大模型rl后训练系统
简介(未完成)
什么是理想中的大模型强化学习后训练系统? 未读。是一个系列,对来龙去脉讲的比较多。
强化学习训练使用的数据集是由模型推理产生,或模型推理产生+人工标注产生。如果把训练任务和生成数据集的推理任务部署在同一集群上,自然部署难度和调度难度都是比较低的,但会存在以下几个问题:
- 训练和推理两个阶段的优化思路是完全不同的,两个阶段耦合在一起优化难度极大且会相互影响
- 训练和推理对硬件的需求不同,无法通过异构硬件部署的形式提升性价比
- 训练或推理各自过程中如出现异常,则会影响到对方环节。
还是同样的思路,如果把两个阶段解耦开来独立优化(PS:类似推理的 pd分离 ==> afd分离),便比较容易的解决上述的几个问题。但是在训推分离的实践中,又会出现两个新的问题:
- 推理的输出可能经过agent复杂的处理逻辑,比如和记忆有关
- 训练和推理流程间的时序依赖关系,很容易造成“气泡”式的算力资源浪费
未命名
OpenRLHF OpenRLHF源码解读:1.理解PPO单机训练
阿里PAI-ChatLearn:大规模 Alignment高效训练框架正式开源 未细读
【AI Infra】【RLHF框架】四、VeRL中PPO、GRPO、REINFORCE++、RLOO实现源码解析 未读
verl RL支持训练deepseek-v3 671B实习复盘
- 上下游对接任务。与传统的单纯训练与推理流程相比,强化学习(RL)的训练框架具有明显的异构性。一方面,它需要借助推理框架对 prompt 进行 rollout;另一方面,还需依赖训练框架完成 log 计算与梯度更新。这种双重依赖意味着整个任务流程需要协调至少两个不同系统,显著增加了系统集成与工程实现的复杂度。在具体实现中,目前主流的训练框架包括 FSDP 和 Megatron/DeepSpeed,推理框架则有vLLM、SGLang等可选。
- 框架特性支持。假如每位开发者都拥有 1024 张 GPU 卡,那么成功运行一个671B的模型并非难事。只需按照 DeepSeek 论文中提供的并行配置,或参考NV实践过的脚本,即可较为顺利地完成部署。然而在大多数实际场景中,可用的资源往往没有这么多。因此,为了尽可能在资源受限的条件下完成训练任务,就必须将更多节省显存的特性集成到verl的训练流程中。这些功能的支持也可分为训练侧与推理侧两个部分。
- 在训练侧,配置训练框架的 offload 机制和参数
- 在推理侧,显存占用主要来源于模型参数与KV cache。 综上所述,verl的开发难点并不完全在于其自身框架的实现,而在于必须确保上下游训练与推理框架能够提供完善的接口支持,才能使 verl 更高效地解决训练过程中面临的实际问题。
- 模型权重转换。
- verl的模型加载是从训练框架侧加载的。对于checkpoint加载和存储来说,一般fsdp的框架可以基于huggingface的模型直接加载。但是对于Megatron来说,它的模型必须要来源于Megatron本身的模型结构。这也就表明如果我们想跑671B的模型,那么就需要首先将huggingface上671B的模型转换为Megatron可以加载的形式。
- 从训练框架和推理框架之间的权重转换,是RL场景下特有的训练阶段。在verl的具体流程中,训练过程中需要先使用推理框架进行相关推理。然后当获得prompt+response的结果之后,再将这些模型权重切换到训练框架中。我们知道权重实际上是以字典的形式进行存储的,kv的结构分别是
{name,tensor}。但是由于Megatron和vllm&sglang之间对于权重的key命名并不相同。这也就导致我们在切换的时候实际上是需要对两边进行一个reshard的操作,并且也有许多需要解决的问题。
- 模型精度对齐。在实践的过程中往往会因为框架之间内部存在一些对齐问题,为了验证新开发特性的有效性,一般的开发中都需要先进行精度对齐的操作,就是先用一个已经确认是准确的框架,跑一遍相关算法,然后再使用我们开发的版本去再跑一次,以保证精度上的对齐。
