学计算
前言
李智慧:软件编程技术出现已经半个多世纪了,核心价值就是把现实世界的业务操作搬到计算机上,通过计算机软件和网络进行业务和数据处理。但是时至今日,能用计算机软件提高效率的地方,几乎已经被全部发掘过了,在这种情况下,如果想让软件再成百上千倍地提高我们的生活和工作效率,使用以前的那套“分析用户需求和业务场景,进行软件设计和开发”的做法显然是不可能的了。 那如何走出这个困局呢?我觉得,要想让计算机软件包括互联网应用,能够继续提高我们的生活工作效率,那就必须能够发掘出用户自己都没有发现的需求,必须洞悉用户自己都不了解的自己。计算机软件不能再像以前那样,等用户输入操作,然后根据编写好的逻辑执行用户的操作,而是应该能够预测用户的期望,在你还没想好要做什么的情况下,主动提供操作建议和选项,提醒你应该做什么。所以,我同意这样一种说法:在未来,软件开发将是“面向 AI 编程”,软件的核心业务逻辑和价值将围绕机器学习的结果也就是 AI 展开,软件工程师的工作就是考虑如何将机器学习的结果更好地呈现出来,如何更好地实现人和 AI 的交互。
事实上,公司到了一定规模,产品功能越来越复杂,人员越来越多,不管用什么驱动,最后一定都是数据驱动。没有量化的数据,不足以凝聚团队的目标,甚至无法降低团队间的内耗。这个时候哪个部门能有效利用数据,能用数据说话,能用数据打动老板,哪个部门就能成为公司的驱动核心,在公司拥有更多话语权。我们学大数据,手里用的是技术,眼里要看到数据,要让数据为你所用。数据才是核心才是不可代替的,技术并不是。
大数据处理的主要应用场景包括数据分析、数据挖掘与机器学习。数据分析主要使用 Hive、Spark SQL 等 SQL 引擎完成;数据挖掘与机器学习则有专门的机器学习框架 TensorFlow、Mahout 以及 MLlib 等,内置了主要的机器学习和数据挖掘算法。此外,大数据要存入分布式文件系统(HDFS),要有序调度 MapReduce 和 Spark 作业执行,并能把执行结果写入到各个应用系统的数据库中,还需要有一个大数据平台整合所有这些大数据组件和企业应用系统。
发展历史
大数据计算的核心思路是移动计算比移动数据更划算。既然计算方法跟传统计算方法不一样,移动计算而不是移动数据,那么用传统的编程模型进行大数据计算就会遇到很多困难,因此 Hadoop 大数据计算使用了一种叫作 MapReduce 的编程模型。PS:MapReduce这个编程模型解决什么问题?能够用分治法解决的问题。
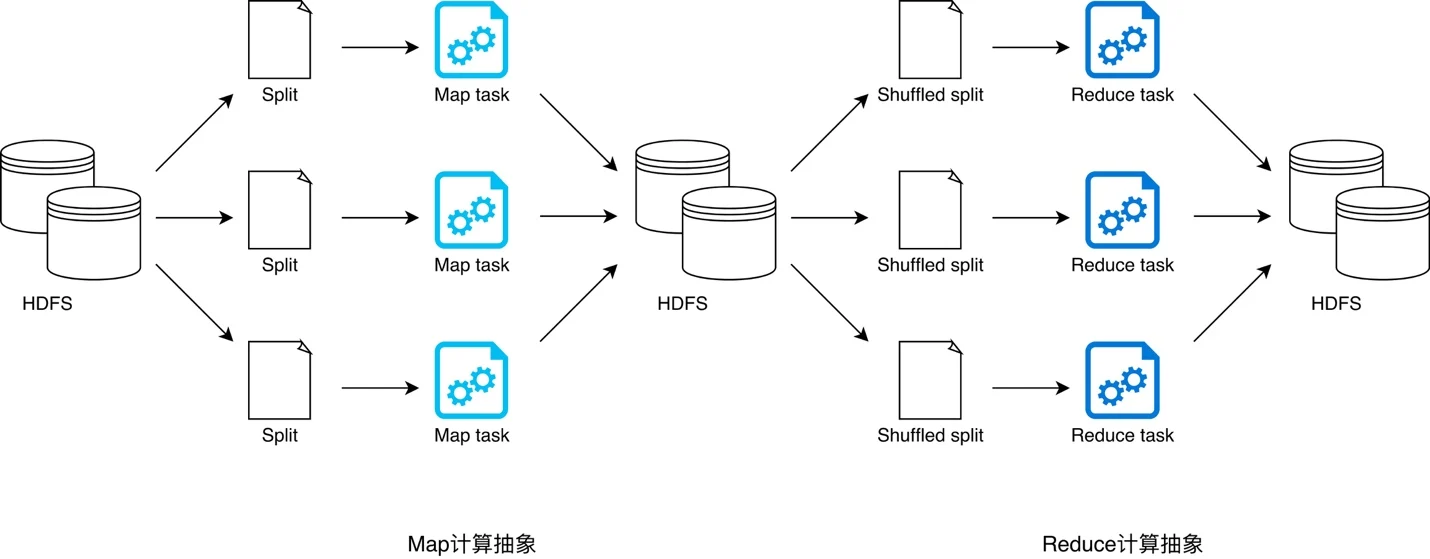
- 为什么说 MapReduce 是一种非常简单又非常强大的编程模型?简单在于其编程模型只包含 Map 和 Reduce 两个过程,map 的主要输入是一对
