语言模型的发展
简介
- 当模型足够大,语料足够多的时候,涌现这件事情出现就不足为奇。这就好比把你甩到一个外语环境中,见得多听得多,根本不用专门学语法就可以学会语言,这就是语料和模型规模的重要性。看的句子多了,就懂得语法;见的世面多了,就懂得推理和逻辑。ChatGPT在认知能力上前进了一大步,通过强化学习与NLP(自然语言处理)相结合,通过人的反馈强化学习,基本解决了自然语言理解与生成问题,并且展现出人类无中生有的原创能力。PS:模型的参数量和训练数据的 token 数之间有个比例关系,只要把模型想象成数据的压缩版本就行了,压缩比总是有极限的。模型的参数量太小,就吃不下训练数据里面所有的知识;模型的参数量如果大于训练数据的 token 数,那又浪费,还容易导致 over-fitting。
- 人们对知识的表示和调用发生了根本性变化。从关系数据库(SQL),到互联网信息检索,科技史上每次知识表示与调用方式的跃迁,都会掀起一次巨大的技术变革。
- 大模型作为基础平台支撑无数智能应用。大模型在内容创意生成、对话、语言或风格互译、搜索等方面的能力,将为各应用领域带来百花齐放。而大模型基础平台,在数据层、模型层、中间层、应用层,都蕴藏着巨大发展机遇。
脉络:NLP基本问题 词表示+语言模型,模型=模型结构+模型参数 ==> 模型结构逐步统一为Transformer,模型参数也希望逐渐统一, 由于自然语言任务种类繁多,且任务之间的差别不太大,所以为每个任务单独微调一份大模型很不划算 ==> pre-train model ==> 多任务逐渐收敛为文字接龙(调整数据集,将任务输入进行转化,将所有任务的形式都转为预测下一个token)、让模型识别指令,意外发现了Few-Shot Learning能力 ==> 指令输出与人类价值观对齐 ==> 特定格式的引导 加上tool的辅助让LLM具备智能体的潜力。PS:能听懂 ==> 能接茬 ==> 接得对路 ==> 智能体。
发展脉络
从分析式AI(input ==> 预测值)到生成式AI,从domain-specific到通用,从fine-tune 到Prompt。
- 早在上个世纪五十年代,就有学者提出了人工智能(Artificial Intelligence)的概念,其目的是希望让计算机拥有人类智能(或部分人类智能)。这个领域经过很多年的发展,依然没有突破,直到2012年出现了深度学习技术。深度学习主要解决了模型表示能力的瓶颈。我们面对的建模问题,比如图像理解、语言翻译、语音识别、分子-蛋白结合构象预测等技术,都是非常复杂的非线性问题,在深度学习出现之前,模型表示能力很弱,无法对这些复杂问题进行精确表示。而深度学习技术,可以通过模型的层次堆叠,理论上可以构建任意深度的模型,突破了模型表示能力的瓶颈,从而在语音识别、计算机视觉、自然语言理解等领域取得了突破性进展。
- 这个阶段的主要局限,是非常依赖于标注数据的数量。由于模型参数变多,想要求解这么多的模型参数,需要大量的训练数据作为约束。而想获得大量的标注数据非常贵,到亿级别之后就很难再有提升,数据支撑的有效模型大小也受到限制。
- 2017年,一个重要的基础工作Transformer出现了。2019年,一个叫作BERT的工作脱颖而出,BERT采用了一个叫作自监督预训练的思路,无需标注数据仅利用文本语料本身存在的约束就可以训练模型(比如某句话的某个位置只能用某些限定的词),这样互联网上存在的优质语料不需要进行人工标定就可以用来做训练,从而一下子使得可用训练数据的数量有了巨大的提高,再配合上大模型,使得BERT模型的效果远远超过过去的模型,并且在不同任务间具有很好的通用性,成为NLP领域里程碑工作之一。其实在BERT出现之前的2018年,还有个工作叫作GPT(即GPT1.0),更早利用了自监督预训练的思路来做文本生成,即输入前面的文本,模型预测输出后面的文本,领域里面的优质语料无需标注就可以做训练。BERT和GPT都是在Transformer基础上发展而来的,而Transformer也逐渐发展成为AI领域的通用模型。
- 在自监督预训练技术出现之后,我们可以认为新一代人工智能发展到了第二个阶段,即自监督预训练技术使得可用训练数据有了几个数量级的提升,我们进入了一切皆为训练数据的时代。这使得模型可以获得几乎无限的训练数据,在训练数据大幅提升的支撑下,模型大小也有了数个数量级的提升(有效模型达到了千亿规模),(为了对如此规模的数据进行建模,模型参数的规模越大越好,更大规模的训练数据需要模型具备更强的记忆、理解和表达能力。而为了拥有更强的记忆、理解和表达能力,模型则需要更大的参数量,也就是更大的模型。)而在模型效果上,这些模型变得不再依赖于下游任务领域数据的再训练,所以,领域进入到基于自监督预训练的通用大模型时代。
- ChatGPT为什么能有这样惊艳的效果?其中一个核心原因是ChatGPT基于生成大模型GPT3.5构建,这应该是当前自然语言理解领域文本生成最好的模型(GPT3.5比GPT3.0使用了更多的数据和更大的模型,具有更好的效果)。第二个核心原因则是基于人类反馈的强化学习技术:第一步,先收集用户对于同一问题不同答案的偏好数据;第二步,利用这个偏好数据重新训练GPT模型,这一步是基于监督信息的精调;第三步,根据用户对于不同答案的偏好,训练一个打分函数,对于ChatGPT的答案会给出分数,这个分数会体现出用户对于不同答案的偏好;第四步,用这个打分函数作为强化学习的反馈(Reward)训练强化学习模型,使得ChatGPT最终输出的答案更偏向于用户喜欢的答案。通过上述过程,ChatGPT在GPT3.5的基础上,针对用户输入,输出对用户更友好的回答。ChatGPT第一阶段训练GPT生成模型使用的训练数据非常多,大约在几十TB,训练一次模型需要花费千万美元,而第二个阶段,基于强化学习的少量优质数据反馈则只需要数万条优质数据。这种新的范式,有可能成为第三阶段人工智能的核心驱动技术,即首先基于自监督预训练的大模型,再结合基于少量优质数据反馈的强化学习、Prompting等技术,形成模型和数据的闭环反馈,获得进一步的技术突破。如果这个技术走通,那么无人驾驶、机器人以及生命科学等数据获取昂贵的领域将显著受益。
- ChatGPT并不能证明人工智能已经有了人类心智,ChatGPT表现出来的一些创造性和心智,是因为自然语言理解语料中包含了语义、逻辑,基于自然语言语料训练出来的生成模型,统计意义上学习到了这些对应关系,看起来似乎有了智能,但并不是真的有人类心智。ChatGPT很棒,但说他智力等于几岁小朋友的说法,都不够严谨。因为从根本上讲,人学习新知识、进行逻辑推理、想象、运动反馈这些能力,目前AI还没有具备。
- ChatGPT并不是一两个研究人员做出的算法突破,而是在先进理念指导下,非常复杂的算法工程体系创造出来的成果,需要在团队和组织上匹配(类比OpenAI和DeepMind)。纯研究型的团队恐怕不能成功,对深度学习理解不够、太工程化的团队也不会成功。这只团队需要:第一要有足够资源支持,可以支撑昂贵的深度学习训练和人才招聘;第二要有真正在工业界领导过工程化大模型团队的专家领导,ChatGPT不仅有算法创新,更是工程体系创新;第三,也可能是最重要的,需要一个团结协作有统一领导且不追求论文发表的组织(松散型的组织利于算法创新,但不利于工程化算法攻坚),且配备足够多优秀的工程和算法人才。
自然语言处理基础
上世纪 50 年代到 70 年代,人们对用计算机处理自然语言的认识都局限在人类学习语言的方式上,当时学术界普遍认为,要让机器完成 NLP 任务,首先必须让机器理解语言。因此分析语句和获取语义成为首要任务,而这主要依靠语言学家人工总结文法规则。但是人类语言既复杂又灵活,仅靠手工编写的文法规则根本无法覆盖,规则之间还可能存在矛盾。因此这一阶段,可以说自然语言处理的研究进入了一个误区。正如人类是通过空气动力学而不是通过模仿鸟类造出了飞机,事实上进行自然语言处理也未必要让机器完全理解语言。70 年代,随着统计语言学的提出,基于数学模型和统计的方法开始兴起,NLP 领域才在接下来的四十多年里取得了一系列突破。80 年代以来,随着硬件计算能力的不断提高,以及互联网发展产生的海量数据,越来越多的统计机器学习方法被应用到自然语言处理中。2006 年,基于神经网络和反向传播算法进行训练的深度学习方法开始兴起,各种神经网络模型也被引入到自然语言处理任务中。
