力达到瓶颈之后,人们开始采用集群方式来提高能力,最终将集群又抽象为了一个超级计算机。
以前只有一个模糊的感觉,通过这次分享,笔者感受到在内部实践上,一直面临着传统运维和paas/cloud native 的博弈
- 笔者的公司基本就两种服务,web服务(前面接nginx)和微服务(前面接服务注册中心)。服务发现、负载均衡等事情有微服务框架去做。所以笔者在16年调研调度框架时,觉得k8s的pod、service 等概念基本用不上,进而选择了marathon + mesos。很多概念很超前,cloud native 还没推动,service mesh 就来了, 但公司层面的实践演变却很慢(与公司的发展阶段相适应就好)。
- 人员的接受成本,运维、开发还是物理机时代,光一个项目重新部署后服务ip 会改变就引起了很多同事的不理解。不适应他们就推不动,适应了他们就不符合新理念,很多问题也不只是技术问题。
需求驱动
为什么要用docker? 笔者曾依次想了几个理由
- 项目发布,因为公司全是java 项目,因此已有的发布系统基本够用,docker 的优势体现不出来
- 自动扩容缩容,这类业务(比如音视频编解码)可以直接使用云服务。
- 提高资源利用率,快速发展的公司,资源按峰值压力分配就可以了,业务发展会很快跟上来。
docker 为什么要这么用?这么改?
- 比如因为我司都是java项目,没考虑过一些项目依赖基础组件,自然对富容器的好处只有模糊而没有深刻的体会。
因此,一切还是跟需求有关系,有时候推动实践,不如推动需求。
留下评论