tensorflow分布式训练
简介
基本思路是:先搞明白 tf 训练的整体设计(client-master-worker),知道Low-level的分布式训练代码如何写,Strategy 如何屏蔽不同训练策略的代码差异,Estimator 如何基于 Strategy 做进一步封装,最终做到训练代码与单机/分布式/并行策略无关。
基本概念
服务
- client 是访问服务的部分
- master是用来维护参数或者数据初始化的
- worker是用来执行具体任务的
- chief,集群中一般有多个worker,需要指定其中一个worker为主节点(cheif,默认worker0),chief节点会执行一些额外的工作,比如模型导出之类的。
客户端(client)进程负责构建计算图(graph),创建 tensorflow::Session 实例。客户端一般由 Python 或 C++ 编写。当客户端调用 Session.run() 时将向主进程(master)发送请求,主进程会选择特定工作进程(worker)完成实际计算。客户端、主进程和工作进程可以位于同一台机器实现本地计算,也可以位于不同机器即分布式计算。主进程和工作进程的集合称为服务端(server),一个客户端可以同多个服务端交互。服务端进程会创建 tf.train.Server 实例并持续运行。client 与 server 之间以 grpc 通信。
在每一台机器上起一个tf.train.Server的服务,然后放在一个集群里,整个集群的server会通过网络通信。
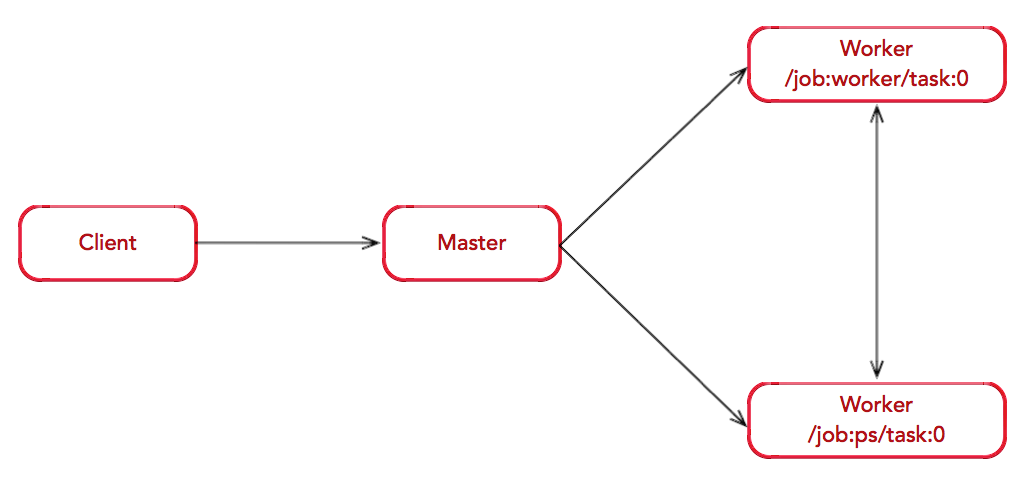
每个Server上会绑定两个Service,就是前面提到的Master Service和Worker Service,Client通过Session连接集群中的任意一个Server的Master Service提交计算图,Master Service负责划分子图并派发Task给Worker Service,Worker Service则负责运算派发过来的Task完成子图的运算。
进程
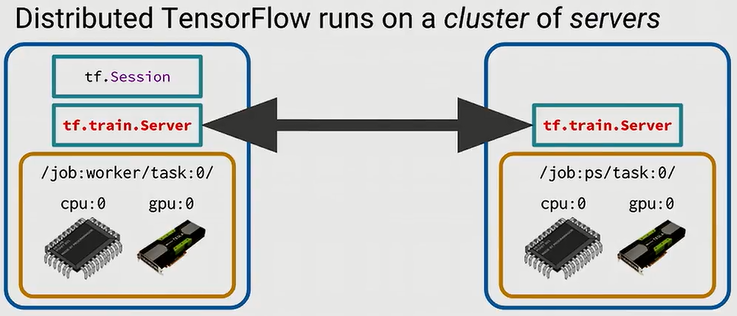
在分布式TensorFlow中,参与分布式系统的所有节点或者设备统称为一个Cluster,一个Cluster中包含很多Server,每个Server去执行一项Task,Server和Task是一一对应的。所以,Cluster可以看成是Server的集合,也可以看成是Task的集合,TensorFlow为各个Task又增加了一个抽象层,将一系列相似的Task集合称为一个Job。形式化地,一个TensorFlow Cluster可以通过以下json来描述:
tf.train.ClusterSpec({
"worker": [
"10.244.2.141:2222",
"10.244.2.142:2222",
],
"ps": [
"10.244.2.140:2222",
]
})
job用job_name(字符串)标识, “ps” 及 “worker” 为 job_name。而task用index(整数索引)标识,那么cluster中的每个task可以用job的name加上task的index来唯一标识,例如/job:worker/task:1。可以通过脚本或者借助调度框架来动态构建 ClusterSpec。
编程模型
Low-level 分布式编程模型
针对以下cluster 配置
tf.train.ClusterSpec({
"worker": [
"10.244.2.141:2222",
"10.244.2.142:2222",
],
"ps": [
"10.244.2.140:2222",
]
})
在第一个worker解释器内执行如下语句启动Server:
server = tf.train.Server(cluster, job_name="worker", task_index=0)
在第二个worker解释器内执行如下语句启动Server:
server = tf.train.Server(cluster, job_name="worker", task_index=1)
在ps解释器内执行如下语句启动Server:
server = tf.train.Server(cluster, job_name="ps", task_index=0)
至此,我们已经启动了一个TensorFlow Cluster,它由两个worker节点和一个ps节点组成,每个节点上都有Master Service和Worker Service,其中worker节点上的Worker Service将负责梯度运算,ps节点上的Worker Service将负责参数更新,三个Master Service将仅有一个会在需要时被用到,负责子图划分与Task派发。PS: 这是与spark 不同的地方,spark 的后台服务是事先启动好的。