- 模型效率问题。所以对于DeepSeek这种moe的模型来说,在训练框架&推理框架中加入对于专家并行的支持,或者容纳更多的并行策略,都是比较重要的事情。虽然我们也知道在训练框架或者是推理框架中,针对模型效率提高有着非常多的技巧。例如在训练框架中使用多种并行方式或者overlap操作。在推理侧使用多种并行策略,pd分离,ep并行等。那如何将他们有效地包含在verl的框架中,使得这些不同的策略能够朝一致的方向去提高模型的效率也是需要探索的。简单的例子,在不同的环境和训练模型下:
- 在训练侧,机内的TP可能比PP好,机内的EP也可能比TP好
- 推理侧,有时候跨机TP可能比TP+PP效率来的高,有的时候PD分离往往不如不用PD分离等…即便最后verl成功的将671B模型成功跑起来,我们的并行策略搭配也不一定就是最高效的。模型的训练效率优化,一定是一个需要花费大量时间去探索的事情
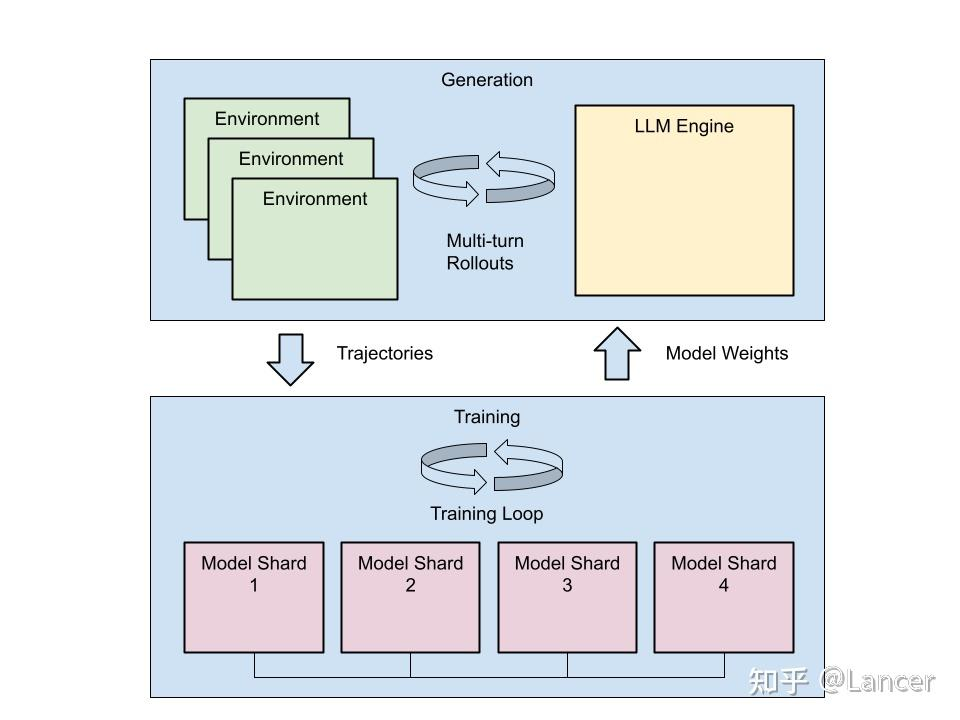
未知
parallelism
标准训练流程包含三个核心环节:
- 模型forward,计算loss,保存中间激活值
- 模型backward,通过中间激活值计算gradient
- 模型update,把gradient传给optimizer,更新模型weight。
模型不大的情况下,在step1和step2都不需要做通信,也就是每张卡算自己loss和gradient即可,并不会有什么影响。而在step3之前,我们需要把各卡的梯度放在一起求平均,保证得到正确的完整bs的梯度,而这个操作也就是all-reduce通信。
我们简单地把模型看成是Y=XW的矩阵乘法。将模型抽象为Y=XW的矩阵运算时,参数切分存在两种基本策略:
- 输入切分(X维度):对应Data Parallel/Sequence Parallel
- 权重切分(W维度):对应Tensor Parallel/Pipeline Parallel/Expert Parallel
切分X要比切分W简单的多。因为我们的模型输入往往是一个或多个规整的tensor,在batch维度可以很容易地做切分。而切分W就要头疼得多了,一旦出现诸如诸如卷积这种非典型矩阵计算,或者unet这种前后复杂的依赖关系,都要经过精心设计才行。在目前这种朴素的data parallel策略下,每块卡都拥有完整的model weight/gradient/optimizer,尺寸和单卡训练无异。而deepspeed使用的zero stage即是对这部分显存占用的优化。
- zero1中,每张卡只需要保留1/n的optimizer参数,通信量保持不变
- zero2在zero1的基础上,每张卡只需要保留1/n的graident,通信量保持不变
- zero3在zero2的基础上,每张卡只需要保留1/n的model weight,通信量变为1.5倍。
其中,zero1和zero2影响的分别是optimizer和graident,对应的是后两步,并没有影响forward部分
而Zero3模式下的训练流程演进为:
- Forward阶段:all-gather获取完整参数→计算loss→释放参数→保存中间激活
- Backward阶段:all-gather获取完整参数→计算梯度→释放参数
- Update阶段:reduce-scatter获取梯度切片→优化器更新局部参数”
要注意的是,zero123本质仍然属于data parallel,不属于model parallel的范畴,尽管zero3看起来做了模型参数的切分,但实际上计算时会先做all gather得到完整的模型参数,计算时使用的也是完整的参数和切分后的输入。
- 对比tp/pp,它们从头到尾都只存模型参数的一部分,计算时使用的是切分后的参数和完整的输入。
- 对于dp,通信的是模型参数,也就是W和它对应的weight/optimizer
- 对于tp/pp,通信的是中间激活值,例如PP需要将上一个rank计算得到的中间结果传给下一个rank继续计算。
SPMD(Single Program, Multiple Data) 编程范式
在典型的多卡训练场景中(如使用torchrun或accelerate launch),通过nvidia-smi可观察到每块GPU对应独立进程,这种模式本质源于SPMD(Single Program Multiple Data)架构。那么问题来了,是torchrun之类的启动脚本把它们“分配”到每张卡上的吗?实际上并不是。主流并行框架(DDP/DeepSpeed/Megatron)均基于SPMD范式:所有进程执行相同代码逻辑,通过环境变量差异自主确定行为模式,无需中心调度节点。一段经典的PyTorch分布式训练初始化的代码
