强化学习细节(上):基本概念与直觉
简介
如果你想先建立整体框架,建议先看从长期回报、Credit Assignment 到 PPO。这篇保留细节、公式和推导,主线篇则以问题主线和演化关系为主。
这篇虽然会多次借用 LLM / token 生成来帮助理解,但它讨论的仍然是通用 RL 细节,重点在策略梯度、Advantage、Actor-Critic、GAE、PPO 这些方法本身。如果你更想专门看 RL 放到 LLM post-train 之后的对应关系,可以再读LLM Post-Train 中的 RL:从 PPO 到 GRPO。
强化学习的目标是找到一个「策略」,所谓策略,就是「在某个环境状态下,需要采取某个动作」。这里的「学习」二字,可以借由「机器学习」的概念去理解,你可以笼统地认为为是「用一个函数去逼近这个策略」。而「神经网络」就可以看做是这个函数逼近器。而「强化」二字,可以借由「控制系统」的概念去理解,RL 算法是构建一个「闭环控制系统」,其目标是通过与环境的交互来优化决策。在不断地「采样-评估-更新」过程中,找到或逼近解一个高维动态规划问题的「最优策略」,其本质是求解由随机过程和不完全信息耦合所带来的高维优化问题。在这个视角下,RL的数学本质可以概括为:构建闭环的学习系统,利用反馈信息去逼近策略函数。PS:「闭环」是控制系统中的概念,具有反馈环节,能够感知系统输出的变化,并根据输出的变化进行调整。与之相对的是「开环」概念,没有反馈环节。
PS:单单是rl 强化学习本身的推导就是一门很厚的知识,搞明白actor-critic 就有百分之七八十了,之后是ppo 针对actor-critic 的一些调整,可以直接看PPO理论推导+代码实战
从训练机器人行走开始
策略梯度法入门—强化学习该例是要设计一个两腿机器人,使其能自动的行走。机器人左右腿的跨、膝、踝共有6个关节,都装有小电机,希望能自动控制它的6个小电机,使机器人能和人一样正常的行走。
强化学习需要一个软件系统,其基本组成包括:
- 代理(Agent智能体):是个软件,相当于机器人的大脑,是强化学习的核心。它可以接受环境状态的信息,还可以将计算的结果传输给环境。其中,负责计算的是个函数,称作策略(policy),是强化学习最重要的部分。
-
环境(Environment):代理以外的部分都是环境。和通常的环境概念不同,机器人所处的周边当然是环境,不同的是,机器人的躯体四肢都在代理之外,也都归于环境,比如躯干的高度,各个腿及各个关节的位置、速度等。此例中,环境状态使用31个观测值。包括
- 躯干沿Y和Z轴方向的坐标值,
- 躯干沿X、Y和Z方向的速度,
- 躯干旋转的角度和角速度,
- 6个关节的角度和角速度,
- 脚和地面之间的接触力。
- 状态(State):指环境的状态。机器人一直在移动,所以,周围环境的状态,以及自身各关节的状态也在不断的变化。
