关于docker image的那点事儿
简介
2013 年,Docker 出现了,工程师可以第一次到软件生产环境中定义,通过 Docker image 完成单机软件的交付和分发。Docker 不完全是基础设施即代码,但 Dockerfiles 确实允许您将应用程序运行时定义为 git 存储库中的一个简单文件。
自下而上学习容器对于熟悉 runc 是如何启动容器的人来说,他们都知道镜像并非是必需的。那我们为什么还要有容器镜像?当每一个容器都包含根文件系统的一个数兆字节那么大的拷贝副本时,所需的磁盘空间就会急剧增加。因此,镜像的存在是为了有效地解决存储和发行问题。
打包所有依赖
代码分发:在物理机时代, springboot项目普遍都带了一个run.sh文件,不论项目本身的特点如何,开发和运维约定run.sh start/stop来启停应用
- 这说明只有一个jar是运行不起来的
- 如果我们不是一个java系为主的公司,这么做够么? 到后面,你就发现,run.sh 里可能什么都有,包括依赖库(比如转码程序会安装ffmpeg)、下载文件等,run.sh做到极致:一个应用一个操作系统环境(依赖库、env等),但整个文件岂不是很大?Docker最大的贡献就是提出了分层镜像的概念。
想起了大学宿舍时候的装系统:
- 当说镜像的时候第一反应是啥?一键ghost ==> 装系统 ==> 装qq ==> 自动启动项目 ==> 装系统顺带装app
- App最完整的依赖的OS ==> 为了启动app干脆配上一个系统 ==> 裸操作系统 + docker即可运行任何项目。
进一步延伸到集群概念 集群镜像:实现高效的分布式应用交付
镜像与操作系统的关系
并非每个容器内部都能包含一个操作系统docker镜像不仅能够打包应用,还能打包整个操作系统的文件和目录,记住是操作系统的文件和目录。通过这种方式docker就把一个应用所有的依赖库包括操作系统中的文件和目录都被打包到镜像中。docker正是通过打包操作系统级别的方式,解决了开发到线上环境的一致性。宿主机操作系统只有一个内核,也就是说,所有的容器都依赖这一个内核了?比如我现在有一个需求,我的两个容器运行在同一台宿主机上,但是依赖的内核版本不一样,或者需要配置的内核参数不一样,怎么解决呢?解决不了,这也是容器化技术相比于虚拟机的主要缺陷之一。
内核,操作系统和发行版之间的区别:
- Linux内核是Linux操作系统的核心部分。这就是Linus最初写的。
- Linux操作系统是内核和用户域(库,GNU实用程序,配置文件等)的组合。
- Linux发行版是Linux操作系统的特定版本,例如Debian,CentOS或Alpine。
其实linux操作系统中代码包含两部分,一部分是文件目录和配置,另外一部分是内核,这两部分是分开存放的,内核模块只有在宿主机开机启动时才会加载。说白了,即使镜像中包含了内核也不会被加载。说到最后,原来镜像只是包含了操作系统的躯干(文件系统),并没有包含操作系统的灵魂(内核)。 容器中的根文件系统,其实就是我们做的镜像。
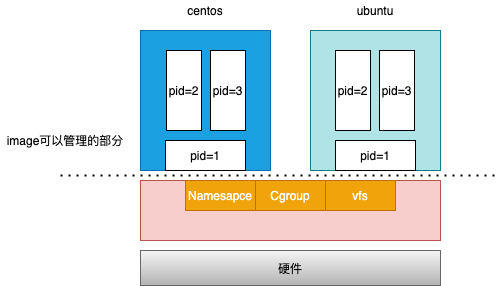
容器文件系统往事
容器那些事儿-从graph dirver谈起容器中使用两种文件系统:overlay 和 snapshotting。
- AUFS 和 OverlayFS 都为 overlay 文件系统,有多个目录为镜像中的每一层提供文件 diff。overlay 通常工作在 EXT4 和 XFS 这类文件系统上。
- 而 snapshot 文件系统包括 devicemapper、btrfs 和 ZFS,它们在块层级处理文件 diff。snapshot 文件系统只在其格式化的卷上。
Docker 最早只支持 Ubuntu,因为它是唯一支持 AUFS 的Linux发行版,Docker 使用 overlay 文件系统来构建镜像和容器的读写层。为了让 Docker 能够支持老版本的内核,需要 Docker 除 AUFS 以为更多的文件系统。因此,对支持device mapper(LVM thinpool)成为替换 AUFS 兼容老版本的可选项。为了让更多Linux发行版用户用上 Docker,文件系统的支持必须是可插拔的。Solomon 设计了一个新的驱动 API 以支持 Docker 中的多个文件系统。他们将新 API 命名为 graph driver,因为 Docker 将镜像各层的关系建模在“图”中,而文件系统主要存储镜像。但是随着时间的推移,需求日益增多,graph driver有很多问题,于是又出现了 snapshotter API 。
联合文件系统是一种 堆叠文件系统,通过不停地叠加文件实现对文件的修改。可以把多个目录内容联合挂载到同一个目录下 ,而目录的物理位置是分开的,并且对文件系统的修改是类似于 git 的 commit 一样 作为一次提交来一层层的叠加的。其中,增加操作通过在读写层增加新文件实现,删除操作一般通过添加额外的删除属性文件实现,比如删除a.file时读写层增加一个a.file.delete文件。修改只读层文件时,需要先复制一份儿文件到读写层,然后修改复制的文件。PS:所以我们说镜像是一层层的,每个layer是什么呢? 一堆文件,比如a.file 和 b.file.delete 文件。
容器的rootfs 由多个layer 文件叠加而成,每个layer 文件在分发时都必须被打包成一个tar 文件(即a.file 和b.file.delete或whiteout标记 弄成一个文件),可选择压缩或非压缩的方式。打成一个文件的好处 除了发布方便,还可以生成摘要,便于校验和按内容寻址。
在 Docker 中,镜像相当于是容器的模板,一个镜像可以衍生出多个容器。镜像利用 UnionFS 技术来实现,就可以利用其 分层的特性 来进行镜像的继承,基于基础镜像,制作出各种具体的应用镜像,不同容器就可以直接 共享基础的文件系统层 ,同时再加上自己独有的改动层,大大提高了存储的效率。对于相同的镜像层,每一个容器都会有自己的可写容器层,并且所有的变化都存储在这个容器层中,所以多个容器可以共享对同一个底层镜像的访问,并且拥有自己的数据状态。而当容器被删除时,其可写容器层也会被删除,如果用户需要持久化容器里的数据,就需要使用 Volume 挂载到宿主机目录。
本地存储
Where are Docker images stored?
