《mysql技术内幕》笔记
简介
《mysql技术内幕》 主要讲存储引擎部分。
慢SQL是如何拖垮数据库的? 学以致用。
基本架构
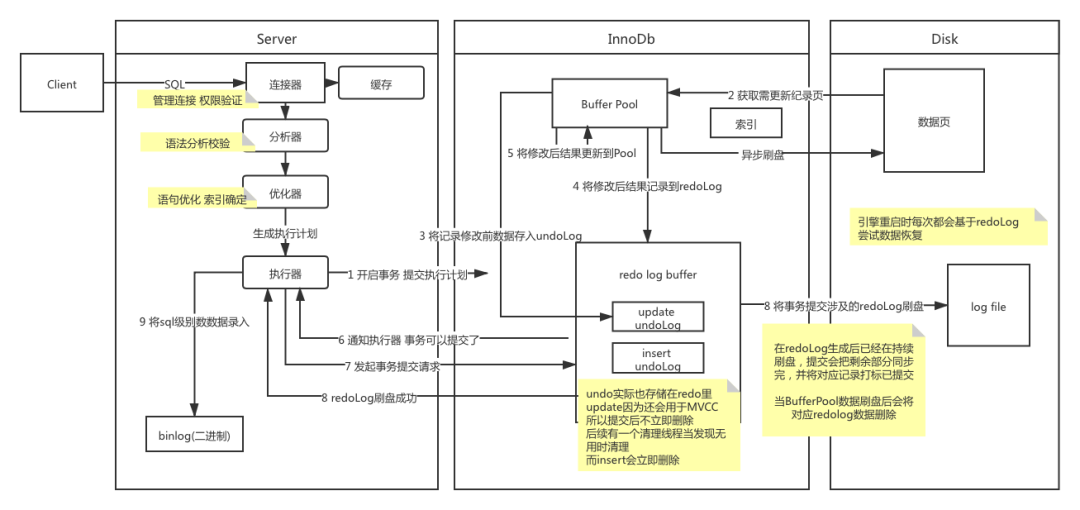
按照近些年流行的概念来讲,MySQL 是一个典型的存储计算分离的架构,MySQL Server 作为计算层,Storage Engine 作为存储层。
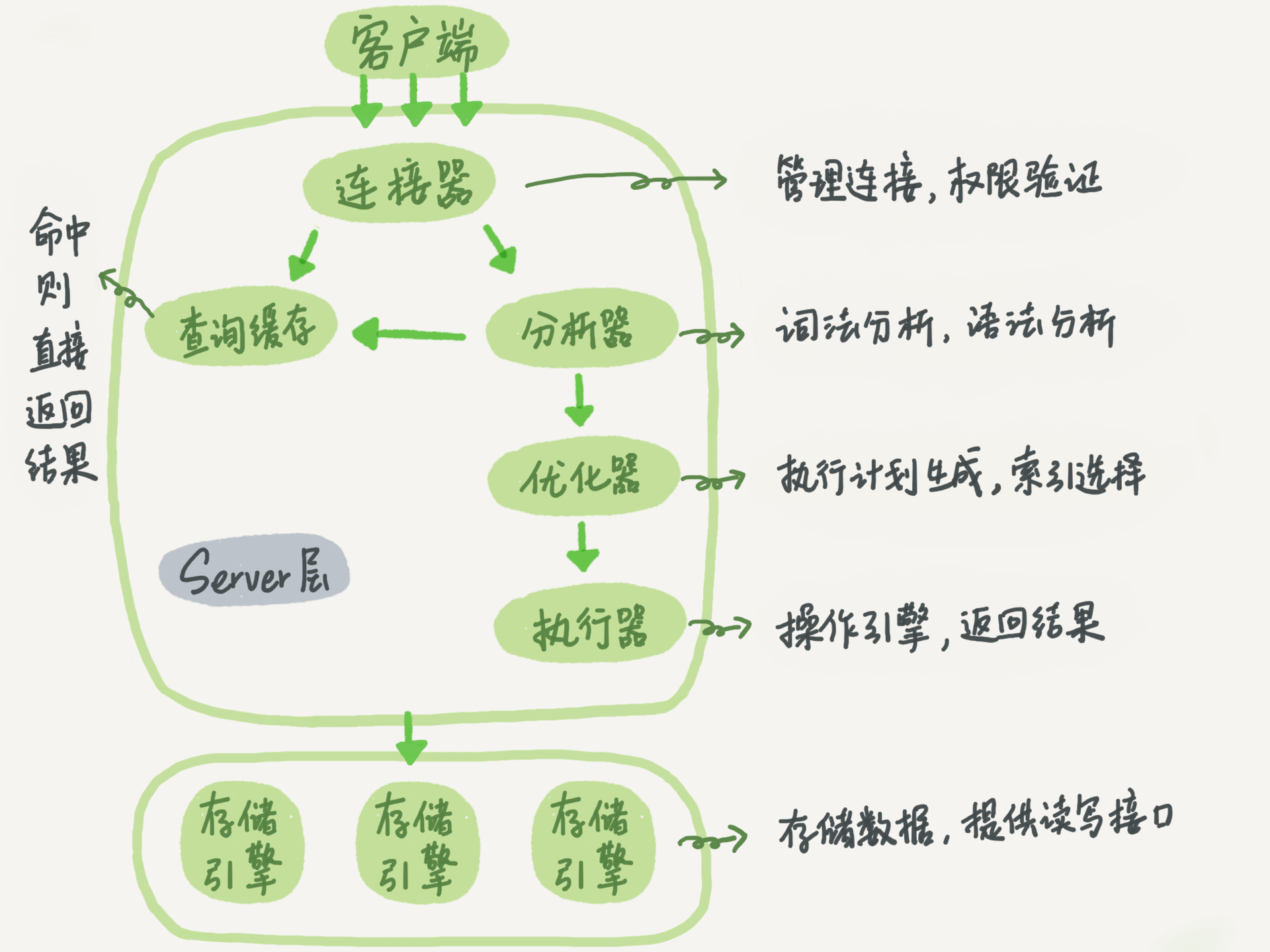
查询缓存:key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。大多数情况下我会建议你不要使用查询缓存,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。对于更新压力大的数据库来说,查询缓存的命中率会非常低。除非你的业务就是有一张静态表,很长时间才会更新一次。MySQL 8.0 版本直接将查询缓存的整块功能删掉了。
crash-safe 能力:保证即使数据库发生异常重启,之前提交的记录都不会丢失。日志系统
- Server层日志/binlog/逻辑日志。最开始 MySQL 里并没有 InnoDB 引擎。MySQL 自带的引擎是 MyISAM,但是 MyISAM 没有 crash-safe 的能力,binlog 日志只能用于归档。
