volcano特性源码分析
简介
SchedulerCache
借一下kube-batch 设计图
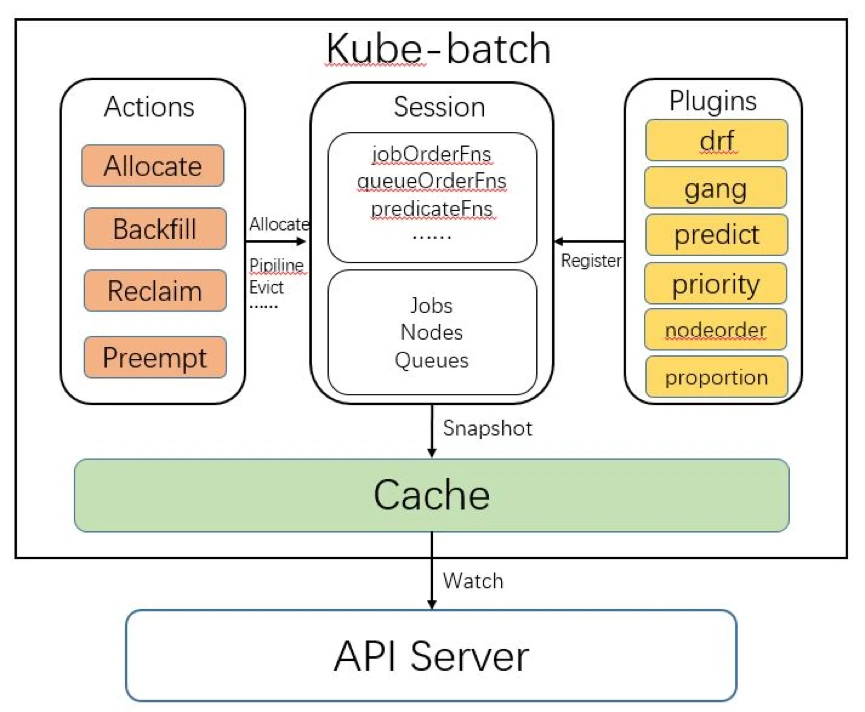
SchedulerCache 将调度所需的数据缓存起来,并保持与apiserver 同步。Cache 模块还封装了对 API server 接口的调用。比如 Cache.Bind 接口,会调用 API Server 的 Bind 接口,将容器绑定到指定节点上。在 kube-batch/volcano 中,只有 cache 模块需要和 API Server 交互,其他模块只需要调用 Cache 模块接口。
type SchedulerCache struct {
xxInformer ... // 各种informer
...
Jobs map[schedulingapi.JobID]*schedulingapi.JobInfo
Nodes map[string]*schedulingapi.NodeInfo
Queues map[schedulingapi.QueueID]*schedulingapi.QueueInfo
PriorityClasses map[string]*v1beta1.PriorityClass
}
SchedulerCache 会持有很多informer, 初始化的 informer 注册各个 eventHandler,然后pod/podgroup等变动会被同步在 Jobs, Nodes, Queues, PriorityClasses 等几个 map 中。pg 加入jobInfo,pod 加入taskInfo。
session 与调度周期
Session 模块是将action/plugin/cache三个模块串联起来的模块。Kube-batch 在每个调度周期开始时,都会新建一个 Session 对象,这个 Session 初始化时会做以下操作:
- 调用 Cache.Snapshot 接口,将 Cache 中节点、任务和队列信息拷贝一份副本,之后在这个调度周期中使用这份副本进行调度。因为 Cache 的数据会不断变化,为了保持同个调度周期中的数据一致性,在一开始就拷贝一份副本。PS:在一个调度周期,基于snapshot 数据,找到当前资源可以运行的最高优先级的pod,优先调度。全局决策,也是批量调度的一个内涵。
- 将配置中的各个 plugin 初始化,然后调用 plugin 的 OnSessionOpen 接口。plugin 在 OnSessionOpen 中,会初始化自己需要的数据,并将一些回调函数注册到 session 中。
plugin 会根据自己的语义 注册相关的函数到 Session中,在Action.Execute 中被调用。
// kube-batch/pkg/scheduler/framework/session.go
type Session struct {
UID types.UID
cache cache.Cache
Jobs map[api.JobID]*api.JobInfo
Nodes map[string]*api.NodeInfo
Queues map[api.QueueID]*api.QueueInfo
Backlog []*api.JobInfo
Tiers []conf.Tier
plugins map[string]Plugin
eventHandlers []*EventHandler
}
Action 只有一个Session 一个入参,从 Session.jobs 等拿到数据,处理完成后写回Session.jobs 等,Session 既是数据载体,也是action 之间的信息传递渠道。比如 Enqueue action 将session.Jobs 中符合条件的job 状态从pending 改为非pending,allocate/backfill action 不处理pending状态的job。 allocate 不处理 request resource 为空的task,backfill 会处理。
type Session struct {
jobOrderFns map[string]api.CompareFn // 决定哪个训练任务优先被处理(调度、回收、抢占)。
queueOrderFns map[string]api.CompareFn // 决定哪个训练队列优先被处理。
taskOrderFns map[string]api.CompareFn // 决定任务中哪个容器优先被处理。
predicateFns map[string]api.PredicateFn // 判断某个节点是否满足容器的基本调度要求。比如容器中指定的节点的标签。
nodePrioritizers map[string][]priorities.PriorityConfig // 当多个节点满足容器的调度要求时,优先选择哪个节点。