有了Cluster,我们就可以编写Client,构建计算图,并提交到这个Cluster上执行。使用分布式TensorFlow时,最常采用的分布式训练策略是数据并行,数据并行就是在很多设备上放置相同的模型,在TensorFlow中称之为Replicated training,主要表现为两种模式:图内复制(in-graph replication)和图间复制(between-graph replication)。不同的运行模式,Client的表现形式不一样。
对于图内复制,只构建一个Client,这个Client构建一个Graph,Graph中包含一套模型参数,放置在ps上,同时Graph中包含模型计算部分的多个副本,每个副本都放置在一个worker上,这样多个worker可以同时训练复制的模型。再开一个Python解释器,作为Client,执行如下语句构建计算图,并:
import tensorflow as tf
with tf.device("/job:ps/task:0"):
w = tf.get_variable([[1., 2., 3.], [1., 3., 5.]])
input_data = ...
inputs = tf.split(input_data, num_workers)
outputs = []
for i in range(num_workers):
with tf.device("/job:ps/task:%s" % str(i)):
outputs.append(tf.matmul(inputs[i], w))
output = tf.concat(outputs, axis=0)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print sess.run(output)
从以上代码可以看到,当采用图内复制时,需要在Client上创建一个包含所有worker副本的流程图,随着worker数量的增长,计算图将会变得非常大,不利于计算图的维护。此外,数据分发在Client单点,要把训练数据分发到不同的机器上(with tf.device(...)),会严重影响并发训练速度。所以在大规模分布式多机训练情况下,一般不会采用图内复制的模式,该模式常用于单机多卡情况下,简单直接。
对于图间复制,每个worker节点上都创建一个Client,各个Client构建相同的Graph,但是参数还是放置在ps上,每个worker节点单独运算,一个worker节点挂掉了,系统还可以继续跑。所以我们在第一个worker和第二个worker的Python解释器里继续执行如下语句实现Client完成整个分布式TensorFlow的运行:
with tf.device("/job:ps/task:0"):
w = tf.get_variable(name='w', shape=[784, 10])
b = tf.get_variable(name='b', shape=[10])
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.int32, shape=[None])
logits = tf.matmul(x, w) + b
loss = ...
train_op = ...
with tf.Session() as sess:
for _ in range(10000):
sess.run(train_op, feed_dict=...)
在上述描述的过程中,我们是全程手动做分布式驱动的,先建立Cluster,然后构建计算图提交执行,Server上的Master Service和Worker Service根本没有用到。实际应用时当然不会这么愚蠢,一般是将以上代码片段放到一个文件中,通过参数控制执行不同的代码片段,例如:
import tensorflow as tf
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# 启动 ps 或worker
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
if FLAGS.job_name == 'ps':
server.join()
elif FLAGS.job_name == "worker":
# 开始扮演 Client
with tf.device(tf.train.replica_device_setter(worker_device="/job:worker/task:%d" % FLAGS.task_index,cluster=cluster)):
# Build model...
loss = ...
train_op = ...