- 存储引擎层日志。当有一条记录需要更新的时候,InnoDB 引擎就会先把记录写到 redo log里面,并更新内存,这个时候更新就算完成了。同时,InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面。redo log 是固定大小的,如果redo log 写满了(write ops-checkpoint),就不能再执行更新操作了,得停下来将内存数据写到磁盘(把checkpoint 推进一下)。
| redo log | binlog | |
|---|---|---|
| 层次 | InnoDB 引擎特有的 | Server 层实现 |
| 内容 | 物理日志 记录的是“在某个数据页上做了什么修改” |
逻辑日志 记录的是这个语句的原始逻辑,比如“给 ID=2 这一行的 c 字段加 1” |
| 写的方式 | 循环写 空间固定会用完 |
追加写 写到一定大小后会切换到下一个,并不会覆盖以前的日志 |
- 分层逻辑架构
- MySQL 5.6引入的特性,将WHERE条件中索引相关部分”下推”到存储引擎层进行过滤(掉不符合条件的记录),而不是在服务器层过滤。
- InnoDB存储引擎
- 事务机制与并发控制
- 主从复制原理
- 分区策略与应用场景
- SQL鱼骨图
API
存储引擎 API以Handler类的虚函数的方式存在,可在代码库下的sql/handler.h中查看详细信息
class handler : public Sql_alloc{
...