自然语言处理(Natural Language Processing, NLP) 被誉为“人工智能皇冠上的明珠”,一方面表明了它的重要性,另一方面也突出了它的技术难度。简单来说,NLP要做的事就是利用计算机实现自然语言数据的智能化处理、分析和生成,以期让计算机实现听、说、读、写、译这些人类所具备的语言能力。
- 词表示。没有思考过 Embedding,不足以谈 AI
- synonym and hypernym。用一个词相关的词来表示一个词
- one-hot。假定所有的文字一共有 N 个单词(也可以是字符),我们可以将每个单词赋予一个单独的序号 id,那么对于任意一个单词,我们都可以采用一个 N 位的列表(向量)对其进行表示。 缺点:这样会导致词汇与词汇之间是没有任何关联的。
- word embedding。基于神经网络的词的向量表示方法。
- represent word by context。词通常有多重含义,需要根据单词出现的上下文以不同的向量表示同一个词。PS:语义的几何学
- 总结:如何用向量表示一次词? 要求:同义词距离更近。onehot ==> word embedding ==> Word2Vec,问题来了,这些词表示方法本质上是静态的,由于词和向量是一对一的关系,所以多义词的问题无法解决 ==> 不直接将词向量作为神经网络输入,当前上下文对词向量动态调整后,再作为新特征接入下游任务。PS:几乎所有模型的后半部分都是mlp,负责适配下游任务,但是你不能直接将input 录入mlp,那样的话weight 就太大了。 从这个视角看,可以认为transformer 是一个语义上、性能上更好的动态embedding模型。
- 语言模型。语言模型是根据语言客观事实而进行的语言抽象数学建模(对自然语言的概率分布建模),是一种对应关系。根据前文预测下一个词是什么:计算一个序列的词成为一句话的概率是多少;根据已经出现的词,计算某个词出现的概率
- 统计语言模型。本质是基于词与词共现频次的统计。给定一个句子
S=w1,w2,w3,…,wn,则生成该句子的概率为:p(S)=p(w1,w2,w3,w4,w5,…,wn),再由链式法则我们可以继续得到:p(S)=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn-1)。那么这个 p(S) 就是我们所要的统计语言模型。有一个非常本质的问题并没有被解决,那就是语料中数据必定存在稀疏的问题,公式中的很多部分是没有统计值的,那就成了 0 了,而且参数量真的实在是太大了。- N-gram,前面出现的N个词,出现xx概率多大。但是如果 n 比较大,或者相关语料比较少的时候,数据稀疏问题仍然不能得到很好地解决。这就好比我们把水浒传的文本放入模型中进行统计训练,最后却问模型林冲和潘金莲的关系,这就很难回答了。因为基于 ngram 的统计模型实在是收集不到两者共现的文本。
- 神经网络语言模型。a neural language model is a language model based on netual networks to learn distributed representations of words. 给每个词分别赋予了向量空间的位置作为表征,从而计算它们在高维连续空间中的依赖关系。PS:模型=模型结构(逐渐统一为Transformer)+模型参数。
- 统计语言模型。本质是基于词与词共现频次的统计。给定一个句子
有没有一种方法,可以把语言变成一种数学计算过程,比如采用概率、向量等方式对语言的生成和分析加以表示呢?之前很方案都是基于 符号、统计的,引入神经网络之后,一般用一个向量表示一个词,向量是学习出来的,并且可以根据新的语料学习调整。 PS:词表示 + 下游任务 结合在一起,词表示统一输入,下游任务统一输出,就是AGI。PS:极大地弱化对显式特征工程依赖。传统 ML 更依赖数据结构(特征工程)以及规则(专家经验)。
什么是语言模型?其实每个人都用到过语言模型,那就是拼音输入法。拼音输入法的本质就是一个语言模型,用户给定一串拼音之后,比如“wo he ni”,每个拼音下都有很多的候选汉字,多个拼音就会组合爆炸,屏幕上不可能把所有组合展示出来让用户选,只能展示一个或几个最可能的汉字组合。可能性如何判断?这就要用到中文语言模型,任意一个中文串,语言模型可以给出这个中文串是一个正常人类句子的概率大小。比如“我和你”是正常人类句子的概率要明显大于“窝核腻”、“我喝泥”等等,所以最终给用户呈现“我和你”。此外,现代输入法通常都有联想功能,当你输入“wo he ni”之后,输入法不止能猜到你想输入“我和你”,还会给出后面的联想“我和你一起”,这也是基于语言模型。给定前面若干个单词,预测下一个单词是什么;然后模型将预测的单词加入到给定单词序列,继续预测下一个;如此递归直到预测下一个单词为结束符号或达到要求长度。如果一开始给定的单词序列为我们提问的一个问句,我们认为它的后续输出为问题的答案,那这个语言模型就变成了一个问答系统,ChatGPT的本质正是如此。
自回归模型的核心思想可以用一个优雅的公式表达:
\[P(x_1, x_2, \dots, x_T) = \prod_{t=1}^{T} P(x_t \mid x_1, x_2, \dots, x_{t-1})\]分解理解
- $ x_1, x_2, \dots, x_T $ 表示一个由 $ T $ 个词组成的序列
- $ P(x_1, x_2, \dots, x_T) $ 是这个序列出现的概率
- $ P(x_t \mid x_1, x_2, \dots, x_{t-1}) $ 是在给定前 $ t-1 $ 个词的条件下,第 $ t $ 个词出现的概率
- $ \prod $ 表示连乘,将所有条件概率相乘得到整个序列的概率
直观例子:对于句子“我爱学习” \(P(\text{我}, \text{爱}, \text{学习}) = P(\text{我}) \times P(\text{爱} \mid \text{我}) \times P(\text{学习} \mid \text{我}, \text{爱})\)
在深度学习中,我们通过神经网络参数化这个条件概率: \(P(x_t \mid x_1, \dots, x_{t-1}) = \text{Softmax}\left(f_\theta(x_1, \dots, x_{t-1})\right)\)
其中:
- $ f_\theta $ 是参数为 $ \theta $ 的神经网络(如 Transformer)
- Softmax 函数将网络输出转换为概率分布
机器怎么看懂人类的文字?
语言模型编码了关于语言的统计信息。简单来说,统计信息告诉我们在给定上下文中,某个内容(例如单词、字符)出现的可能性有多大。从这点出发,“9.9和9.11比大小”翻车的原因也就容易理解了,若是训练时存在着许多版本号相关的数据,那么从版本号的角度来看,9.11确实要比9.9大,大模型也就很可能会根据这种概率分布得出“9.11比9.9要更大”的结论。
OPENAI首席科学家llya:大型语言模型的理念是:如果有一个大型神经网络,我们可以对其进行训练,让它根据前面的文本内容预测下一个单词。再看最初的猜想:也许生物神经元和人工神经元极为类似,没有太大区别。那么,如果有一个可以准确预测下一个单词的大型神经网络,它的运转方式也许类似于人们谈话时生物神经元的运转方式。如果我们和这样的神经网络对话,因为它能够准确预测下一个单词,所以可以在理解对话的基础上,准确地缩小生成对话的可能性范围。精确猜测下一个单词需要进行预测,这也是理解的方式。我们很难清楚定义神经网络的“理解“,但我们可以轻易测量和优化网络对下一个单词的预测误差。我们想要神经网络拥有“理解”能力,但能做的是优化预测。通过优化预测得到了目前的大型语言模型,它们都是用强大的反向传播算法训练的神经网络。PS:就好像我们想让孩子好好学习,但没有好的考核手段,分数成了考核手段,分高就认为学的好。