with tf.train.MonitoredTrainingSession(master="/job:worker/task:0",is_chief=(FLAGS.task_index == 0),checkpoint_dir="/tmp/train_logs") as mon_sess:
while not mon_sess.should_stop():
mon_sess.run(train_op)
每个节点上都执行如上代码,只是不同节点输入的参数不一样,对于ps节点,启动Server后就堵塞等待参数服务,对于worker节点,启动Server后(后台服务),开始扮演Client,构建计算图,最后通过Session提交计算。注意在调用Session.run之前,仅仅是Client的构图,并未开始计算,各节点上的Server还未发挥作用,只有在调用Session.run后,worker和ps节点才会被派发Task。在调用Session.run时,需要给Session传递target参数,指定使用哪个worker节点上的Master Service,Client将构建的计算图发给target指定的Master Service,一个TensorFlow集群中只有一个Master Service在工作,它负责子图划分、Task的分发以及模型保存与恢复等,在子图划分时,它会自动将模型参数分发到ps节点,将梯度计算分发到worker节点。另外,在Client构图时通过tf.train.replica_device_setter告诉worker节点默认在本机分配Op,这样每个Worker Service收到计算任务后构建出一个单独的计算子图副本,这样每个worker节点就可以单独运行,挂了不影响其他worker节点继续运行。
虽然图间复制具有较好的扩展性,但是从以上代码可以看到,写一个分布式TensorFlow应用,需要用户自行控制不同组件的运行,这就需要用户对TensorFlow的分布式架构有较深的理解。另外,分布式TensorFlow应用与单机版TensorFlow应用的代码是两套,一般使用过程中,用户都是先在单机上调试好基本逻辑,然后再部署到集群,在部署分布式TensorFlow应用前,就需要将前面的单机版代码改写成分布式多机版,用户体验非常差。所以说,使用Low-level 分布式编程模型,不能做到一套代码既可以在单机上运行也可以在分布式多机上运行,其用户门槛较高,一度被相关工程及研究人员诟病。为此,TensorFlow推出了High-level分布式编程模型,极大地改善用户易用性。
High-level 分布式编程模型
TensorFlow提供Estimator和Dataset高阶API,简化模型构建以及数据输入,用户通过Estimator和Dataset高阶API编写TensorFlow应用,不用了解TensorFlow内部实现细节,只需关注模型本身即可。
使用Estimator编写完应用后,可以直接单机上运行,如果需要将其部署到分布式环境运行,则需要在每个节点执行代码前设置集群的TF_CONFIG环境变量(实际应用时通常借助资源调度平台自动完成,如K8S,不需要修改TensorFlow应用程序代码)。TF_CONFIG环境变量是一个json字符串,指定集群规格cluster以及节点自身的角色task,cluster包括chief、worker、ps节点,chief节点其实是一个特殊的worker节点,而且只能有一个节点,表示分布式TensorFlow Master Service所在的节点。
通过以上描述可以看到,使用高阶API编写分布式TensorFlow应用已经很方便了,然而因为PS架构的缘故,我们实际部署时,需要规划使用多少个ps,多少个worker,那么调试过程中,需要反复调整ps和worker的数量。当模型规模较大时,在分布式训练过程中,ps可能成为网络瓶颈,因为所有worker都需要从ps处更新/获取参数,如果ps节点网络被打满,那么worker节点可能就会堵塞等待,以至于其计算能力就发挥不出来。所以后面TensorFlow引入All-Reduce架构解决这类问题。PS: ps-worker跨机通信是通过 gRPC + Protocol Buffers 实现的,这种方案的问题是,首先 gRPC 本身的效率就比较差,其次使用 Protocol Buffers 序列化就意味着节点间的所有交互必须经过内存,无法使用 GPUDirect RDMA,限制了速度提升。通常情况下,同步训练通过全归约(all-reduce)实现,而异步训练通过参数服务器架构实现。
TensorFlow从v1.8版本开始支持All-Reduce架构,它采用NVIDIA NCCL作为All-Reduce实现,为支持多种分布式架构,TensorFlow引入Distributed Strategy API,用户通过该API控制使用何种分布式架构,例如如果用户需要在单机多卡环境中使用All-Reduce架构,只需定义对应架构下的Strategy,指定Estimator的config参数即可:
mirrored_strategy = tf.distribute.MirroredStrategy()
config = tf.estimator.RunConfig(train_distribute=mirrored_strategy, eval_distribute=mirrored_strategy)
regressor = tf.estimator.LinearRegressor(
feature_columns=[tf.feature_column.numeric_column('feats')],
optimizer='SGD',
config=config)
对于分布式多机环境,最早是Uber专门提出了一种基于Ring-Allreduce的分布式TensorFlow架构Horovod,并已开源。目前TensorFlow已经官方支持,通过MultiWorkerMirroredStrategy来指定,目前该API尚处于实验阶段。如果在代码中通过MultiWorkerMirroredStrategy指定使用All-Reduce架构,则分布式提交时,TF_CONFIG环境变量中的cluster就不需要ps类型的节点了。
Middle-level/Strategy
tf单机 与 分布式训练代码 很不一样,再加上ps-worker/allreduce 等训练策略 训练代码写起来就更乱了,为此 tf 为分布式训练 专门抽象了 tf.distribute.Strategy,想办法在训练代码层面 屏蔽掉 不同策略的差异。Strategy 代码从v1.14 开始比较完整了。
TensorFlow 分布式之 ParameterServerStrategy V2Strategy支持训练有两种主要方法:
- Keras Model.fit 或者 estimator API。如果用户喜欢用高层次抽象来训练,则建议使用这种方式。
- 自定义训练循环(custom training loop)。如果用户需要自己实现或者定义训练细节,则可以考虑这种方式。
代码示例
StrategyBase 代码注释中给出了一个 custom training loop 代码示例
my_strategy = xxxStrategy(cluster_resolver,variable_partitioner,...)
