数据并行——allreduce
简介
基本原理
Ring AllReduce简介 各种配图都比较详细了。
Reduce:从多个sender那里接收数据,最终combine到一个节点上。RingAllReduce 是一个环状拓扑结构,在环状结构中不存在中心节点,其各个节点的地位是相同的。梯度同步时,每个worker 只向其右边的邻居发送数据,并从左边的邻居接收数据。这样的架构可以充分利用每个节点的带宽资源,避免中心节点的瓶颈问题。更重要的是,由于梯度被平均放到了不同的节点上,所有节点之间完成一次同步所需要的通信量只跟参数总量有关,而与集群中的节点数量无关。因此,这种架构下的模型训练效率随着集群规模的增加几乎呈线性增长。
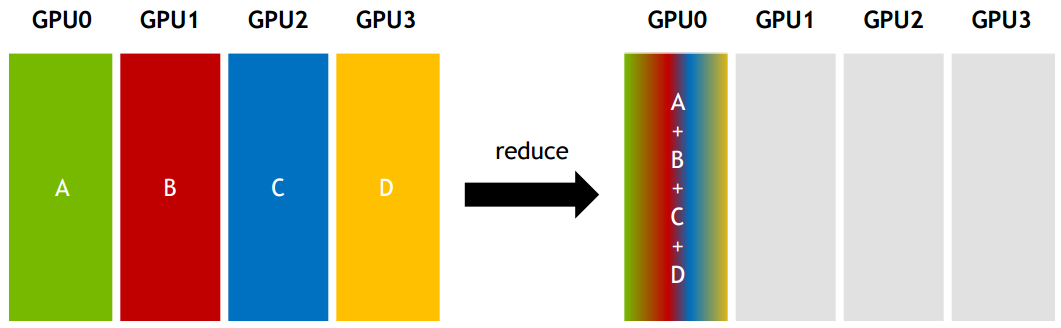
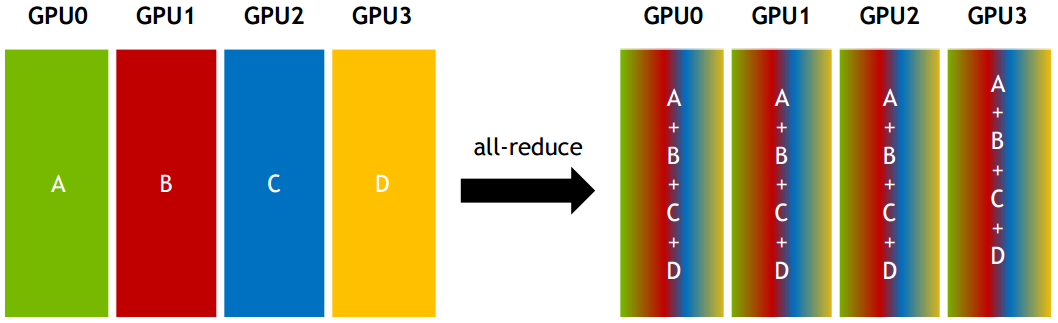
All-reduce:从多个sender那里接收数据,最终combine到每一个节点上。ringAllReduce 是实现 All-reduce 的一种算法(先reduce再broadcast 也是一种,一共有七八种之多),字节也提出了一种算法 bytePS,不是 ps 架构,而是一种带有辅助带宽节点(bandwidth server)的 allreduce 实现。MPI,OpenMPI 与深度学习
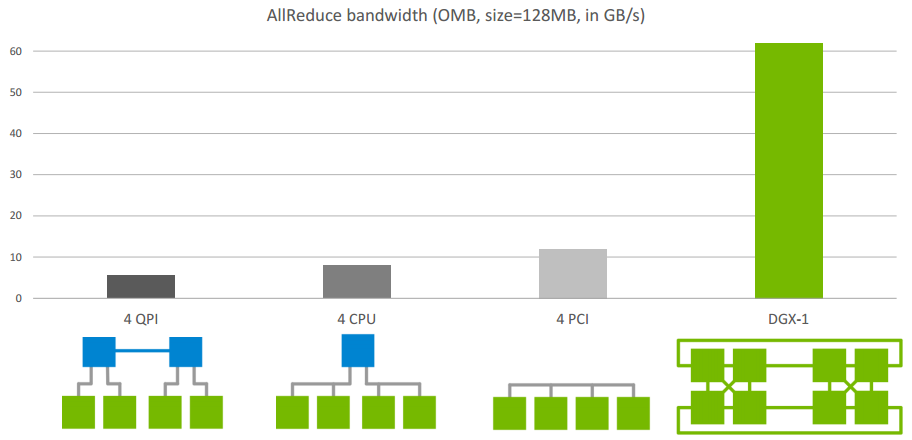
Allreduce在单机不同架构下的速度比较
用Reduction Server加速梯度聚合All-reduce有很多具体的实现,通常是可以由两步组合而成,通常分别是由reduce-scatter和all-gather的两步组合而成。Reduce-scatter完成之后,每个节点各自拥有1/N完整规约过后的数据。下一步的all-gather则是将各个节点上1/N的规约结果发送到所有的节点。效果上等价于N次的broadcast。用Reduction Server加速梯度聚合 也提到了用 Reduction Server 对all-reduce 进一步优化。
在 all_reduce 操作中,我们发送的梯度是网络参数的两倍。例如,当对 Llama 70B 的 fp16 梯度求和时,我们需要在每次迭代中在 GPU 之间发送 280 GB 的数据。在当今的集群中,这需要相当长的时间。
《用python实现深度学习框架》 api示例(待补充)
Ring AllReduce 分为Split/ScatterReudce/AllGather 三个步骤(《用python实现深度学习框架》配图解释的非常好),对于每个worker 来说,它既是右邻居的client,要把自身的梯度发送出去,又是左邻居的server,接收来自左邻居的梯度。AllReduce 的gprc 定义
service RingAllReduceService{
rpc Receive(RingAllReduceReq) returns (RingAllReduceResp){}
rpc VariableWeightsInit(VariableWeightsReqResp) returns(VariableWeightsReqResp){}
}
message RingAllReduceReq{
enum Stage{
INIT = 0;
Scatter = 1;
Gather = 2
}
Stage stage = 1;
NodeGradients node_gradients = 2;
}
VariableWeightsInit 在单机训练的场景下,各变量节点的值是随机初始化的,但是分布式训练场景下,如果多个worker节点也各自随机初始化自己的变量节点,则会导致模型参数在多个worker 节点上不一致。其实从理论上说,随机甚至还是好事,不过从编程来说,还得加上这个保证。
class RingAllReduceService(arrpc.RingAllReduceServiceServicer):
def __init__(self, vars_init_fn, scatter_fn, gather_fn):
# 参数初始化回调函数,由外部trainer传入
self.vars_init_fn = vars_init_fn
# scatter回调函数,由外部的trainer传入
self.scatter_fn = scatter_fn
# gather回调函数,由外部的trainer传入
self.gather_fn = gather_fn
def VariableWeightsInit(self, varibale_weights_req, context):
'''
变量节点初始化。接收上一个worker发送来的初始值并更新自身的变量节点值
'''
variable_weights_cache = DistCommon._deserialize_proto_variable_weights(
varibale_weights_req)
self.vars_init_fn(variable_weights_cache)
return common_pb2.VariableWeightsReqResp()
def Recieve(self, send_req, context):
stage = send_req.stage
# 从gRPC请求中解析出发送来的节点和梯度
node_gradients_dict = DistCommon._deserialize_proto_node_gradients(send_req.node_gradients)
