提高gpu 利用率
简介
在GPU卡越来越贵情景下,如何实现AI任务的调度对GPU等异构资源充分利用,实现GPU利用趋于饱和,尽可能减少idle的GPU core,实现效益最大化是至关重要的。
等数据
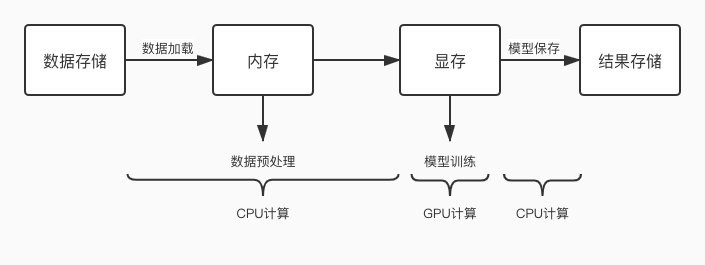
GPU 任务会交替的使用 CPU 和 GPU 进行计算,当 CPU 计算成为瓶颈时,就会出现 GPU 等待的问题,GPU 空跑那利用率就低了。那么优化的方向就是缩短一切使用 CPU 计算环节的耗时,减少 CPU 计算对 GPU 的阻塞情况。常见的 CPU 计算操作如下:
- 数据加载
- 存储和计算跨城了,跨城加载数据太慢导致 GPU 利用率低
- 存储介质性能太差
- 小文件太多,导致文件 io 耗时太长,读取会浪费很多时间在寻道上
- 未启用多进程并行读取数据
- 未启用提前加载机制来实现 CPU 和 GPU 的并行
- 未设置共享内存 pin_memory
- 数据预处理
- 数据预处理逻辑太复杂
- 利用 GPU 进行数据预处理 – Nvidia DALI
- 模型保存
- 模型保存太频繁
- loss 计算
- loss 计算太复杂
- 评估指标计算
- 指标上报太频繁,CPU 和 GPU 频繁切换导致 GPU 利用率低
- 日志打印
- 日志打印太频繁,CPU 和 GPU 频繁切换导致 GPU 利用率低
- 指标上报
- 进度上报
gpu 共享
- 支持共享gpu,按卡和按显存调度共存(主要针对推理和开发集群)。通过共享gpu 的方式提高资源利用率,将多应用容器部署在一张 GPU 卡上。 Kubernetes对于GPU这类扩展资源的定义仅仅支持整数粒度的加加减减, it’s impossible for a user to ask for 0.5 GPU in a Kubernetes cluster。需要支持 以显存为调度标尺,按显存和按卡调度的方式可以在集群内并存,但是同一个节点内是互斥的,不支持二者并存;要么是按卡数目,要么是按显存分配。可以使用 Volcano GPU共享特性设计和使用 和 AliyunContainerService/gpushare-scheduler-extender 等开源实现
- 支持gpu隔离, 减少共享gpu 带来的pod 间干扰。多pod共享gpu卡,容易导致使用不均,比如两个pod调度到一个卡,其中一个pod有可能占用过多mem,导致另外一个pod oom,需要进行显存和算力隔离,怎样节省 2/3 的 GPU?爱奇艺 vGPU 的探索与实践基于 CUDA API 截获方式实现显存及算力隔离和分配,并基于开源项目 aliyun-gpushare scheduler实现 K8S 上对虚拟 GPU 的调度和分配,实现了多应用容器部署在一张 GPU 卡的目标。
- 显存隔离,拦截特定的API 将其读取的显存的总量 改为 给容器设定的显存上限值
- 算力隔离,CUDA 有三层逻辑层次,分别为 grid(对应整个显卡),block(对应SM),和 thread(对应SP)。SM 之间可以认为是没有交互的(不绝对),既然一些模型无法完全利用 GPU 的全部算力,那么何不削减其占用的 SM 个数,使得空闲下来的 SM 可以为其他 GPU 程序所用?