preemptableFns map[string]api.EvictableFn // 决定某个容器是否可以被抢占
reclaimableFns map[string]api.EvictableFn // 决定某个容器是否可以被回收
overusedFns map[string]api.ValidateFn // 决定某个队列使用的资源是否超过限额,是的话不再调度对队列中的任务
jobReadyFns map[string]api.ValidateFn // 判断某个任务是否已经准备好,可以调用 API Server 的接口将任务的容器调度到节点。
jobPipelinedFns map[string]api.ValidateFn // 判断某个任务是否处于 Pipelined 状态
jobValidFns map[string]api.ValidateExFn // 判断某个任务是否有效
}
// kube-batch/pkg/scheduler/framework/session_plugins.go
func (ssn *Session) AddJobReadyFn(name string, vf api.ValidateFn) {...}
func (ssn *Session) JobReady(obj interface{}) bool {...jobValidFns...}
func (ssn *Session) AddJobValidFn(name string, fn api.ValidateExFn) {...}
func (ssn *Session) JobValid(obj interface{}) *api.ValidateResult {...jobReadyFns...}
// kube-batch/pkg/scheduler/framework/session.go
func (ssn *Session) Allocate(task *api.TaskInfo, hostname string) error {...}
func (ssn *Session) Pipeline(task *api.TaskInfo, hostname string) error {...}
func (ssn *Session) Evict(reclaimee *api.TaskInfo, reason string) error {...}
Session 一共有两类方法:
- session_plugins,与plugin 相关的各种Function 注入与调用;
- 真正操作Pod的Allocate/Pipeline/Evict。 Action.Execute中,Action 依次遍历 pending 状态的task,根据session_plugins方法判断task 和job 状态,最终调用Pod的Allocate/Pipeline/Evict。这或许是Action 和Plugin ,机制和策略分离的一种解释。
gang-scheduler 如何实现
kube-batch 具体如何实现gang scheduler kube-batch 从代码中找出gang scheduler这个过程
gang-scheduler 非常类似分布式事务/tcc,tcc 有一个预留的动作,要实现gang-scheduler的效果,Pod 自带的Pending/Running/Succeeded/Failed/Unknown 是不够的, 为此Pod 对应struct TaskInfo 定义了Pending/Allocated/Pipelined/Binding/Bound/Running/Releasing/Succeeded/Failed/Unknown 状态,其中 Allocated 用来标记pod 已分配资源但未实际运行的状态。
当需要进行gang-scheduler 时,上层operator/controller 会将pod 的schedulerName 设置为kube-batch或volcano,并带上 annotation scheduling.k8s.io/group-name,创建 name= scheduling.k8s.io/group-name 的podgroup,即podgroup 和 pod 通过scheduling.k8s.io/group-name 关联。
一个podGroup 对应一个JobInfo,kube-batch 将pod 转换为taskInfo,每一个node对应NodeInfo,所谓 为pod分配Node:taskInfo.NodeName=nodeName,NodeInfo减去pod 标定的资源。当发现 JobInfo 下的taskInfo 符合minMember,即真正为 pod 赋值nodeName。具体代码还要再捋捋。
func (alloc *allocateAction) Execute(ssn *framework.Session) {
...