# 接收到左邻居的请求,根据当前阶段的不同,执行不同的回调函数
if stage == arpb.RingAllReduceReq.SCATTER:
acc_no = send_req.node_gradients.acc_no
self.scatter_fn(node_gradients_dict, acc_no)
elif stage == arpb.RingAllReduceReq.GATHER:
self.gather_fn(node_gradients_dict)
else:
print('[ALLREDUCE] Invalid ring all-reduce stage: {}, it should be either SCATTER or GATHER'.format(stage))
return arpb.RingAllReduceResp()
Recieve 解析左邻居发来的节点和梯度,根据当前处于SCATTER 阶段还是GATHER 阶段分别调用不同的回调函数:self.scatter_fn 或self.gather_fn,这两个回调函数会在类实例化时从外部传入。
class DistTrainerRingAllReduce(Trainer):
'''
Ring All-Reduce模式的分布式训练
'''
def __init__(self, *args, **kargs):
Trainer.__init__(self, *args, **kargs)
# 读取集群配置信息和自身信息
self.cluster_conf = kargs['cluster_conf']
self.worker_index = kargs['worker_index']
self.workers = self.cluster_conf['workers']
self.worker_num = len(self.workers)
self.host = self.workers[self.worker_index]
self.step = self.worker_num - 1
# 根据集群的环状拓扑结构确定右邻居
self.target_host = self.workers[(
self.worker_index + 1) % self.worker_num]
# 本节点是否已被初始化
self.is_init = False
self.init_cond = threading.Condition()
self.cur_partion_index = self.worker_index
self.partition = []
# 获取所有可训练节点
self.variables = get_trainable_variables_from_graph()
# 根据worker的总数量,对即将更新的变量节点列表进行等长切分
self._partition_variables()
# 用于控制梯度的发送和接收
self.is_recieved = False
self.recieved_gradients = None
self.recieved_acc_no = None
self.cond = threading.Condition()
# 创建本节点的梯度接收服务
allreduce.RingAllReduceServer(
self.host, self.worker_index,
self._variable_weights_init_callback,
self._scatter_callback,
self._gather_callback).serve()
# 创建连接目标节点的梯度发送client
self.client = allreduce.RingAllReduceClient(self.target_host)
def _variable_weights_init(self):
var_weights_dict = dict()
for node in default_graph.nodes:
if isinstance(node, Variable) and node.trainable:
var_weights_dict[node.name] = node.value
print('[INIT] Send variable init weights to worker ', self.target_host)
# 第一个节点不需要等待,使用默认值更新给下一个节点
if self.worker_index == 0:
self.client.variable_weights_init(var_weights_dict)
else:
self.init_cond.acquire()
while not self.is_init:
self.init_cond.wait()
self.init_cond.release()
self.client.variable_weights_init(var_weights_dict)
def _variable_weights_init_callback(self, var_weights_dict):
# 第一个节点不需要接收上一个节点的初始值
if self.worker_index != 0:
print('[INIT] Variables initializing weights from last worker node...')