// 创建、打开和关闭表
int create(const char *name, TABLE *form, HA_CREATE_INFO *info);
int open(const char *name, int mode, int test_if_locked);
int close(void);
virtual int rnd_init (bool scan); //初始化全表扫描
virtual int rnd_next (byte* buf); //从表中读取下一行
virtual int rnd_pos(uchar *buf, uchar *pos); // 读取pos 的数据,一般用于读取字段
// 索引操作
int ha_foo::index_init(uint keynr, bool sorted) //使用索引前调用该方法
int ha_foo::index_end(uint keynr, bool sorted) //使用索引后调用该方法
int ha_index_first(uchar * buf); //读取索引第一条内容
int ha_index_next(uchar * buf); //读取索引下一条内容
int ha_index_prev(uchar * buf); //读取索引前一条内容
int ha_index_last(uchar * buf); //读取索引最后一条内容
int index_read(uchar * buf, const uchar * key, uint key_len,
enum ha_rkey_function find_flag) //给定一个key基于索引读取内容
// 事务操作
int my_handler::start_stmt(THD *thd, thr_lock_type lock_type) //开始一个事务
int (*rollback)(THD *thd, bool all); //回滚一个事务
int (*commit)(THD *thd, bool all); //提交一个事务
// 对表加锁
int ha_example::external_lock(THD *thd, int lock_type) // 当客户端调用LOCK TABLE时,通过external_lock函数加锁:
}
磁盘文件
内存管理系统将内存条编址,对每个进程看到的都是0~n。文件系统相当于将离散的磁盘存储空间编址,对每个文件看到的都是0~n。当然,进程根据进程号查找就可以,文件要根据文件名查找,因此多了一些结构。
我们常说逻辑结构、物理/存储结构
- 存储结构是扁平的,一个文件/对象/实体的数据或连续或分散,能从offset 0到结尾找到就行。存在磁盘上通常有一定的文件格式rm、mp3,一般分为文件header和body两个部分。存在内存时,真应该也定一个数据格式。
- 逻辑结构,逻辑结构通常不是扁平的,能够承载一定的抽象概念。比如此处的innodb存储引擎文件,物理上就是一个个页连续构成,offset 0~16kb是第一个页(假设一个页大小16kb),接着第二个页等。但页有系统页、数据页,页上有共同的segment id,那么就有了段的概念,段的功能有又不同,最终组成了一个复杂的结构。
物理结构
假设一个表,一个表空间文件,表名test,对应文件test.ibd,ibd就是一个文件格式,有专门的工具解析,跟rm、mp3性质上一样一样的。
首先test.ibd 被划分为一个个页,每个页有不同的功能
每个页从offset 0到结束,有一定的格式约定。页有一个重要组成部分是行记录
行记录从offset 0到结束,有一定的格式约定。
逻辑结构
B+树数据库加锁历史在磁盘数据库中,数据组织方式的王者非B+树莫属,而且已经半个世纪有余。通过多叉树的方式,实现从单个节点中索引大量子树。从而大大降低了整个树高(一般为1-3层就能满足千万级的数据存储),将二叉树中大量的随机访问转化为顺序访问,减少磁盘寻道,完美契合了磁盘顺序访问性能远好于随机访问的特性,以及其块设备接口。BTree在结构上有大量变种,B+Tree所有的数据信息都只存在于叶子节点,中间的非叶子节点只用来存储索引信息,这种选择进一步的增加了中间节点的索引效率,使得内存可以缓存尽可能多的索引信息,减少磁盘访问;除根节点以外,每个节点的键值对个数需要介于M/2和M之间,超过或者不足需要做分裂或者合并。B+ 树是天然有序的,叶子节点形成有序链表,非常适合范围查询和排序操作。