<Key,Value>值,经过 map 计算后输出 一对<Key,Value>值;然后将相同 Key 合并,形成<Key,Value集合>;再将这个<Key,Value集合>输入 reduce,经过计算输出零个或多个<Key,Value>对。 - MapReduce 又是非常强大的,不管是关系代数运算(SQL 计算),还是矩阵运算(图计算),大数据领域几乎所有的计算需求都可以通过 MapReduce 编程来实现。
一个 MapReduce 程序要想在分布式环境中执行,并处理海量的大规模数据,还需要一个计算框架,能够调度执行这个 MapReduce 程序,使它在分布式的集群中并行运行,而这个计算框架也叫 MapReduce。
- 如何为每个数据块分配一个 Map 计算任务,也就是代码是如何发送到数据块所在服务器的,发送后是如何启动的,启动以后如何知道自己需要计算的数据在文件什么位置(BlockID 是什么)。
- 处于不同服务器的 map 输出的 ,如何把相同的 Key 聚合在一起发送给 Reduce 任务进行处理。PS: 分布式计算需要将不同服务器上的相关数据合并到一起进行下一步计算,这就是 shuffle。不管是 MapReduce 还是 Spark,只要是大数据批处理计算,一定都会有 shuffle 过程,只有让数据关联起来,数据的内在关系和价值才会呈现出来。移动计算主要是map阶段,reduce阶段数据还是要移动数据合并关联,不然很多计算无法完成。
其实 MapReduce 的架构思想可以从两个方面来看。一方面,它希望能提供一套简洁的 API 来表达工程师数据处理的逻辑。另一方面,要在这一套 API 底层嵌套一套扩展性很强的容错系统,使得工程师能够将心思放在逻辑处理上,而不用过于分心去设计分布式的容错系统。
《大规模数据处理实战》
- 使用 MapReduce,你需要严格地遵循分步的 Map 和 Reduce 步骤。很多现实世界中的问题,往往需要一系列的 map 或 reduce 步骤。然而,每一步的 MapReduce 都有可能出错,都需要重试和异常处理的机制。为了解决这个问题,作为架构师的我们或许可以用有向无环图(DAG)来抽象表达。因为有向图能为多个步骤的数据处理依赖关系,建立很好的模型。如果我们用有向图建模,图中的每一个节点都可以被抽象地表达成一种通用的数据集,每一条边都被表达成一种通用的数据变换。如此,你就可以用数据集和数据变换描述极为宏大复杂的数据处理流程,而不会迷失在依赖关系中无法自拔。
- MapReduce 的另一个问题是,配置太复杂了。以至于错误的配置最终导致数据处理任务效率低下。我们不想要复杂的配置,需要能自动进行性能优化,我们要能把数据处理的描述语言,与背后的运行引擎解耦合开来。用有向图进行数据处理描述的话,实际上数据处理描述语言部分完全可以和后面的运算引擎分离了。有向图可以作为数据处理描述语言和运算引擎的前后端分离协议。比如,我的数据描述可以用 Python 描述,由业务团队使用;计算引擎用 C++ 实现,可以由数据底层架构团队维护并且高度优化;或者我的数据描述在本地写,计算引擎在云端执行。
