并发通信模型
前言
共享内存 vs 消息传递
如何理解 Golang 中“不要通过共享内存来通信,而应该通过通信来共享内存”? - 赵丙峰的回答 - 知乎
无论是共享内存还是消息,本质都是不同实体之间的如何协调信息,以达成某种一致。
- 直接共享内存基于的通讯协议由硬件和OS保证,这种保证是宽泛的,事实上可以完成任何事情,同样也带来管理的复杂和安全上的妥协。无锁数据结构和算法
- 消息是高级的接口,可以通过不同的消息定义和实现把大量的控制,安全,分流等相关的复杂细节封装在消息层,免除上层代码的负担。
所以,这里其实是增加了一层来解决共享内存存在的问题(比如基于CSP 模型的go channel 本质是一个有锁队列),实际上印证了另一句行业黑话:计算机科学领域所有的问题都可以通过增加一个额外的间接层来解决。PS:有点类似于招商模式的不同,共享内存就是给你块地自己搞,消息通信是除了地皮连厂房都建好了,找人过来上班就行。
然而其实还有另一句话:计算机可以领域大多数的性能问题都可以通过删除不必要的间接层来解决。不要误解这句话,这句话不过是说,针对领域问题的性能优化可以使用不同于通用问题的办法,因为通用的办法照顾的是大多数情况下的可用性而不是极端情况下的性能表现。诟病消息系统比共享内存性能差其实是一个伪问题。当二者都不存在的时候,自然共享内存实现直接而简单,成熟的消息系统则需要打磨并且设计不同情况下的策略。人们自然选择快而脏的共享内存。
然而,技术进步的意义就在于提供高层次的选择的灵活性。当二者都存在的时候,选择消息系统一般是好的,而且绝大多数的性能问题可以通过恰当的策略配置得以解决。针对遗留系统,则可以选择使用消息系统模拟共享内存。这种灵活性,是共享内存本身不具备的。
对这种编程哲学,golang提供语言层面的支持无疑是好的,可以推动良好设计的宣传和广泛使用。
如果程序设计成通过通信来共享数据的话,那么通信的两端是不是在同一个物理设备上就无所谓了,只有这样才能实现真正的分布式计算。
Actor 模型
《java并发编程实战》按照面向对象编程的理论,对象之间通信需要依靠消息,而实际上,像 C++、Java 这些面向对象的语言,对象之间通信,依靠的是对象方法。对象方法和过程语言里的函数本质上没有区别,那面向对象理论里的消息是否就等价于面向对象语言里的对象方法呢?很长一段时间里,我都以为对象方法是面向对象理论中消息的一种实现,直到接触到 Actor 模型,才明白消息压根不是这个实现法。在 Actor 模型中,Actor 是一个计算实体,具备以下特点:
- 消息传递:每个 Actor 都是独立的,它们通过异步消息传递进行通信。Actor 不会直接访问其他 Actor 的状态,而是通过发送消息来请求行为。
- 封闭的状态:每个 Actor 都有自己的私有状态,外部无法直接修改或访问这些状态。Actor 只能通过处理消息来改变自己的状态。
- 并发执行:多个 Actor 可以并行执行,每个 Actor 在其自己的线程或计算单元中独立运行,不同的 Actor 之间的消息传递通常是异步的。
- 行为:Actor 处理消息的方式是通过“行为”来定义的。当一个 Actor 接收到消息时,它会做出相应的反应,通常是:
- 发送消息给其他 Actor
- 改变自身的状态
- 创建新的 Actor 常见 Actor 实现:Erlang/Akka/Microsoft Orleans。特别适用于分布式和并行系统的开发。
Actor 模型本质上是一种计算模型,基本的计算单元称为 Actor,换言之,在 Actor 模型中,所有的计算都是在 Actor 中执行的。在面向对象编程里面,一切都是对象;在 Actor 模型里,一切都是 Actor,并且 Actor 之间是完全隔离的,不会共享任何变量。但是 Java 语言本身并不支持 Actor 模型,需要借助第三方类库,目前能完备地支持 Actor 模型而且比较成熟的类库就是 Akka了,先基于 Akka 写一个 Hello World 程序
//该Actor当收到消息message后,会打印Hello message
static class HelloActor extends UntypedActor {
@Override
public void onReceive(Object message) {
System.out.println("Hello " + message);
}
}