for var_name, weights in var_weights_dict.items():
update_node_value_in_graph(var_name, weights)
# 已初始化完成,通知发送流程
self.init_cond.acquire()
self.is_init = True
self.init_cond.notify_all()
self.init_cond.release()
def _optimizer_update(self):
# 共执行 N-1 次scatter操作,把本worker的梯度切片发送给下一个worker
# 同时接收左邻居发送过来的梯度,累加到自己的对应切片上
for scatter_index in range(self.step):
gradients_part = self._get_gradients_partition()
cur_acc_no = self.optimizer.acc_no if scatter_index == 0 else self.recieved_acc_no
# 把自身的一个数据分块发送给右邻居
self.client.send(gradients_part, cur_acc_no, 'scatter')
# 等待接收并处理完左邻居节点的数据
self._wait_for_recieve('scatter')
# 然后执行 N-1 次all-gather操作,把本worker的梯度切片发送给下一个worker
# 同时接收上一个worker发送过来的梯度并替换自己的对应切片
for gather_index in range(self.step):
gradients_part = self._get_gradients_partition()
self.client.send(gradients_part, 0, 'gather')
self._wait_for_recieve('gather')
self.optimizer.update()
def _partition_variables(self):
'''
根据worker的总数量,对即将更新的权值变量列表进行等长切分
'''
var_num = len(self.variables)
part_length = math.ceil(var_num / self.worker_num)
assert part_length > 0
start = 0
end = start + part_length
for i in range(self.worker_num - 1):
self.partition.append((start, end))
start = end
end = start + part_length
self.partition.append((start, var_num))
def _get_gradients_partition(self):
'''
获取下一个梯度切片
'''
start, end = self.partition[self.cur_partion_index]
part_variables = self.variables[start:end]
self.cur_partion_index = (
self.cur_partion_index + self.step) % self.worker_num
part_gradients = dict()
for var in part_variables:
part_gradients[var] = self.optimizer.acc_gradient[var]
return part_gradients
def _scatter_callback(self, node_gradients_dict, acc_no):
'''
Scatter 阶段的回调函数,接收上一个worker发送过来的梯度和样本数
'''
if self.cond.acquire():
while self.is_recieved:
self.cond.wait()
# 把接收到的梯度缓存下来
self.recieved_gradients = node_gradients_dict
self.recieved_acc_no = acc_no
self.is_recieved = True
# 通知主流程,把接收到的梯度更新到优化器
self.cond.notify_all()
self.cond.release()
else:
self.cond.wait()
def _gather_callback(self, node_gradients_dict):
'''
All-gather 阶段的回调函数,接收上一个worker发送来的梯度
'''
if self.cond.acquire():
while self.is_recieved:
self.cond.wait()
self.recieved_gradients = node_gradients_dict
self.is_recieved = True
# 通知主流程,把接收到的梯度更新到优化器
self.cond.notify_all()
self.cond.release()
else:
self.cond.wait()
def _wait_for_recieve(self, stage):
'''
等待梯度,并把接收到的梯度更新到优化器中
'''
if self.cond.acquire():
while not self.is_recieved:
self.cond.wait()
# 如果是scatter阶段则累加梯度,同时累加样本数
if stage == 'scatter':
self.optimizer.apply_gradients(
self.recieved_gradients, summarize=True, acc_no=self.recieved_acc_no)
# 如果是all-gather阶段则覆盖梯度,样本数保持不变
else:
self.optimizer.apply_gradients(
self.recieved_gradients, summarize=False, acc_no=self.optimizer.acc_no)
self.is_recieved = False
# 梯度已被更新,通知接收流程继续接收新的梯度
self.cond.notify_all()
self.cond.release()
else:
self.cond.wait()
horovod
Horovod 目前架构的基础是:机器学习的模型参数在一张 GPU 上可以存下。
使用
在用户已经构建的代码上,只需要插入三段很短的代码即可:
- hvd.init()
- 创建horovod的优化器,即DistributedOptimizer,将旧的优化器封装起来
- 创建horovod的初始化hook,即BroadcastGlobalVariablesHook,将master的初始化值广播给其他worker
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model...
