如何学习Kubernetes
简介
所谓学习,就是要能回答几个基本问题:
- kubectl 创建 Pod 背后到底发生了什么? 这个问题 对于一个java 工程师来说,就像“在浏览器里输入一个url之后发生了什么?” 一样基础。再进一步就是 自己从kubectl 到crd 实现一遍。
- github kubernetes community
好文章在知识、信息概念上一定是跨层次的,既有宏观架构,又有微观佐证。只有原理没有代码总觉得心虚,只有代码没有原理总觉得心累。从概念过渡到实操,从而把知识点掌握得更加扎实。
为什么会有k8s——大数据视角
Docker 技术到底解决了一个什么样的问题呢?Docker 自己宣传的口号是:一次构建到处运行。它一举解决了开发、测试、生产中环境不一致这困扰业界多年的问题。从更高的维度来说,Docker 其实解决的是软件到底应该通过什么样的方式进行交付。当软件的交付方式变得清晰明确以后,那么我们做托管软件的平台也就变得非常简单明了了。
Borg(一):当电力成为成本瓶颈当我们采购了很多服务器,搭建起了一系列的大数据系统,我们又会发现这些服务器在很多时候负载不高,显得非常浪费。因为我们在采购服务器的时候,需要根据平时的峰值流量来确定服务器数量。如果就只是采购服务器的硬件成本,那还好,毕竟服务器我们已经采购完了。但是,对于一个数据中心来说,硬件成本只是一小部分,最大的一头在电力成本。所以,能不能尽量少用一点服务器,就变成一个很有价值的问题了。
- 一个很自然的想法,就是对我们服务器的使用进行“削峰填谷”,我们让原本在高峰时间运行的一些任务,挪到半夜这样的低谷时段去。这个思路,对于离线进行数据分析的任务,当然很容易做到,所以一般来说,我们的 Hadoop 或者 Spark 集群的 CPU 整体利用率往往很高。
- 但是对于 Kafka、Dataflow 这样提供近实时服务的数据系统,我们是没办法把峰值时段的任务,也挪到第二天半夜才计算的。所以,一个新的想法自然也就冒出来了,那就是,我们是不是可以把 MapReduce 这样的离线分析任务,也放到 Dataflow 的集群上运行呢?在半夜 Dataflow 没有什么流量的时候,我们完全可以把这部分服务器的资源用起来。
所以,我们需要有一个办法,能够让我们的各种大数据系统混合编排在同一批服务器上。事实上,这个混合编排并不局限于大数据系统,我们的业务系统也可以一并考虑进来。正是这么一个朴素的、尽量利用服务器资源的思路,就催生了 Google 的 Borg 系统,并最终从中进化出了 Kubernetes 这个开源的容器编排系统。
声明式应用管理
Kubernetes 是一个“数据库”吗?Kubernetes 里面的绝大多数功能,无论是 kubelet 执行容器、kube-proxy 执行 iptables 规则,还是 kube-scheduler 进行 Pod 调度,以及 Deployment 管理 ReplicaSet 的过程等等,其实从总体设计上都是在遵循着我们经常强调过的“控制器”模式来进行的。即:用户通过 YAML 文件等方式来表达他所想要的期望状态也就是终态(无论是网络、还是存储),然后 Kubernetes 的各种组件就会让整个集群的状态跟用户声明的终态逼近,最终达成两者的完全一致。这个实际状态逐渐向期望状态逼近的过程,就叫做 reconcile(调谐)。而同样的原理,也正是 Operator 和自定义 Controller 的核心工作方式。
声明式应用管理的本质:Infrastructure as Data/Configuration as Data,这种思想认为,基础设施的管理不应该耦合于某种编程语言或者配置方式,而应该是纯粹的、格式化的、系统可读的数据,并且这些数据能够完整的表征使用者所期望的系统状态。这样做的好处就在于,任何时候我想对基础设施做操作,最终都等价于对这些数据的“增、删、改、查”。而更重要的是,我对这些数据进行“增、删、改、查”的方式,与这个基础设施本身是没有任何关系的。
