数据湖
前言
降本增效的背后,谈谈阿里云存储数据湖3.0因为企业无时无刻地不在产生数据,这些数据需要进行分析,才能激活它的价值。数据分析可以分为实时性分析和探索性分析。实时性分析是用已知数据回答已知问题;探索性分析是用已知数据回答未知问题,所以需要预先把数据都保存下来,这无疑会增加许多存储费用。为了压缩存储成本,阿里云选择了存算分离架构,这种架构提供了独立的扩展性。客户可以做到数据入湖,计算引擎按需扩容,这样的解耦方式会得到更高的性价比。现在,数据湖已经进入 3.0 时代。在存储上,以对象存储为中心,实现了多协议全兼容、统一元数据管理;在管理上,面向湖存储+计算的一站式湖构建和管理,做到智能“建湖”和“治湖”。
从 HDFS 将数据持久化到对象存储
- HDFS 的存算耦合设计扩展性差。
- HDFS 难以适配云原生化
- 对象存储也有一些弊病,它不能很好的适配 HDFS API,由于网络等原因性能跟本地盘比也相差很多,另外 list 目录等元数据操作也很慢。
阿里云EMR数据湖文件系统: 面向开源和云打造下一代 HDFS 未细读
存算分离的需求出现与问题解决
从 Hadoop 到云原生, 大数据平台如何做存算分离2006 年 Hadoop 刚发布,这是一个 all-in-one 的套装,最早有三个核心的组件:MapReduce 负责计算,YARN 负责资源调度,HDFS 分布式文件系统,负责存数据。
- 在这三个组件中,发展最迅速和多元的是计算组件这一层,最早只有一个 MapReduce,但业界很快在计算层上面各显神通,造出了一大堆的轮子。包括有 MapReduce,Tez,Spark 这样的计算框架,Hive 这类数据仓库,还有 Presto、Impala 查询引擎,各种各样的组件。
- 底层存储经过了大概 10 年左右的时间,一直是 HDFS 一枝独秀,带来的一个结果就是它会成为所有计算组件默认的设计选择。上面提到的这些大数据生态里发展出来的各种组件,都是面向HDFS API 去做设计的。有些组件也会非常深入的利用 HDFS 的一些能力,比如深入看 Hbase,在写 WAL log 的时候就直接利用了HDFS 的一些很内核的能力,才能达到一个低时延的写入;
- 为什么 Hadoop 在设计之初是一个存储计算耦合的架构?一个不能忽略的重要的原因是,网络通讯和硬件的局限。在机房里面,当时我们面对的最大的问题就是网卡,主流的还是百兆网卡,刚开始用千兆网卡。
- 从 2006 年发展到 2016 年左右,这十年我们看到了一些新的变化,第一企业数据增长很快,但是算力的需求其实长得没那么快。这些任务靠人开发,不会发生一天一倍的去涨的情况,但是产生的数据的速度是是非常快的,有可能是指数型的。在这个背景下,存算耦合的硬件的拓扑的架构就给扩容带来了一个影响,当存储不够,就要去加机器。但是不能只加机器,不能只有硬盘,因为在存算耦合的架构上,数据的节点还需要负责计算,所以 CPU 和内存也不能太差。这样扩出来的算力对企业来说造成了更大的浪费。而且,数据调度亲和性的策略在实际的业务中未必能发挥作用,因为数据有可能会有很明显的倾斜,可能会有很局部的热点,需要非常多的算力。