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them.
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization, restoring from a checkpoint, saving to a checkpoint, and closing when done or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,config=config,hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
horovod 的tf 结合又分为 与tf原生api、keras api、estimator 结合。horovod搭配estimator
- 单机多卡启动命令:
horovodrun -np 4 -H localhost:4 python train.py -np指的是进程的数量localhost:4表示localhost节点上4个GPU。- 会启动4个进程执行
python train.py(底层使用ssh进行命令分发) - 多机多卡启动命令,不需要在每个机器上都启动,只需要在第一个机器上启动该命令即可
horovodrun -np 16 -H server1:4,server2:4,server3:4,server4:4 python train.py, 这里使用 4 个服务器,每个服务器使用 4 块 GPU
架构
horovod/horovod
common // 主要是c的部分
data
keras
mxnet // 与mxnet融合
runner // horovodrun 实现
tensorflow // 与tensorflow 融合,比如将allreduce 算子注册tf上,挂到Optimizer的 _compute_gradients 逻辑中
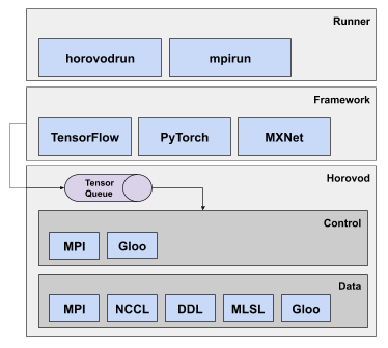
基于 Horovod 进行深度学习分布式训练Horovod主要由数据通信层、通信控制层、深度学习框架接口层、启动层四部分组成。其中启动层通过horovodrun或mpirun启动训练进程,之后每个训练进程通过调用TensorFLow、PyTorch、MXNet等框架(python train.py)进行单个结点的数据输入、参数更新,在每个进程完成一个或多个batch计算后,得到的Tensor(参数)通过MPI或GLoo控制进行ring-allreduce,ring-allreduce 的通信可以基于MPI、NCLL、DDL、MLSL或GLoo。PS: Horovod 本身会在每一个worker 上启动一个进程(运行工作组件),然后内部 执行 python train.py 启动tf 框架进程,与框架融合的代码会负责 将tf 框架的 操作指令发给 Horovod 进程 干活。这就有点类似于 k8s 中的CNI 插件,CNI 插件一般分为两部分,一部分按照k8s的规范 提供执行接口(cni binary),另一部分独立运行在容器内 作为service,cni binary 会把 k8s 的指令 转给 service。
horovodrun 做了什么
深度学习分布式训练框架 horovod (3) — Horovodrun背后做了什么
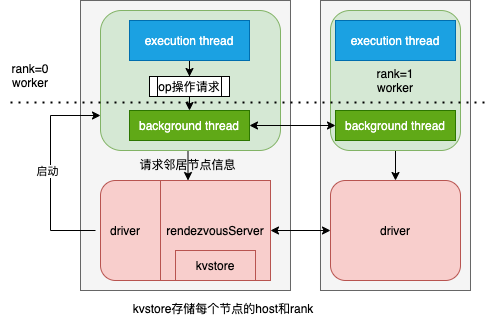
horovodrun ==> run_commandline ==> _run ==> _run_static ==> _launch_job ==> run_controller ==> gloo_run ==> launch_gloo
- 建立 RendezvousServer,这个会被底层 Gloo C++ 环境使用到;
- Horovod 在进行容错 AllReduce 训练时,除了启动 worker 进程外,还会启动一个 driver 进程。这个 driver 进程用于帮助 worker 调用 gloo 构造 AllReduce 通信环。
- Driver 进程需要给 Gloo 创建一个带有 KVStore 的 RendezvousServer,其中 KVStore 用于存储通信域内每个节点的 host 和 其在逻辑通信环分配的序号 rank 等信息。
- 这个 RendezvousServer 运行在 Horovod 的 driver 进程里。driver 进程拿到所有 worker 进程节点的地址和 GPU 卡数信息后,会将其写入RendezvousServer 的 KVStore 中,然后 worker 就可以调用 gloo 来访问 RendezvousServer 构造通信环。
- host_alloc_plan = get_host_assignments 来根据host进行分配slot,就是horovod的哪个rank应该在哪个host上的哪个slot之上运行;
- get_run_command 获取到可执行命令;
- slot_info_to_command_fn 来得到在slot之上可执行的 slot command;
- 依据 slot_info_to_command_fn 构建 args_list,这个 list 之中,每一个arg就是一个 slot command;
- 多线程执行,在每一个 exec_command 之上执行每一个 arg(slot command);
worker 负责训练和模型迭代。
- 每个 worker 节点会向 RendezvousServer 发起请求来得到自己的邻居节点信息,从而构造通信环。
- 在这个通信环之中,每个 worker 节点有一个左邻居和一个右邻居,在通信过程中,每个 worker 只会向它的右邻居发送数据,只会从左邻居接受数据。
汇总一下逻辑: horovodrun ==> run_commandline ==> _run ==> _run_static ==> _launch_job ==> gloo_run
# horovod/horovod/runner/launch.py
def _run(args):
if _is_elastic(args):
return _run_elastic(args)
else:
return _run_static(args)
def _run_static(args):
...