TKE qGPU 通过两层调度解决 GPU 资源碎片问题 TKE qGPU 通过 CRD 管理集群 GPU 卡资源
- mGPU Driver 是火山引擎内核与虚拟化团队推出的容器共享 GPU 驱动软件,负责提供算力、显存的虚拟化能力和故障隔离能力。在 GPU 设备之上,切分后的 GPU 资源由 mgpu-device-plugin 发现和上报,mGPU Scheduler 根据上报资源和 Pod 中请求的 GPU 资源,通过调度算法计算实现 Pod 的灵活调度。VKE 支持单个容器申领 1% 精度的百分比算力和 1 MiB 级显存调度,兼容整卡调度场景,满足同时使用 GPU 容器共享和整卡 GPU 的业务场景。
- 算力分配策略:固定配额;固定争抢;争抢模式。类似 Pod的QoS 机制。
- 双重调度策略:mGPU Binpack 调度,可将多个 Pod 优先调度到同一个节点或者使用同一张 GPU; mGPU Spread 调度,可将 Pod 尽量分散到不同的节点或者 GPU 卡上。
- 多卡共享策略: 单个容器可使用同一节点上的多张 GPU 卡共同提供算力和显存资源。 假设 A 应用申请了 18GiB 显存和 240% 的算力,并指定了 GPU 卡数为 3,那么该节点需为该应用提供 3 张 GPU 卡,且每张 GPU 卡提供 6GiB 显存和 80% 算力。
- 截获CUDA库转发,如vCUDA。
- 截获驱动转发,如阿里云cGPU、腾讯云qGPU。
- 截获GPU硬件访问,如NVIDIA GRID vGPU。
虚拟化
当前 GPU 原生的的隔离机制在灵活性和分配力度上都无法满足云原生场景下的使用需求。实现资源虚拟化隔离,首先需要资源在时间或空间维度是可分的,在用户视角看来就是多个任务可以并发(concurrent)或并行(parallel)地执行。namespace 和 cgroup 都是内核提供的机制,本质上还要依赖于硬件提供的相关能力。这一点在目前 GPU 上是不存在的,GPU 目前并长期是闭源状态,这些能够 upstream 到内核主线的功能只有硬件提供商有能力提供。当前三方的方案都是在用户态或内核态做的非标准实现,暂时还没有办法纳入 namespace 和 cgroup 范畴。但可以认为 GPU 虚拟化要实现的就是这些接口下面对应的机制,至于是否能标准化是另外一个更大的问题。
- GPU虚拟化的主要出发点是,有些计算任务的颗粒度比较小,单个任务无法占满整颗GPU,如果为每一个这样的任务单独分配一颗GPU并让这个任务独占,就会造成浪费。因此,人们希望可以让多个细粒度的任务共享一颗物理的GPU,同时,又不想让这些任务因共享资源互相干扰,也就是希望实现隔离。因此,GPU 虚拟化要实现“一分多”,也就是把一颗物理的GPU分成互相隔离的几个更小的虚拟GPU,也就是vGPU,每颗vGPU独立运行一个任务,从而实现多个任务共享一颗物理的GPU。
- GPU虚拟化在推理任务中有需求,这是因为推理任务的负载取决于服务请求的多寡,在服务请求的低谷,推理需要的计算时有时无,多个不同的推理任务通过GPU虚拟化共享资源说的通。在模型调试环节或教学环境,GPU虚拟化也有需求,算法工程师或学生每改一次代码就启动一次任务,这个任务或者因为错误很快就停止,或者被工程师杀死,不会持续的需要资源。
- 一般来说,正式的深度学习训练任务计算量都比较大,唯恐资源不够,而不是发愁资源多余,因此GPU虚拟化在训练过程中不太需要。在正式训练中如果出现 GPU 利用率不高的时候,采取的措施往往是对训练进程进行 profiling,找出 GPU 处于 idle 的原因,比如 io、通信、cpu 计算,而不是切分 GPU。