with my_strategy.scope():
@tf.function
def distribute_train_epoch(dataset):
def replica_fn(input):
# process input and return result
return result
total_result = 0
for x in dataset:
per_replica_result = my_strategy.run(replica_fn, args=(x,))
total_result += my_strategy.reduce(tf.distribute.ReduceOp.SUM,per_replica_result, axis=None)
return total_result
dist_dataset = my_strategy.experimental_distribute_dataset(dataset)
for _ in range(EPOCHS):
train_result = distribute_train_epoch(dist_dataset)
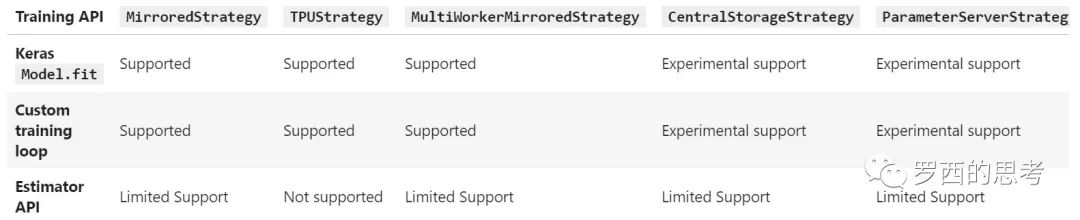
使用 TensorFlow 进行分布式训练 tf.distribute.Strategy 是一个可在多个 GPU、多台机器或 TPU 上进行分布式训练的 TensorFlow API。使用此 API,您只需改动较少代码就能基于现有模型和训练代码来实现单机多卡,多机多卡等情况的分布式训练。
- MirroredStrategy,单机多卡数据并行,使用 nccl all-reduce 在设备之间传递变量更新
- MultiWorkerMirroredStrategy,多机多卡分布式版本,使用all-reduce
- ParameterServerStrategy,ps/worker 异步模式
基于Tensorflow高阶API构建大规模分布式深度学习模型系列: 开篇
与estimator 结合使用
using_tfdistributestrategy_with_estimator_limited_support
Estimator.train ==> _train_model ==> _train_model_distributed,可以看到
- 训练代码都在 Strategy.scope 范围下
- 在 训练数据的获取
_get_iterator_from_input_fn(input_fn, ModeKeys.TRAIN, strategy)、训练图构建strategy.extended.call_for_each_replica都有Strategy 直接参与
class Estimator(object):
def _train_model_distributed(self, input_fn, hooks, saving_listeners):
...
# Configures the strategy class with `cluster_spec` 核心逻辑是 _initialize_multi_worker
self._config._train_distribute.configure(self._config.session_config)
return self._actual_train_model_distributed(self._config._train_distribute, input_fn, hooks, saving_listeners)
def _actual_train_model_distributed(self, strategy, input_fn, hooks,saving_listeners):
worker_hooks = []
with tf.Graph().as_default() as g:
with strategy.scope(), scale_ctx: # 都在Strategy.scope 范围下
# 调用input_fn来得到训练特征和标签
iterator, input_hooks = self._get_iterator_from_input_fn(input_fn, ModeKeys.TRAIN, strategy)
worker_hooks.extend(input_hooks)
global_step_tensor = self._create_and_assert_global_step(g)
tf.compat.v1.add_to_collection(training_util.GLOBAL_STEP_READ_KEY,strategy.extended.read_var(global_step_tensor))
features, labels = estimator_util.parse_iterator_result(iterator.get_next())
# 调用model_fn来得到训练图
grouped_estimator_spec = strategy.extended.call_for_each_replica(self._call_model_fn,args=(features,labels, ModeKeys.TRAIN,self.config))
loss = strategy.reduce(_get_loss_reduce_op_for_reporting(),grouped_estimator_spec.loss,axis=None)
distributed_train_op = grouped_estimator_spec.train_op
# 各种hook
training_hooks = get_hooks_from_the_first_device(grouped_estimator_spec.training_hooks)
training_chief_hooks = get_hooks_from_the_first_device(grouped_estimator_spec.training_chief_hooks)
# 进入training loop
estimator_spec = model_fn_lib.EstimatorSpec(mode=grouped_estimator_spec.mode,loss=loss,train_op=strategy.group(distributed_train_op),training_hooks=training_hooks,training_chief_hooks=training_chief_hooks,scaffold=scaffold)
return self._train_with_estimator_spec(estimator_spec, worker_hooks,hooks, global_step_tensor,saving_listeners)
def _train_with_estimator_spec(self, estimator_spec, worker_hooks, hooks,global_step_tensor, saving_listeners):
# 配置Hook
worker_hooks.extend(hooks)
worker_hooks.append(tf.compat.v1.train.NanTensorHook(estimator_spec.loss))
worker_hooks.extend(estimator_spec.training_hooks)
if (self._config.cluster_spec and type(self._train_distribution).__name__ in ('CollectiveAllReduceStrategy','CollectiveAllReduceStrategyV1','MultiWorkerMirroredStrategy')):
return self._train_with_estimator_spec_distributed(estimator_spec, worker_hooks, saving_listeners)
...