import torch
import os
print(os.environ['RANK'], os.environ['WORLD_SIZE'], os.environ['MASTER_ADDR'], os.environ['MASTER_PORT'])
torch.distributed.init_process_group(backend="nccl")
torch.cuda.set_device(torch.distributed.get_rank())
当我们使用torchrun启动这段代码后,会启动多个进程,每个进程有着不同的环境变量,标识它们属于哪一台机器和端口,是第几个进程和进程总数。之后torch.distributed.init_process_group会根据这些环境变量构建通信组,这是一个阻塞操作,所有进程都要完成init_process_group后才会继续往下走。最后set_device将当前进程绑定到一块gpu上,对于RANK=0的进程绑定在0号卡,RANK=1的进程绑定在1号卡,以此类推,不存在一个进程去调度安排它们的行为,它们运行的是完全相同的代码,只是用不同的rank区分开他们的行为。以naive dp为例,会发现在训练过程中并不存在各个dp rank之间对齐参数的行为,这是因为只要保证各个rank初始化时的模型参数保持一致,之后每个step的gradient一致,从而optimizer对模型参数的更新是一致的,自然每个rank的模型就是一致的。这也就引出了一个问题,SPMD的编程模式心智负担较重,相信写过Megatron的朋友都有感受,当逻辑复杂以后要考虑不同rank之间的不同行为和通信,以及避免corner case造成的stuck,一写一个不吱声,都是容易掉头发的环节。总结来说,SPMD由于没有中心控制器,在运行时更为高效,完全由worker自驱。但由于在编程模式上需要各worker运行相同的程序(根据rank领取自己的weights和data,自己算自己的部分,到点了通信一下就好了,不需要调度),灵活性不如single-controller模式。
SPMD是分布式训练的“灵魂”。无论是 DDP(分布式数据并行)、TP(张量并行)还是 PP(流水线并行),在底层逻辑上都遵循 SPMD。写一份 Python 脚本,然后用 torchrun启动x个进程,这就是 SPMD。
FSDP(Fully Sharded Data Parallelism )
FSDP是一种具体的数据并行技术,核心思想,将模型参数(权重、优化器状态等)在所有GPU之间分片存储,计算时,仅当某个GPU需要其他GPU上的参数时才进行通信,并且还进行了计算通信重叠的优化;
DeepSpeed的ZeRO零冗余优化器便是一种手段。它一共分为三个等级,stage-1, stage-2和stage-3,分别逐级地将优化器状态量(Optimizer states)、梯度(Gradient)和模型参数(Model Parameter)划分到不同的GPU上,以降低单张GPU的显存压力。ZeRO在stage-1和stage-2上还是比较有效的,能以较小的通信代价换取到很划算的显存降低,毕竟优化器状态量和梯度只需要在参数更新那一步去做all-reduce的收集。但是一旦model更大,stage-2的划分也装不下了的时候,开启stage-3会严重拖慢训练的速度。原因是一旦将模型参数也切分到不同GPU上,那么模型的前向、后向的计算过程也需要引入大量的通信。虽然有很多的技术能够尽可能地减少这部分的overhead,但可惜ZeRO-3在速度优化上做得还不是很好。与之相对应地,Pytorch自身其实也有他们自己的一版ZeRO-3——FSDP(Fully Shared Data Parallel)。FSDP就是在Data Parallel基础上,当model很大时,将model也完全地分块(Fully Shared),同时做数据并行,整体的思路和ZeRO-3是一样的,但优化上做得比ZeRO-3要更好。