// 对queue和job 进行排序 queues 和jobs 都是优先级队列
for {
if queues.Empty() {break}
queue := queues.Pop().(*api.QueueInfo) // 取出优先级最高的queue
if ssn.Overused(queue) {continue} // 某个queue 占用的资源过多,不再为其pod进行调度了
jobs, found := jobsMap[queue.UID] // 取出queue 对应的jobs
job := jobs.Pop().(*api.JobInfo)
// 赋值api.Pending状态的task 到 pendingTasks
tasks := pendingTasks[job.UID]
glog.V(3).Infof("Try to allocate resource to %d tasks of Job <%v/%v>",
tasks.Len(), job.Namespace, job.Name)
for !tasks.Empty() {
task := tasks.Pop().(*api.TaskInfo)
predicateNodes := util.PredicateNodes(task, allNodes, predicateFn) // 预选
if len(predicateNodes) == 0 {break}
priorityList, err := util.PrioritizeNodes(task, predicateNodes, ssn.NodePrioritizers()) // 优选
if err != nil {break}
nodeName := util.SelectBestNode(priorityList)
node := ssn.Nodes[nodeName]
// Allocate idle resource to the task.
if task.InitResreq.LessEqual(node.Idle) {
if err := ssn.Allocate(task, node.Name); err != nil {...} // 绑定task到node
} else {
//store information about missing resources
job.NodesFitDelta[node.Name] = node.Idle.Clone()
job.NodesFitDelta[node.Name].FitDelta(task.InitResreq)
// Allocate releasing resource to the task if any.
if task.InitResreq.LessEqual(node.Releasing) {
if err := ssn.Pipeline(task, node.Name); err != nil {...}
}
}
// job ready(比如job一共10个 minMember=5)当前job 放在jobs的最后,还剩的5的pod 调度优先级就不高了,可以放放,暂停对这个job的调度
if ssn.JobReady(job) && !tasks.Empty() {
jobs.Push(job)
break
}
}
queues.Push(queue) // Added Queue back until no job in Queue.
}
}
Session.Allocate ==> if ssn.JobReady(job) Session.dispatch==> Cache.Bind(task *api.TaskInfo, hostname string) error 真正 更新pod 即设定pod.nodeName。
- 对于jobReadyFns 来说,只有gang plugin 注册了jobReadyFns 到Session 上,Session.JobReady 默认返回true。也就是,如果不用gang plugin,则每一次 Session.Allocate,job ready默认为true,为pod 真正分配node。
- 用了gang plugin之后,则每次Session.Allocate,要先校验 gang.jobReadyFns,校验通过,则为pod 真正分配node,否则只是将 task 标记为 api.Allocated ,记住了taskInfo 所属的nodeInfo,并在nodeInfo 中扣掉了taskInfo的资源
NodeInfo.addTask。 - 比如job一共10个task, minMember=5。如果已经分配了4个,第5找不到合适的节点。gang plugin 向Session 注册了 ReclaimableFn/PreemptableFn(计算牺牲作业)。对于 这种状态的 job,这4个task 可以被抢占。如果已经分配了 6个,则多出来的一个task 也可以被抢占
Volcano 调度器源码分析(scheduler 03)整体上,gang plugins 的逻辑就是围绕着 jobInfos.MinAvailable 这个属性展开的,几个函数位点主要也是为了增加跟 jobInfos.MinAvailable 的比较条件。
资源配额管理
假设存在queue1/queue2,包含运行或排队的任务task1/task2/task3/task4, 在一个调度周期内,queue 和 task 是确定的,volcano 负责在这个确定的任务列表和资源约束下 调度排队的任务。
主要逻辑在哪
如何实现了Queue 的weight 资源软约束与capacity 硬约束?主要在 proportion plugin 中