- FlumeJava(对应Spark)。在 2010 年的时候,Google 公开了 FlumeJava 架构思想的论文。FlumeJava 的思想是将所有的数据都抽象成名为 PCollection(Parallel Collection) 的数据结构,无论是从内存中读取的数据,还是在分布式环境下所读取的文件。且在 MapReduce 框架中 Map 和 Reduce 思想上,抽象出 4 个了原始操作(Primitive Operation),分别是 parallelDo、groupByKey、 combineValues 和 flatten,让工程师可以利用这 4 种原始操作来表达任意 Map 或者 Reduce 的逻辑。同时,FlumeJava 的架构运用了一种 Deferred Evaluation 的技术,来优化我们所写的代码。对于 Deferred Evaluation,你可以理解为 FlumeJava 框架会首先会将我们所写的逻辑代码静态遍历一次,然后构造出一个执行计划的有向无环图。这在 FlumeJava 框架里被称为 Execution Plan Dataflow Graph。有了这个图之后,FlumeJava 框架就会自动帮我们优化代码。
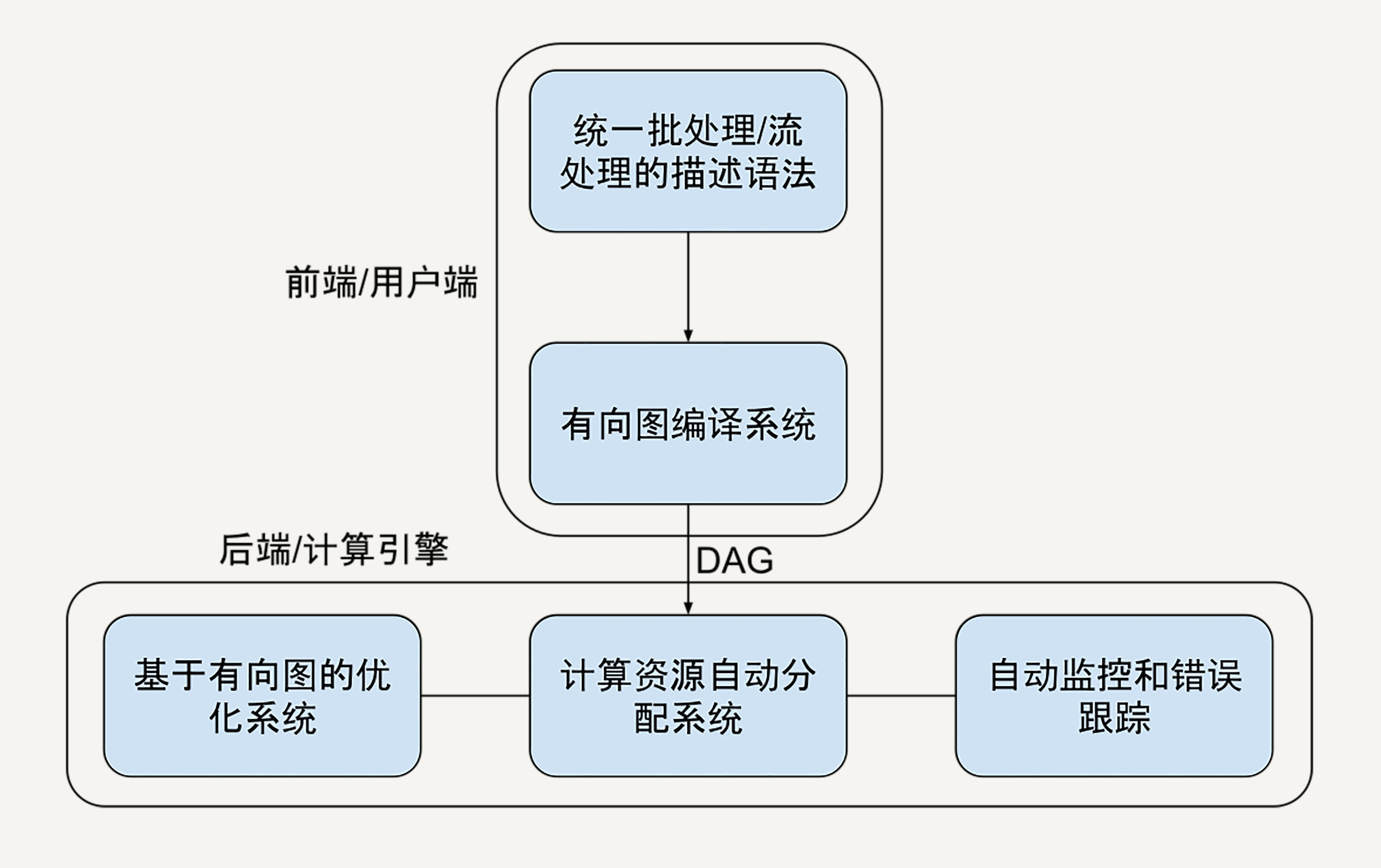
流批一体:《大规模数据处理实战》批处理处理的是有界离散的数据,比如处理一个文本文件;流处理处理的是无界连续的数据,比如每时每刻的支付宝交易数据。MapReduce 的一个局限是它为了批处理而设计的,应对流处理的时候不再那么得心应手。即使后面的 Apache Storm、Apache Flink 也都有类似的问题,比如 Flink 里的批处理数据结构用 DataSet,但是流处理用 DataStream。但是真正的业务系统,批处理和流处理是常常混合共生,或者频繁变换的。因此,我们设计的数据处理框架里,就得有更高层级的数据抽象。不论是批处理还是流处理的,都用统一的数据结构表示。编程的 API 也需要统一。这样不论业务需求什么样,开发者只需要学习一套 API。即使业务需求改变,让我们只需要将注意力专注于在数据处理的算法上,而不用再花时间去对两种数据处理模式上的差异进行维护。如果是我们站在 2008 年春夏之交来设计下一代大规模数据处理框架,一个基本的模型会是图中这样子的:
- 高度抽象的数据处理流程描述语言。在一个分布式计算系统中,我们作为架构设计者需要为用户隐藏的实现细节有很多,其中就包括了数据是怎样表达、存储和转换的。
- 根据描述的数据处理流程,自动化的任务分配优化。有向无环图是框架能够自动优化执行计划的核心。