all_host_names, _ = hosts.parse_hosts_and_slots(args.hosts)
...
command = args.command
_launch_job(args, settings, nics, command)
def _launch_job(args, settings, nics, command):
env = os.environ.copy()
config_parser.set_env_from_args(env, args)
def gloo_run_fn():
driver_ip = network.get_driver_ip(nics)
gloo_run(settings, nics, env, driver_ip, command)
def mpi_run_fn():
mpi_run(settings, nics, env, command)
run_controller(args.use_gloo, gloo_run_fn,args.use_mpi, mpi_run_fn,args.use_jsrun, js_run_fn,args.verbose)
if __name__ == '__main__':
run_commandline() # ==> _run
- Horovod 在进行容错 AllReduce 训练时,除了启动 worker 进程外,还会启动一个 driver 进程。这个 driver 进程用于帮助 worker 调用 gloo 构造 AllReduce 通信环。
- driver 进程中会创建一个带有 KVStore 的 RendezvousServer,driver 会将参与通信的 worker 的 ip 等信息存入 KVstore 中。
- 然后 worker 就可以调用 gloo 来访问 RendezvousServer 构造通信环了。
# horovod/horovod/runner/gloo_run.py
def gloo_run(settings, nics, env, server_ip, command):
# Each thread will use ssh command to launch the job on each remote host. If an error occurs in one thread, entire process will be terminated. Otherwise, threads will keep running and ssh session.
exec_command = _exec_command_fn(settings)
launch_gloo(command, exec_command, settings, nics, env, server_ip)
def launch_gloo(command, exec_command, settings, nics, env, server_ip):
# Make the output directory if it does not exist
if settings.output_filename:
_mkdir_p(settings.output_filename)
# start global rendezvous server and get port that it is listening on
# 建立 RendezvousServer,这个会被底层 Gloo C++ 环境使用到
rendezvous = RendezvousServer(settings.verbose)
# allocate processes into slots
# 来根据host进行分配slot,就是horovod的哪个rank应该在哪个host上的哪个slot之上运行
hosts = parse_hosts(settings.hosts)
host_alloc_plan = get_host_assignments(hosts, settings.num_proc)
# start global rendezvous server and get port that it is listening on
global_rendezv_port = rendezvous.start()
rendezvous.init(host_alloc_plan)
# 获取到可执行命令
run_command = get_run_command(command, server_ip, nics, global_rendezv_port)
# 得到在slot之上可执行的 slot command
slot_info_to_command = _slot_info_to_command_fn(run_command, env)
event = register_shutdown_event()
# 依据 slot_info_to_command_fn 构建 args_list,这个 list 之中,每一个arg就是一个 slot command
args_list = [[slot_info_to_command(slot_info), slot_info, [event]]
for slot_info in host_alloc_plan]