这种好处具体体现在 Kubernetes 上,就是如果我想在 Kubernetes 上做任何操作,我只需要提交一个 YAML 文件,然后对这个 YAML 文件进行增删改查即可。而不是必须使用 Kubernetes 项目的 Restful API 或者 SDK 。这个 YAML 文件里的内容,其实就是 Kubernetes 这个 IaD 系统对应的 Data(数据)。Kubernetes 从诞生起就把它的所有功能都定义成了所谓的“API 对象”,其实就是定义成了一份一份的 Data。Kubernetes 本质上其实是一个以数据(Data)来表达系统的设定值、通过控制器(Controller)的动作来让系统维持在设定值的调谐系统。
既然 Kubernetes 需要处理这些 Data,那么 Data 本身不是也应该有一个固定的“格式”这样 Kubernetes 才能解析它们呢?没错,这里的格式在 Kubernetes 中就叫做 API 对象的 Schema。Kubernetes 为你暴露出来的各种 API 对象,实际上就是一张张预先定义好 Schema 的表(Table)。而我们绞尽脑汁编写出的那些 YAML 文件,其实就是对这些表中的数据(Data)进行的增删改查(CURD)。唯一跟传统数据库不太一样的是,Kubernetes 在拿到这些数据之后,并不以把这些数据持久化起来为目的。
如果你从一个“数据库”的角度重新审视 Kubernetes 设计的话
- 数据模型 - Kubernetes 的各种 API 对象与 CRD 机制
- 数据拦截校验和修改机制 - Kubernetes Admission Hook
- 数据驱动机制 - Kubernetes Controller/Operator
- 数据监听变更与索引机制 - Kubernetes 的 Informer 机制
随着 Kubernetes 基础设施越来越复杂,第三方插件与能力越来越多,社区的维护者们也发现 Kubernetes 这个“数据库”内置的“数据表”无论从规模还是复杂度上,都正在迎来爆炸式的增长。所以 Kubernetes 社区很早就在讨论如何给 Kubernetes 设计出一个“数据视图(View)”出来。阿里正在推 (OAM)及 oam-kubernetes-runtime。
声明式的好处 在ansible学习 ansible 与其它集群操作工具saltstack等的对比中也有体现。
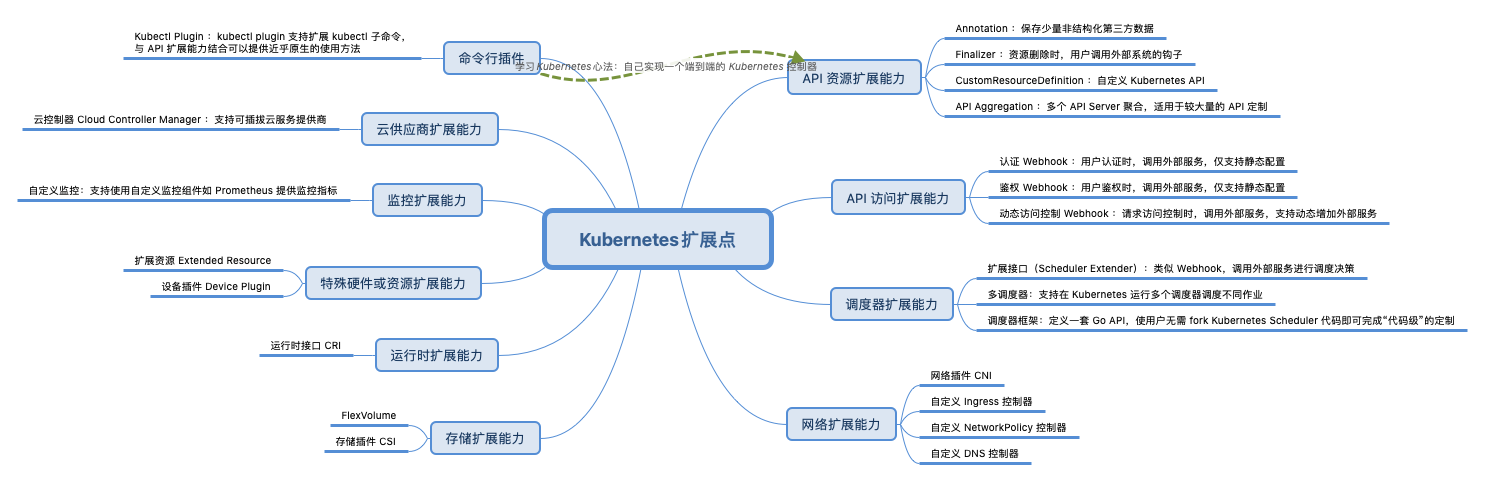
一个充分支持扩展的系统
Kubernetes 本身就是微服务的架构,虽然看起来复杂,但是容易定制化,容易横向扩展。在 Kubernetes 中几乎所有的组件都是无状态化的,状态都保存在统一的 etcd 里面,这使得扩展性非常好,组件之间异步完成自己的任务,将结果放在 etcd 里面,互相不耦合。有了 API Server 做 API 网关,所有其他服务的协作都是基于事件的,因而对于其他服务进行定制化,对于 client 和 kubelet 是透明的。
| k8s涉及的组件 | 功能交付方式 | |
|---|---|---|
| crd | API,随着社区的发展,某些通用需求的crd 会逐渐标准化,以便在不同的云厂商之间迁移 | |
| kubectl | binary,用户直接使用 | |
| kubelet | binary,提供http服务 | |
| cri-shim | grpc server | |
| csi | grpc server | |
| cni plugin | binary,程序直接使用 | binary 放在约定目录,需要安装到所有Node节点上 |
| adminssion controller | webhook | |