- 行动(Action):指代理根据当前状态采取的动作,比如机器人向左或向右,向前或向后移动等。
- 奖励(Reward):代理在当前状态下,采取了某个行动之后,会获得环境的反馈,称作奖励。但可能是奖励,也可能是惩罚,实际是代理对行动的评价。在强化学习中,奖励非常重要,因为样本没有标签,所以奖励起到引领学习的作用。
使机器人正常行走要做的工作。让两腿机器人正常行走,要做的工作是,用正确的指令控制每个关节,使机器人的腿和躯干正确的移动,这需要有六个关节的扭矩指令。在给定的环境状态下,如何得到正确的指令,这就是强化学习要做的工作。用传统方法开发机器人的行走程序,要人工设计逻辑、循环、控制器及参数等等,需要很多的环路,非常复杂。而强化学习的思想极为简单,它不考虑整个过程的具体步骤,不进行一步步的具体设计,而是把这一切复杂工作都塞到一个函数里,这个函数称作策略函数。策略收到环境传来的31个状态值,会自动计算出6个可供执行的指令,指令正确,机器人就会正常的行走。可以看出,强化学习中,机器人能正常行走的关键,就是这个策略函数。
所以下面的重点是:智能体里的策略函数是什么形式?它如何进行学习?如何通过环境状态值计算出6个正确的指令,使机器人能正常的行走。
- 策略是个函数,因其过于复杂,很难用显性的公式来表式。对于这种连续且复杂的问题,强化学习是采用功能强大的神经网络来近似这个函数。这里策略神经网络是用的多层感知机(最基本的前馈神经网络),并以此为例进行说明。
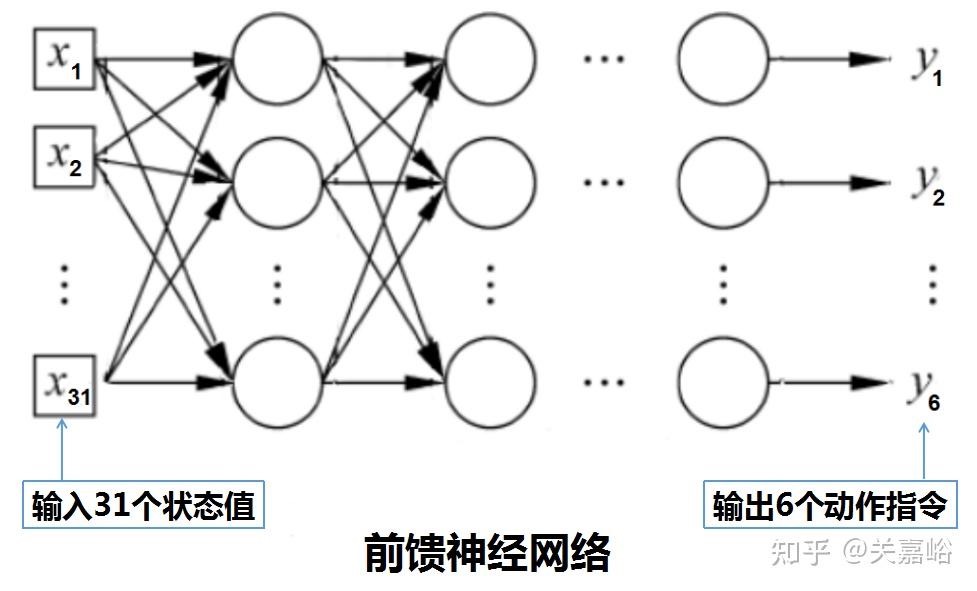 神经网络包含多个隐藏层,每层都有数百个神经元,没有足够多的神经元,网络无法拟合这么复杂的非线性函数,不可能将31个观察值正确的映射到6个动作。但是,神经元过多,将花费更多的时间训练,还容易得到过拟合的逻辑。所以,如何选择网络结构,包括网络层的数量,各层如何连接,以及每层神经元的数量等等,需要丰富的经验和知识找到最佳平衡点,使训练即可行又有效。
神经网络包含多个隐藏层,每层都有数百个神经元,没有足够多的神经元,网络无法拟合这么复杂的非线性函数,不可能将31个观察值正确的映射到6个动作。但是,神经元过多,将花费更多的时间训练,还容易得到过拟合的逻辑。所以,如何选择网络结构,包括网络层的数量,各层如何连接,以及每层神经元的数量等等,需要丰富的经验和知识找到最佳平衡点,使训练即可行又有效。 - 神经网络的学习过程。策略函数的学习过程,可以选择仿真或真实行走的方式。方法是让机器人不断的行走,不断的调整策略函数里的参数w和b,直至得到能使机器人正常行走的网络模型(策略函数)。一般前馈网络的学习,样本都有标签(标准答案),在一次前向传播后,计算出结果,先求计算结果与标签的误差(损失函数),再求损失函数对各个节点的偏导数(梯度),然后求出损失函数对各个参数w和b的偏导数,用这些参数的偏导数来调整各个参数。