netty内存管理
前言
深入浅出Netty内存管理:PoolChunk开篇说的太好了:多年之前,从C内存的手动管理上升到java的自动GC,是历史的巨大进步。然而多年之后,netty的内存实现又曲线的回到了手动管理模式,正印证了马克思哲学观:社会总是在螺旋式前进的,没有永远的最好。的确,就内存管理而言,GC给程序员带来的价值是不言而喻的,不仅大大的降低了程序员的负担,而且也极大的减少了内存管理带来的Crash困扰,不过也有很多情况,可能手动的内存管理更为合适。
整体思路
Netty Memory Management OverviewAt the operating system level, each software requests the operating system to quickly allocate computer memory resources at runtime and release and reclaim memory resources when appropriate. Some common algorithms include slab, buddy, and jemalloc. PS:Netty uses the idea of jemalloc
From the Netty level, the essence is to allocate a large memory first, and then use some data structure to record the memory usage status during memory allocation and recycling. If there is a new allocation request, find the most suitable location based on the status information. Returns and updates the data structure; after the memory is released, the data structure is modified synchronously. netty 先申请大块内存,然后自己负责这块内存的申请与回收。PS: netty 这样做的前提是,bytebuf 大部分时候只出现在 协议编解码层,这一块由netty 封装,因此netty 可以把控bytebuf的 分配与回收。在业务层开发直接操作的是消息对象,比如channel.write(Obj)。
Netty-内存管理内存池大概思路
- 首先应该会向系统申请一大块内存,然后通过某种算法管理这块内存并提供接口让上层申请空闲内存
- 申请到的内存地址应该透出到应用层,但是对开发人员来说应该是透明的,所以要有一个对象包装这个地址,并且这个对象应该也是池化的,也就是说不仅要有内存池,还要有一个对象池。
所以,自然可以带着以下问题去看源码:
- 内存池管理算法是怎么做到申请效率,怎么减少内存碎片。主要在于数据结构的组织。Chunk、smallSubPage、tinySubPage、ChunkList按照使用率分配、Chunk的二叉树内存管理、subPage的位图内存管理。
- 高负载下内存池不断扩展,如何做到内存回收
- 对象池是如何实现的
- 内存池跟对象池作为全局数据,在多线程环境下如何减少锁竞争
- 池化后内存的申请跟释放必然是成对出现的,那么如何做内存泄漏检测,特别是跨线程之间的申请跟释放是如何处理的。
内存规格(这块其实很复杂,本文只是简单说下)
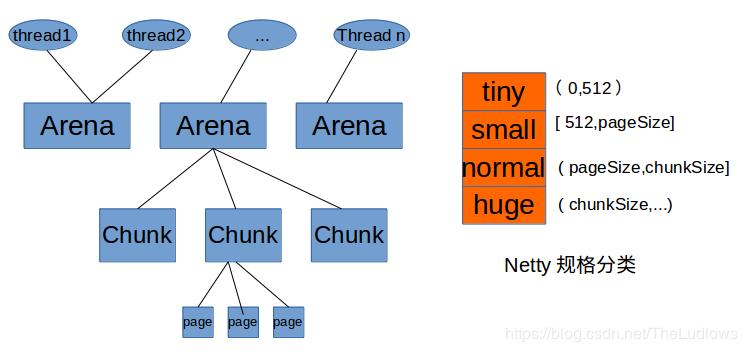
- The minimum unit of memory allocation is 16B.
- The request of less than 512B is Tiny, the request of less than 8KB (PageSize) is Small, the request of 16MB (Chunk Size) is Normal, and the request of more than 16MB (Chun kSize) is Huge.
- Requests smaller than 512B are incremented by 16B each time starting from 16B; requests larger than or equal to 512B are doubled each time.
jemalloc 在分配内存时,会根据我们申请的字节数 N,找一个比 N 大,但是最接近 N 的 2 的幂次数作为分配的空间,这样可以减少频繁分配的次数。
allocate 流程
public class PooledByteBufAllocator extends AbstractByteBufAllocator implements ByteBufAllocatorMetricProvider {
private final PoolArena<byte[]>[] heapArenas;
private final PoolArena<ByteBuffer>[] directArenas;
private final PoolThreadLocalCache threadCache;
protected ByteBuf newHeapBuffer(int initialCapacity, int maxCapacity) {
PoolThreadCache cache = threadCache.get();
PoolArena<byte[]> heapArena = cache.heapArena;
final ByteBuf buf;
if (heapArena != null) {
buf = heapArena.allocate(cache, initialCapacity, maxCapacity);
} else {
buf = PlatformDependent.hasUnsafe() ?