GPU池化技术的演进与发展趋势GPU池化发展的四个阶段:
- 共享调度(自己加一个),只是从资源的层面把两个任务简单的调度到一张卡上。在实际场景中,简单的共享会造成业务之间相互影响,长尾延迟甚至吞吐的恶化导致简单共享无法真正应用于生产环境。
- 简单虚拟化。将单物理GPU按固定比例切分成多个虚拟GPU,比如1/2或1/4,每个虚拟GPU的显存相等,算力轮询。最初是伴随着服务器虚拟化的兴起,解决虚拟机可以共享和使用GPU资源的问题。
- 任意虚拟化。支持将物理GPU按照算力和显存两个维度灵活切分,实现自定义大小虚拟GPU(通常算力最小颗粒度1%,显存最小颗粒度1MB),满足AI应用差异化需求。切分后的小颗粒度虚拟GPU可以满足虚拟机,容器的使用。
- 远程调用。重要技术突破在于支持GPU的跨节点调用,AI应用可以部署到数据中心的任意位置,不管所在的节点上有没有GPU。在该阶段,资源纳管的范围从单个节点扩展到由网络互联起来的整个数据中心,是从GPU虚拟化向GPU资源池化进化的关键一步。一文了解 TKG 如何使用 GPU 资源池 未读。
- 资源池化。关键点在于按需调用,动态伸缩,用完释放。借助池化能力,AI应用可以根据负载需求调用任意大小的虚拟GPU,甚至可以聚合多个物理节点的GPU;在容器或虚机创建之后,仍然可以调整虚拟GPU的数量和大小;在AI应用停止的时候,立刻释放GPU资源回到整个GPU资源池,以便于资源高效流转,充分利用。 “GPU池化”术语发布
gpu 调度
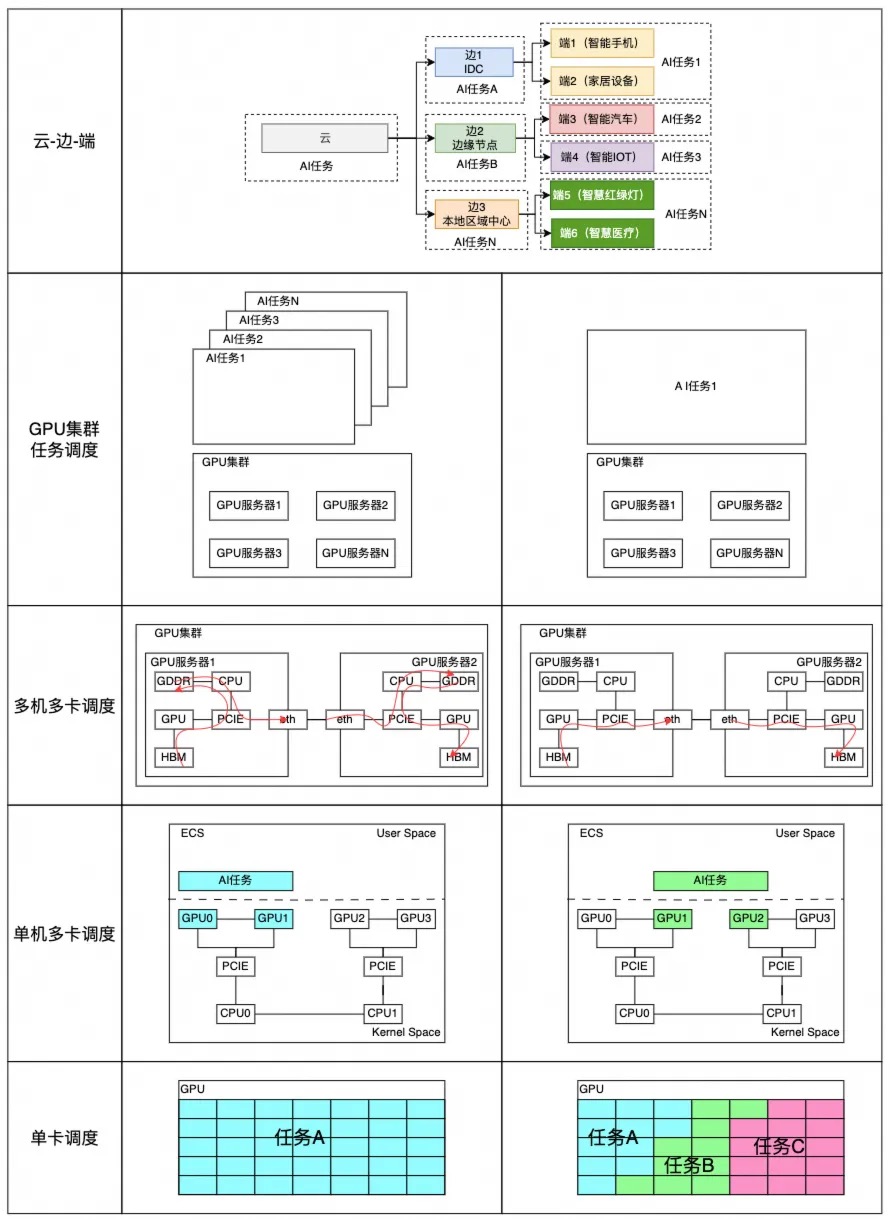
云原生 AI 的资源调度和 AI 工作流引擎设计分享GPU 在离线混部调度,,这个功能分两部分调度逻辑:
- 一是在 K8s 层, AI 调度器将按照亲和性,尽量让在线与离线业务混部 ,同时在线与在线业务反亲和调度;
- 二是底层,cGPU 将根据在离线任务实际负载,调整算力。离线任务使用在线任务空闲算力,同时通过水位线设置保证在线任务的 SLA。
GPU 拓扑架构感知调度,是我们针对单机多卡、多机多卡训练时的一个专项调度优化。我们知道 NVIDIA GPU 卡从 Volta 架构开始,主流的训练卡就已经支持了 NVLink。相较于 PCIe,NVLink 有着巨大的带宽优势。从最佳实践来讲,单机多卡训练时应该优先将同一 NUMA node 下 NVLink 数最多的 GPU 调度给同一个 Pod。而多机多卡的训练时,除了需要考虑 NVLink 数量的条件外,还需要考虑网卡与 GPU卡的物理位置关系,避免出现同一张网卡分配给了不同的 Pod 的情况。因为在这种情况下,可能会出现多 Pod 间相互带宽影响的情况。PS:跟CPU NUMA node调度类似。
Tor 架构感知:对于一些超大模型,可能会需要用到上千卡来进行训练,这会导致 GPU 节点的规模可能会到几百,这些节点毫无疑问会处于不同的 Tor 交换机下。通常这种场景下,模型会采用混合并行策略,即数据并行叠加模型并行的网络结构进行训练,会将训练任务拆分成 n 组单元,n 组单元内的 Pod 会先进行数据同步,再到单元间进行数据同步,那么如果这些训练 Pod 分散到不同交换机的节点上,那有可能同组单元的 Pod 要经过最顶层的 Spine 交换机进行通信,这势必会严重影响训练性能,极端情况下会引起严重的网络拥塞。
弹性训练
具体到工程上是各个 训练组件支持 动态地调整参与训练的实例数量。 worker 加入/移除训练后,训练任务会不中断地继续训练。
- Horovod / mpi-operator云原生的弹性 AI 训练系列之一:基于 AllReduce 的弹性分布式训练实践