但是,强化学习是以状态观测值作为输入(样本),没有标签,当然也就没有损失函数,那么求谁的梯度(偏导数)?没有梯度怎么修改参数w和b?强化学习的作法是设计一个奖励函数,用动作的奖励函数作准则,来调整网络的参数。强化学习里奖励函数的作用,相当于一般神经网络里的损失函数。做法是,每输入31个环境状态值,用策略函数计算出6个动作指令,然后执行这6个动作指令,当然这会改变了环境的状态值,包括躯干和6个关节的位置和速度等,然后再计算这个动作的奖励函数值,通过提高奖励函数值来调整网络的各个参数w和b。注意,不是像一般前馈网络学习那样,通过减小损失函数来调整参数w和b。
- 奖励函数。奖励函数是人工精心设计的,其作用相当于前馈网络或循环网络的标签,是引导机器人正常行走的根据。此例已经设计好的奖励函数是$ r_t = v_x -3y^2 - 50z^2 + 25xx - 0.22xx $,其中 $v_x$ 是前进速度,$v_x$ 越大,机器人走得越快。y是侧向位移,使机器人沿着一条直线移动,不向左右偏移,越小越好。z是机器人重心的垂直位移,是要机器人的躯干保持一定的高度,不摔倒、不跳跃或蹲着走路,越小越好。其余设置,这里不逐一深究。总之,这个奖励函数值越大,机器人走的就越好。奖励函数非常重要,但其设置是个难点,需要丰富的经验和专业知识。
- 策略函数的学习过程。现在,策略函数是一个神经网络(多层感知机),策略能否做出正确的动作指令,取决于网络里的所有参数w和b。而评价一个动作优劣的标准,是这个动作的奖励函数,奖励函数的值越高,该动作就越好。所以,强化学习是求出奖励函数对各个参数w和b的梯度,让参数w和b沿着奖励函数的梯度方向调整,这样奖励函数值就会升高,下一次遇到同样的环境状态,策略计算出的指令就会更好。就这样,反复的调整参数w和b,最终得到一个可以时时做出正确指令的神经网络。
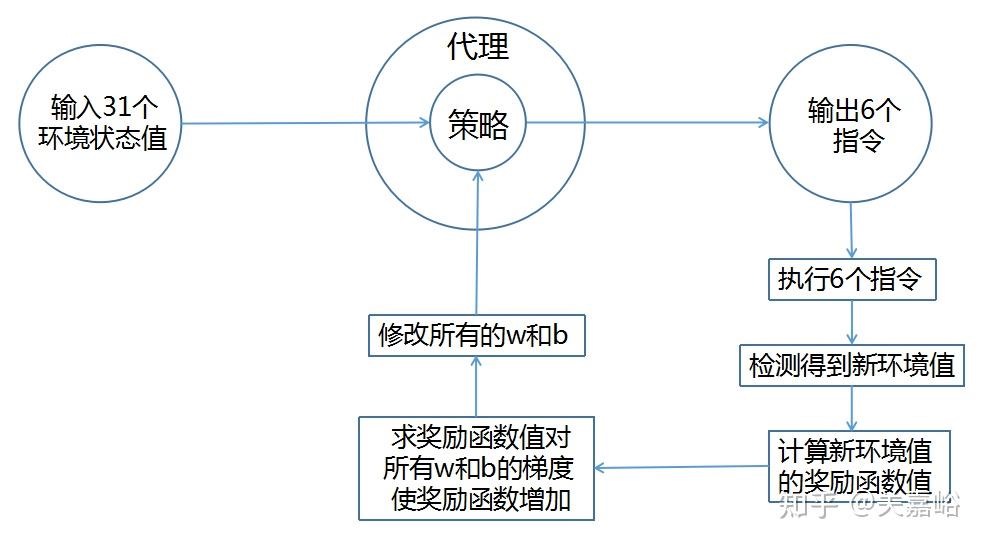 具体作法大意是
具体作法大意是
- 输入31个环境值;
- 网络计算得到6个指令,执行指令改变了环境,检 测得到了31个新环境值;
- 用检测到的31个新环境值,求奖励函数对各个参数w和b的梯度(偏导数),即反向传播;
- 修改网络所有的参数w和b;
- 返回到1,进行下一循环学习。 就这样,代理不断与环境交互,不断修改策略的参数,最终,在任何状态情况下,它都会采取最有利的行动。强化学习的过程,就是不断优化这个策略的过程,整个过程,是计算机自己在学习正确的参数,实际是个反复优化完善网络的过程。上述2执行6个指令后得到的新环境状态值,是环境检测出来的,和策略网络没有连在一起,用它求奖励函数值没问题,直接代入就行。但用这个新环境状态值对各个参数w和b求偏导数,就有问题了,因为它和策略网络根本没连接上。
PS: rl和dl都是在想办法,算一个loss,优化w和b。 李宏毅老师提到 ml 约等于looking for a funtion, 对监督学习 label = func(input), 对rl来说,action=func(observation)。