在allocate.go 中,针对一个task 的调度,会先找到task 所属queue 富余的资源(包括cpu/memory/自定义),如果queue 富余资源够 task 使用,则资源申请成功,开始进入预选优选环节。
// queue 有没有资源运行task
taskRequest := task.Resreq.ResourceNames()
if underusedResources := ssn.UnderusedResources(queue); underusedResources != nil && !underusedResources.Contains(taskRequest) {
klog.V(3).Infof("Queue <%s> is overused when considering task <%s>, ignore it.", queue.Name, task.Name)
continue
}
// 预选优选
一个queue富余资源的计算来自ssn.UnderusedResources ,只有proportion 一个plugin 注册了 underUsedFns,所以主要工作 在 proportion plugin 里。
如何计算 queue.deserved
type proportionPlugin struct {
// 集群总资源
totalResource *api.Resource
queueOpts map[api.QueueID]*queueAttr
// Arguments given for the plugin
pluginArguments framework.Arguments
}
type queueAttr struct {
queueID api.QueueID
name string
weight int32
share float64
deserved *api.Resource // queue 应得的资源
allocated *api.Resource // running task 已经申请的资源
request *api.Resource // running + pending task 准备申请的资源
// inqueue represents the resource request of the inqueue job
inqueue *api.Resource
capability *api.Resource // queue capability 配置
}
一个queue 对应 一个queueAttr,proportionPlugin.OnSessionOpen 主要工作就是 为queue 的deserved/allocated/request/capability 属性赋值
- 其中capability 从queue配置获取
- allocated/request 从queue 所属的 pod 申请的资源累加得到
- deserved 需要计算,分为多次循环,每次循环尝试给 queue 一点资源,直到给queue 的资源满足request,这个queue的分配就结束。这一点资源= weight * remaing,下文称weight remaing resoruce (简称wrr)
如何计算 queue.deserved
每个queue deserved 初始为0
for{
for 每个queue{
deserved = deserved + wrr
1. 如果 deserved 大于 capability,则取 deserved/capability/request 较小值,不管资源够不够用,meet了,不再继续分配资源了
2. 如果 deserved 小于 capability 大于 request,也是meet 了 退出循环
3. 如果 deserved 小于 request ,那就先给其它queue 分配资源,若还有剩余remaining 再来一轮
}
更新remaining
如果上一次remaining 和这一次 没有变化或者没有remaining了,说明queue 都分配好了或没有资源了,退出分配过程
}
deserved 计算的本质是 三者求最小,即min(deserved,capacity,request)。
假设资源总量是100,queue1和queue2 weight=1
- 一次分配循环给 queue 属于它weight 配额的资源(deserved += wrr),够了就算了(deserved > request),不够等别人的配额分完了再来一轮。
- 哪怕集群资源足够,proportion 也只是给queue 分配刚好够 request的资源。
attr.deserved = helpers.Min(attr.deserved, attr.request), 假设queue1,queue2 request=30 那么最终 queue1,queue2 deserved=30 - 结合前2点,可能会出现一种情况:假设queue1 request=40,queue2 request=60,则第一轮queue1 deserved=40,queue2 deserved=50,第二轮queue2 deserved=60
其它:在一个调度周期内,一个queue 不会用到超过 deserved 的资源。 多轮调度周期下, t1 时刻 queue.deserve 是一个值,因为有新的task等导致 t2 时刻queue.deserved 值变小,此刻,可能会出现一个queue的 allocated 大于 deserved的情形。
如何判断queue 是否可以执行
proportion.underUsedFns 计算富余资源:session 初始化的核心是 计算Queue的 deserved ,之后每次 调度task 时,对queue deserved 与 allocated 求差值即 得到富余的资源,进而确定 富余资源是否够 task 运行。