数据部分,将一个B+Tree存在一个文件里一个个连续摆放的页上。
表空间 ==> 段 ==> 区 ==> 页。
体现在文件上,就是一个个页(看不出来段和区)。页按大小划分,这样根据页号*大小就知道页的地址。区也固定大小,分为多个页,区大小/页大小=区内页的数量。页大小可调,区大小不可调,通过两个大小维度实现固定与灵活有机统一吧。段则界定了页数据的性质,有点类似内存管理的段页机制。
数据库的并发安全
本文是innodb的读书笔记,更宏观的看待并发问题请参考腾讯云李海翔:数据库的并发控制技术深度探索基本要点:
- 数据库一共会发生11种异常现象,脏读、不可重复读、幻读只是其中三种。
-
主流的并发控制技术
- 两阶段锁
- 基于时间戳
- 基于有效性检查
- MVCC,常与其它技术一起使用
- SCO
所谓并发控制技术就是抑制并发,或者发现数据异常并处理。 使各种共享资源在被并发访问变得有序所设计的一种规则。
一个线上SQL死锁异常分析:深入了解事务和锁为了控制事务并发时的数据安全,在不同隔离级别下会通过不同的协同机制进行处理。传统隔离机制,完全由锁(LBCC)来处理,但是这样只能满足读读并发,会对性能造成很大影响,故而出现了支持读写并发的MVCC。
《软件架构设计》软件并发问题其实就是读写、写写冲突问题,读写冲突又可以细分为快照读与写冲突、当前读与写冲突。
| 并发冲突 | 处理办法 | 示例 |
|---|---|---|
| 读读 | 无冲突 | |
| 快照读与写 | copyOnWrite/MVCC | select xx from xx |
| 当前读与写 | 加锁,但锁有强弱(互斥、读写),粒度有大小(表、行、范围),锁住的对象有不同(索引、数据行) 可以根据容忍的读错误类型加不同的锁 |
select xx for udpate select xx in share mode |
| 写写 | 加锁 |
db 锁并不直接对 开发暴露,锁用于支持实现不同的事务的隔离性强度(有讨论价值的主要是RR和RC),加锁情况太多,容易晕。举个例子感受下事务和锁的关系
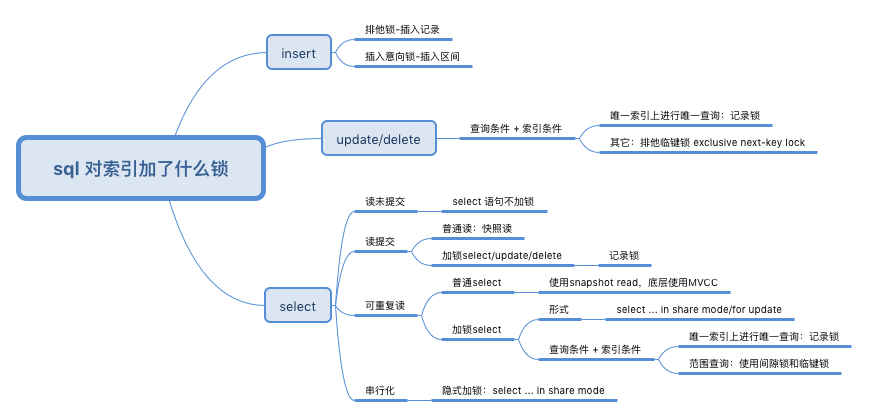
- 聚簇索引(查询命中,存在id=15)
UPDATE students SET score = 100 WHERE id = 15;,RC、RR都是对聚簇索引加X锁。未命中(存在id=16),RC不加锁,RR在16之前和之后的范围里加GAP锁。 - 二级唯一索引(查询命中,存在no=
S0003),UPDATE students SET score = 100 WHERE no = 'S0003',RC、RR会对二级和聚簇索引都加X锁(防止其他事务通过聚簇改数据)。未命中,RC不加锁,RR只在二级索引加GAP锁。
锁的实现
《MySQL实战45讲》MySQL 里面的锁大致可以分成全局锁、表级锁和行锁三类
- 全局锁,对整个数据库实例加锁,命令是
flush tables with read lock,释放全局锁命令unlock tables,典型使用场景是:做全库逻辑备份 - 表级锁
- 表锁,表锁的语法是
lock tables … read/write,可以用unlock tables主动释放锁,也可以在客户端断开的时候自动释放。 - 元数据锁,不需要显式使用,在访问一个表的时候会被自动加上。在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁。
- 表锁,表锁的语法是
- 行锁就是针对数据表中行记录的锁。在 InnoDB 事务中,行锁是在需要的时候才加上的,但并不是不需要了就立刻释放,而是要等到事务结束时才释放。这个就是两阶段锁协议。因此,如果你的事务中需要锁多个行,要把最可能造成锁冲突、最可能影响并发度的锁尽量往后放。有一点需要额外强调的是,行锁的施加需要依附于索引而存在,因此触发加锁行为的 SQL 语句是否走到索引就尤为关键,倘若检索条件未命中任何索引,那么锁的粒度就会由行锁上升为表锁.