什么是强化学习
如果只用一句话概括,强化学习就是:让模型在与环境的持续交互中,通过奖励反馈不断修正策略,最终最大化长期回报。
这篇保留的是细节、推导和 LLM / PPO / GAE 相关内容。如果你想先看主线,比如 Agent / Environment / MDP / Bellman / MC / TD / value-based / policy-based 是怎么串起来的,可以先读从长期回报、Credit Assignment 到 PPO。
强化学习和监督学习最大的不同在于:监督学习面对的是静态训练集,而强化学习面对的是一个闭环系统。当前策略会影响你接下来看到的状态、动作和奖励,所以“训练数据”本身会随着策略变化而变化。
如何学习
Agent learns to take action to maximize expected reward. 单从训练视角看,RL 和 supervised learning 一样,也可以粗略理解成三步:function with unknown variable;define loss / signal from training data;optimization。
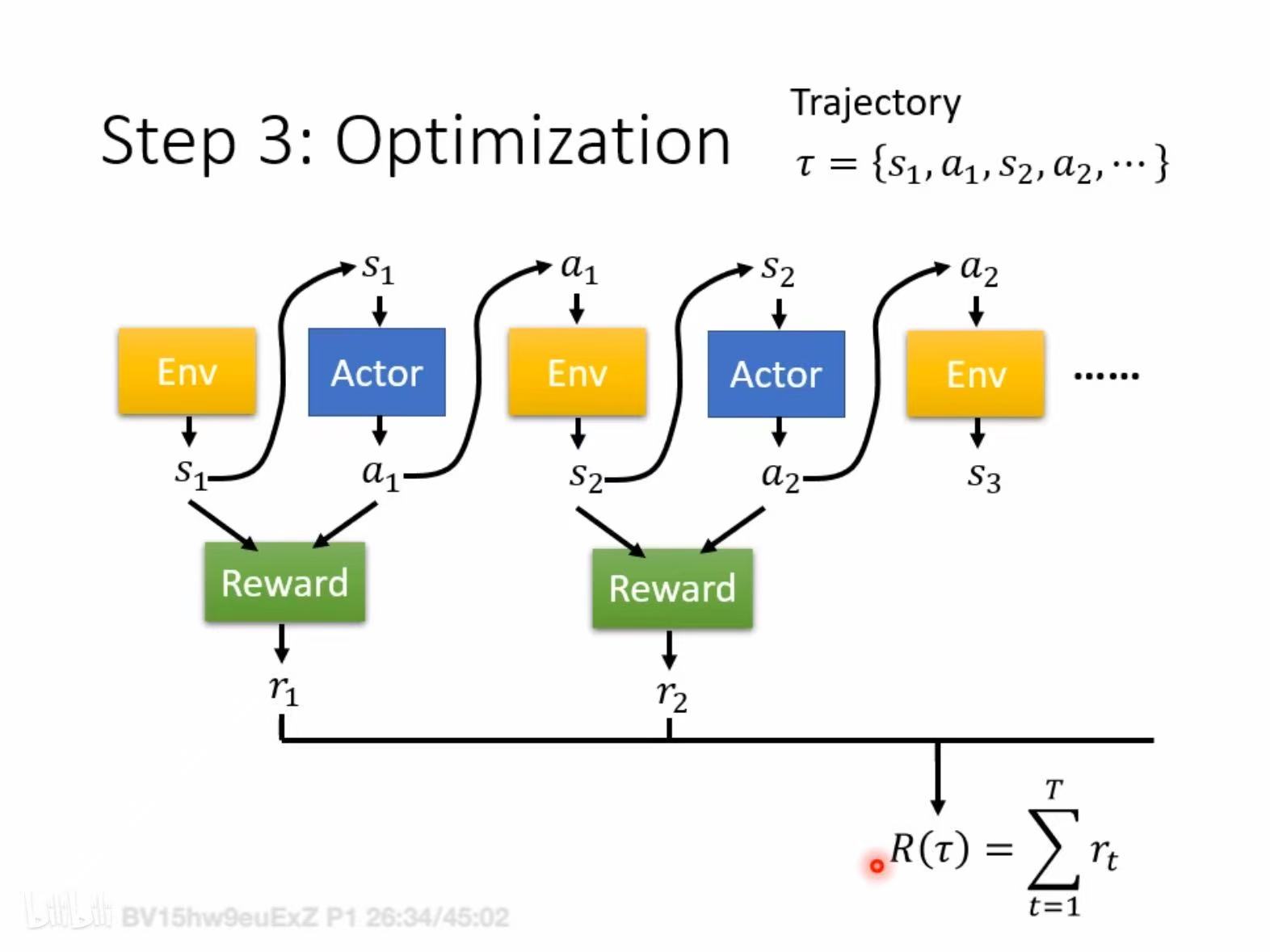
强化学习并不是根据“标准答案标签”来学,而是根据和环境交互得到的反馈来学。它优化的是累积奖励,而不是“这一步对不对”。也正因为如此,RL 往往更难收敛:奖励信号是否准确、参数更新是否平稳、交互环境是否稳定,都会直接影响训练效果。
如果你能收集很多<s,a->r> training data, 就可以监督学习Agent(如果agent 是一个network的话),不过一般不直接用r,我们用A来表示你有多希望s时采取动作a,<s,a->A>,在实践中,A有多种表示方式。
- r 直接作为A,缺点是会导致actor 比较短视
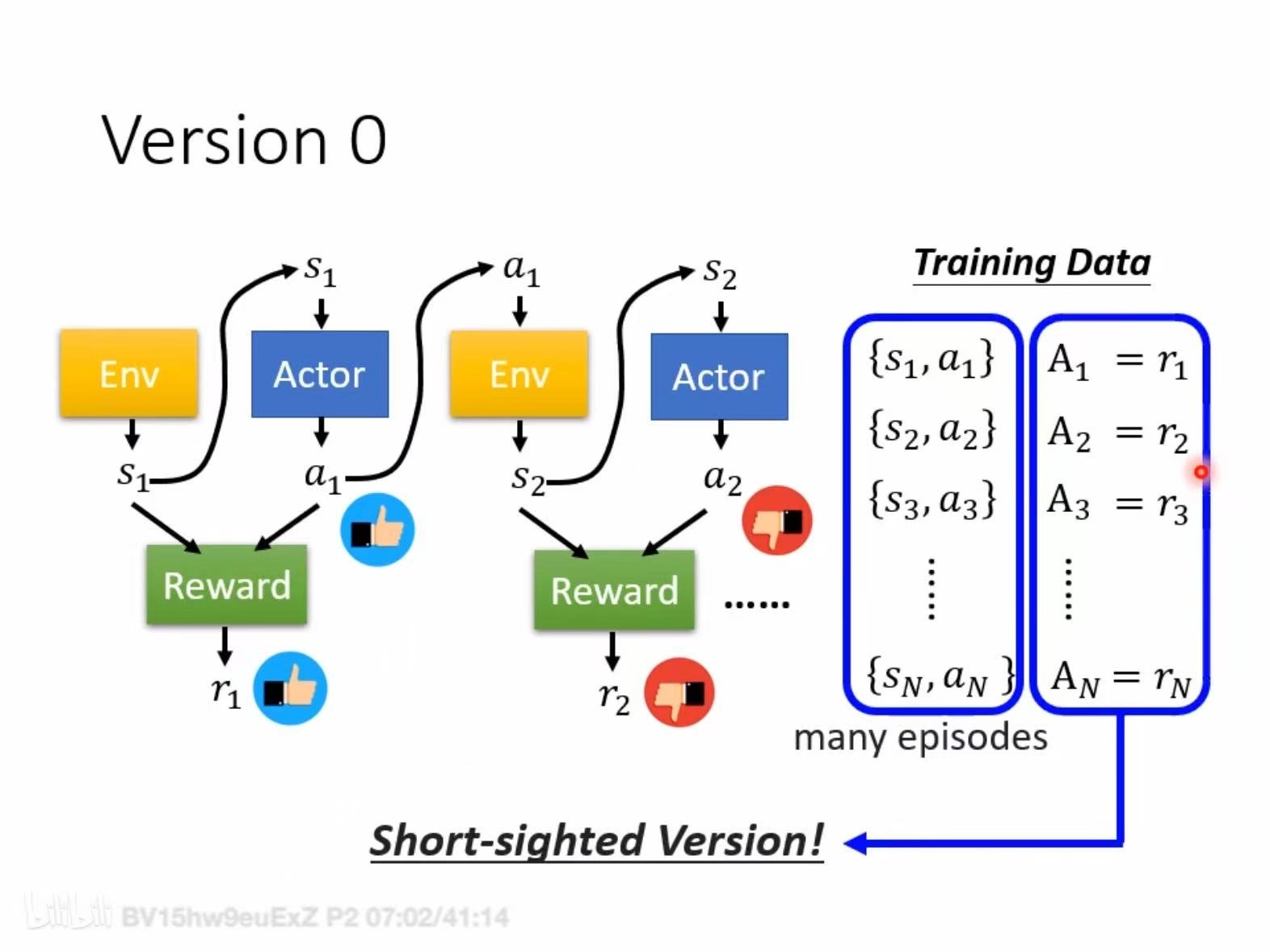
- G 作为A,缺点是越靠前的a的A越大,也不符合实际。
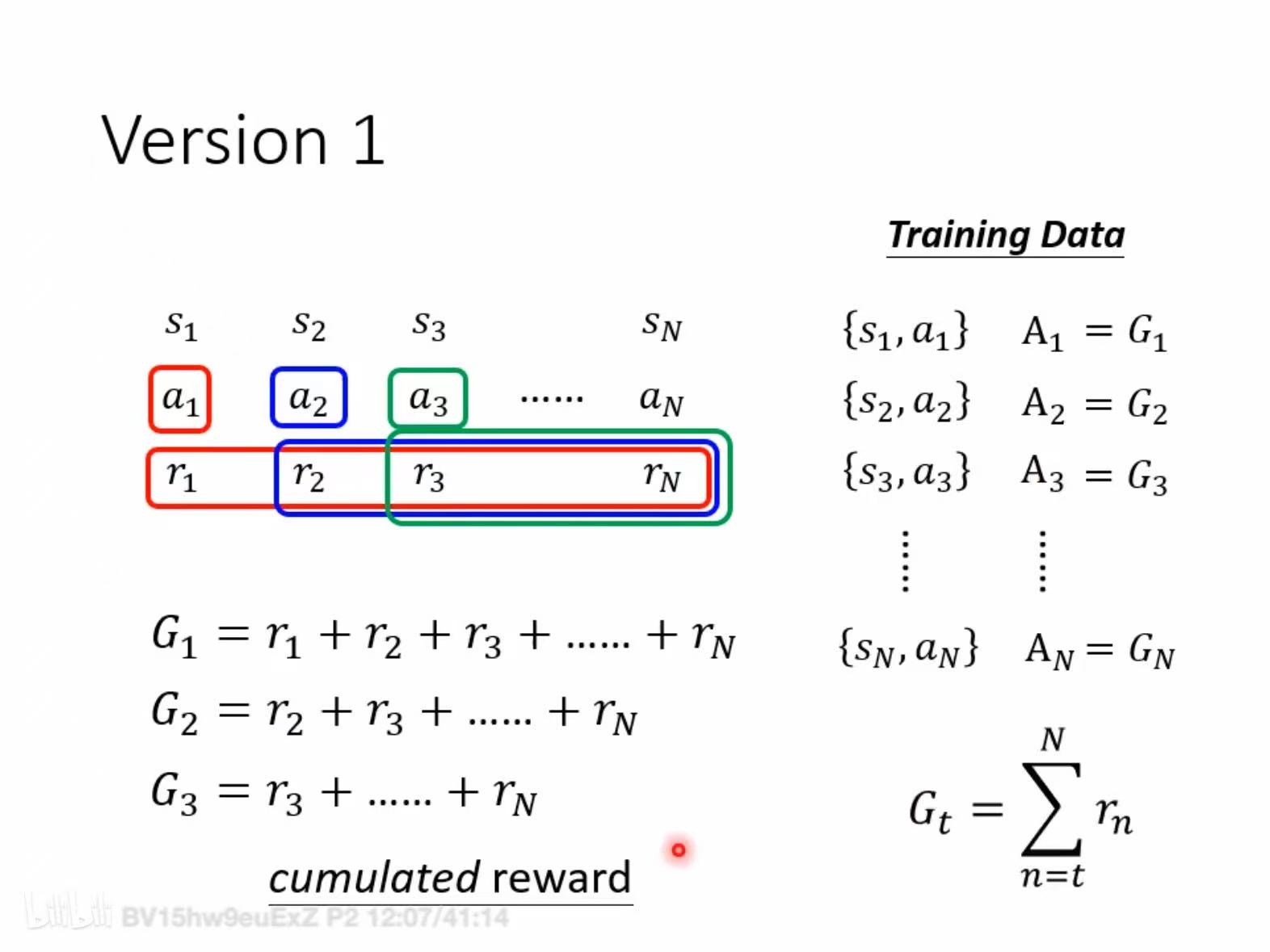
- 离a越远的r打一下折扣

- G是绝对值,不能直接用,比如一次考试你单说考了80分其实说不清楚你考的好与差,所以要对G标准化一下,一个简单的方法是减去一个baseline。,但如何选baseline也有很多花样了(下文会考)。

- 但其实这么做还有问题,比如对于下围棋来说,大部分a的$r_i$都是0,最后最后一步的a的r是1(赢)或-1(输)。所以A的花活很多,甚至专门安排一个模型来学习。
换个视角:RL 本质上是一个 gradient estimator