public static void main(String[] args) {
//创建Actor系统
ActorSystem system = ActorSystem.create("HelloSystem");
//创建HelloActor
ActorRef helloActor = system.actorOf(Props.create(HelloActor.class));
//发送消息给HelloActor
helloActor.tell("Actor", ActorRef.noSender());
}
首先创建了一个 ActorSystem(Actor 不能脱离 ActorSystem 存在);之后创建了一个 HelloActor,Akka 中创建 Actor 并不是 new 一个对象出来,而是通过调用 system.actorOf() 方法创建的,该方法返回的是 ActorRef,而不是 HelloActor;最后通过调用 ActorRef 的 tell() 方法给 HelloActor 发送了一条消息 “Actor”。
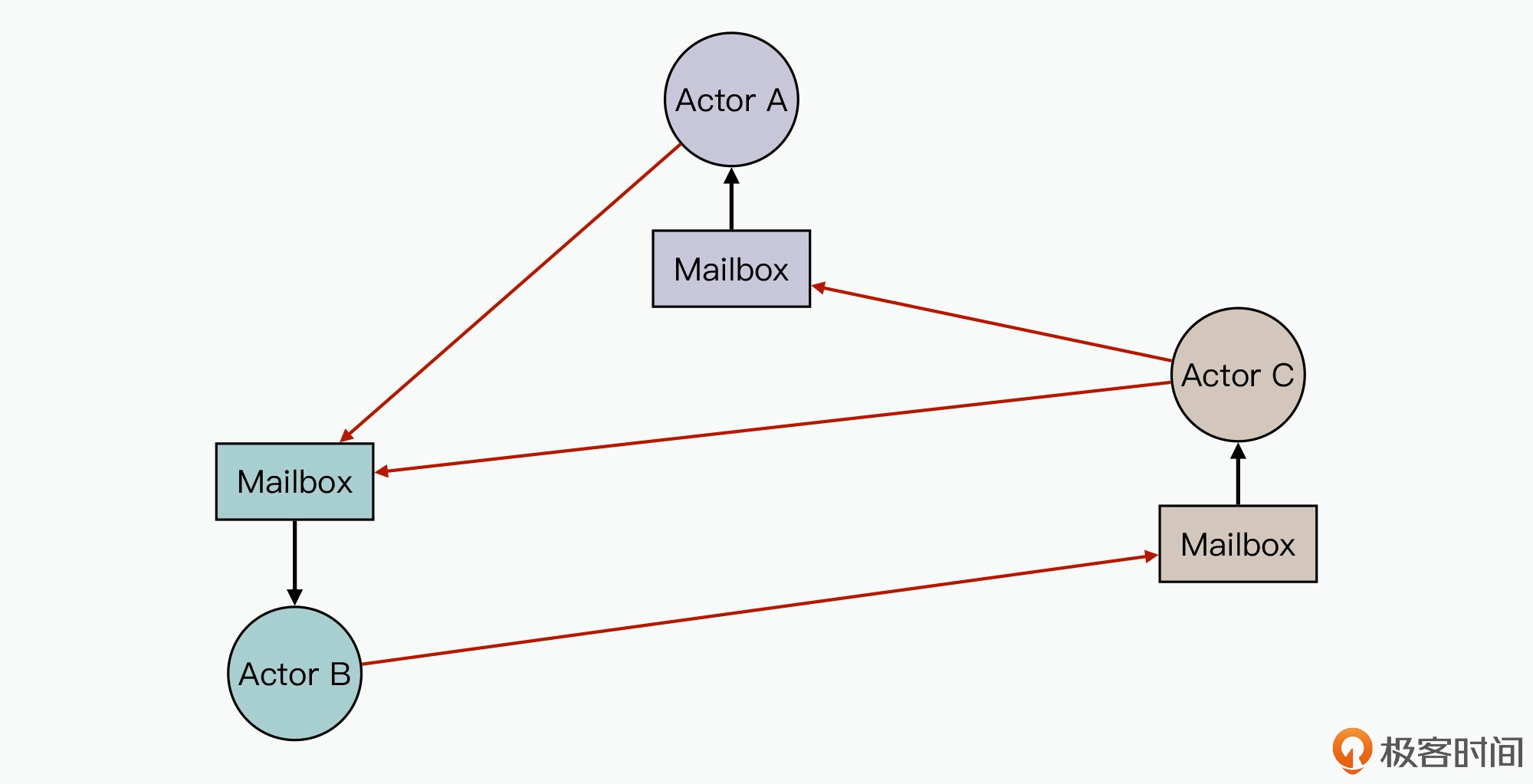
Actor 中的消息机制,就可以类比这现实世界里的写信。Actor 内部有一个邮箱(Mailbox),接收到的消息都是先放到邮箱里,如果邮箱里有积压的消息,那么新收到的消息就不会马上得到处理,也正是因为 Actor 使用单线程处理消息,所以不会出现并发问题。采用基于 Actor 模型的 Akka 框架,在开发实现软件时,你就不需要关注底层的并发交互同步了(天然避免了在消息交互中需要解决的数据一致性的问题),只需要聚焦到业务中设计每个 Actor 实现的业务逻辑,它需要接收什么消息,又需要向谁发送什么消息。在实际的业务开发中要注意,如果在使用 Actor 时,没有利用好 Actor 轻量级的特性,开发出来的 Actor 承载的业务逻辑太多,导致 Actor 的任务粒度过大 或IO 密集型业务,那么就很难发挥出 Actor 的最佳性能表现。
| 区别 | 消息 | 对象方法 |
|---|---|---|
| 同步异步 | 发送消息仅仅是把消息发出去而已,接收消息的 Actor 在接收到消息后,也不一定会立即处理, 也就是说 Actor 中的消息机制完全是异步的 |
实际上是同步的,对象方法 return 之前,调用方会一直等待 |
| 收发双方位置 | 发送消息类似于现实中的写信,只需要知道对方的地址就可以, 发送消息和接收消息的 Actor 可以不在一个进程中,也可以不在同一台机器上 |
调用对象方法,需要持有对象的引用,所有的对象必须在同一个进程中 |
Actor 可以创建新的 Actor,这些 Actor 最终会呈现出一个树状结构,非常像现实世界里的组织结构,所以利用 Actor 模型来对程序进行建模,和现实世界的匹配度非常高。
CSP 模型
Joe Armstrong的博士论文《面对软件错误构建可靠的分布式系统》,文中提到“在构建可容错软件系统的过程中要解决的本质问题就是故障隔离。”操作系统进程本身就是一种天然的故障隔离机制,当然从另一个层面,进程间还是因为共享cpu和内存等原因相互影响。进程要想达到容错性,就不能与其他进程有共享状态;它与其他进程的唯一联系就是由内核消息系统传递的消息。
Tony Hoare提出的 CSP(Communicationing Sequential Processes,通信顺序进程)并发模型。在 Tony Hoare 眼中,一个符合 CSP 模型的并发程序应该是一组通过输入输出原语连接起来的 P 的集合。从这个角度来看,CSP 理论不仅是一个并发参考模型,也是一种并发程序的程序组织方法。
Golang 中协程之间通信推荐的是使用 channel,channel 你可以形象地理解为现实世界里的管道。需要注意的是 Golang 中 channel 的容量可以是 0,容量为 0 的 channel 在 Golang 中被称为无缓冲的 channel,容量大于 0 的则被称为有缓冲的 channel。无缓冲的 channel 类似于 Java 中提供的 SynchronousQueue
func main() {
// 变量声明
var result, i uint64
// 4个协程共同执行累加操作
start = time.Now()
ch1 := calc(1, 2500000000)
