CRI——kubelet与容器引擎之间的接口
简介
《深入剖析Kubernetes》:kubelet 调用下层容器运行时的执行过程,并不会直接调用Docker 的 API,而是通过一组叫作 CRI(Container Runtime Interface,容器运行时接口)的 gRPC 接口来间接执行的。Kubernetes 项目之所以要在 kubelet 中引入这样一层单独的抽象,当然是为了对 Kubernetes 屏蔽下层容器运行时的差异。
![]()
理解容器运行时接口CRI有一句话说得很好,「软件问题都可以通过加一层来解决」,我们的 CRI 就是加了这样一层。
kubelet==> CRI ==> 容器引擎
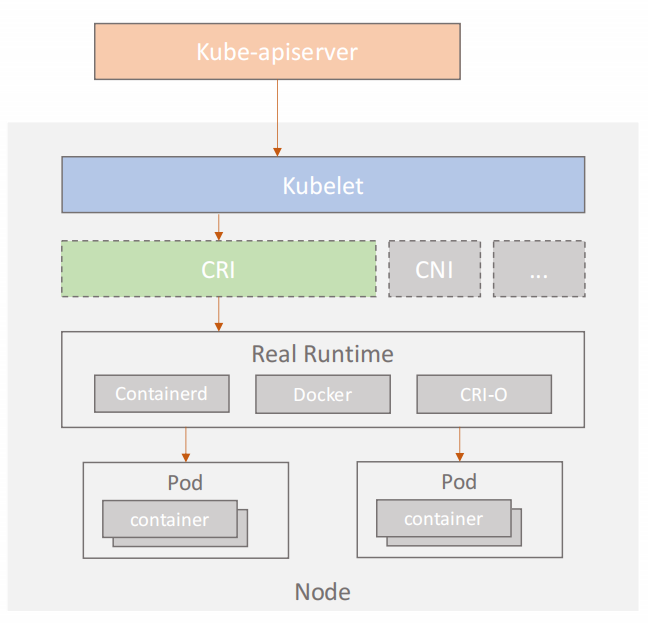
目前 dockershim 还是存在于 Kubelet 的代码中的,它是当前性能最稳定的一个容器运行时的实现。除了 dockershim 之外,其他容器运行时的 CRI shim,都是需要额外部署在宿主机上的。
CRI 接口
CRI 标准的制定是自上而下的,通过 Kubernetes 的一些 feature 反向地要求 CRI 提供这样的功能,进而完善 CRI 规范。
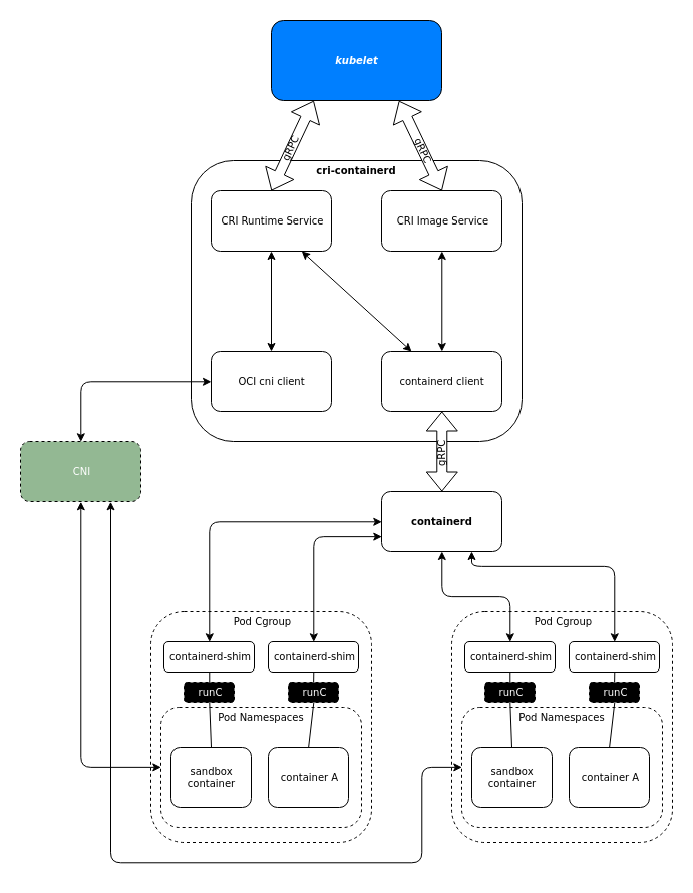
CRI实现了两个GRPC协议的API,提供两种服务ImageService和RuntimeService。
// grpcServices are all the grpc services provided by cri containerd.
type grpcServices interface {
runtime.RuntimeServiceServer
runtime.ImageServiceServer
}
// CRIService is the interface implement CRI remote service server.
type CRIService interface {
Run() error
// io.Closer is used by containerd to gracefully stop cri service.
io.Closer
plugin.Service
grpcServices
}
CRI的实现CRIService中包含了很多重要的组件:其中最重要的是cni.CNI,用于配置容器网络。还有containerd.Client,用于连接containerd来创建容器。
// criService implements CRIService.