不管是 backprop 还是 RL,它们的最终目的都是修改 DNN 的 parameters $\theta$。先厘清一件事:backprop 本身不是一种 learning algorithm,它的作用其实是求导(differentiation)。给定一个可微的 loss $L(\theta)$,backprop 通过 chain rule 算出 $\nabla_\theta L$,然后我们把这个 gradient 交给 optimizer(SGD、Adam)去更新 $\theta$。
在监督学习(比如 CNN)里,这个流程非常直观,因为 data 和 $\theta$ 无关——不管训练时 params 怎么变,图片本身不会变,所以我们可以直接对着固定的 dataset 做 backprop。
而 RL 的目标函数是 $J(\theta) = \mathbb{E}{\tau \sim \pi\theta}[R(\tau)]$,我们想最大化策略 $\pi_\theta$ 所能 sample 到的 trajectory 的 average returns。看起来也是”算个目标、对 $\theta$ 求导、交给 optimizer”,但真要动手求导,会撞上两道监督学习里根本不存在的坎。
-
数据分布本身随 $\theta$ 一起动(监督学习里数据是钉死的)。把两边的目标摊开对比就清楚了。监督学习的 loss 长这样:
\[L(\theta) = \frac{1}{N}\sum_{i=1}^{N} \ell\big(f_\theta(x_i),\, y_i\big)\]这里的数据 $(x_i, y_i)$ 来自一个固定的、和 $\theta$ 无关的 dataset。所以求梯度时,求和号外面那一圈样本纹丝不动,梯度只落在里面的 $f_\theta$ 上:$\nabla_\theta L = \frac{1}{N}\sum_i \nabla_\theta\, \ell\big(f_\theta(x_i), y_i\big)$。一句话——对着一批不变的题,只调整你的答题函数。
而 RL 的目标,把期望按定义展开,其实是对所有可能的轨迹求和:
\[J(\theta) = \sum_{\tau} P(\tau;\theta)\, R(\tau)\]关键在于轨迹出现的概率 $P(\tau;\theta)$ 里带着 $\theta$。逻辑链路是:$\theta$ 变 → 策略 $\pi_\theta$ 变 → 每一步采的 action 变 → 环境随之给出的下一个 state 也变 → 整条轨迹 $\tau$ 的分布 $P(\tau;\theta)$ 跟着变。也就是说,你”训练数据”(采样到的轨迹)的分布,随着你优化 $\theta$ 一起在漂。这就是后面会反复出现的 on-policy 困境:上一轮采的数据,参数一更新就”过期”了。落到求导上,这一项绕不过去——你必须对 $P(\tau;\theta)$ 本身求导,而不能像监督学习那样把数据分布当常数提到求和号外面。