# If an error occurs in one thread, entire process will be terminated.
# Otherwise, threads will keep running.
# 多线程执行,在每一个 exec_command 之上执行每一个 arg(slot command)
res = threads.execute_function_multithreaded(exec_command,args_list,block_until_all_done=True)
for name, value in sorted(res.items(), key=lambda item: item[1][1]):
exit_code, timestamp = value
与tf 融合
- Horovod 不依托于某个框架,自己通过MPI建立了一套分布式系统,完成了allreduce, allgather等collective operations通信工作。PS:类似于上图 driver 组成的部分
- Horovod 定义的这套HVD OP是跟具体深度学习框架无关的,比如使用 TensorFlow时候,是无法直接insert到TF Graph中执行的,所以还需要注册TF的OP。针对 TensorFlow 模型分布式训练,Horovod 开发了 TensorFlow ops 来实现 Tensorflow tensor 的 AllReduce。而且这些 op 可以融入 TensorFlow 的计算图中,利用 TensorFlow graph 的 runtime 实现计算与通信的 overlapping,从而提高通信效率。以 TensorFlow 模型的 AllReduce 分布式训练为例,Horovod 开发了 allreduce ops 嵌入 TensorFlow 的反向计算图中,从而获取 TensorFlow 反向计算的梯度并进行梯度汇合。allreduce ops 可以通过调用 gloo 提供的 allreduce API 来实现梯度汇合的。
深度学习分布式训练框架 horovod (7) — DistributedOptimizerHorovod 要求开发者使用Horovod自己定义的 hvd.DistributedOptimizer 代替 TensorFlow 官方的 optimizer,从而可以在优化模型阶段得到梯度。hvd.DistributedOptimizer继承keras Optimizer,然后hvd.DistributedOptimizer在其重载的get_gradients中把获取到的梯度传给hvd.allreduce(gradients, …),从而实现整个horovod集群的梯度集体归并。具体计算梯度的逻辑是:
- TF 调用 hvd.DistributedOptimizer 的 compute_gradients 方法:
- hvd.DistributedOptimizer 首先会利用 TF 官方 optimizer.compute_gradients 计算出本地梯度;
- 然后利用 AllReduce 来得到各个进程平均后的梯度;
- compute_gradients 返回一个(梯度,权值)对的列表。由apply_gradients使用;
- TF 调用 hvd.DistributedOptimizer 的 apply_gradients 方法:
- 调用 TF 官方 optimizer.apply_gradients 对传入的参数进行处理,返回一个更新权值的op。TF 可以用这个返回值进行后续处理; 对于 TF2.x,每行代码顺序执行,不需要构建图,所以 Horovod 梯度更新部分的实现并不是基于计算图的实现
# horovod/horovod/tensorflow/__init__.py
def DistributedOptimizer(optimizer, name=None, use_locking=False, device_dense='',...):
...
return hvd_k.DistributedOptimizer(optimizer=optimizer,name=name,device_dense=device_dense,device_sparse=device_sparse,...)
# horovod/horovod/tensorflow/keras/__init__.py
def DistributedOptimizer(optimizer, name=None,device_dense='', device_sparse='',...):
...
return _impl.create_distributed_optimizer(keras=keras,optimizer=optimizer,name=name,device_dense=device_dense,device_sparse=device_sparse,...)
# horovod/horovod/_keras/__init__.py
def create_distributed_optimizer(keras, optimizer, name, device_dense, device_sparse,...):
class _DistributedOptimizer(keras.optimizers.Optimizer):
def __init__(self, **kwargs):
super(self.__class__, self).__init__(**kwargs)
...
self._allreduce_grads = hvd._make_allreduce_grads_fn(self._name,device_dense,device_sparse,...)
def _compute_gradients(self, loss, var_list, grad_loss=None, tape=None):
tape = tf.GradientTape() if tape is None else tape
# 计算梯度
grads_and_vars = super(self.__class__, self)._compute_gradients(loss,var_list,grad_loss,tape=tape)
grads, weights = list(zip(*grads_and_vars))
# 利用 AllReduce 来得到各个进程平均后的梯度
allreduced_grads = self._allreduce(grads, weights)
return list(zip(allreduced_grads, weights))
def _allreduce(self, grads, vars):
...
return self._allreduce_grads(grads, vars)
def apply_gradients(self, *args, **kwargs):
if self._agg_helper:
...
else:
results = super(self.__class__, self).apply_gradients(*args, **kwargs)
return results
# horovod/horovod/tensorflow/__init__.py
def _make_allreduce_grads_fn(name, device_dense, device_sparse,compression, sparse_as_dense,...):
groups = vars_to_refs(groups) if isinstance(groups, list) else groups
# 弯弯绕绕最后执行_allreduce
return _make_cached_allreduce_grads_fn(name, device_dense, device_sparse,compression, sparse_as_dense,...)
# horovod/horovod/tensorflow/mpi_ops.py
def _load_library(name):
filename = resource_loader.get_path_to_datafile(name)
library = load_library.load_op_library(filename)
return library
MPI_LIB = _load_library('mpi_lib' + get_ext_suffix())
def _allreduce(tensor, name=None, op=Sum, prescale_factor=1.0, postscale_factor=1.0,...):
# 调用的就是 HorovodAllreduceOp
return MPI_LIB.horovod_allreduce(tensor, name=name, reduce_op=op,...)