训练框架和推理引擎的拼接
RL训练框架的难点在于缝合,很考验框架作者对各种系统,业务的理解。
训练框架和推理引擎之间最核心的是训练数据和模型参数的通信。
Ray也来插一脚
传统的ai infra 是训练文件读写hdfs,各个进程跑一样代码(SPMD),参数文件process_group(nccl)通信,那用了ray 之后,有啥不同呢?或哪方面更优呢?当然,多进程/实例只能靠torch.distributed.barrier 来同步确实效率低。
把actor/ref/reward/critic模型都放一张卡上就是colocate。但7B模型训练单卡都塞不下,1000B的模型下半年预计也会开源好几个,并行带来的开销是很夸张的。现在reward模型也普遍不大,7-30B就满足要求,模型size也有差异,分开部署性价比更高。但分开部署的硬编码就相对麻烦了,于是大家引入了ray(写本地代码,跑分布式任务,声明你要什么资源,而不是操心资源在哪里;天然异步,数据自动流转)。
Ray 是一个分布式计算框架,现在流行的RL框架如VeRL和OpenRLHF都依托Ray管理RL中复杂的Roles(比如PPO需要四个模型)和分配资源。以下是一些核心的概念:
- Ray Actor:有状态的远程计算任务,一般是被ray.remote装饰器装饰的Python类,运行时是一个进程(和PPO等Actor-Critic算法的Actor不要混淆了);
- Ray Task:无状态的远程计算任务,一般是被ray.remote装饰器装饰的Python函数,创建的局部变量仅在当前可见,对于任务的提交者不可见,因此可以视作无状态;
- 资源管理:Ray可以自动管理CPU、GPU、Mem等资源的分配(通过ray.remote装饰器或者启动的options参数可以指定指定的ray actor所需的计算资源),并且还可以设计资源组(placement group),将不同的ray actor指定放置在相同或者不同的资源位置(bundle); 通过使用ray,verl可以方便地实现各种角色、各种并行策略的资源分配,并且实现hybrid engine等colocate策略;
- 异步执行:ray的计算是异步的,一般执行一个ray的计算任务后,ray会立刻返回任务的执行句柄Object reference,用户的代码不会阻塞,可以自行使用ray.get/ray.wait进行阻塞式/轮询式的结果获取;
- PS: 在RL训练中引入异步的概念,可以方便actor/critic/generator/rm之间互相overlap掉一些处理时间(比如actor在更新上一个batch的时候,generator已经可以生成下一个batch了)。由于o1-liked rl的主要时间卡点在rollout位置,因此将rollout 更好地aynsc化(例如充分利用线上serving集群的夜晚空闲时间)是未来 rl infra优化的方向之一;
用于传统Pytorch DP训练
传统 PyTorch DDP通常需要通过 torchrun 启动,并在代码中手动处理 rank、world_size 以及设备的绑定。
import torch
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def train():
# 1. 手动初始化进程组
dist.init_process_group(backend="nccl")
local_rank = int(os.environ["LOCAL_RANK"])
torch.cuda.set_device(local_rank)
# 2. 包装模型
model = MyModel().to(local_rank)
model = DDP(model, device_ids=[local_rank])
# 3. 手动处理 DataSampler
sampler = torch.utils.data.DistributedSampler(dataset)
loader = DataLoader(dataset, sampler=sampler)
for data, target in loader:
# 训练逻辑...
pass
dist.destroy_process_group()
# 启动命令: torchrun --nproc_per_node=4 train.py
Ray Train,引入 Ray 后训练逻辑被封装在一个普通函数中,通过 TorchTrainer 进行分发,代码更接近单机写法。
import ray.train.torch
from ray.train.torch import TorchTrainer
from ray.train import ScalingConfig
def train_func(config):
# 1. 自动处理分布式环境(替代 init_process_group)
model = MyModel()
model = ray.train.torch.prepare_model(model)
# 2. 自动处理 DataSampler 转换
loader = DataLoader(dataset)
loader = ray.train.torch.prepare_data_loader(loader)
for data, target in loader:
# 训练逻辑...
ray.train.report({"loss": loss.item()}) # 自动收集指标
# 3. 配置与启动(无需命令行控制进程数)
scaling_config = ScalingConfig(num_workers=4, use_gpu=True)
trainer = TorchTrainer(train_func, scaling_config=scaling_config)
result = trainer.fit()
ray TorchTrainer 真实对标的是pytorch torchrun,如果把 torchrun 比作一个**“启动器”(或者说是一个运维脚本),那么 Ray TorchTrainer 就是一个“托管式操作系统”,把分布式训练变成了一个可编程的 API 逻辑。比如你只需声明 num_workers=4,Ray 会自动在集群中找到最合适的 4 张空闲显卡,哪怕它们跨越了物理节点。
| 功能环节 | torchrun (传统方式) | Ray TorchTrainer (Ray方式) |
|---|---|---|
| 进程拉起 | 依靠Shell 命令在每台机器上手动/脚本执行 | 依靠 Ray RPC 协议在集群内自动远程创建 Actor |
| 环境变量 | 自动注入RANK/WORLD_SIZE/MASTER_ADDR |
同样注入这些变量,但由 Ray Actor 内部环境管理 |
| 节点发现 | 依赖静态 IP 或共享存储进行 Rendezvous | 依赖 Ray GCS(全局状态服务)进行服务发现 |
| 失败重启 | 本地进程挂了自动重启(有限容错) | 跨机器自动重启,支持从 Checkpoint 自动恢复 |
| 日志收集 | 各个进程日志散落在不同机器/文件 | 统一聚合到驱动端(Driver)控制台输出 |
用于LLM训练
# ====== 定义 Actor ======
@ray.remote( # 声明这个 Actor需要什么资源——几张卡、什么型号、跑在哪台机器上。而不是直接指定卡号。
num_gpus=4, # 需要 4 张 GPU
accelerator_type="H100", # 指定 H100 卡
resources={"node:192.168.1.10": 1} # 指定运行在这个节点上
)
class Trainer: # 类的实现本身就是普通的 Python 代码,没有任何分布式的痕迹
def train(self):
# Training step
...
def get_weights(self):
return self.model.state_dict()
@ray.remote(
num_gpus=8, # 需要 8 张 GPU
accelerator_type="B200", # 指定 B200 卡
resources={"node:192.168.1.20": 1} # 指定另一个节点
)
class Generator:
def generate(self):
# Generate rollouts
...
def set_weights(self, weights):
# Set weights
...
# ====== 使用 Actor ======
# 创建 Actor 实例,Ray 自动调度到指定节点
# 调用方不需要知道 Trainer/Generator 跑在哪个节点,权重同步也只是一行代码,数据会在节点间自动流转,调用方完全不用操心
trainer = Trainer.remote()
generator = Generator.remote()
while True:
# Train
trainer.train.remote()
# Synchronize weights
ref = trainer.get_weights.remote()
generator.set_weights.remote(ref)
# Rollouts
generator.generate.remote()
留下评论