# 使用MonitoredTrainingSession进行Training loop
with training.MonitoredTrainingSession(master=self._config.master,is_chief=self._config.is_chief,checkpoint_dir=self._model_dir,...)
while not mon_sess.should_stop():
_, loss = mon_sess.run([estimator_spec.train_op, estimator_spec.loss])
return loss
Strategy 原理
TensorFlow 分布式之 ClusterCoordinatorTensorFlow 2 推荐使用一种基于中央协调的架构来进行参数服务器训练。每个worker和ps-server都运行一个 tf.distribution.Server,在此基础上,一个协调者任务负责在worker和ps-server上创建资源,调度功能,并协调训练。协调器使用 tf.distribution.experimental.coordinator.ClusterCoordinator 来协调集群,使用 tf.distribution.experimental.ParameterServerStrategy 来定义参数服务器上的变量和工作者的计算。
TensorFlow 分布式 DistributedStrategy 之基础篇从系统角度或者说从开发者的角度看,Strategy 是基于Python作用域或装饰器来实现的一套机制。它提供了一组命名的分布式策略,如ParameterServerStrategy、CollectiveStrategy来作为Python作用域,这些策略可以被用来捕获用户函数中的模型声明和训练逻辑,其将在用户代码开始时生效。在后端,分布式系统可以重写计算图,并根据选择的策略合并相应的语义。因此我们分析的核心就是如何把数据读取,模型参数,分布式计算融合到Python作用域或装饰器之中。
TensorFlow 分布式之 ParameterServerStrategy V1Strategy 工作原理,我们从分布式训练的几个过程来描述
- 初始化,负责获取集群信息。
- 如何获取训练数据。XXStrategy.distribute_datasets_from_function(dataset_fn) 或 XXStrategy.experimental_distribute_dataset(dataset)
- 作用域和(创建)变量。不需要XXStrategy.create_variable,但要求必须在 XXStrategy.scope 执行 tf.variable,tf.variable 时会 从 threadlocal 和 默认Graph 获取(XXStrategy.scope 时挂载好的) XXStrategy.creator_with_resource_vars 并执行。
- 运行,即调用XXStrategy.run为每个副本运行函数。
- 使用一个方法(如tf.distributed.Strategy.reduce)将得到的 per-replica 的值转换成普通的张量。
总结一下就是:XXStrategy 提供了 训练过程的各个步骤实现,要么直接执行 XXStrategy 方法,要么间接执行,XXStrategy 持有集群、设备信息,以便根据策略 实现取数、创建变量(包括variable placement)、构建计算图 等操作。
初始化
# 指定如何对变量进行分区
variable_partitioner = ( tf.distribute.experimental.partitioners.MinSizePartitioner(min_shard_bytes=(256 << 10),max_shards=NUM_PS))
strategy = tf.distribute.experimental.ParameterServerStrategy(cluster_resolver,variable_partitioner=variable_partitioner)
初始化方法如下,主要工作是连接到集群,然后调用 _extended 进行继续初始化。
def __init__(self, cluster_resolver, variable_partitioner=None):
self._cluster_resolver = cluster_resolver
self._verify_args_and_config(cluster_resolver)
self._cluster_coordinator = None
self._connect_to_cluster(coordinator_name="chief") # 连接到集群
self._extended = ParameterServerStrategyV2Extended(self, cluster_resolver,variable_partitioner)
super(ParameterServerStrategyV2, self).__init__(self._extended)
distribute_lib.distribution_strategy_gauge.get_cell("V2").set("ParameterServerStrategy")