type criService struct {
// config contains all configurations.
config criconfig.Config
// imageFSPath is the path to image filesystem.
imageFSPath string
// os is an interface for all required os operations.
os osinterface.OS
// sandboxStore stores all resources associated with sandboxes.
sandboxStore *sandboxstore.Store
// sandboxNameIndex stores all sandbox names and make sure each name
// is unique.
sandboxNameIndex *registrar.Registrar
// containerStore stores all resources associated with containers.
containerStore *containerstore.Store
// containerNameIndex stores all container names and make sure each
// name is unique.
containerNameIndex *registrar.Registrar
// imageStore stores all resources associated with images.
imageStore *imagestore.Store
// snapshotStore stores information of all snapshots.
snapshotStore *snapshotstore.Store
// netPlugin is used to setup and teardown network when run/stop pod sandbox.
netPlugin cni.CNI
// client is an instance of the containerd client
client *containerd.Client
......
}
我们知道 Kubernetes 的一个运作的机制是面向终态的,在每一次调协的循环中,Kubelet 会向 apiserver 获取调度到本 Node 的 Pod 的数据,再做一个面向终态的处理,以达到我们预期的状态。循环的第一步,首先通过 List 接口拿到容器的状态,再通过 Sandbox 和 Container 接口来创建容器,另外还有镜像接口用来拉取容器镜像。
需要注意的是,我们的 CNI(容器网络接口)也是在 CRI 进行操作的,因为我们在创建 Pod 的时候需要同时创建网络资源然后注入到 Pod 中(PS:CNI包含在创建Pod 这个动作里)。接下来就是我们的容器和镜像。我们通过具体的容器创建引擎来创建一个具体的容器。
与OCI
PS: k8s 把docker 放在了OCI的位置,OCI 仅需负责创建容器即可,镜像、CNI 都不用管。
深入理解 OCI 标准 包含了两个标准:
- 镜像标准 Image Specification (image-spec) ,定义了容器的镜像如何打包如何将镜像转换成一个bundle。
- 运行时标准 Runtime Specification (runtime-spec) ,述了如何通过一个bundle运行容器,bundle就是一个目录,里面包括一个容器的规格文件,文件叫config.json 和一个rootfs,rootfs中包含了一个容器运行时所需操作系统的文件。
镜像 = 一份文件清单 (manifest) + 一个或多个文件压缩包 (layer) + 一份配置文件 (config),按照 OCI 规范组合并解压这些压缩包,便组成了一个包含程序包和依赖库的可运行文件系统。只要把该文件系统 (在 OCI 规范中叫做 rootfs) 和 json 配置文件交给 OCI 容器运行时,容器运行时便能够按照用户期望运行目标应用程序。
# runc run -d oci-demo-app > oci-demo-app.out 2>&1
# runc list
ID PID STATUS ... OWNER
oci-demo-app 3054 running ... root
# runc exec -t oci-demo-app sh
通过 runC exec 进入容器 shell 控制台,运行 ifconfig 会发现,默认情况下 runC 容器只有一张 loop 网卡,只有 127.0.0.1 一个地址。也即,通过这种方式运行的容器,被隔离在独立 cgroup 的 network namespace 中,无法直接从宿主机访问容器。
使用 brctl 生成在宿主机生成网桥 runc0 并往 runc0 上挂一张虚拟网卡,网卡的一端 veth-host 绑定在宿主机,网卡的另外一端 veth-guest 将绑定到容器(即容器里的 eth0)。同时使用 ip netns 针对 namespace 进行操作,我们赋予容器网卡(地址在 /var/run/netns/runc-demo-contaienr),同时给予它一个 IP 地址,如此一来即可访问容器。PS:这就是纯 brctl 和 ip netns 操作了。