-
采样这一步不可导,链式法则在这里断了。
就算我们下决心去对 $P(\tau;\theta)$ 求导,还有第二道坎。策略网络的实际工作方式是:forward 先算出一个动作的概率分布(比如 logits 过 softmax),然后从这个分布里”掷骰子”抽一个具体的 action $a \sim \pi_\theta(\cdot\mid s)$。(顺带一提,softmax 有平移不变性——logit 的绝对高度无意义,只有 logit 之间的差值有意义:所有 logit 同时加一个常数,$\text{softmax}$ 出来的分布完全不变。这也是常说”模型权重的绝对大小意义不大、相对值才重要”的一个来源。)
监督学习的前向过程,从头到尾都是矩阵乘、激活函数这类可微算子的堆叠,所以 chain rule 能一路从 loss 流回每个参数。但”从分布里采样”这一步不是可微算子:它的输入是一组概率,输出是一个被随机抽中的离散动作。你把 $\theta$ 挪动一丁点,这个被抽中的动作要么不变、要么突然跳到另一个值,中间没有平滑的 $\frac{\partial a}{\partial \theta}$ 可言。形象点说,采样就像在计算图正中间插了个
np.random.choice,梯度流到这儿就断了,没法像监督学习一样直接 backprop 穿过去。
所以 RL 真正要解决的是:如何去 estimate $\nabla_\theta J(\theta)$?这就是 policy gradient 的由来。解法是一个很巧的数学技巧——log-derivative(似然比)技巧。它基于一个对任意可微概率 $P$ 都成立的恒等式(来自 $\nabla_\theta \log P = \frac{\nabla_\theta P}{P}$ 这条求导链式法则的反用):
\[\nabla_\theta P(\tau;\theta) = P(\tau;\theta)\,\nabla_\theta \log P(\tau;\theta)\]把它代进 $\nabla_\theta J(\theta) = \sum_\tau \nabla_\theta P(\tau;\theta)\, R(\tau)$:
\[\nabla_\theta J(\theta) = \sum_\tau P(\tau;\theta)\,\nabla_\theta \log P(\tau;\theta)\, R(\tau) = \mathbb{E}_{\tau \sim \pi_\theta}\big[R(\tau)\,\nabla_\theta \log P(\tau;\theta)\big]\]这一步同时拆掉了上面两道坎:
- 拆第一道坎:右边重新变回了一个”对 $\pi_\theta$ 的期望”,于是可以用采样去估计——拿当前策略实际跑出来的几条轨迹求平均,就是对这个期望的无偏估计,不必再纠结”分布在漂”。
- 拆第二道坎:再把 $\log P(\tau;\theta)$ 展开,一条轨迹的概率 = 环境的状态转移概率 × 策略每步的动作概率,而环境转移概率不含 $\theta$、求导后整项消失,只剩下 $\sum_t \nabla_\theta \log \pi_\theta(a_t\mid s_t)$。这一项是策略网络输出的 log 概率,完全可微,backprop 能正常穿过去——我们绕开了”对采样本身求导”,改成对”采到的动作的 log 概率”求导。
于是就得到著名的 REINFORCE:$\nabla_\theta J(\theta) = \mathbb{E}{\pi\theta}[R(\tau)\nabla_\theta \log \pi_\theta(\tau)]$,通过 sampling 若干 trajectories 来 estimate 这个 expected value,得到一个关于 gradient 的“近似”。直觉上它在干一件很朴素的事:对你真正采到的那些动作,按它最终带来的回报 $R$ 的好坏,去调高或调低它们的 log 概率——好动作让它以后更容易被采到,差动作压下去。这也正是”用 A 来表示你有多希望 s 时采取动作 a”的数学出处:公式里的 $R(\tau)$ 就是那个权重 A,A 估得越准,这个梯度就越靠谱。
说清楚这一层,关系就明确了:在监督学习里,backprop 直接精确地给出 gradient;但在 RL 里,我们没法直接求这个 gradient,所以需要 policy gradient 这类方法先 estimate 出一个 gradient,然后把这个近似值交给和监督学习完全一样的 optimizer(Adam)去更新 $\theta$。换句话说,RL 的作用本质上是一个结构复杂的 gradient estimator,给 optimizer 提供优化信息;而它的那些子问题(credit assignment、exploration、variance reduction)全部是为了让最终输出的那个 gradient vector 更准。
有偏与无偏:RL 估计里的两个维度
RL 里到处在“估计”一个没法直接算出来的量——最典型的就是“在当前局面下,未来到底能拿多少分”(价值 $V$)。未来还没发生、还带运气成分,所以只能拿手头的样本去估计它。既然是估计,“准不准”要拆成两个互相独立的维度:有没有偏(bias)、稳不稳(variance)。很多人一上来就把它们混在一起,这是第一个坎。
把“估计”想象成反复做很多次、每次给出一个数:
- 无偏(unbiased):这些数平均下来正好等于真实值。单看某一次可能偏高偏低,但没有系统性地偏向某个方向,误差会互相抵消。