self._should_use_with_coordinator = True
# Used while constructing distributed iterators.
self._canonicalize_devices = False
ParameterServerStrategyExtended 初始化之后各字段值如下

获取训练数据
对于输入数据集,主要有两种实现:
- experimental_distribute_dataset :从 tf.data.Dataset 生成 tf.distribute.DistributedDataset,得到的数据集可以像常规数据集一样迭代读取。
- _distribute_datasets_from_function :通过调用 dataset_fn 来分发 tf.data.Dataset。
XXStrategy.distribute_datasets_from_function(dataset_fn) ==> XXStrategyExtended._experimental_distribute_datasets_from_function(dataset_fn) ==> input_lib.get_distributed_datasets_from_function(dataset_fn,…) ==> DistributedDatasetsFromFunctionV1,返回 DistributedIteratorV1,既然得到了 iterator,就可以从数据集之中获得数据了。
class DistributedDatasetsFromFunctionV1(DistributedDatasetsFromFunction):
def _make_initializable_iterator(self, shared_name=None):
return self._get_iterator()
def _make_one_shot_iterator(self):
return self._get_iterator()
def _get_iterator(self):
iterators = _create_iterators_per_worker(self._datasets,self._input_workers, True,self._options)
iterator = DistributedIteratorV1(self._input_workers, iterators,self._strategy,self._enable_get_next_as_optional)
iterator._element_spec = self._element_spec
return iterator
XXStrategy.experimental_distribute_dataset(dataset) ==> XXStrategyExtended._experimental_distribute_dataset ==> input_lib.get_distributed_dataset(dataset, …) ==> DistributedDatasetV1(dataset, …)
class DistributedDatasetV1(DistributedDataset):
def make_one_shot_iterator(self):
return self._make_one_shot_iterator()
def _make_one_shot_iterator(self):
return self._get_iterator()
def _get_iterator(self):
worker_iterators = _create_iterators_per_worker(self._cloned_datasets,self._input_workers)
iterator = DistributedIteratorV1(self._input_workers, worker_iterators,self._strategy)
iterator.element_spec = self.element_spec
return iterator
TensorFlow 分布式 DistributedStrategy 之基础篇DistributedDataset 的 iter 方法会针对每个 worker 建立一个 iterator,最后统一返回一个 DistributedIterator。DistributedIterator 的 get_next 方法完成了获取数据功能。
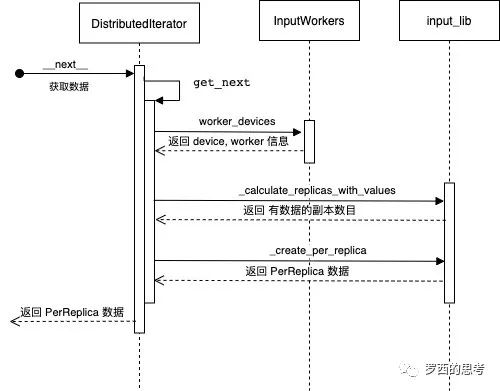
作用域和(创建)变量
StrategyBase 的 scope 方法返回一个 Context manager,其使用当前策略来建立分布式变量,当进入 Strategy.scope 时会发生:
- “strategy” 成为全局上下文内的 “当前” strategy 。在这个作用域内,tf.distribute.get_strategy() 将返回此策略。在此范围之外,它返回默认的无操作策略。
- 进入此作用域也会进入”cross-replica context”。
- “scope”内的变量创建被策略拦截。每个策略都定义了它想要如何影响变量的创建。像 ‘MirroredStrategy’、’TPUStrategy’ 和 ‘MultiWorkerMirroredStrategy’ 这样的同步策略会在每个副本上创建复制的变量,而 ‘ParameterServerStrategy’ 在参数服务器上创建变量。这是使用自定义的 tf.variable_creator_scope 完成的。
- 在某些策略中,还可以输入默认的设备作用域:比如在”MultiWorkerMirroredStrategy”中,为每个工作者输入默认的设备作用域 “/CPU:0”。
StrategyBase 主要是靠 StrategyExtendedV2 干活。
class StrategyBase(object):
def run(self, fn, args=(), kwargs=None, options=None): # Invokes `fn` on each replica, with the given arguments.
...
def reduce(self, reduce_op, value, axis): # Reduce `value` across replicas and return result on current device.
...
def extended(self): # Strategy 很多操作直接转给了 StrategyExtendV1/V2
return self._extended
def scope(self):
return self._extended._scope(self)
def make_dataset_iterator(self, dataset):
def make_input_fn_iterator(self,input_fn,replication_mode=InputReplicationMode.PER_WORKER):
def experimental_distribute_dataset(self, dataset, options=None):
def distribute_datasets_from_function(self, dataset_fn, options=None):
def experimental_run(self, fn, input_iterator=None):
with self.scope():
args = (input_iterator.get_next(),) if input_iterator is not None else ()
return self.run(fn, args=args)
# tensorflow/tensorflow/python/distribute/distribute_lib.py
class StrategyExtendedV2(object):
def _scope(self, strategy):
def creator_with_resource_vars(*args, **kwargs):
_require_strategy_scope_extended(self)
kwargs["use_resource"] = True
kwargs["distribute_strategy"] = strategy
return self._create_variable(*args, **kwargs)
def distributed_getter(getter, *args, **kwargs):
return getter(*args, **kwargs)
return _CurrentDistributionContext(strategy,variable_scope.variable_creator_scope(creator_with_resource_vars),
variable_scope.variable_scope(variable_scope.get_variable_scope(),custom_getter=distributed_getter), self._default_device)
# tensorflow/tensorflow/python/ops/variable_scope.py
def variable_creator_scope(variable_creator):
with ops.get_default_graph()._variable_creator_scope(variable_creator):
yield
# tensorflow/tensorflow/python/framework/ops.py
class Graph(object):
def _variable_creator_scope(self, creator, priority=100):
old = self._variable_creator_stack
new = list(old)
new.append((priority, creator))
new.sort(key=lambda item: item[0])
self._thread_local._variable_creator_stack = new
...