- pytorch 云原生的弹性 AI 训练系列之二:PyTorch 1.9.0 弹性分布式训练的设计与实现
- 云原生的弹性 AI 训练系列之三:借助弹性伸缩的 Jupyter Notebook,大幅提高 GPU 利用率 Jupyter Notebooks 在 Kubernetes 上部署往往需要绑定一张 GPU,而大多数时候 GPU 并没有被使用,因此利用率低下。为了解决这一问题,我们开源了 elastic-jupyter-operator将占用 GPU 的 Kernel 组件单独部署,在长期空闲的情况下自动回收,释放占用的 GPU。
实现弹性训练需要注意的问题
- 弹性训练需要一种机制来解决节点/训练进程间相互发现的问题。Horovod 将这一问题交给用户来解决,Horovod 定期执行用户定义的逻辑来发现目前的节点。PyTorch 通过第三方的分布式一致性中间件 etcd 等来实现高可用的节点发现。
- 要实现弹性训练还需要捕获训练失效。Horovod 和 PyTorch 都通过一个后台进程(Horovod 中是 Driver,PyTorch 中是每个节点的 Local Elastic Agent)来实现这一逻辑。当进程 crash,或在梯度通信中遇到问题时,后台进程会捕获到失效并且重新进行节点发现,然后重启训练。
- 训练时的数据切分的逻辑和学习率/ batch size 的设置也要对应进行修改。由于参与训练的进程会动态的增减,因此可能需要根据新的训练进程的规模来重新设置学习率和数据分配的逻辑,避免影响模型收敛。
gpu 监控
GPU计算单元类似于CPU中的核,用来进行数值计算。衡量计算量的单位是flop:the number of floating-point multiplication-adds,浮点数先乘后加算一个flop。计算能力越强大,速度越快。衡量计算能力的单位是flops:每秒能执行的flop数量
1*2+3 1 flop
1*2 + 3*4 + 4*5 3 flop
AI推理加速原理解析与工程实践分享从硬件上看,GPU 的强大算力来源于多 SM 处理器,每个 SM 中包含多个 ALU 计算单元和专有的 Tensor Core 处理单元。对 GPU 来说,当所有 SM 上的所有计算单元都在进行计算时,我们认为其算力得到了充分的发挥。GPU 无法自己独立工作,其工作任务还是由 CPU 进行触发的。 整体的工作流程可以看做是 CPU 将需要执行的计算任务异步的交给 GPU,GPU 拿到任务后,会将 Kernel 调度到相应的 SM 上,而 SM 内部的线程则会按照任务的描述进行执行。当 CPU 不发起新的任务时,则 GPU 的处理单元就处在空闲状态。
通过这两个层面的分析,我们知道要想将 GPU 的算力充分发挥,其核心就是保持GPU 上有任务,同时对单个 GPU 计算任务,使其可以尽量充分的用好 SM 处理器。针对这两个层面的使用情况,NVIDIA 提供了相应的牵引指标 GPU 利用率和 SM 利用率:
- GPU 利用率被定义为在采样间隔内,GPU 上有任务在执行的时间。
- SM 利用率则被定义为在采样间隔内,每个 SM 有 warp 活跃时间的平均值。
显存
对于如下图所示的一个全连接网络(不考虑偏置项b)
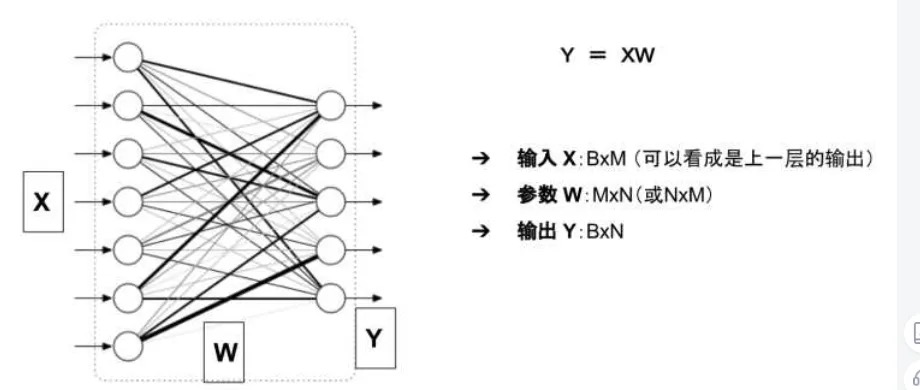
模型的显存占用包括:
- 参数:二维数组 W
- 模型的输出:二维数组 Y 输入X可以看成是上一层的输出,因此把它的显存占用归于上一层。
参数的显存占用。只有有参数的层,才会有显存占用。这部份的显存占用和输入无关,模型加载完成之后就会占用。