- 有偏(biased):这些数平均下来系统性地偏高(或偏低),而且这个偏差再多做几次也消不掉——因为方法本身锚错了地方。
关键:“无偏”不等于“这一次准”。无偏说的是方法没有系统性偏向,是对方法的评价,不是对单次结果的评价。
打靶比喻最直观(真实值 = 靶心,每次估计 = 一发子弹):
| 方差小(稳) | 方差大(散) | |
|---|---|---|
| 无偏 | 全打在靶心——理想 | 弹着点乱飞,但平均落点在靶心,多打几枪取平均会逼近靶心 |
| 有偏 | 枪枪打在一起,但整体偏在角落,再多打也到不了靶心 | 又散又偏——最差 |
带数字的小例子:假设某学生这类考试的真实平均分 = 70(靶心,但你不知道)。
- 无偏、高方差:随便抽他一次成绩当估计,这次 45、下次 92,单看不靠谱,但抽足够多次取平均 → 收敛到 70。它没偏,只是抖。
- 有偏、低方差:干脆每次都报“上学期记录的 65 分”,永远 65、超级稳,但系统性低了 5 分,做一万次还是 65。它很稳,但偏了。
放到 RL 里(具体推导见下篇与主线篇),这正是 MC 与 TD 的区别:
- MC(蒙特卡洛):用整条轨迹真实拿到的回报 $G_t$,没掺任何猜测 → 无偏;但把一整条轨迹的随机都加进来 → 高方差。
- TD:用“当前奖励 + 对下一步价值的估计 $V(s’)$”,而 $V(s’)$ 是还没训准的网络猜的 → 有偏;但只看一步 → 低方差。
所以 RL 里几乎所有花活,本质都在这条 bias-variance(偏差-方差)权衡轴上挑位置:要无偏但抖(如 MC、以及用组内均值当 baseline 的做法),还是吃一点偏差换稳定(如 TD、critic)。这条轴会在下篇的 baseline / Actor-Critic / GAE 里反复出现。
而且这条轴的最优落点会随任务的“长短”移动——2025 年长程 Agentic 任务起来后,这点变得很显眼:
- 短任务(数学题、单测这类几十到几千 token、可验证的):轨迹短、方差本就小,又有清晰的最终得分,于是“无偏但高方差、还省掉 critic”的做法(用组内均值当 baseline,即 GRPO 那一路)几乎无损,还省显存,很划算。
- 长程任务(几十上百步、动辄上十万 token 的 agent 轨迹):方差随轨迹长度不断累积,“整条输出共用一个优势”又把信用分配摊得极粗,这时无偏的代价太大,反而值得吃一点偏差、把 critic 请回来(PPO 那一路)压方差、给每一步单独的信号。
所以“短任务爱用 GRPO、长任务回 critic”,本质不是谁取代谁,而是 bias-variance 天平随 horizon 换了落点。这个“天平”的完整版(GRPO/PPO 在长短程下的机制差异)见 LLM Post-Train 中的 RL;通用 RL 的 critic / GAE 推导见下篇。
留下评论