Google 在 2016 年的时候联合了 Talend、Data Artisans、Cloudera 这些大数据公司,基于 Dataflow Model 的思想开发出了一套 SDK,并贡献给了 Apache Software Foundation。而它 Apache Beam 的名字是怎么来的呢?Batch + Streaming = Beam。Beam 并不是一个数据处理平台,本身也无法对数据进行处理。Beam 所提供的是一个统一的编程模型思想。
Beam 能够将工程师写好的算法逻辑很好地与底层的运行环境分隔开。也就是说,当我们通过 Beam 提供的 API 写好数据处理逻辑后,这个逻辑可以不作任何修改,直接放到任何支持 Beam API 的底层系统上运行。在 Beam 上,这些底层运行的系统被称为 Runner。现阶段 Apache Beam 支持的 Runner 有近十种,包括了我们很熟悉的 Apache Spark 和 Apache Flink。
吴翰清:计算实际上是从数字出发,模拟世界万物的结构。它是通过机器驱动字符的变形,或者如果没有计算机,那就是用机械化的方式驱动。字符的变形是有一定的顺序和架构的,这个顺序和架构我们称之为算法。所以什么东西是重要的呢?结构是重要的,你对世间万物的洞察是重要的。因为你洞察了世间万物,所以你才能够理解它是一个什么样的架构,才能把这个架构抽象出来,抽象出来才能够用数字字符去模拟它,最后才能用机械化的方式驱动它。这个东西能带来什么好处呢?就是可以做模拟和预测了。如果从技术的层面谈什么是计算,那这个是计算。如果更大一点,就是通过数字编码世间万物,世界万物所有的规律就能够通过机械化的方式来推导。当机械化推导的方式有了电以后,电子的速率又是非常高的,那么效率又取得了一个巨大的飞跃,这就是今天所有计算机的秘密。今天我们不管谈什么领域,城市大脑也好、人工智能也好,包括搭一个网站,不都是在模拟一种结构吗?最后底层就是在用字符驱动,只不过今天我们把字符限定成为数字的字符,仅此而已。
数学和物理开始融合,这个事情就开始有意思了。今天的物理也不是无止境的,到最后就会符合数学的一些特性,那就意味着这个世界可以用数学来解释,或者说可以用今天的数学来解释。你会发现这个物理世界是符合计算复杂性的。想通这一点之后就会想明白很多事情,包括为什么存在安全这件事。比如说这里有一杯茶,还有一杯热水,我们把茶和热水混合到一起,这个过程就是计算的加法。这个时候我们就会发现计算复杂性的存在。我们面前的水已经变成了一杯茶水,我现在想把茶叶粉末跟这杯水分开,是不是很难分开?我们必须付出比之前大很多倍的代价,通过一些化学反应等等,才能把它分开。我们把茶叶粉末和热水混合在一起,这个是正向运算,反过来就是逆向运算。逆向运算的代价是远远大于正向运算的,这意味着我们这个世界是单向函数的世界。再举个例子,比如诈骗这个事儿,我们看一些网上电信诈骗的案例,一下就被骗了几十万。这类问题为什么屡禁不止?原因很简单,因为我们这个世界是符合计算复杂性的,这个世界是存在单向函数的。这意味着这些犯罪分子很容易设计一个骗局,因为这是正向运算。如果我们要破案,要逆向运算,就要找到他在哪里,找到他是谁,什么时间、什么地点干的这件事情,代价非常大,所以这件事情就确保了犯罪的成本是远远低于破案成本的。