| Scheduler plugin | 被编译到Scheduler中 | |
| Operator | binary,以容器方式运行在Kubernetes 集群中 通过扩展API server支持与kubectl 交互 |
|
| Ingress Controller | pod 部署在 Kubernetes 集群里,根据api server 中Ingress 数据做出处理即可 | |
| metric server | 以Deployment 方式运行 | |
| cadvisor | 以源码包方式被集成在 kubelet里 |
单机有 ubuntu centos 操作系统;集群中可以把 Kubernetes 看成云操作系统。单机有计算、存储、网络等驱动;集群有 CNI/CSI/CRI 实现像是集群的驱动。
从技术实现角度的整体设计
对于一个编排系统来说,资源管理至少需要考虑以下几个方面:
- 资源模型的抽象;包括,
- 有哪些种类的资源,例如,CPU、内存等;
- 如何用数据结构表示这些资源;
- 资源的调度
- 如何描述一个 workload 的资源申请(spec),例如,“该容器需要 4 核和 12GB~16GB 内存”;
- 如何描述一台 node 当前的资源分配状态,例如已分配/未分配资源量,是否支持超分等;
- 调度算法:如何根据 workload spec 为它挑选最合适的 node;
- 资源的限额(capacity enforcement)
- 如何确保 workload 使用的资源量不超出预设范围(从而不会影响其他 workload);
- 如何确保 workload 和系统/基础服务的限额,使二者互不影响。 k8s 是目前最流行的容器编排系统,那它是如何解决这些问题的呢?
A few things I’ve learned about Kubernetes 值得读三遍
47 advanced tutorials for mastering Kubernetes 设计k8s 的方方面面,未详细读
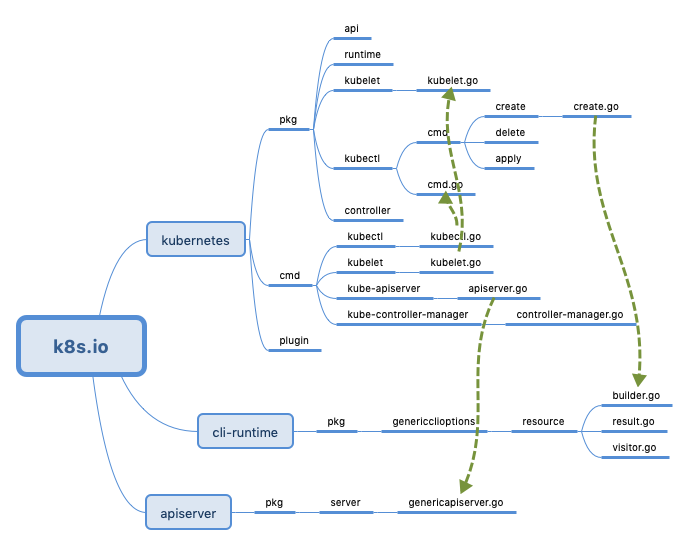
- pkg是kubernetes的主体代码,里面实现了kubernetes的主体逻辑
- cmd是kubernetes的所有后台进程的代码,主要是各个子模块的启动代码,具体的实现逻辑在pkg下
- plugin主要是kube-scheduler和一些插件
go get -d k8s.io/kubernetes
cd $GOPATH/src/k8s.io/kubernetes
k8s各个组件的实现思路
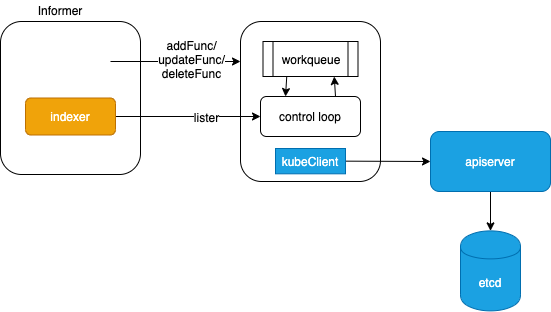
除apiserver/kubectl 之外(kubelet 类似,但更复杂些),与api server 通信的Controller/Scheduler 的业务逻辑几乎一致
- 组件需要与apiserver 交互,但核心功能组件不直接与api-server 通信,而是抽象了一个Informer 负责apiserver 数据的本地cache及监听。Informer 还会比对 资源是否变更(依靠内部的Delta FIFO Queue),只有变更的资源 才会触发handler。因为Informer 如此通用,所以Informer 的实现在 apiserver 的 访问包client-go 中。在k8s推荐的官方java库中,也支持直接创建Informer 对象。
- 组件 全部采用control loop 逻辑
- 组件 全部内部维护一个 queue队列,通过注册Informer事件 函数保持 queue数据的更新 或者说 作为队列的生产者,control loop 作为队列的消费者。
- 通过Informer 提供过的Lister 拥有遍历数据的能力,将操作结果 重新通过kubeclient 写入到apiserver
留下评论