AllReduce 被注册为 Op,在 ComputeAsync 中,计算请求被入队到一个进程内共享的全局对象维护的队列中(EnqueueTensorAllreduce)。这一队列会被一个统一的后台线程处理,从而把 TF OP 和 Horovod OP 联系起来。后台进程,会一直在执行一个循环 RunLoopOnce,后台线程会利用 MPIController 来处理入队的请求。MPIController 可以理解为是协调不同的 Rank 进程,处理请求的对象。
# horovod/horovod/tensorflow/mpi_ops.cc
class HorovodAllreduceOp : public AsyncOpKernel {
public:
void ComputeAsync(OpKernelContext* context, DoneCallback done) override {
OP_REQUIRES_OK_ASYNC(context, ConvertStatus(common::CheckInitialized()),done);
auto node_name = ...
auto device = GetDeviceID(context);
auto tensor = context->input(0);
horovod::common::ReduceOp reduce_op = static_cast<horovod::common::ReduceOp>(reduce_op_);
Tensor* output;
OP_REQUIRES_OK_ASYNC(context, context->allocate_output(0, tensor.shape(), &output), done);
// ReadyEvent makes sure input tensor is ready, and output is allocated.
common::ReadyEventList ready_event_list;
#if HAVE_GPU
ready_event_list.AddReadyEvent(std::shared_ptr<common::ReadyEvent>(RecordReadyEvent(context)));
#endif
auto hvd_context = std::make_shared<TFOpContext>(context);
auto hvd_tensor = std::make_shared<TFTensor>(tensor);
auto hvd_output = std::make_shared<TFTensor>(*output);
// 把 张量的Allreduce操作加入Horovod后台队列,从而把 TF OP 和 Horovod OP 联系起来。
auto enqueue_result = EnqueueTensorAllreduce(hvd_context, hvd_tensor, hvd_output, ready_event_list, node_name, device,...);
OP_REQUIRES_OK_ASYNC(context, ConvertStatus(enqueue_result), done);
}
private:
int reduce_op_;
// Using float since TF does not support double OP attributes
float prescale_factor_;
float postscale_factor_;
bool ignore_name_scope_;
int process_set_id_;
};
REGISTER_OP("HorovodAllreduce")
.Attr("T: {int32, int64, float16, float32, float64}")
.Attr("reduce_op: int")
.Attr("prescale_factor: float")
.Attr("postscale_factor: float")
.Attr("ignore_name_scope: bool = False")
.Attr("process_set_id: int = 0")
.Input("tensor: T")
.Output("sum: T")
弹性训练
深度学习分布式训练框架 horovod (12) — 弹性训练总体架构
容错,当众多worker之间对张量进行聚合操作时候,如果某一个worker失败,则gloo不会处理异常,而是抛出异常并且退出,这样所有worker都会报异常退出。为了不让某一个 worker 的失败导致整体训练退出,Horovod 需要做两方面工作:
- 不让异常影响现有作业。Horovod 必须捕获 gloo 抛出的异常,于是就构建了一个python处理异常机制。Worker 在捕获异常之后会将异常传递给对应的 Python API 处理,API 通过判断异常类型决定是否继续训练。如果异常信息中包括 “HorovodAllreduce”、“HorovodAllgather” 或者 “HorovodBroadcast” 等关键字,说明这可能是某个worker死掉导致的通信失败,这种异常被Horovod认为是可以恢复的。
- 放弃失败的worker,使用剩余可用worker继续训练。
- 其他存活的 worker 停止当前的训练,记录当前模型迭代的步数。
- 此时gloo的runtime已经出现问题,通信环已经破裂,无法在剩余的 worker 之间继续进行 AllReduce 操作。
- 为了可以继续训练,Horovod Driver 会重新初始化 gloo,启动一个新的 rendezvous server,然后获取存活的 worker 的信息,利用这些worker组成新的通信环。
- 当新的通信环构造成功后,rank 0 worker 会把自己的模型广播发给其他所有worker,这样大家就可以在一个基础上,接着上次停止的迭代开始训练。
容错机制是被动操作,监控机制就是主动操作。在 Horovod 启动命令中提供一个发现脚本 discovery_host。discovery_host 由用户编写,负责发现可用的 worker 节点拓扑信息。Driver在运行之后会定期调用这个 bash 脚本来对集群监控,当worker发生变化时,discover_host 脚本会返回最新的worker状态,Driver 根据 discover_host 的返回值得到 worker 节点信息:
- 如果Driver发现有worker失败,就捕获异常,根据存活的worker信息来更新 RendezvousServer KVStore 的节点信息,号召大家重新建立通信环进行训练。
- 如果Driver发现有新worker节点加入集群,根据目前所有worker信息来更新 RendezvousServer KVStore 的节点信息,号召大家重新建立通信环进行训练。现有worker 节点收到通知后,会暂停当前训练,记录目前迭代步数,调用 shutdown 和 init 重新构造通信环。Driver也会在新节点上启动worker,扩充进程数目。
- 当新的通信环构造成功之后,rank 0 worker 会把自己的模型广播发给其他所有worker,这样大家就可以在一个基础上,接着上次停止的迭代开始训练。
发现节点机制的几个关键设计点如下:
- 有节点变化时候,如何即时发现?Horovod是通过定期调用完成。
- 发现节点变化时候,如何通知各个worker? Horovod通过构建了一个通知机制完成。即,每个worker把自己注册到WorkerNotificationManager 之上,当有节点变化时候,WorkerNotificationManager 会逐一通知这些worker。
- worker得到通知之后,如何处理?Horovod 把worker的状态在深度框架上进一步封装成各种State,得到通知之后就会调用State的对应callback函数,或者同步状态,或者进行其他处理。
示例代码
import tensorflow as tf
import horovod.tensorflow as hvd
hvd.init()
gpus = tf.config.experimental.list_physical_devices('GPU')
for gpu in gpus:
tf.config.experimental.set_memory_growth(gpu, True)
if gpus:
tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')
dataset = ...