llya:专业化训练 vs 通用训练?在某些情况下,专业化训练肯定能发挥巨大作用。我们进行通用化训练的原因仅仅是为了让神经网络能够理解我们所提出的问题。只有当它具有非常强大的理解能力时,我们才能进行专业化训练,并真正从中受益。所以,这两种训练方向都有前景。在开源领域,人们已经开始进行专业化训练,因为他们使用的模型性能较弱,所以要尽可能地提升模型的性能。我们可以将AI看成是由多个元素组成的集合,每个元素都能对其性能作出贡献。在特定任务中,专业数据集可以使AI表现得更好;从所有任务角度出发,性能更强的基础模型无疑也更有用。所以答案就是:我们不必非要二选一,也可以将两者结合起来。
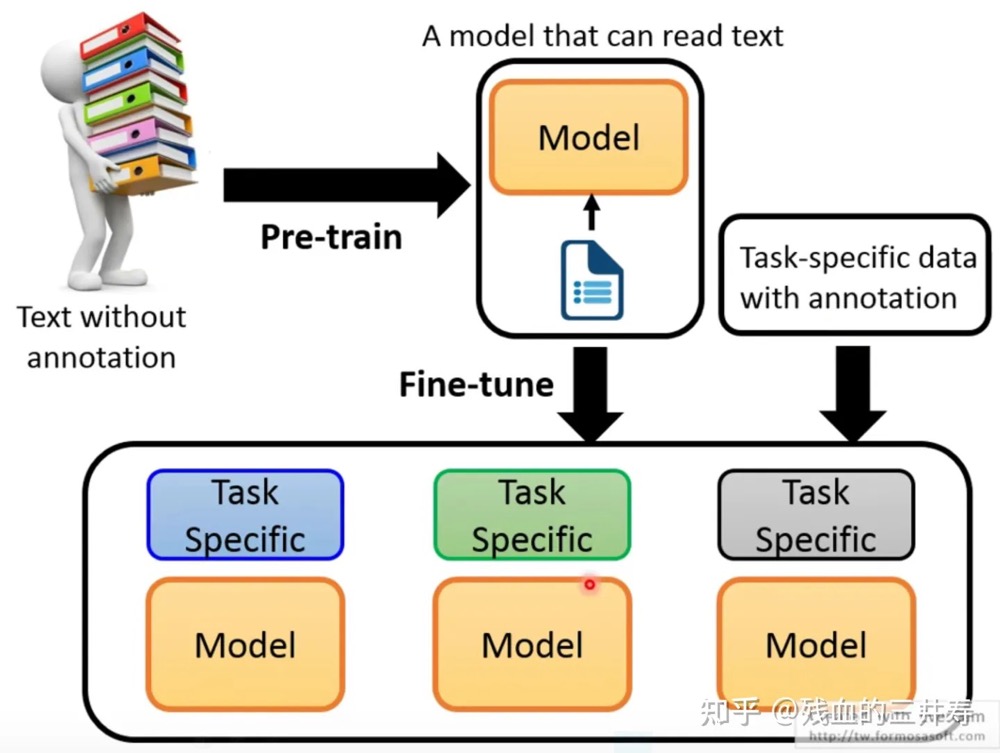
以往的NLP任务都是为每个任务分配一个模型,之后用对应任务大量的标注数据去训练这个模型。Transformer出世后,模型对文字上下文的理解能力得到显著增强
- 首先,用无标注的数据(可以理解为一段普通的文字)训练一个预训练模型。在这个环节里,我们培养模型文字接龙的能力,也就是给定前k个词,模型能预测出第k+1个词。(pre-training)。
- 然后,在模型能够理解文字含义的基础上,用有标注的数据训练模型去定向做一些下游任务。例如文本分类,文本相似性比较等。有标注的数据集是远小于无标注数据集的,在这个环节,我们只是对模型做了一些微小的调整。(fine-tuning)。 这个过程和人类学习语言的过程是十分接近的。比如考托福考试,需要有听说读写这些测试。但是人类的学习的过程并不是直接去学习这些题目的做法,而是通过阅读大量的英文语料去掌握英文,之后再学习这个题目的解法,达到解题的效果。
Pre-training
给出一段文本,OpenAI 就能返回给你一个 Embedding 向量,这是因为它的背后是 GPT-3 这个超大规模的预训练模型(Pre-trained Model)。
- 这个 API 可以把任何你指定的一段文本,变成一个大语言模型下的向量,也就是用一组固定长度的参数来代表任何一段文本。
- 提前计算“好评”和“差评”这两个字的 Embedding。对于任何一段文本评论,我们也都可以通过 API 拿到它的 Embedding。
- 我们把这段文本的 Embedding 和“好评”以及“差评”通过余弦距离(Cosine Similarity)计算出它的相似度。然后我们拿这个 Embedding 和“好评”之间的相似度,去减去和“差评”之间的相似度,就会得到一个分数。如果这个分数大于 0,那么说明我们的评论和“好评”的距离更近,我们就可以判断它为好评。如果这个分数小于 0,那么就是离差评更近,我们就可以判断它为差评。 PS: 对于大模型,即便没有在针对具体的业务场景进行专门的训练(比如电影评论、商品评论),以上面情感分析为例,使用预训练模型给出来的向量,直接根据距离做的判断,其准确率也很厉害了。
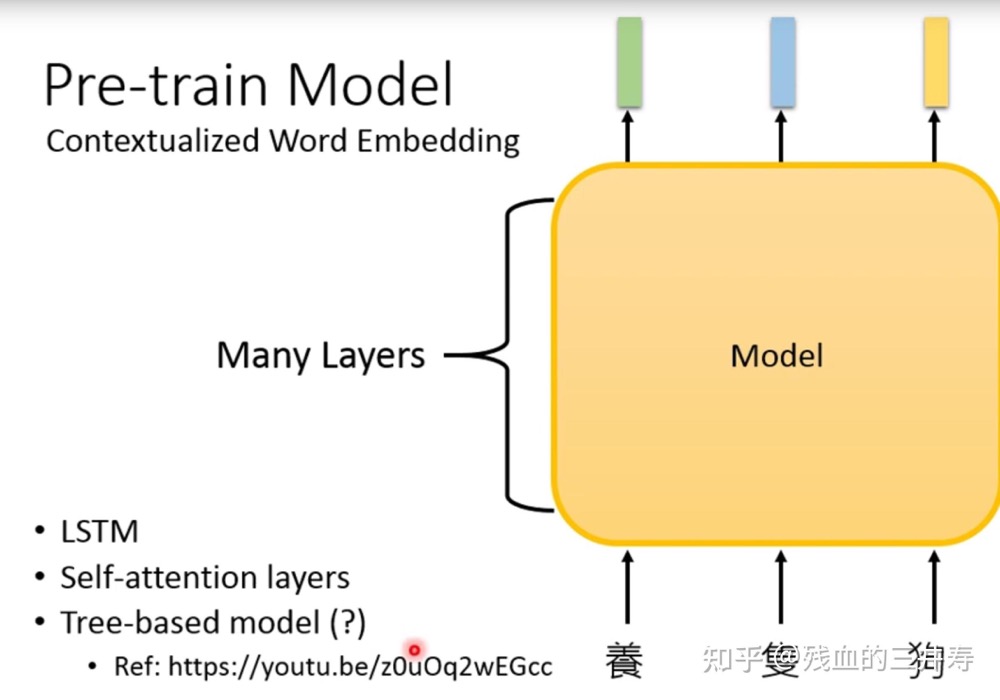
what is pre-train model(也被称为foundation model)? represent each token by a embedding vector. 预训练语言模型的本质是从海量数据中学到语言的通用表达。
- contextualized word embedding。比如bank 单词有两种或三种意思,对于不同的意思的token,会根据其经常出现的上下文,学习一个 embedding token。 相关方法如ELMO等。
- 不同于以往的embedding:输入一个token,输出一个embedding。contextualized word embedding是在输入一整个句子以后,输出这个句子中各个token的embedding。这样这个token的embedding就是在看过这个token的上下文后,输出token embedding,这个embedding就包含了上下文的信息。每个词的向量,随着位置以及前后词的不同,编码出来的结果是不一样的。
- contextualized word embedding的模型就像是一个encoder,用于编码信息。通常是非常深的网络,可以用到lstm,可以用自注意力层。
NLP任务一般又被分为自然语言理解(NLU)和自然语言生成(NLG)两大类,对应的不同的无监督预训练目标。其中,自回归(Autoregressive,简称AR)语言建模和自编码(Autoencoder,简称AE)一直是最成功的两个预训练目标。Transformer encoder是一个AE模型,Transformer decoder则是一个AR模型。
![]()
- AR模型,代表作GPT,从左往右学习的模型。AR模型从一系列time steps中学习,并将上一步的结果作为回归模型的输入,以预测下一个time step的值。AR模型通常用于生成式任务,优缺点如下:
- 优点:AR模型擅长生成式NLP任务。AR模型使用注意力机制,预测下一个token,因此自然适用于文本生成。此外,AR模型可以简单地将训练目标设置为预测语料库中的下一个token,因此生成数据相对容易。
- 缺点:AR模型只能用于前向或者后向建模,不能同时使用双向的上下文信息,不能完全捕捉token的内在联系。
- AE模型,代表作BERT,它不会进行精确的估计,但却具有从被mask的输入中,重建原始数据的能力,即fill in the blanks(填空)。测出该位置应该出现的那个正确词汇,这就意味着模型能够“吃透”上下文语义信息,是一种有效的将文本转换成高维特征的方法。AE模型通常用于内容理解任务/只需要理解输入语义的任务,比如自然语言理解(NLU)中的分类任务:情感分析、提取式问答。AE模型的优缺点如下:
- BERT使用双向transformer,在语言理解相关的任务中表现很好。
- 输入噪声:BERT在预训练过程中使用【mask】符号对输入进行处理,这些符号在下游的finetune任务中永远不会出现,这会导致预训练-微调差异。而AR模型不会依赖于任何被mask的输入,因此不会遇到这类问题。且基于一个独立假设:在给定了unmasked tokens时,所有待预测(masked)的tokens是相互独立的。
- 针对机器翻译这种序列到序列的任务(同时需要内容理解和生成的任务/适用于需要基于输入的生成式任务),往往会将模型组织为完整的编码器-解码器架构。它将每个task视作序列到序列的转换/生成(比如,文本到文本,文本到图像或者图像到文本的多模态任务)。
- 理论上是结合了 GPT 和 BERT 的优点,但会带来参数的暴涨,训练成本很高,google 提出T5后并未过多发展。T5 统一了 NLP 任务的形式,一切都可以是 Text2Text 的形式,与 GPT 解决问题的思路是一致的。
在自回归生成的过程中,会为序列开始后的每个时刻生成一个词,并把它当作下一个时刻生成的上下文。这个过程可以用伪代码来表示。
def generate_text(prompt, model, max_length=100):
# 输入一个初始的提示语,然后逐步生成文本
output_text = prompt
while len(output_text) < max_length:
# 从模型中预测下一个词
next_word = model.predict_next_word(output_text)
# 将下一个词添加到输出文本中
output_text += next_word
return output_text
| BERT | GPT | |
|---|---|---|
| 预训练的方式不同 | 双向语言模型,通过左右两侧的单词序列来预测中心单词的表示 | 单向语言模型,通过左侧的单词序列预测右侧的单词序列 |
| 目标不同 | 预测中心单词 | 生成下一个单词/预测下一个单词的概率分布 |
| 预训练数据集不同 | 主要使用了BooksCorpus和Wikipedia数据集 | 使用了互联网上的大规模文本数据集,包括维基百科、新闻、小说等等 |
| 模型结构不同 | 由多个Transformer编码器组成,最后一层会输出整个输入序列的表示 | 由多个Transformer解码器组成,只输出最后一个单词的表示 |
how to pre-train?