- 有参数的层主要包括:
- 卷积 ,Conv2d(Cin, Cout, K): 参数数目:Cin × Cout × K × K。
- 全连接,Linear(M->N) 参数数目:M×N。计算量:BxMxN
- BatchNorm,BatchNorm(N) 参数数目:2N。计算量:BHWC*{4,5,6}
- Embedding层,Embedding(N,W) 参数数目:N × W
- …
- 无参数的层:
- 多数的激活层(Sigmoid/ReLU)。 计算量:BHWC
- 池化层。计算量:BHWCK^2
- Dropout
- …
参数占用显存 = 参数数目×n(n = 4 :float32;)。在PyTorch中,当你执行完model=MyGreatModel().cuda()之后就会占用相应的显存,占用的显存大小基本与上述分析的显存差不多。
梯度与动量的显存占用:优化器如果是SGD,需要保存动量, 因此显存x3,如果是Adam优化器,动量占用的显存更多,显存x4。
总结一下,模型中与输入无关的显存占用包括:
- 参数 W
- 梯度 dW(一般与参数一样)
- 优化器的动量(普通SGD没有动量,momentum-SGD动量与梯度一样,Adam优化器动量的数量是梯度的两倍)
输入输出的显存占用 :需要计算每一层的feature map的形状(多维数组的形状);模型输出的显存占用与 batch size 成正比;需要保存输出对应的梯度用以反向传播(链式法则);模型输出不需要存储相应的动量信息(因为不需要执行优化)。
显存占用 = 模型显存占用(参数 + 梯度与动量 + 模型输出) + batch_size × 每个样本的显存占用
AlexNet的分析如下图,左边是每一层的参数数目(不是显存占用),右边是消耗的计算资源

单机
nvidia-smi 查看某个节点的gpu 情况
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce RTX 208... Off | 00000000:3D:00.0 Off | N/A |
| 23% 25C P8 19W / 250W | 0MiB / 11019MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 208... Off | 00000000:41:00.0 Off | N/A |
| 22% 24C P8 14W / 250W | 0MiB / 11019MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 GeForce RTX 208... Off | 00000000:B1:00.0 Off | N/A |
| 22% 24C P8 13W / 250W | 0MiB / 11019MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 GeForce RTX 208... Off | 00000000:B5:00.0 Off | N/A |
| 23% 26C P8 13W / 250W | 0MiB / 11019MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
- 第一栏的Fan:从0到100%之间变动
- 第二栏的Temp:是温度,单位摄氏度。
- 第三栏的Perf:是性能状态,从P0到P12,P0表示最大性能,P12表示状态最小性能。