model = ...
optimizer = tf.optimizers.Adam(lr * hvd.size())
@tf.function
def train_one_batch(data, target, allreduce=True):
with tf.GradientTape() as tape:
probs = model(data, training=True)
loss = tf.losses.categorical_crossentropy(target, probs)
if allreduce:
tape = hvd.DistributedGradientTape(tape)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# Initialize model and optimizer state so we can synchronize across workers
data, target = get_random_batch()
train_one_batch(data, target, allreduce=False)
# 使用 @hvd.elastic.run 对 train 做了一个封装
@hvd.elastic.run
def train(state):
for state.epoch in range(state.epoch, epochs):
for state.batch in range(state.batch, batches_per_epoch):
data, target = get_random_batch()
train_one_batch(data, target)
if state.batch % batches_per_commit == 0:
state.commit()
state.batch = 0
def on_state_reset():
optimizer.lr.assign(lr * hvd.size())
# 这里是新修改处,传入了一个 TensorFlowKerasState
state = hvd.elastic.TensorFlowKerasState(model, optimizer, batch=0, epoch=0)
state.register_reset_callbacks([on_state_reset])
train(state)
启动命令horovodrun -np 18 --host-discovery-script discover_hosts.sh python train.py
worker 进程逻辑
# horovod/tensorflow/elastic.py
def run(func):
from tensorflow.python.framework.errors_impl import UnknownError
def wrapper(state, *args, **kwargs):
try:
return func(state, *args, **kwargs)
except UnknownError as e:
if 'HorovodAllreduce' in e.message or 'HorovodAllgather' in e.message or 'HorovodBroadcast' in e.message:
raise HorovodInternalError(e)
return run_fn(wrapper, _reset)
# horovod/common/elastic.py
def run_fn(func, reset):
@functools.wraps(func)
def wrapper(state, *args, **kwargs):
notification_manager.init()
notification_manager.register_listener(state)
skip_sync = False
try:
while True:
if not skip_sync:
state.sync() # 当重置时候,用户也会进行必要的同步,具体是广播变量 和 存模型 两步
try:
return func(state, *args, **kwargs)
except HorovodInternalError: # 训练出错
state.restore() # 进行恢复,就是重新加载模型,具体加载就是利用 TensorFlowKerasState 的 model, optimizer 这两个成员变量。
skip_sync = False
except HostsUpdatedInterrupt as e: # driver发现一个节点被标记为新增或者移除时,将发送一个通知到 所有worker,worker 抛出 HostsUpdatedInterrupt
skip_sync = e.skip_sync
reset()
state.on_reset() # 执行用户设置的 reset callback
finally:
notification_manager.remove_listener(state)
return wrapper
def _reset():
shutdown()
init() # 重新建立 MPI 相关 context
与k8s运行
在 Kubernetes 上常见的是 kubeflow 社区的 tf-operator 支持 Tensorflow PS 模式,或者 mpi-operator 支持 horovod 的 mpi allreduce 模式。
其它
百度:AIAK-Training 是基于 Horovod 深度定制优化的分布式训练框架(Horovod 是 TensorFlow、Pytorch 等的分布式深度学习训练框架),在保留 Horovod 已有功能特性的基础上,增加了新的通信优化特性,完全兼容 Horovod 原有 API,经典模型的训练效率提升 50% 以上。
留下评论