- 最早的跟预训练有关的模型,应该是CoVe,是一个基于翻译任务的一个模型,其用encoder的模块做预训练。但是CoVe需要大量的翻译对,这是不容易获得的,能不能通过一大段没有标注的语料进行预训练呢?
-
比较直觉的self-supervised learning就是预测下一个单词是什么。给出的解法就是将一个token输入到网络中,经过softmax之后,得到下一个token的概率分布。
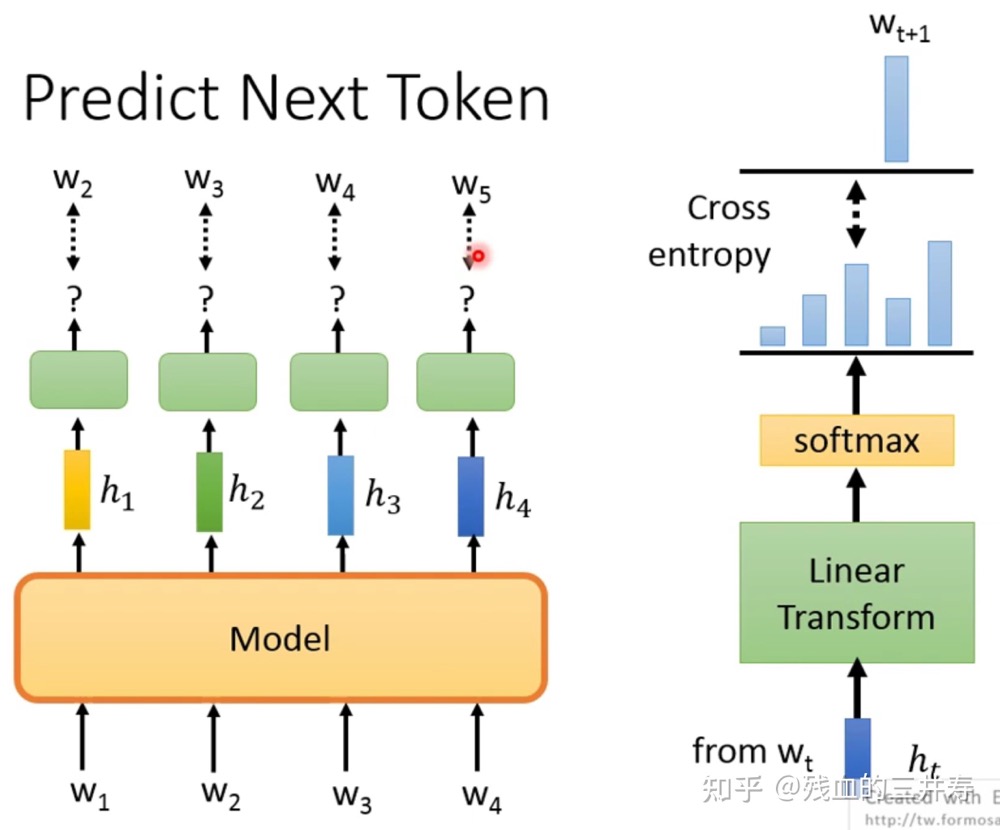
- 其中使用LSTM(上图的model = LSTM)做predict next token的工作有elmo,以及ulmfit。
- 使用self-attention的方式(上图的model = LSTM)进行next token prediction。
有哪些预训练模型?
- Left-to-Right LM: GPT, GPT-2, GPT-3。适合文字接龙
- Masked LM: BERT, RoBERTa。适合文字填空
- Prefix LM: UniLM1, UniLM2
- Encoder-Decoder: T5, MASS, BART
Task-specific Fine-tuning
语言模型虽然可以对训练过的语言产生统计意义上的理解,例如可以根据上下文预测被遮盖掉的词语,但是如果直接拿来完成特定任务,效果往往并不好。因此,我们通常还会采用迁移学习 (transfer learning) 方法,使用特定任务的标注语料,以有监督学习的方式对预训练模型参数进行微调 (fine-tune),以取得更好的性能。预训练是一种从头开始训练模型的方式:所有的模型权重都被随机初始化,然后在没有任何先验知识的情况下开始训练:这个过程不仅需要海量的训练数据,而且时间和经济成本都非常高。因此,大部分情况下,我们都不会从头训练模型,而是将别人预训练好的模型权重通过迁移学习应用到自己的模型中,即使用自己的任务语料对模型进行“二次训练”,通过微调参数使模型适用于新任务。
how to fine-tune? fine-tune部分旨在根据预训练的model添加部分层从而可以解决下游任务。
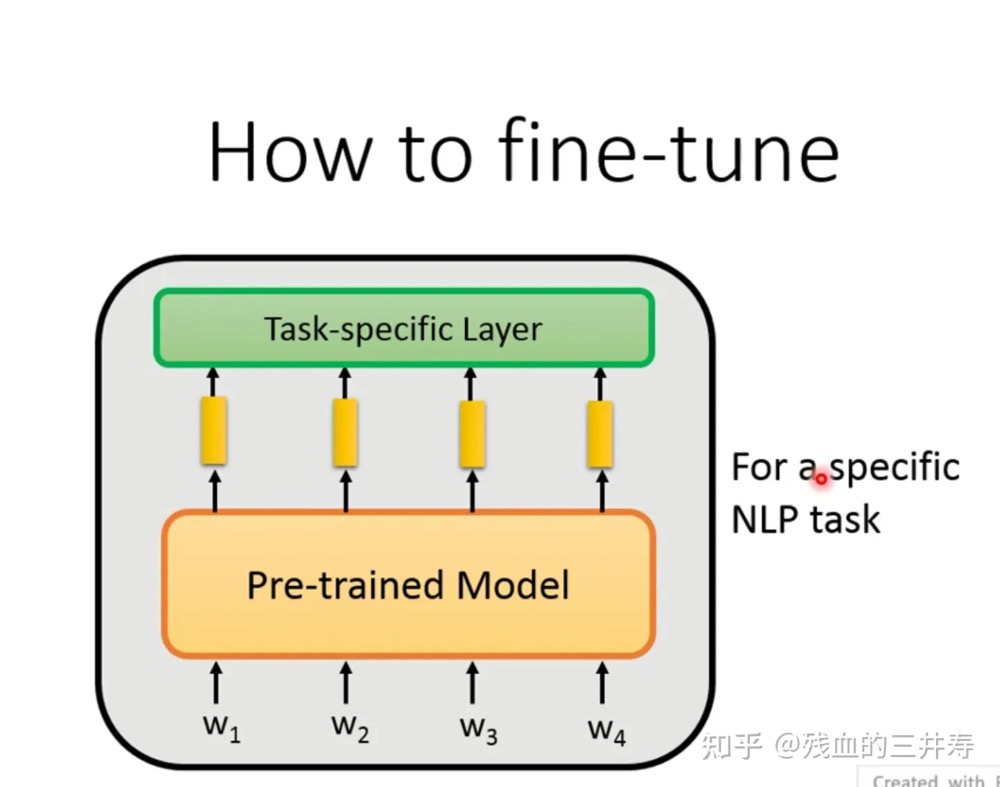
如何在预训练好的模型中再加入一部分让其可以实现下游任务?现有的NLP任务的分类,其中按照输入可以分为两类,按照输出可以分为四类(one class;class for each token;copy from input;general sequence)。
输入可以分为两类
- one sentence; 如句子分类
- mutliple sentences; 比如QA,自然语言推理,需要在两个句子之间加入一个特殊的符号
[SEP](转为一个句子)。
输出可以分为四类
- one class; BERT的解法是让一个特殊的符号
[CLS]作为整个句子的表示,之后将[CLS]的embedding输入到一个分类器中,进行分类任务。也可以像其他模型一样,将所有token的embedding都输入到一个模型中(可以是各个token embedding的均值,也可以是各个token输入到RNN,再得到下一层的嵌入),进行分类。 - class for each token; 如果任务是对每一个token进行分类的话,就需要将每一个token的embedding输入到一个网络中,对其进行分类。
- copy from input。 比如说Extraction-based QA任务,其任务就是输入一段原文和一个问题,之后在原文中标注好哪个token是开始,哪个token是结尾。BERT论文中的解法就是设计了两个可以训练的embedding(一个是start,一个是end),之后用start和end向量分别和BERT得到的嵌入求内积,之后再通过softmax,计算哪个最大,就是最后的结果。
- general sequence。生成任务
- BERT可以作为一个encoder,需要我们自己去设计一个decoder,但是decoder是没有经过预训练的。
- 让pre-training模型当作decoder来使用,其方法就是输入一个
[sep]之后让model输出一个东西,再将模型的输出作为模型的输入,以此类推,不断的得到输出结果。
如何进行fine-tune呢?大模型参数高效微调技术原理综述(一)-背景、参数高效微调简介 对应代码可以查看大模型LLM微调经验总结
- 全部微调:使用新的数据集对整个模型进行微调,包括预训练的部分和新加的任务特定层。这种方法通常需要大量的数据和计算资源,并且需要更长的训练时间,但能够获得最好的性能。
- 部分微调:只对特定的层或几个层进行微调,通常是模型的最后几层或添加的任务特定层。这种方法通常需要较少的数据和计算资源,训练时间也较短,但性能可能不如全局微调。
- 冻结部分层:将预训练模型的前几层(如 BERT 的前若干层)冻结,只对后面的层进行微调。这种方法可以减少微调的参数量和计算量,但可能会影响性能。
- 动态掩码微调:对于需要进行序列标注任务的预训练模型,可以使用动态掩码微调的方法,即只对标注序列的位置进行微调,对其他位置的参数进行冻结。这种方法可以减少微调的参数量,提高计算效率。
- 半监督微调:使用少量的标注数据和大量的无标注数据对模型进行微调,以提高性能。这种方法需要使用半监督学习的技术,如自监督学习或基于对抗学习的方法。
- Prompt 工程:更偏向应用与业务,通过修改输入给大模型的提示词,调优输出结果。 前面五种,都需要一定的操作成本,且一般由算法工程师或所谓 AIGC 工程师来完成,最后一种是在解决大模型从生产到应用的“最后一公里”问题,目前是必备的,当下一般由算法工程师或其他技术角色兼任,或是企业招聘专人负责。