new UnpooledUnsafeHeapByteBuf(this, initialCapacity, maxCapacity) :
new UnpooledHeapByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer(buf);
}
}
abstract class PoolArena<T> implements PoolArenaMetric {
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// 从对象池 中取出一个 buf 对象
PooledByteBuf<T> buf = newByteBuf(maxCapacity);
// 从内存池 取出一块内存 赋给buf
allocate(cache, buf, reqCapacity);
return buf;
}
protected abstract PooledByteBuf<T> newByteBuf(int maxCapacity);
// HeapArena 是 PoolArena 子类,也是内部类
static final class HeapArena extends PoolArena<byte[]> {
@Override
protected PooledByteBuf<byte[]> newByteBuf(int maxCapacity) {
return HAS_UNSAFE ? PooledUnsafeHeapByteBuf.newUnsafeInstance(maxCapacity)
: PooledHeapByteBuf.newInstance(maxCapacity);
}
}
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
final int normCapacity = normalizeCapacity(reqCapacity);
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
if (tiny) { // < 512
cache.allocateTiny(this, buf, reqCapacity, normCapacity)
...
return;
} else {
cache.allocateSmall(this, buf, reqCapacity, normCapacity);
...
return;
}
}
if (normCapacity <= chunkSize) {
cache.allocateNormal(this, buf, reqCapacity, normCapacity)
...
return;
} else {
// Huge allocations are never served via the cache so just call allocateHuge
allocateHuge(buf, reqCapacity);
}
}
private void allocateHuge(PooledByteBuf<T> buf, int reqCapacity) {
PoolChunk<T> chunk = newUnpooledChunk(reqCapacity);
activeBytesHuge.add(chunk.chunkSize());
buf.initUnpooled(chunk, reqCapacity);
allocationsHuge.increment();
}
}
class PooledHeapByteBuf extends PooledByteBuf<byte[]> {
// ByteBuf 工作的基础元素
protected long handle;
protected T memory;
protected int offset;
protected int length;
int maxLength;
// 持有ByteBuf 相关的一些引用
protected PoolChunk<T> chunk;
PoolThreadCache cache;
private ByteBuffer tmpNioBuf;
private ByteBufAllocator allocator;
static PooledHeapByteBuf newInstance(int maxCapacity) {
PooledHeapByteBuf buf = RECYCLER.get();
buf.reuse(maxCapacity);