- 第四栏下方的Pwr:是能耗,上方的Persistence-M:是持续模式的状态,持续模式虽然耗能大,但是在新的GPU应用启动时,花费的时间更少,这里显示的是off的状态。
- 第五栏的Bus-Id是涉及GPU总线的东西,domain:bus:device.function
- 第六栏的Disp.A是Display Active,表示GPU的显示是否初始化。
- 第五第六栏下方的Memory Usage是显存使用率。
- 第七栏是浮动的GPU利用率。第八栏上方是关于ECC的东西。第八栏下方Compute M是计算模式。
其它技巧:调用 watch -n 1 nvidia-smi 可以每一秒进行自动的刷新。nvidia-smi 也可以通过添加 –format=csv 以 CSV 格式输。在 CSV 格式中,可以通过添加 --gpu-query=... 参数来选择显示的指标。为了实时显示 CSV 格式并同时写入文件,我们可以将 nvidia-smi 的输出传输到 tee 命令中,nvidia-smi --query-gpu=timestamp,pstate,temperature.gpu,utilization.gpu,utilization.memory,memory.total,memory.free,memory.used --format=csv | tee gpu-log.csv。这将写入我们选择的文件路径。
这里推荐一个好用的小工具:gpustat,直接pip install gpustat即可安装,gpustat基于nvidia-smi,可以提供更美观简洁的展示,结合watch命令,可以动态实时监控GPU的使用情况。watch --color -n1 gpustat -cpu
exporter
NVIDIA GPU Operator分析四:DCGM Exporter安装DCGM Exporter是一个用golang编写的收集节点上GPU信息(比如GPU卡的利用率、卡温度、显存使用情况等)的工具,结合Prometheus和Grafana(提供dashboard template)可以提供丰富的仪表大盘。
dcgm-exporter采集指标项以及含义:
| 指标 | 含义 | |
|---|---|---|
| dcgm_fan_speed_percent | GPU 风扇转速占比(%) | |
| dcgm_sm_clock | GPU sm 时钟(MHz) | |
| dcgm_memory_clock | GPU 内存时钟(MHz) | |
| dcgm_gpu_temp | GPU 运行的温度(℃) | |
| dcgm_power_usage | GPU 的功率(w) | |
| dcgm_pcie_tx_throughput | GPU PCIe TX传输的字节总数 | (kb) |
| dcgm_pcie_rx_throughput | GPU PCIe RX接收的字节总数 | (kb) |
| dcgm_pcie_replay_counter | GPU PCIe重试的总数 | |
| dcgm_gpu_utilization | GPU 利用率(%) | |
| dcgm_mem_copy_utilization | GPU 内存利用率(%) | |
| dcgm_enc_utilization | GPU 编码器利用率 (%) | |
| dcgm_dec_utilization | GPU 解码器利用率 (%) | |
| dcgm_xid_errors | GPU 上一个xid错误的值 | |
| dcgm_power_violation | GPU 功率限制导致的节流持续时间(us) | us) |