对于大模型的两种不同的期待
- 成为专才。比如bert(做文字填空的,所以不能“说话”)
- 在进行具体的任务之前需要改造:加外挂(即为模型加额外模块)和微调参数(fine tune)。
- 有机会在专一任务有机会跑赢通才。
- 成为通才(处理多任务)。GPT 提出的MQAN模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而无需再为每一个子任务单独设计一个模型。基于上面的思想,作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集 。例如当模型训练完“麦克乔丹是历史上最好的篮球运动员”语料的语言模型之后,便也学会了(question:“谁是最好的篮球运动员 ?”,answer:“麦克乔丹”)的Q&A任务。所以这也是 GPT 的一个特点。
- 需要额外进行prompt。
- Multitask learning as Question Answering。所有自然语言的处理都是问答问题。
- 只要重新设计 prompt 就可以快速开发新功能,不用写程序。
比如做情感分析,你可以专门做一个情感分析的模型。也可以你给一点情感分析的例子,让模型去做文字接龙。
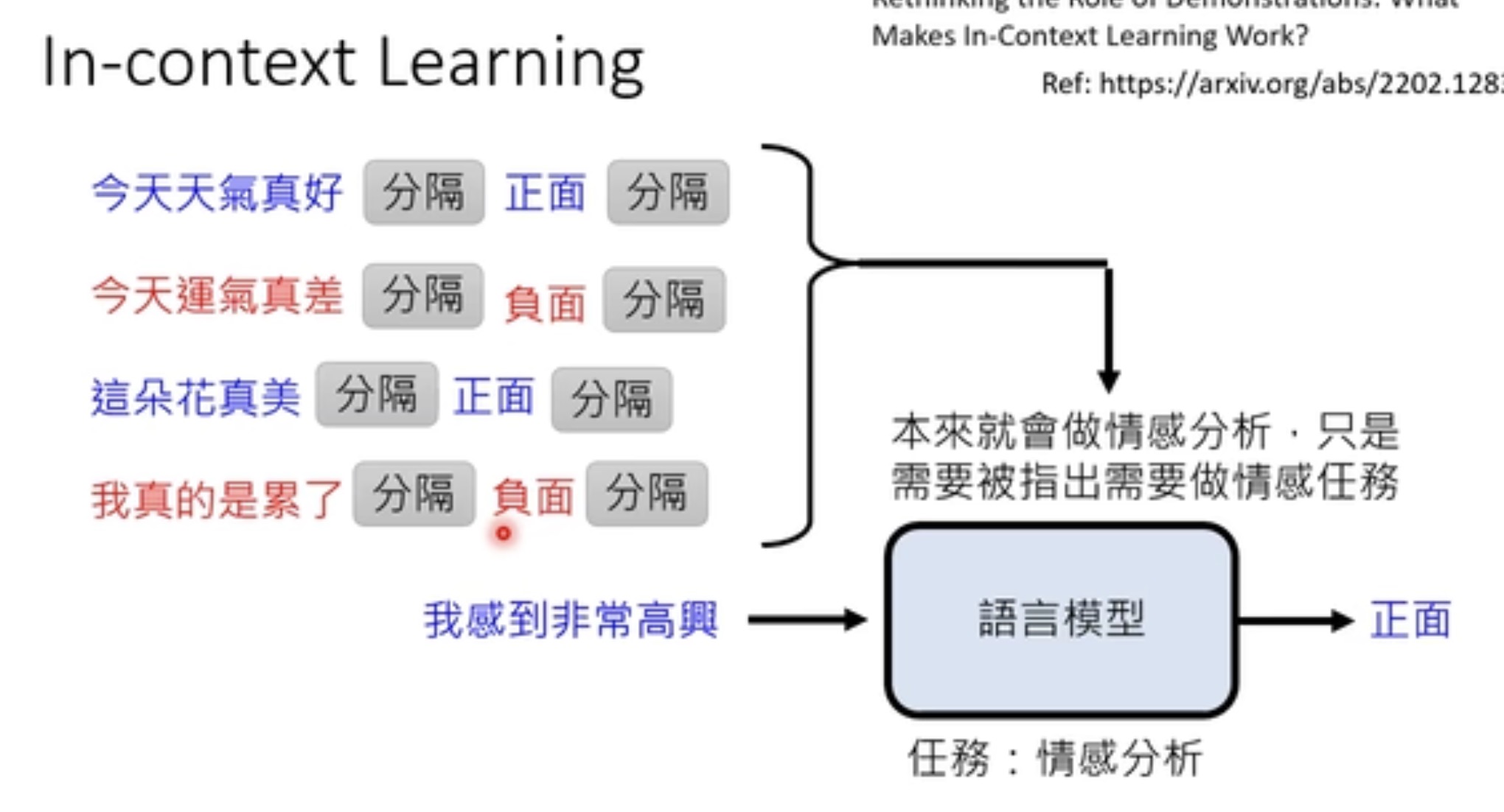
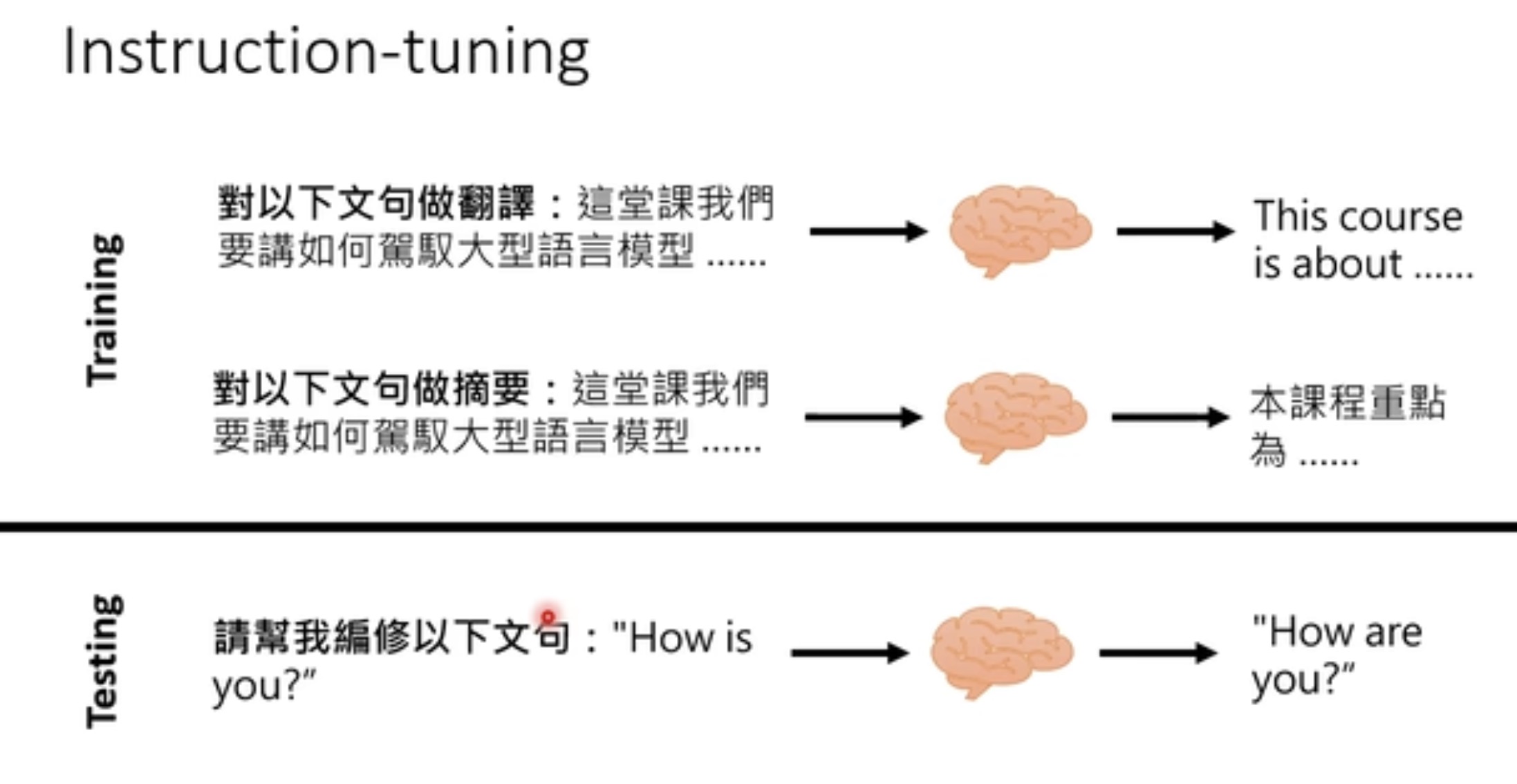
再进一步,毕竟找范例有点麻烦,让机器根据叙述知道我们让它干嘛(instruction-tuning读懂人类的指令)。把任务用人类的语言描述出来,变成一个dataset,然后让llm 学到你让它干嘛,进而可以 generalized 到没有看过的指令上。
GPT-1到ChatGPT的演进
李沐老师的「跟李沐学 AI」 系列视频专栏分析了整个 GPT 系列的相关论文,深入浅出,形象生动,强烈推荐!
GPT-1到ChatGPT的演进和技术原理Transformer的出现完全打开了大规模预训练语言模型(Pre-trained Language Model , PLM)的空间,并且奠定了生成式AI的游戏规则。
- Transformer相比之前论文的novalty在于:大胆地抛弃了传统的CNN和RNN基础模型,整个网络结构完全是由Attention机制组成。更准确地说,Transformer由且仅由自注意力(self-Attenion)机制和前馈神经网络(Feed Forward Neural Network)组成。
- 从实际应用的角度来看,Transformer的主要贡献(contribution)在于以下几个方面:
- 突破了RNN模型不能并行计算的限制
- 精度和模型复杂度相比RNN + Attention系列模型更优
- Transformer本身也可以作为base model扩展
BERT仅使用了Transformer的编码器(Encoder)部分进行训练,而GPT-1则只使用了Transformer的解码器(Decoder)部分,实现了NLG层的统一。将海量知识融入到一个统一的模型中,而不针对每个特定任务分别训练模型,使AI解决多类型问题的能力大大加强。
- GPT-1: 预训练+微调模式,117M参数、12层、2亿单词。 利用 transformer 架构成功捕捉到了文本中相距较远的依赖关系。PS:GPT-1先于Bert出现。
- 预训练阶段:基于Transformer Decoder架构,以语言建模作为训练目标(文字接龙)。
- 微调阶段:将训练好的Decoder参数固定,接上一层线性层,通过有监督训练任务(分类(Classification)、文本蕴含(Entailment)、相似性(Similarity)、多选题(Multiple Choice))微调线性层的参数,从而进行预测。
- GPT采用Masked-Attention,对模型和训练数据的要求会更高,因为模型能读到的信息只有上文。而采用普通Attention的Bert在训练阶段就能同时读到上下文。这个性质决定了GPT模型越来越大的趋势(GPT需要把模型做大,训练数据做丰富,才能达到超越Bert的效果)。但是,长远来看,Masked-Attention是push模型更好理解文字的重要手段,毕竟在现实中,我们更希望培养模型知上文补下文,而不是单纯地做完形填空。GPT2的核心思想是:只要我的数据够多够好,只要我的模型够大够强。我可以直接去掉fine-tune,训练出一个通用的模型。
- GPT-2的目标是试图用一个模型去做多个NLP任务,在无监督数据中包含很多有监督的任务内容,如果在无监督数据上学习的足够充分,就无需下游任务进行微调,只需将任务输入进行转化,并增加对应的提示信息,就能够进行下游任务的预测。例如在解决英译法的翻译任务时,将输入变成“翻译成法语,英文文本,法语文本”。
- 通俗地解释一下:语言模型实际上是一种自监督的方式,根据已知的词预测未知的词,只是不需要显示地定义哪些字段是要预测的输出。那如何用无监督多任务的训练方式实现语言模型自监督训练+多任务微调的效果呢?带有任务性质的数据集。我们只需要将input、output和task都表示为数据,例如在一个英文翻译成法语的机器翻译任务中,我们只需要将样本、标签和任务表示成
(translate to french,english text,french text),就实现了对P(output|input,task)的建模。 - 重要的是,这种方式可以实现无监督训练,并且里面的task可以变化,也就是说现在GPT-2可以实现无监督多任务训练而不需要第二阶段分不同任务有监督的微调!所以,GPT2在训练数据上,玩出了花样。它从著名的在线社区Reddit上爬取训练数据(数据具有一定的问答特性),并按社区用户的投票结果筛选出优质的内容。