plugin为什么要分成tiers
actions: "enqueue, allocate, backfill"
tiers:
- plugins:
- name: priority # 让用户自定义job、task优先级
- name: gang # 满足了调度过程中的“All or nothing”的调度需求
- name: conformance # 除了 critical pod 都ok
- plugins:
- name: drf # 优先占用资源小的业务
- name: predicates # 快速筛选出来需要GPU的进行集中调度
- name: proportion # 如果投递的作业量超过所属queue最大可用资源,就需要排队。
- name: nodeorder # 从各个维度为node打分,打分参数由用户来配置。
- name: binpack # binpack调度算法的目标是尽量把已有的节点填满,每种资源配置的权重值、不同的插件在计算节点分数时权重值由用户来配置
为什么要分成tiers?背景:每个plugin 注册了一堆函数,action 会在会在适当的实际调用Session.函数()执行。Session.函数() 的大体逻辑都是 遍历plugin 注册的所有函数并执行,每个plugin 只注册了跟自己逻辑有关的函数。
- priority, TaskOrderFn/JobOrderFn/PreemptableFn
- gang, JobValidFn/ReclaimableFn/PreemptableFn/JobOrderFn/JobReadyFn/JobPipelinedFn/JobStarvingFns
- conformance, PreemptableFn/ReclaimableFn
- drf, PreemptableFn/QueueOrderFn/ReclaimableFn/JobOrderFn/NamespaceOrderFn
- predicates, PredicateFn
- proportion, QueueOrderFn/ReclaimableFn/OverusedFn/UnderusedResourceFn/JobEnqueueableFn
- nodeorder, NodeOrderFn/BatchNodeOrderFn
- binpack , NodeOrderFn
Session.函数() 核心逻辑是两层循环,分为三种情况
- “一言不合”直接返回的
func (ssn *Session) xx() xx{ for _, tier := range ssn.Tiers { for _, plugin := range tier.Plugins { if(xx){ return xx } } } return xx } - 所有plugin 一起配合计算的,比如给某个node 打分
func (ssn *Session) xx() xx{ for _, tier := range ssn.Tiers { for _, plugin := range tier.Plugins { sum += xx } } return sum } - tier内 的所有plugin 参与计算。比如 Reclaimable 决定回收哪些正在运行的pod,即寻找victim。如果在第一层tier 中可以找到牺牲者 就直接返回了,毕竟能牺牲少点就牺牲少点,实在不行,才会计算第二层tier。
func (ssn *Session) xx() xx{ var victims []*api.TaskInfo for _, tier := range ssn.Tiers { for _, plugin := range tier.Plugins { // 寻找victim } if victims != nil { return victims } } return nil前两种情况,是不需要区分两层的,此时所有的plugin 先后顺序是重要的,是不是在一个tier 里不重要,即要么立即结束要么全局聚合。第三种情况, tier内 的plugin 局部聚合,两层for 之间做判断,如果有数据则 return。以默认的配置文件
scheudler.conf来说,第一个tier 更多是基于用户设置,第二个tier 是基于task 和集群的实际情况,以用户设置为优先。
其它
鲁直:做开源,我觉得首先肯定要做一个心理准备,就是说你要有一个核心部分,再在这个基础上做扩展,在维护的成本上肯定有一定的上升,但是你要接受这样的成本——我觉得这种成本是可以接受的。……项目本身要设计好,具备一定分拆的可能性。如果不具备分拆可能性,那没法做了。像微内核这样的设计方式就会比较适合——就是开源一个核心模块,然后再去扩展,各种模块是可插拔的。
- job plugin:ssh提供免密登陆,svc提供作业运行所需要的网络信息如host文件、headless service等,来提供计算集群参数的自动化配置。1.7版本提供了Pytorch Job强化功能插件
- policies字段:一旦有pod被杀死,重启还是算了?RestartJob/CompeletedJob。因为这种HPC场景、基于Gang的训练作业,如果一个worker运行失败,通常来说整个作业运行下去是没什么意义的。
- volcano 中代码做了优化,将很多实际操作的逻辑从 session 剥离到 statment 中。statement 支持Evict/Pipeline/Allocate/Discard/Commit,关键就是这个Discard/Commit,前面几个操作(都有两个对象的小写方法,正反向操作,比如allocate/unallocate)被调用时并没有真正执行,而是一起丢弃或提交,有点类似sql 中的事务。
留下评论