大数据平台的任务可能调度到有限节点上,I/O 仍然有可能成为瓶颈。在这个过程中硬件也有变化,给存算分离架构带来了可行性。存储方面,在今天大的数据集群里面,许多企业还是使用磁盘来存储,磁盘的吞吐提升了一倍,从 50MB/s 每秒提升到 100MB/s。一个配置了万兆的网卡的实例,可以支持差不多 12 块磁盘的峰值吞吐,对于大部分企业来说已经够用了,以前网络传输的瓶颈就基本不存在了。不仅网卡,磁盘也在变化,软件也在变化。最早的时候,我们可能用 csv 或者打一个 zip 包,现在有了更高效的压缩算法,比如说有 snappy、lz4、zstandard 这些。而且有了 Avro、Parquet、Orc 这些列存格式。这些变化加在一起,都进一步减小了需要传输的数据量。
- 从2013、2014年,行业内开始看到一些存算分离架构的尝试。最初的方案比较简单,就是独立部署 HDFS,不再和负责计算 worker 去混合部署(DataNode 节点上不再部署 Node Manager)。在机房做这样的改造是可行的,但当我们去使用云上资源的时候,这个方案的弊端就显露了。过去,企业在机房使用裸硬盘去搭建一套 HDFS,为了解决裸硬损坏的风险, HDFS 设计了多副本的机制,来保证数据安全性;同时多副本还承载着保证数据可用性的作用。当数据被迁移到云上时,云提供给用户的是经过多副本机制存储的云盘,不再是裸硬盘了,企业用这块云盘去搭一个HDFS,又要做3副本,企业数据在云上要存 9 副本,成本立马飙升了好几倍。另一个是HDFS 本身的局限。首先是,NameNode,只能垂直扩展,并不能分布式扩展说扩出更多的 NameNode 节点,限制了 HDFS 单集群去管理的文件数量。当 NameNode 的资源占用比较多,负载又高的时候就有可能会触发 FullGC 。一旦触发这个问题之后,它会影响到整个 HDFS 集群可用性。根据实际运维经验,一般在 3 亿文件以内,运维 HDFS 还是比较轻松的,3 亿文件之后运维的复杂度就会明显提升,峰值可能就在 5 亿文件左右,就达到单机群的天花板了。
- 层级命名空间和平坦命名空间相比,扩展性要差很多:这里主要就是因为层级命名空间需要维护父子关系。HDFS 为了简化这个关系的维护,使用了单点 NameNode 的设计,数据还直接放在内存里,这导致这个单点很难扩展,性能上限也比较低,通常一个系统只能保存数亿文件,几十 PB 的数据。虽然社区后来推出了 Federation 的功能,但没有本质上解决问题。对象存储则不同,平坦命名空间里的每个对象天然没有任何关联,可以作为独立的个体对待,关联性的打破让扩展性更容易做。云厂商的对象存储服务因此可以做到一个集群 EB 级的容量,万亿条元数据,比 HDFS 大很多。
- 随着云计算技术的成熟,企业存储又多了一个选项,对象存储。对象存储适用于大规模存储非结构化数据的数据存储架构,其设计的初衷是想满足非常简单的上传下载数据,企业存储系统拥有超级强大的弹性伸缩的能力,还能保证低成本的存储。最早从 AWS 开始,后来所有的云厂商其实都在往这个方向发展,开始推动用对象存储去替代 HDFS。但当对象存储被用来去支持复杂的 Hadoop 这样的数据系统,就会发现如下的一些问题。