- 最后我们看到,GPT-2相对于GPT-1,最大的改进就是去掉了第二阶段的微调(fine-tune)层,OpenAI 在预训练过程中,将各类 NLP 任务的数据都放到 GPT-2 的训练数据中,帮助大模型更好地理解和生成文本。在经过这些步骤以后呢,GPT-2 的预训练模型在未经过任何微调的情况下,就能战胜许多下游任务的最佳结果。
- 通俗地解释一下:语言模型实际上是一种自监督的方式,根据已知的词预测未知的词,只是不需要显示地定义哪些字段是要预测的输出。那如何用无监督多任务的训练方式实现语言模型自监督训练+多任务微调的效果呢?带有任务性质的数据集。我们只需要将input、output和task都表示为数据,例如在一个英文翻译成法语的机器翻译任务中,我们只需要将样本、标签和任务表示成
- GPT-3 。GPT-2 “零样本学习” 的方式仍然存在一定的局限性,因为下游的使用者,很难把新的下游数据注入到模型中(PS:没见过的下游任务?)。因为 GPT-3 预训练模型的规模已经变得非常庞大了,很少有机构有能力承担微调所需的巨大算力成本。OpenAI 提出了一个更新的理念,也就是全新的“少样本学习”(Few-Shot Learning)的概念。 允许下游使用者通过提示词(prompt)直接把下游任务样本输入到模型中,让模型在提示语中学习新样本的模式和规律,这种方法的学名叫做 in-context learning。
- 只给提示就是zero-shot,给一个示例叫做one-shot,给少量多个示例就是few-shot。

- 只给提示就是zero-shot,给一个示例叫做one-shot,给少量多个示例就是few-shot。
- 从GPT2到GPT3,Zero-shot和Few-shot的方式被证明可以使得模型能够去除fine-tune部分,训练一个通用的语言模型,辅助少量样本可以对没见过的下游任务也有一定的能力。 但 GPT 本身也存在一些不完善的地方,比如下面这些缺点也是 GPT 需要改进的地方。
- 对于一些命题没有意义的问题,GPT 不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于海量数据的存在,很难保证 GPT3 生成数据的安全性,数据会存在一些非常敏感的内容,比如 Copilot 就把用户真实身份证号码生成出来。数据缺失一定的清洗,甚至包含种族歧视,性别歧视,宗教偏见等。
- InstructGPT相对GPT-3要解决的是大模型的alignment(对齐)问题。GPT-3 使用大量互联网上的语料,训练完成后,并不适合对话这个场景。积累大量指令对齐的 QA(问题-回答)训练数据,成本很高,此外大型语言模型会生成一些不真实、有毒(不符合人类道德伦理等)或对用户毫无帮助的输出,显然这些与用户期待的不一致。InstructGPT 不是为了追求真正的正确答案,而是追求让人更加认可的答案。
- 大模型在预训练过程中见识了各种各样的数据,因此针对一个prompt/instruct(提示)会输出什么东西,也可能是多种多样的。但是预训练数据中出现的数据模式,不代表都是人类在使用模型时希望看到的模式,原因是 predicting the next token on a webpage from the internet is different from the objective “follow the user’s instructions helpfully and safely”,预训练阶段的目标函数(预测下一个token)与人类对LLM真实的期望(有帮助、安全)不一样。因此需要一个alignment(对齐)的过程,来规范模型的“言行举止”。而实现这个过程InstructGPT引入了RLHF机制(人类反馈强化学习),实际上6年前的AlphaGo正是充分利用了强化学习,才在围棋领域实现了所到之处无敌手。简单点说,InstructGPT就是在GPT-3基础上利用RLHF机制(人类反馈强化学习)做了微调,以解决大模型的alignment(对齐)问题。
- 整个过程就是老师(人类标注员)先注入一些精华知识,然后让模型试着模仿老师的喜好做出一些尝试,然后老师对模型的这些尝试进行打分,打分之后,学习一个打分机器,最后打分机器就可以和模型配合,自动化地进行模型的迭代,总体思路称为RLHF:基于人类反馈的强化学习。
为什么引入RLHF
base model会“文字接龙”之后,对于每个问题,人工标注者都会比较辅助模型的多个答案,并标注出最佳答案。这一步骤称为从人类反馈中强化学习(RLHF)。
在 LLM 革命之前,已经存在几种流行的语言模型评估指标,这些指标通过比较模型的生成输出与参考输出来操作。通常,这些参考输出是由人工手动编写的。比如ROUGE 分数最常用于评估摘要任务,它通过简单地计算参考输出中也出现在模型生成输出中的单词数量来工作。虽然这些固定指标对于摘要或翻译等任务效果相当好,但它们对于更开放式的任务效果不佳,包括像信息寻求对话这样的生成任务。为什么会这样?这些指标与人类对模型输出的判断之间往往存在较差的相关性。ROUGE 和 BLEU 量化了模型输出与某个参考输出匹配的程度。然而,对于许多问题,模型可能产生多个同样可行的输出——像 ROUGE 这样的固定指标无法考虑到这一点。我们有一个不一致的问题——所测量的是两个文本序列之间的重叠度——而我们实际想要测量的是输出质量。下一个 token 预测是几乎普遍用于 LLM 的训练目标(即在预训练和有监督微调期间)尽管下一个 token 预测具有巨大影响和普遍实用性,但结果 LLM 的性能高度依赖于数据质量,并且模型只学习产生与其训练集相当的输出。相比之下,RLHF 为我们提供了直接根据人类反馈优化 LLM 的能力,从而避免了 LLM 的训练目标与训练的真正目标——产生人类用户评估的高质量输出——之间的不一致。如果完全不做模型对齐,那输出的结果就完全符合语料中的数据分布,而互联网上出现次数最多的内容不一定就是真理。