借助 OCI Runtime 标准,客户端只需提供 rootfs 和 config.json 声明,便可借助不用的 OCI Runtime 实现,将应用跑到不同操作系统上,且达到不同的隔离效果。如只需达到 namespace 级别隔离,Linux 使用 runC,Windows 使用 runhcs,这也是传统容器的隔离级别,隔离资源但并不隔离内核。如果需要达到 VM 级的强隔离,可以使用 gVisor runsc 实现用户态内核隔离,也可以使用 kata-runtime 实现 hypervisor VM 级别隔离。
OCI Runtime 实现支持使用 create 和 start 两阶段启动容器,使用方可以在 create 和 start 间隔准备网络、存储等资源。如今比较流行容器网络接口标准是 CNCF CNI,比较流行的容器存储标准是 container-storage-interface-community CSI。事实上,正是 OCI 将标准定在足够低级的通用范围,才取得了巨大的成功。现如今,它跨云平台、跨操作系统、跨硬件平台、支持各种隔离……
CRI streaming 接口
它可以用来在容器内部执行一个命令,又或者说可以 attach 到容器的 IO 流中做各种交互式的命令。
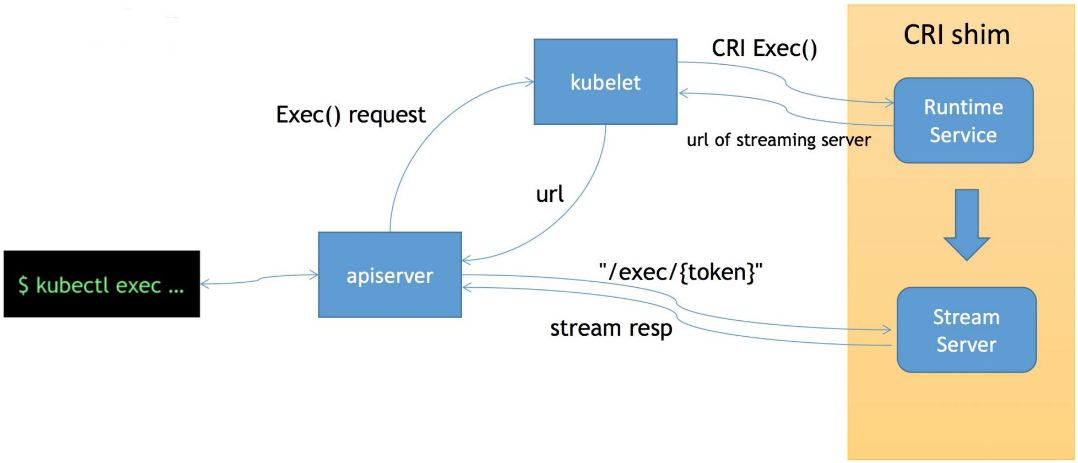
首先 exec 操作会发送到 apiserver,经过鉴权,apiserver 将对 Kubelet Server 发起 exec 的请求,然后 Kubelet 会调用 CRI 的 exec 接口将具体的请求发至容器的运行时。这个时候,容器运行时不是直接地在 exec 接口上来服务这次请求,而是通过我们的 streaming server 来异步地返回每一次执行的结果。也就是说 apiserver 其实实际上是跟 streaming server 交互来获取我们的流式数据的。这样一来让我们的整个 CRI Server 接口更轻量、更可靠。
完整链路是一条“代理接力”,没有谁直接跑命令:
kubectl/client ──exec(HTTP Upgrade)──▶ apiserver ──代理──▶ kubelet ──CRI Exec()──▶ 容器运行时(streaming server)
│ 调 OCI runtime
▼
runc exec = setns 进容器 namespace + execve(cmd)
最底层 runc exec 干的就是上面手动演示的那条 runc exec -t oci-demo-app sh:setns() 钻进目标容器的 mount/pid/net… namespace,再 execve 你的命令——新进程就成了容器 namespace 里的一个子进程,看到的是容器的文件系统和进程视图。
协议上,exec 要同时双向传 stdin/stdout/stderr + 终端 resize,普通 HTTP 一来一回不够,于是用 HTTP Upgrade 把连接升级成多路复用流:早期是 SPDY(Upgrade: SPDY/3.1),1.29 起逐步换成 WebSocket;里面分通道 stdin=0 / stdout=1 / stderr=2 / error=3 / resize=4。
一个值得点出来的点:exec 让你不需要 pod 自己跑 sshd / HTTP server 就能进去执行命令——pod 里只要有那个二进制(如 bash)即可,“进得去”是基础设施给的(apiserver→kubelet→CRI→runc setns),不是 pod 暴露出来的。注意分两段看:client↔apiserver↔kubelet 这前半段是 HTTP(升级成 SPDY/WS),是控制连接;而 kubelet/CRI 到进程的最后一跳不是网络,是 setns + 管道/pty,所以 pod 零配合、不开端口。换句话说,“k8s API 是 HTTP”说的是前半段,“访问 pod 不必让 pod 自己提供 HTTP”说的是后半段。
PS:这条“setns 进 namespace”能成立,前提是容器和宿主共享内核(上面 runC 那种 namespace 级隔离)。如果换成 gVisor / kata 这类 VM 级强隔离,host 跨不进 guest 的内核边界、setns 没用,就必须在 guest 里预先放一个 agent,host 经 vsock 之类的通道喊它“替我在里面 fork+exec”——一个是“从外面伸手进去”,一个是“在里面安插内应”。
CRI 相关工具
Containerd是一个行业标准的容器运行时,它是一个daemon进程,可以管理主机上容器的全部生命周期和它的文件系统,包括:镜像的分发和存储、容器的运行和监控,底层的存储和网络。Containerd有多种客户端,比如K8s、docker等,为了不同客户端的容器或者镜像能隔离开,Containerd中有namespace概念,默认情况下docker的namespace是moby,K8s的是k8s.io。
crictl是一个类似 docker 的命令行工具,用来操作 CRI 接口。它能够帮助用户和开发者调试容器问题,而不是通过 apply 一个 yaml 到 apiserver、再通过 Kubelet 操作的方式来调试。这样的链路太长,而这个命令行工具可以直接操作 CRI。
留下评论