return buf;
}
void initUnpooled(PoolChunk<T> chunk, int length) {
init0(chunk, 0, chunk.offset, length, length, null);
}
private void init0(PoolChunk<T> chunk, long handle, int offset, int length, int maxLength, PoolThreadCache cache) {
assert handle >= 0;
assert chunk != null;
this.chunk = chunk;
memory = chunk.memory; // 将chunk 的内存起始地址 赋给ByteBuf
allocator = chunk.arena.parent;
this.cache = cache;
this.handle = handle;
this.offset = offset;
this.length = length;
this.maxLength = maxLength;
tmpNioBuf = null;
}
}
创建对象和分配内存不是一起的:ByteBuf byteBuf = PooledByteBufAllocator.newnewHeapBuffer(xx,xx) 并不是new 一个对象,创建一个数组。而是从对象池中 get 一个bytebuf对象,从内存池中 拿到一个适合大小的array 将array 地址赋给 bytebuf,bytebuf 对外接口 操作这块内存。 Recycler负责对象的分配与回收(这块还没细看),PooledArena负责buffer对象引用内存的分配与回收。

和线程的关系
Arena和线程的关系
PoolArena是Arena功能的门面,通过PoolArena提供接口供上层使用,屏蔽底层实现细节。为了减少线程成间的竞争,很自然会提供多个PoolArena。Netty默认会生成2×CPU个PoolArena跟IO线程数一致。
虽然提供了多个PoolArena减少线程间的竞争,但是难免还是会存在锁竞争,所以需要利用ThreaLocal进一步优化,把已申请的内存放入到ThreaLocal自然就没有竞争了。大体思路是在ThreadLocal里面放一个PoolThreadCache对象,然后释放的内存都放入到PoolThreadCache里面,下次申请先从PoolThreadCache获取。PS:换个说法,Netty会为每一个线程都维护一个PoolThreadCache对象,当进行内存申请时,首先会尝试从PoolThreadCache中申请,如果无法从中申请到,则会尝试从Netty的公共内存池中申请。
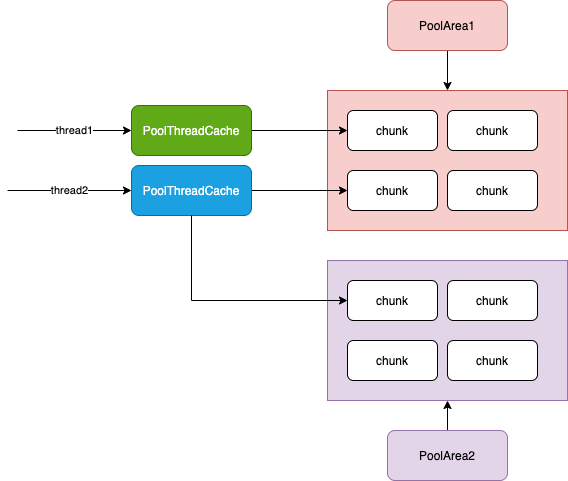
对象池和线程的关系
Netty-对象池(Recycler)每个线程都有自己的对象池,分配时从自己的对象池中获得一个对象。其他线程release对象时,把对象归还到原来自己的池子中去(分配线程的池子)。大量使用了ThreadLocal,每个线程都有自己的stack和weakorderqueue,做到线程封闭,有力减小竞争。
// 获取一个对象
public abstract class Recycler<T> {
public final T get() {
if (maxCapacityPerThread == 0) {
return newObject((Handle<T>) NOOP_HANDLE);// 当没有可用对象时创建对象的实现方法
}
Stack<T> stack = threadLocal.get();
DefaultHandle<T> handle = stack.pop();
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}
}
// 回收一个对象
public final boolean recycle(T o, Handle<T> handle) {
if (handle == NOOP_HANDLE) {
return false;
}
DefaultHandle<T> h = (DefaultHandle<T>) handle;
if (h.stack.parent != this) {
return false;
}
h.recycle(o);
return true;
}
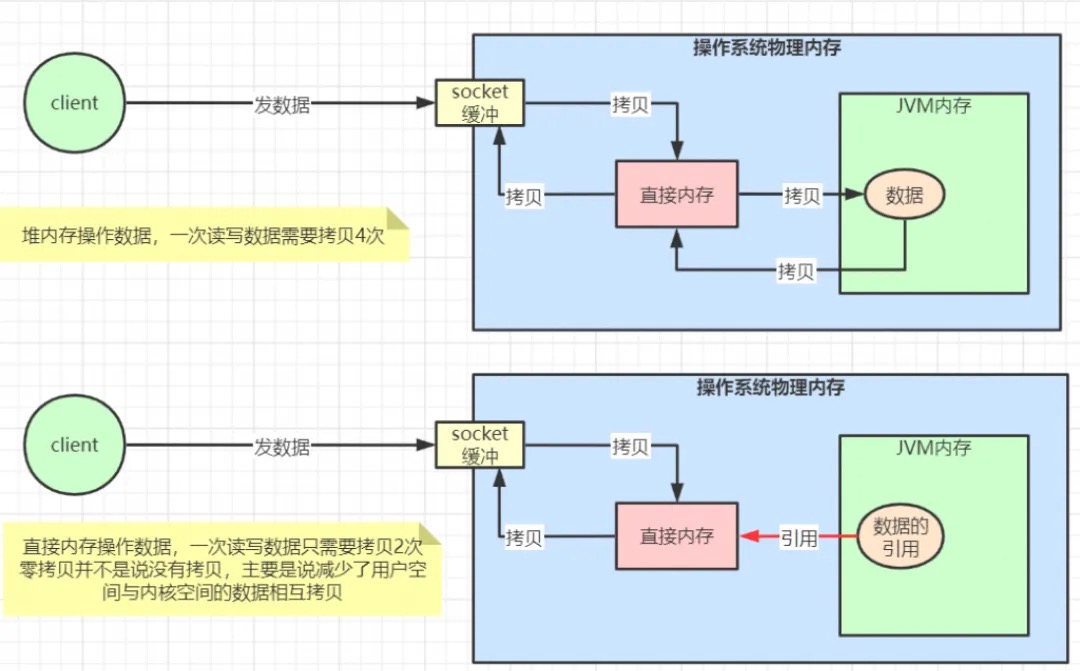
零拷贝
PS: 所谓零拷贝就是jvm堆内存只是持有引用。
留下评论