RLHF——让大模型对齐人类偏好 所谓对齐人类偏好,主要体现在以下三点:有用(遵循指令的能力)、诚实(不容易胡说八道)、安全(不容易生成不合法的,有害,有毒的信息)。因此在大模型的训练阶段,如果引入人类的偏好或者人类的反馈来对模型整体的输出结果进行进一步优化,显然是要比传统的“给定上下文,预测下一个词”的损失函数要合理的多。即使用强化学习的方法,利用人类反馈信号直接优化语言模型。
万字长文详解大模型平台技术栈经过预训练之后,我们可以获得类似于 LLaMA 这样的 Base Model,但这距离 ChatGPT 这种 Assistant Model 还有一段距离。Base Model 并不能像 Assistant Model 一样能够很好的适用于指令理解、多轮聊天和 QA 问答等场景,而只是总是倾向于去续写文本(causal language modeling)。也即是说,Base Model 并不能很好的和用户的意图对齐 (Align),有可能会生成无用、甚至是有害的内容。为了解决这个问题,算法科学家们提出了很多的解决方案,典型代表就是以 InstructGPT 这种先经过 Supervised Finetuning,然后通过 Reward Modeling 和基于人类反馈的强化学习 RLHF。DeepSpeed 团队也发布了 DeepSpeed-Chat,开源了一个支持端到端的 RLHF 的训练和推理系统,复刻了 InstructGPT 论文中的训练模式,并确保三个阶段一一对应:监督微调SFT;奖励模型微调RM;基于人类反馈的强化学习RLHF。PS: 通过人类反馈进行模型微调。
- 模型通过生成答案并接收反馈来学习
- 在强化学习中,我们为模型提供指令,但并不提供人工编写的答案。模型需要自己生成答案。评分机制(例如人类)会读取生成的答案,并告诉模型这些答案的质量。模型的目标是如何回答以获得高分。
- 另一种机制是模型生成多个答案,评分机制告诉模型哪个答案最好。模型的目标是学习生成高分的答案,而不是低分的答案。
- 语言模型(至少)有三种交互模式:
- 文本型(text-grounded): 为模型提供文本和说明(“总结此文本”,“基于此文本,以色列的人口是多少”,“本文中提到的化学名称是什么”,“将此文本翻译成西班牙语”等),让模型基于我们提供的文本生成答案;
- 求知型(knowledge-seeking): 向模型提供问题或指导,让模型根据内在知识(“流感的常见原因是什么”)提供(真实)回答。
- 创造型(creative): 为模型提供问题或说明,然后让模型进行创造性输出。(“写一个关于…的故事”)
- 对于语言生成模型来说,监督学习/指令调优最大的问题是它们只能复制演示者给出的确切答案,但实际上,人类语言可以用多种方式传递相同的信息,它们都是切实可行的。如果因模型轻微偏离人类规定的文本而受到“惩罚”,可能会使模型产生困惑。我们当然可以继续逼迫模型去学习更难学习的遣词造句,尽管模型已经学会了生成具有同样意思、合法的替代性回答。因此,我们非常看好强化学习训练提供的多样性表达。
- 监督学习(SL)只允许正反馈(我们向模型展示一系列问题及其正确答案),而RL允许负反馈(模型被允许生成答案并得到反馈说“这答案是不正确的”),相比正反馈,负反馈要强大得多。
- 对于求知型查询,我们希望模型在对答案没把握的情况下能够如实回答“我不知道”或拒绝回答这一问题。对于这类交互模式,由于监督训练可能会让模型撒谎,所以我们必须使用RL。核心问题是:我们希望模型根据内部知识进行回答,但我们并不知道模型内部知识包含的内容。 在监督训练中,我们给模型提供问题及正确答案,并训练模型复制提供的答案。这里有两种情况:(1)模型“知道”答案。这种情况下,监督学习能够正确推动模型将答案与问题相关连,并且有望让模型执行相似的步骤,回答将来遇到的类似问题。这是所期望的行为。(2)模型不知道答案。在这种情况下,监督训练还是会促使模型给出答案。现在,我们有两种选择。一种可能是,它会促使模型记住特定的问答对。这种做法本身并没什么坏处,但不太高效,因为我们的目的是让模型具有泛化能力,并且能回答任何问题,而不只是那些在训练数据中出现的问题。但如果我们使模型在这些情况下能做到泛化,那么实际上就是在教模型捏造答案,相当于鼓励模型“说谎”,这很不好。由于我们无法确定模型知道哪些信息或不知道哪些信息,所以无法避免第二种情况,这对监督训练来说是一个真实且严重的问题。我们不能仅依靠监督学习来训练模型生成可信任回答,还需要强化学习的加持。与监督学习不同,强化学习不会鼓励模型编造答案:即使模型最初确实猜对了一些答案并错误地学习了“编造”行为,但长远来看,模型会因编造答案的得分较低(很可能是不正确的)而学会依赖内部知识或选择放弃回答。
- 长期以来,使用强化学习训练生成语言任务对大多数玩家来说都不切实际:由于缺乏可靠的自动评分指标,强化学习训练需要对每个训练样本进行人工反馈。这既耗时又昂贵,特别是对于需要查看数千到数万甚至数十万个示例才能学习的模型。然而,强化学习训练现在变得实用了:首先,出现了可以从较少示例中学习的大型预训练语言模型。更重要的是,这些模型为强化学习循环(RL loop)中去掉人类参与铺平了道路。监督训练对于文本相关的任务非常有效,而且大型模型可以很好地学习执行一些任务。例如,让模型确定两个文本是否意思相同,或者一个文本是否包含另一个文本中没有的事实,根据经验来看,大型语言模型(甚至中型语言模型)可以使用监督学习可靠地学习执行这些任务,这为我们提供了可用于强化学习设置的有效自动评分机制。
chatgpt 是怎么炼成的?