xxStrategy.scope ==> variable_scope.variable_creator_scope(creator_with_resource_vars) ==> ops.get_default_graph()._variable_creator_scope(variable_creator) /Graph._variable_creator_scope ,把 Variable 的创建函数 creator_with_resource_vars(各种XXStrategy 子类实现_create_variable) 给挂到了 当前默认graph 和 thread local 上。
创建Variable的时候 tf.Variable ==> VariableMetaclass.call ==> VariableMetaclass._variable_v1_call ==> previous_getter ==> ops.get_default_graph()._variable_creator_stack(从thread local或默认graph 拿到 creator_with_resource_vars) ==> StrategyExtendedV2.creator_with_resource_vars ==> XXStrategy._create_variable 来创建变量。
# tensorflow/tensorflow/python/ops/variables.py
class Variable(six.with_metaclass(VariableMetaclass,trackable.Trackable)):
# Variable 是 VariableMetaclass 子类
...
class VariableMetaclass(type):
def _variable_v1_call(cls,initial_value=None,trainable=None,...):
previous_getter = lambda **kwargs: default_variable_creator(None, **kwargs)
# previous_getter 来自 ops.get_default_graph()
for _, getter in ops.get_default_graph()._variable_creator_stack:
previous_getter = _make_getter(getter, previous_getter)
return previous_getter(initial_value=initial_value,trainable=trainable,...)
def __call__(cls, *args, **kwargs):
if cls is VariableV1:
return cls._variable_v1_call(*args, **kwargs)
elif cls is Variable:
return cls._variable_v2_call(*args, **kwargs)
...
以ParameterServerStrategy 为例,第一个操作序列是建立变量,第二个操作序列是处理变量。
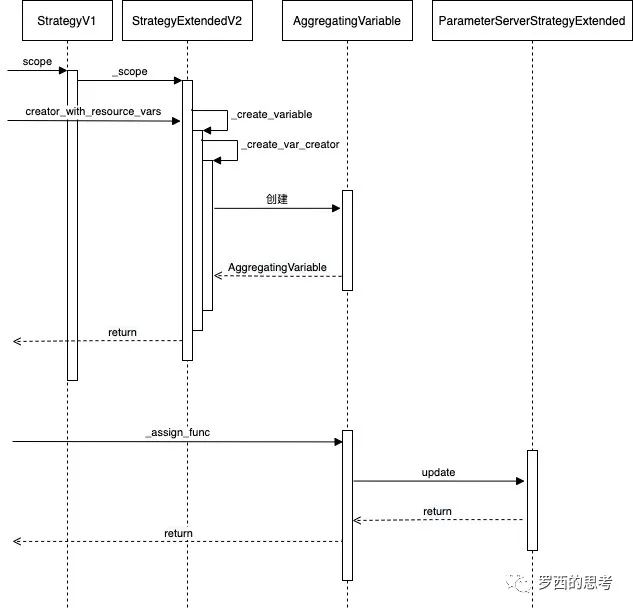
xxStrategy.scope 返回一个 _CurrentDistributionContext 对象,作为一个上下文管理器,包含 __enter__ 和 __exit__ 方法(with退出时执行),将 contenxt 信息保存在了当前默认 graph 和 thread local上
class _CurrentDistributionContext(object):
def __enter__(self):
...
_push_per_thread_mode(self._context) # ==> distribution_strategy_context._push_per_thread_mode
def __exit__(self, exception_type, exception_value, traceback):
...