| dcgm_thermal_violation | GPU 热约束节流持续时间(us) | |
| dcgm_sync_boost_violation | GPU 同步增强限制,限制持续时间(us) | us) |
| dcgm_fb_free | GPU fb(帧缓存)的剩余(MiB) | |
| dcgm_fb_used | GPU fb (帧缓存)的使用 (MiB) |
dcgm-exporter 可以物理机部署,也可以根据官方建议 使用daemonset 部署,之后配置一个 service,用于Prometheus找到节点上dcgm-exporter服务监听的端口,然后访问dcgm-exporter。
从k8s 1.13开始,kubelet通过/var/lib/kubelet/pod-resources下的Unix套接字来提供pod资源查询服务,dcgm-exporter可以访问/var/lib/kubelet/pod-resources/下的套接字服务查询为每个pod分配的GPU设备,然后将GPU的pod信息附加到收集的度量中。
其它
如何把 PyTorch 的 GPU 利用率提升到 100% ?造成 GPU 利用率低的表象虽然五花八门,但其深层次的原因却是 CPU 与 GPU 不协调: CPU 负载太多,或者 GPU 负载太少。GPU 负载好理解,主要指的是 CUDA kernel 以及 CPU 和 GPU 之间必要的内存拷贝。这里的 CPU 负载有两层含义:
- 指 CPU 参与的数据运算和逻辑控制: 数据运算如 dataloader 中的数据增强,或者把输入的文本划分为 token 并转为 tensor,逻辑控制如判定要不要梯度裁剪。它们的共同特征是 GPU 需要等来自 CPU 的数据或者决策完全就绪才能继续执行,一旦 GPU 需要这些数据或者决策,而 CPU 没有及时处理完,那么 GPU 就处在空闲状态,降低了 GPU 利用率。
- 指 CPU 为调用 CUDA API 所做的准备和清理工作: 比如一个 nn.Linear,它最终调用了 cuBLAS 中的 GEMM,但 PyTorch 需要从 Python 前端执行到 C++ 后端,需要为输出 tensor 和必要的 workspace 分配内存,需要根据 device、合适的精度、正向传播/反向传播等一些列信息决定执行哪个算子,cuBLAS 需要根据输入参数的信息查询 heuristics 决定调用哪一个 CUDA kernel,PyTorch 还需要在调用 kernel 后维护计算图信息、执行必要的清理工作。调用一个 CUDA kernel 需要准备一系列复杂的运行时环境,这些都由 CPU 负责完成。当模型中存在大量的小 CUDA kernel 时,CPU 准备运行时环境的时间就会超过 CUDA kernel 在 GPU 上的执行时间,造成 GPU 需要等待 CPU 完成运行时环境的准备,从而降低了GPU 利用率。
从增加 GPU 负载的角度,以下手段可以提升 GPU 利用率:
- 增加每个 GPU 上的 batch size: 不是所有的场景都适用,GPU 数目不多且模型本身的 global batch size 较大时可以一试。除了直接增加单 GPU 上的 batch size,一些通过削减 GPU 内存使用量从而间接提升 batch size 的手段也可以考虑,包括但不限于 gradient/activation checkpointing,ZeRO,model parallelism,等等;