ChatGPT (可能)是怎么炼成的 - GPT社会化的过程 (李宏毅)
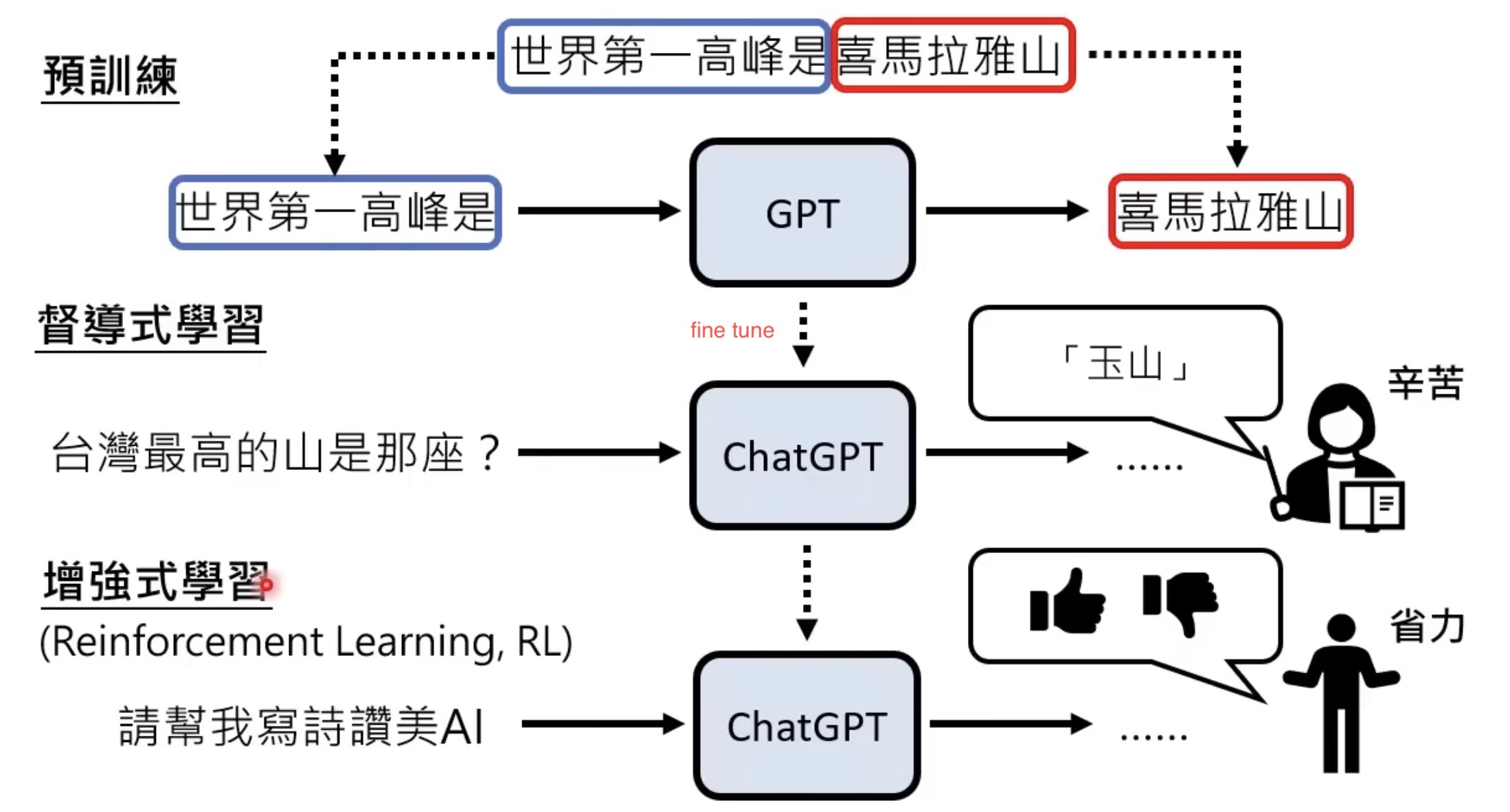
- 学习文字接龙
- 输入“你好”,gpt 可以接“美”(你好美)。当然,“你好” 后面也可以是 “嘛”,也可以是“高”。gpt 的输出是随机的,哪个在它学习的素材里出现的概率高就显示哪个。
- 文字接龙的学习是不需要人工标注的,网络上的每一段文字都可以教机器做文字接龙。
- 文字接龙有什么用?可以回答问题。你问gpt “台湾最高的山是那一座?”,gpt 可能接“玉”,你输入“台湾最高的山是那一座?玉”,它可能会接“山”。我们就知道答案是“玉山”。
- 你问gpt “台湾最高的山是那一座?”,gpt 也能有其它回答,比如gpt学习的素材里有一个选择题:“台湾最高的山是那一座?A 玉山;B 雪山”,也可能“台湾最高的山是那一座?谁能告诉我答案?”。这个时候chatgpt 是一个自由自在的孩子。PS:基础LLM(Base LLM)的特点是基于大量文本训练数据,来预测下一个最有可能出现的单词,缺点是不可控,容易输出有问题的文本。
- 人类老师引导文字接龙方向。gpt ==> chatgpt
- gpt 在网络上看到过各式各样奇怪的东西,可能产生各式各样奇怪的回答,不知道哪些是人类希望它回答的。
- 找人来思考想问gpt的问题,并人工提供正确答案。针对“台湾最高的山是那一座?”,gpt 有多个回答,然后由人来告诉它(标注) 人类想要的回答是“玉山”,人类只需要告诉机器,哪个答案是比较好的,哪个答案是比较差。
- 模仿人类老师的喜好
- 训练一个模仿人类老师的模型,teacher model: 给一个问题,再给一个gpt 提供的答案,它负责输出一个分数。它学习的目标就是模仿人类的标准/偏好。
- 用增强式学习向模拟老师学习
- 问gpt “世界最高的山是哪座?”,gpt 接了一句“世界上最深的海又在哪里?”,这是 对gpt 是一个合理的回答,但不是人类想要的。
- 把上述问题 和答案丢给 teacher model(已经学会了人类的偏好),teacher model 给一个score,也就是增强式学习(reinforcement learning)的reward。
- 接下来就是根据 reward 调整gpt的参数,目标是获取更高的score。经过reinforcement learning之后,就是chatgpt 了。
使用者感受chatgpt 的功能是:生成式学习。但chatgpt 实际做的事儿是 分类:给一句话,从所有的word 中选出一个word输出。
- 如何精准提出需求(Prompting)?它不是一个聊天机器人,它只是根据你说的话生成后面的话,得调教它,靠人工还是靠系统?
- 如果更正错误?chatgpt的预训练资料只有到2021年。chatgpt 在生成内容的时候,并不真正理解所生成的内容,虽然很多时候它是对的,但因为不理解所以还是会出错,甚至是一些虚假的内容,这在比如企业客服场景中是不合适的(客服场景以结果为导向,引导客户购买或者 告诉客户哪个更好,有时候需要给出标准答案,比如价格等,这个时候说不知道也比给出错误的结果强,企业很难接受不可控的输出)
- 侦测一段话是不是AI 生成的。
- 泄露机密。比如教普通人制备生物武器
- 限制其一次性输入的文本量:限制其在训练、推理期间与世界互动的能力 语言大模型100K上下文窗口的秘诀
其它
投身LLM,要从本质上想明白的三个问题:未来是什么,哪些机会更好,我们要怎么准备 好文。从深度学习发展前10年的历程来看,模型精度提升,主要依赖网络在结构上的变革。 例如,从AlexNet到ResNet50,再到NAS搜索出来的EfficientNet,ImageNet Top-1 精度从58提升到了84。但是,随着神经网络结构设计技术,逐渐成熟并趋于收敛,想要通过优化神经网络结构从而打破精度局限非常困难。近年来,随着数据规模和模型规模的不断增大,模型精度也得到了进一步提升,研究实验表明,模型和数据规模的增大确实能突破现有精度的一个局限。
所谓的“涌现”,可能是测评指标不够平滑带来的错觉。就像养一个小孩你会觉得它突然会走了,突然会说话了,但是他的肌肉力量和语言能力可能是平缓发展的,只是我们评估能力是看最终的那个走出的第一步和说出的第一句话。大模型也是一样,Loss 一直在降,能力一直在涨,测评指标却是跳变的,最后惊呼“涌现”了。所谓的“涌现曲线”完全取决于你用什么尺子去量。
留下评论