- 文件 Listing 的性能比较弱。 对象存储没有树形结构的,它的整个存储结构是扁平的。当用户需要存储成千上万,甚至数亿个对象,对象存储需要做的是用 Key 去建立一份索引,Key 可以理解为文件名是该对象唯一标识符。如果用户要执行 Listing,只能在这个索引里面去搜索,搜索的性能相比树形结构的查找弱很多。
- 对象存储没有原子 Rename,这样的改名操作在 HDFS 和其他文件系统中是原子的,速度快,而且有事务性保证。但由于对象存储没有原生目录结构,处理 rename 操作是一个模拟过程,会包含大量系统内部的数据拷贝,会耗时很多,而且没有事务保证。用户在使用对象存储时,常用文件系统中的路径写法作为对象的 Key,比如 “/order/2-22/8/10/detail”。改名操作时,需要搜索出所有 Key 中包含目录名的对象,用新的目录名作为 Key 复制所有的对象,此时会发生数据拷贝,性能会比文件系统差很多,可能慢一两个数量级,而且这个过程因为没有事务保证,所以过程中有失败的风险,造成数据不正确。
- 对象存储数据最终一致性的机制,会降低计算过程的稳定性和正确性。举个例子,比如多个客户端在一个路径下并发创建文件,这是调用 List API 得到的文件列表可能并不能包含所有创建好的文件列表,而是要等一段时间让对象存储的内部系统完成数据一致性同步。
- 对象存储对于 Hadoop 组件的兼容性相对弱。
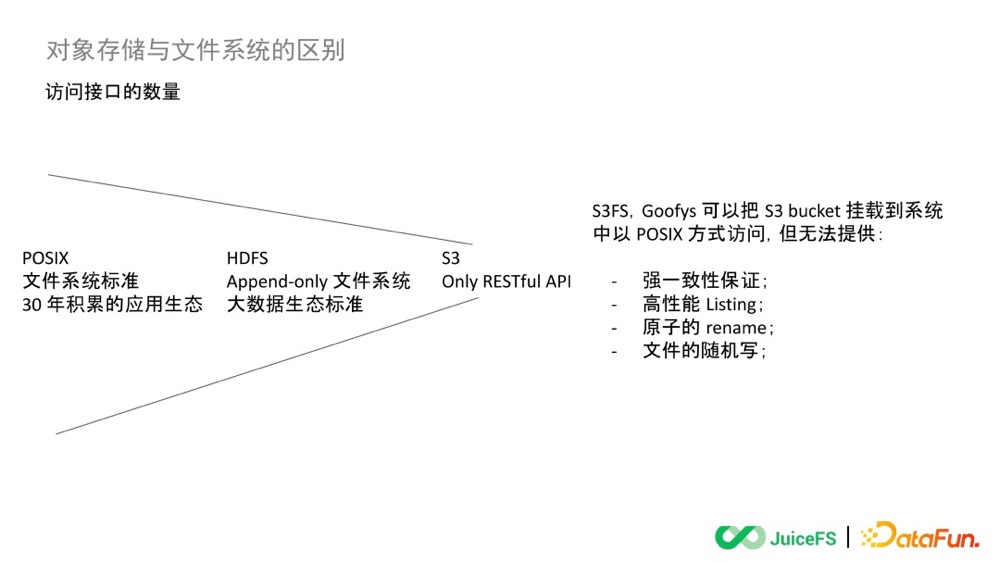
目前的方案是用 JuiceFS 对接对象存储,通过应用层的服务,全部以 POSIX 的方式挂载上去,大家就可以无感地去请求 JuiceFS 里的文件。平台和平台之间全部都是通过 JuiceFS 去共享海量数据。
大数据上云存算分离演进思考与探讨-2022 值得细读。
hdfs vs 对象存储

数据流转
AI 应用的全流程存储加速方案技术解析和实践分享选择数据湖的背后,是业务间的数据流转方式已经发生了翻天覆地的变化。在云原生之前,不同类型的业务处于信息孤岛的状态,大数据的业务使用 HDFS,高性能计算使用并行文件系统,数仓系统自己保存数据。系统 B 需要使用系统 A 的数据,需要把数据从系统 A 里导出来一份。这种点对点的数据交流显然是比较低效和繁琐的。数据湖、存算分离这些概念的兴起,让业界达成一个共识,那就是建设统一的数据湖存储底座,围绕数据存储进行数据流转,可以有效的解决系统间数据流转的问题。
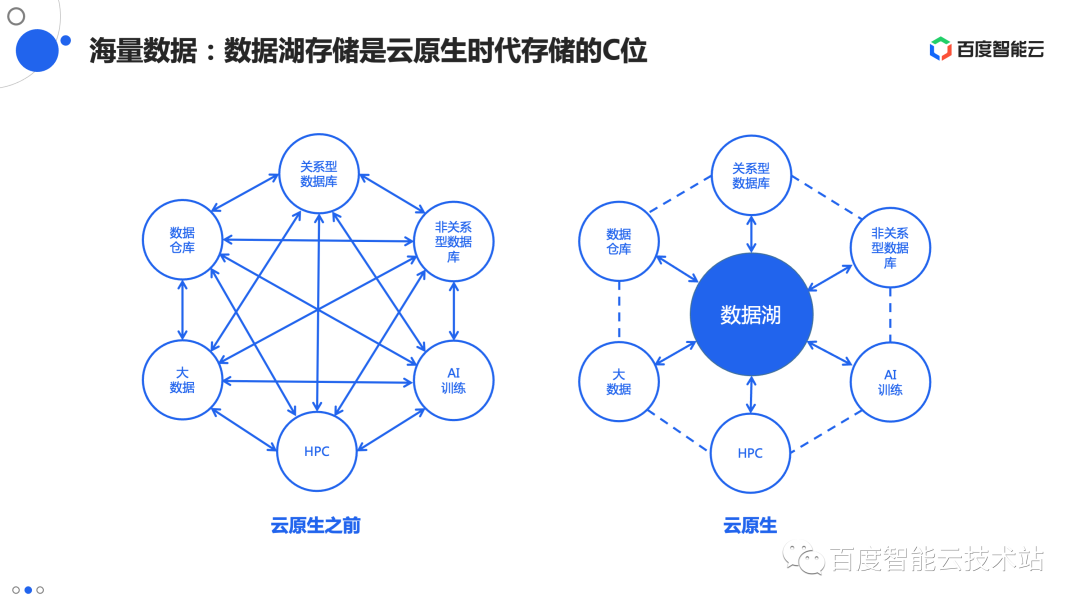
但到了数据湖里,数据湖存储才是最全量、最权威的数据来源,大部分情况下,数据的第一个落脚点是数据湖,然后才会到高性能的加速层。在存算分离架构中,加速层本身都只是临时的存在,其中的数据生命周期和计算资源同步,略早于计算资源的创建而生成,计算资源销毁时同步删除。这就导致数据湖到加速层的数据同步成为一个高频、核心的需求,需要花大力气解决。
留下评论