数据流平台
一位架构师的自述:在尚未踏入的世界成为你自己流入流出的都应该是一个数据集,整个数据集在DAG图上流动,可以聚合,可以关联。这不就是 Spark/Flink 做的事儿么;但现在问题是,这些技术还是有一定的技术门槛的,我们如何让算法工程师、软件开发工程师甚至产品经理都投入到大数据的革命洪流中来呢?必须进一步降低门槛。如果在“设计时”,也就是计算任务上线之前,在开发的时候就看到数据流转的图形就好了。进而,这个图形不只是用来看的,还可以编辑,可以拖拉拽,拖一个输入算子,几个处理算子,几个输出算子,数据加工的逻辑就搞定了。编辑好的图形直接发布线上就能运行,不用写代码,不用知道什么是Spark,那可太棒了。
软件架构师,Architect,实际和建筑设计师,是一个英文单词。你说建筑设计师会不会搬砖?他肯定会。那你说我会搬砖,我砖搬的好,砖搬的快,我会不会成为建筑设计师?那不一定。建筑设计师会告诉你,建筑的骨架是什么样的,如何受力的;哪面墙是承重墙,一定不能砸。当然,最基本的土木工程、建筑技术,那建筑设计师一定要了如指掌。其实软件架构师类似。最基本的编程技术、数据技术,不仅要精通,还需要灵活应用。除此之外,需要知道系统是如何承压的,系统的核心链路是什么。开发之前,需要先进行系统设计,让系统先在纸面上跑起来,各个场景都不会有逻辑漏洞。设计之前,需要先确定设计原则,设计是基于哪些假设的,例如系统运行的前置条件是什么。其实最重要的,就是要独立思考,要挑战自己;多构造一些边缘场景,来验证系统是否可以应对。
其它
不管是批处理计算还是流处理计算,都需要庞大的计算资源,需要将计算任务分布到一个大规模的服务器集群上。那么如何管理这些服务器集群的计算资源,如何对一个计算请求进行资源分配,这就是大数据集群资源管理框架 Yarn 的主要作用。各种大数据计算引擎,不管是批处理还是流处理,都可以通过 Yarn 进行资源分配,运行在一个集群中。
很多大数据产品都是这样的架构方案:Storm,一个 Nimbus,多个 Supervisor;Spark,一个 Master,多个 Slave。大数据因为要对数据和计算任务进行统一管理,所以和互联网在线应用不同,需要一个全局管理者。而在线应用因为每个用户请求都是独立的,而且为了高性能和便于集群伸缩,会尽量避免有全局管理者。
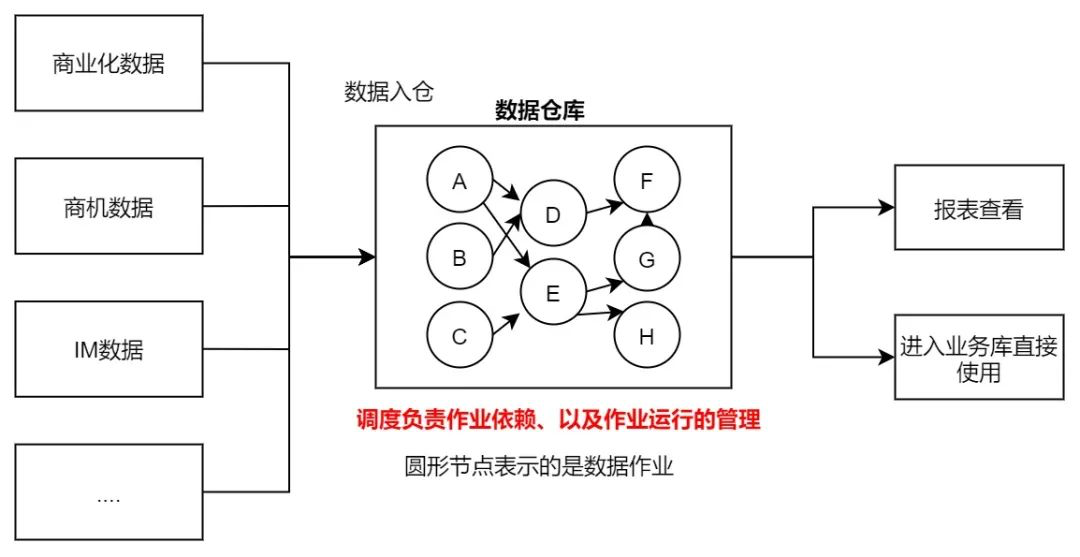
贝壳大数据任务调度DAG体系设计实践 数仓不是建几个表就好了。
留下评论