给一个表加字段,或者修改字段,或者加索引,需要扫描全表的数据。书中提到,在数据库中,锁有lock和latch,一般业务开发熟悉的锁对应的是latch,简单区别如下:
| 对象 | 保护 | 持续时间 | 存在于 | 死锁探测机制 | |
|---|---|---|---|---|---|
| lock | 事务 | 表、页、行 | 整个事务过程 | lock manager的哈希表中 | waits-for graph、time out 机制 |
| latch | 线程 | 内存数据结构 | 很短 | 被保护的数据结构中 |
比如在java中,一个object内存结构就相应有锁的标记位,意味着任何一个object都有可能被竞争访问,如果object已经被锁住(标记位是某个值),则线程会被挂起。其实,锁的标记信息存储在被保护的数据结构上还是独立集中管理,都是一样的。
- 在操作系统中,一个文件在磁盘上的存在形式是一个个磁盘块,在内存中的存在形式除了磁盘块载入内存的缓冲块外,还有一个文件表,表中的文件结构体有锁的标志位。文件是否被某个线程独占,并不属于文件的内容信息,存入磁盘中是不恰当的。如果锁的信息存入磁盘块对应的缓冲块,则破坏了缓冲块与磁盘块的直接对应关系。
- 每个数据结构保有锁的标记信息有一个好处,即语言层面简化锁的使用,比如java的synchronized关键字, 比
lock unlock方便多了。
上层应用开发会加各种锁,有些锁是隐式的,数据库会主动加(比如update),有些锁是显式的,比如select xx for update。 因为开发的使用不当,数据库会发生死锁,就像jvm 也会死锁一样。作为数据库,必须有机制检测出死锁(判断一个有向图是否存在环),并解决死锁问题,比如强制让其中某个事务回滚,释放锁。
其它
change buffer 对更新的加速(尤其是适用于写多读少的业务):当需要更新一个数据页时,如果数据页在内存中就直接更新,而如果这个数据页还没有在内存中的话,在不影响数据一致性的前提下,InnoDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了(写时不用读磁盘,直到读数据时才读磁盘)。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。除了访问这个数据页会触发 merge 外,系统有后台线程会定期 merge。在数据库正常关闭(shutdown)的过程中,也会执行 merge 操作。
如果要简单地对比redo log和change buffer 在提升更新性能上的收益的话,redo log 主要节省的是随机写磁盘的 IO 消耗(转成顺序写),而 change buffer 主要节省的则是随机读磁盘的 IO 消耗(避免更新时读取)。PS:redo log主要是为了crash-safe的
由互联网分层架构的本质 想到的数据在不同介质的表现形式,以mysql innodb存储引擎为例
| 表现形式 | |
|---|---|
| 业务系统 | 一个数据对象 |
| java对象在内存 | 参见java对象内存模型 |
| mysql逻辑上 | 一行记录 |
| mysql一行记录在内存 | 例如compact、redundant等行记录格式 |
| mysql一页记录在内存 | 例如antelope、barracuda等格式 |
| mysql一页记录在文件系统 | 假设页大小16kb,内存数据整体复制到磁盘,地址范围page offset ~ page offset + 16kb |
| mysql表数据在硬盘 | 假设启动innodb_file_per_table,对应一个xx.ibd文件 |
| 一个文件在操作系统 | file id |
| 一个文件在磁盘 | 几个磁盘块 + 部分inode块 |
上层抹不去的底层印记。磁盘天然的随机读写慢于顺序读写,迫使os、mysql进行了大量的缓冲优化。
留下评论