- 共享 GPU: 当一个应用无法充分利用 GPU 时,也可以考虑通过多进程、Multi-Process Service (MPS)、Multi-Instance GPU(MIG) 等手段让多个应用共享同一个GPU,量化投资领域的机器学习模型就有此类案例;
从减小 CPU 负载的角度,以下手段可以提升 GPU 利用率:
- 预处理/缓存: 针对需要 CPU 重复处理的数据,可以在 training 开始前通过预处理把它保存到文件系统中,例如把 training 数据集中的文本转为 token,在预处理阶段把 token 保存在文件系统中,避免在 training 中实时处理数据; 多线程: 现如今的 CPU 基本上都是多核处理器,把主线程上的重负载任务分配给其他 CPU 核,从而降低主线程的工作量,避免主线程因任务繁重而无法及时调用 CUDA kernel;
- CPU 与 GPU 流水线: 把 CPU 和 GPU 组成软件流水线,确保 GPU 需要的数据及时就绪,例如在 GPU 执行当前 iteration 时,CPU 上的 dataloader 预取并处理下一个 iteration 的数据,从而避免由于 CPU 数据没有及时就绪而造成的 GPU 等待;
- 迁移到 GPU 上: 针对 CPU 负责的数据处理和逻辑控制部分,可以把他们迁移到 GPU 上,例如使用 DALI 在 GPU 上进行图像数据预处理,又比如梯度裁剪,原本是否进行梯度裁剪的 if/else 是在 CPU 上执行的,现在把整个梯度裁剪用 GPU 实现,包含其中的 if/else;
- 减少 CUDA kernel 数目: 通过算子融合,可以把多个小 CUDA kernel 合并成一个大 CUDA kernel,原来 CPU 需要为每一个 CUDA kernel 准备运行时环境,融合后则只需要准备一次,这会显著降低 CPU 的运行时开销。能够有效减少 CUDA kernel 数目的手段包括但不限于 vertical fusion,horizontal fusion,multi tensor apply 等等;
- 消除 CPU 与 GPU 之间的同步: CPU 与 GPU 之间的每一次同步,GPU 都会因为 CPU 在准备下一个 CUDA kernel 的运行时环境而进入空闲状态,甚至可能引起后续 CUDA kernel 的连锁反应,使得 CPU 没有足够的时间依次调用 CUDA kernel。移除 CPU 与 GPU 之间的所有同步点,可以把 PyTorch 程序变为 异步(asynchronous, sync-free) 程序,GPU 被 CPU 阻塞的概率大大降低。现阶段,不是所有 PyTorch 中的同步都可以被移除,个别同步点也比较难移除,好在绝大多数同步点都可以避免,例如 .cuda() 会导致一次同步,而 .cuda(non_blocking=True) 则不会有同步;
- CUDA Graph: CUDA Graph 是解决运行时开销的终极武器,它可以基本消除 PyTorch 的所有运行时开销,威力十分强大,但在 PyTorch 中有一定的使用难度,目前也仅限于 static shape 的模型,需要有一定的经验,可以参考 CUDA Graphs。在 PyTorch 中,CUDA Graph 又分为 Partial-network capture 和 Whole-network capture,前者要容易很多,但效果不如后者,Torch 2.0 中的 TorchInductor 也可以自动给一些子图自动应用 CUDA Graph; 异步和 CUDA Graph 提升 GPU 利用率的终极手段;
留下评论