_pop_per_thread_mode()
# tensorflow/python/distribute/distribution_strategy_context.py
def _push_per_thread_mode(context):
ops.get_default_graph()._distribution_strategy_stack.append(context)
def _pop_per_thread_mode():
ops.get_default_graph()._distribution_strategy_stack.pop(-1)
def get_strategy():
return _get_per_thread_mode().strategy
def _get_per_thread_mode():
try:
return ops.get_default_graph()._distribution_strategy_stack[-1] # pylint: disable=protected-access
except (AttributeError, IndexError):
return _get_default_replica_mode()
运行
以ParameterServerStrategy 为例
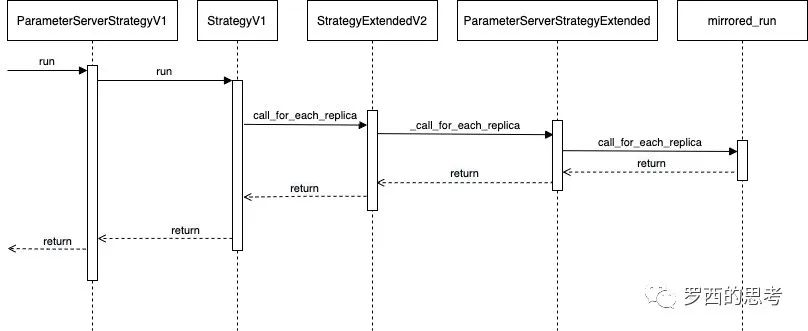
部署
tensorflow手工启动示例:TensorFlow 没有提供一次性启动整个集群的解决方案(相对于pytorch 和 horovod 提供horovodrun来说),所以用户需要在每台机器上逐个手动启动一个集群的所有ps 和worker 任务。为了能够以同一行代码启动不同的任务,我们需要将所有worker任务的主机名和端口、 所有ps任务的主机名和端口、当前任务的作业名称以及任务编号这4个集群配置项参数化。通过输入不同的命令行参数组合,用户就可以使用同一份代码启动每一个任务。
// 在在参数服务器上执行
python mnist_dist_test_k8s.py --ps_hosts=10.244.2.140:2222 --worker_hosts=10.244.1.134:2222,10.244.2.141:2222 --job_name="ps" --task_index=0
// 在第一个worker节点上执行
python mnist_dist_test_k8s.py --ps_hosts=10.244.2.140:2222 --worker_hosts=10.244.1.134:2222,10.244.2.141:2222 --job_name="worker" --task_index=0
// 在第二个worker节点上执行
python mnist_dist_test_k8s.py --ps_hosts=10.244.2.140:2222 --worker_hosts=10.244.1.134:2222,10.244.2.141:2222 --job_name="worker" --task_index=1
深度学习分布式训练框架 horovod (18) — kubeflow tf-operator 深度学习分布式训练框架 horovod (19) — kubeflow MPI-operator
其它
容错性
- 最好的情况就是非Chief的worker task出错了,因为这些task实际上是无状态的。那么当遇到了这种错误,当这样的一个worker task恢复的时候,它会重新与它的PS task中建立连接,并且重新开始之前崩溃过的进程。
- 比较差的一种情况就是PS task失败了,那么就有一个麻烦,因为PS task是有状态的,所有的worker task需要依赖他们来发送他们的梯度并且取得新的参数值。所以这种情况下,他们的chief worker task负责监测这种错误,如果发生了这种错误,chief worker task就打断整个训练,并从上一个检查点恢复所有的PS tasks。
- 最糟糕的情况就是chief worker task失败了,打断训练,并在当它恢复了时候从上一个好的检查点恢复。
Fault tolerance 的API
MonitoredTrainingSession会自动帮你初始化参数,并且当PS 任务失败会自动恢复。PS:client 发现运行出错后自动提交
server = tf.train.Server(...)
is_cheif = FLAGS.task_index == 0
with tf.train.MonitoredTrainingSession(master=server.target,is_chief=is_chief) as sess:
while not sess.should_stop():
sess.run(train_op)
部分session源码分析(client侧)
[翻译] TensorFlow 分布式之论文篇 (1) 分布式tensorflow源码解读2:MonitoredTrainingSession
- 如果chief节点,负责session的初始化或者从已有checkpoint恢复session,并且创建一些用于保存checkpoint和summary的hooks。如果是非chief的worker节点,则需要依赖chief节点完成初始化或恢复session这些操作后才能设置属于自己的session。
- MonitoredTrainingSession可根据不同的角色去创建不同种类的Session,其中chief节点是由ChiefSessionCreator类去创建session,而非chief的worker节点是由WorkerSessionCreator类创建,特殊之处就是创建时调用的是wait_for_session(),大致意思是需要等待chief节点的session创建完成之后才去创建属于自己节点的session。
- 创建session都是属于SessionManager类的一个方法
class SessionManager(object): # prepare_session函数的作用就是如果有checkpoint存在,就从checkpoint恢复session,如果不存在checkpoint就从传入的`init_op`和 调用`init_fn`函数去创建session。 def prepare_session(self,master,init_op=None,saver=None,checkpoint_dir=None,...,init_fn=None): sess, is_loaded_from_checkpoint = self._restore_checkpoint(...) if not is_loaded_from_checkpoint: if init_op is None and not init_fn and self._local_init_op is None: raise RuntimeError("Model is not initialized and no init_op or init_fn or local_init_op was given") if init_op is not None: sess.run(init_op, feed_dict=init_feed_dict) if init_fn: init_fn(sess) return sess
留下评论