ch2 := calc(2500000001, 5000000000)
ch3 := calc(5000000001, 7500000000)
ch4 := calc(7500000001, 10000000000)
// 汇总4个协程的累加结果
result = <-ch1 + <-ch2 + <-ch3 + <-ch4
// 统计计算耗时
elapsed = time.Since(start)
fmt.Printf("执行消耗的时间为:", elapsed)
fmt.Println(", result:", result)
}
Golang 中的 channel 是语言层面支持的,所以可以使用一个左向箭头(<-)来完成向 channel 发送数据和读取数据的任务,使用上还是比较简单的。
| 区别 | Actor | CSP |
|---|---|---|
| 通道可见性 | Actor 之间是可以直接通信的,不需要通信中介 | channel是通信的中介 |
| 通道可见性 | Actor 模型中的 mailbox 对于程序员来说是“透明”的, mailbox 明确归属于一个特定的 Actor,是 Actor 模型中的内部机制 |
channel 对于程序员来说是“可见”的 |
| 发送消息 | 非阻塞的 | 阻塞的 |
| 消息送达 | 理论上不保证消息百分百送达 | 能保证消息百分百送达的 |
Java 领域可以借助第三方的类库JCSP来支持 CSP 模型,相比 Golang 的实现,JCSP 更接近理论模型,不过JCSP 并没有经过广泛的生产环境检验。
STM
很多编程语言都有从数据库的事务管理中获得灵感,并且总结出了一个新的并发解决方案:软件事务内存(Software Transactional Memory,简称 STM)。传统的数据库事务,支持 4 个特性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability),也就是大家常说的 ACID,STM 由于不涉及到持久化,所以只支持 ACI。
class UnsafeAccount {
//余额
private long balance;
//构造函数
public UnsafeAccount(long balance) {
this.balance = balance;
}
//转账
void transfer(UnsafeAccount target, long amt){
if (this.balance > amt) {
this.balance -= amt;
target.balance += amt;
}
}
}
Java 语言并不支持 STM,不过可以借助第三方的类库来支持,Multiverse就是个不错的选择。下面的示例代码就是借助 Multiverse 实现了线程安全的转账操作
class Account{
//余额
private TxnLong balance;
//构造函数
public Account(long balance){
this.balance = StmUtils.newTxnLong(balance);
}
//转账
public void transfer(Account to, int amt){
//原子化操作
atomic(()->{
if (this.balance.get() > amt) {
this.balance.decrement(amt);
to.balance.increment(amt);
}
});
}
}
一个关键的 atomic() 方法就把并发问题解决了,那它是如何实现的呢?数据库事务发展了几十年了,目前被广泛使用的是 MVCC(全称是 Multi-Version Concurrency Control),也就是多版本并发控制。
MVCC 可以简单地理解为数据库事务在开启的时候,会给数据库打一个快照,以后所有的读写都是基于这个快照的。当提交事务的时候,如果所有读写过的数据在该事务执行期间没有发生过变化,那么就可以提交;如果发生了变化,说明该事务和有其他事务读写的数据冲突了,这个时候是不可以提交的。为了记录数据是否发生了变化,可以给每条数据增加一个版本号,这样每次成功修改数据都会增加版本号的值。MVCC 的工作原理和乐观锁非常相似。有不少 STM 的实现方案都是基于 MVCC 的,例如知名的 Clojure STM。
留下评论