docker inspect xx GraphDriver 的部分输出
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/cad72d6e952bbffb754bf3a13af0c401ae1ab743ef4ed0b9994e57ef127c3d29-init/diff:/var/lib/docker/overlay2/6a190d31ec303cc0a4163c2698a38ce449d660265bbab709503a2ac4dde4aa7f/diff:/var/lib/docker/overlay2/05c46a2829a0b37e856434489ef2684c507276697cc325f98225d1d15c84a9bb/diff:/var/lib/docker/overlay2/77aa0717d4e28977139c25a52afb04de25b8bb478670b24f3c8b409b1f1b9495/diff",
"MergedDir": "/var/lib/docker/overlay2/cad72d6e952bbffb754bf3a13af0c401ae1ab743ef4ed0b9994e57ef127c3d29/merged",
"UpperDir": "/var/lib/docker/overlay2/cad72d6e952bbffb754bf3a13af0c401ae1ab743ef4ed0b9994e57ef127c3d29/diff",
"WorkDir": "/var/lib/docker/overlay2/cad72d6e952bbffb754bf3a13af0c401ae1ab743ef4ed0b9994e57ef127c3d29/work"
},
"Name": "overlay2"
},
- lower, 表示较为底层的目录,对应 Docker 中的只读镜像层
- uppder, 在 OverlayFS 中,如果有文件的创建,修改,删除操作,那么都会在这一层反映出来,它是可读写的。对应 Docker 中的可写容器层
- merged,挂载点(mount point)目录,也是用户看到的目录,用户的实际文件操作在这里进行。
- work,只是一个存放临时文件的目录,OverlayFS 中如果有文件修改,就会在中间过程中临时存放文件到这里,在使用过程中对用户不可见
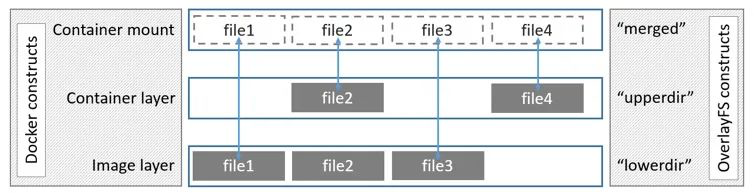
上图lowerdir 所对应的镜像层( Image layer ),实际上是可以有很多层的,图中只画了一层。有时候某个容器疯狂的写文件,大量占用磁盘,可以根据这些 overlay 目录找到所属的 容器id。或者反过来,容器退出后,想查询容器内新增的某个文件,可以查看容器 UpperDir 对应的目录。
# 检索正在运行的容器 哪个使用了目录 b941fe7f18c19285614a27857af1c811b4e117551d54f04b44c8ce5b6b585ad8
docker ps -q | xargs docker inspect --format ', , , '| grep b941fe7f18c19285614a27857af1c811b4e117551d54f04b44c8ce5b6b585ad8
# 检索所有的容器
docker ps -a |awk '{print $1}'|grep -v CONTAINER | xargs docker inspect --format ', , , '|grep 96cafbea806cfe0ccc98
镜像要复用,所以只能只读。但程序的运行会写文件,所以要可写。OverlayFS/UnionFS 解决这个折中的问题。
runC这类容器低层运行时不包含镜像管理,它假定容器的文件包已经从镜像里解压出来并存放于文件系统中。containerd是最常用的 容器高层运行时,提供镜像下载、解压等功能,但不包含镜像构建、上传等功能, 再往上,Docker 提供了许多 UX 增强功能。——镜像并不是运行容器所必须的。
制作镜像
cid=$(docker run -v /foo/bar debian:jessie)
image_id=$(docker commit $cid)
cid=$(docker run $image_id touch /foo/bar/baz)
docker commit $(cid) my_debian
image的build过程,粗略的说,就是以容器执行命令(docker run)和提交更改(docker commit)的过程
开发者可以使用一些工具(如Dockerfile)构建出自己的容器镜像、签名并上传到互联网上(分发内容一定会有签名, 更进一步签名还可以作为内容寻址),然后需要运行这些软件的人可以通过指定名称(如_example.com/my-app_)下载、验证和运行这些容器。
build 时使用http代理
2019.4.3 补充
docker build --build-arg HTTPS_PROXY='http://userName:password@proxyAddress:port' \
--build-arg HTTP_PROXY='http://userName:password@proxyAddress:port' \
-t $IMAGE_NAGE .
当你在公司负责维护docker 镜像时,不同镜像的Dockerfile 为了支持协作及版本跟踪 一般会保存在git 库中。制作镜像 通常需要安装类似jdk/tomcat 等可执行文件,这些文件建议使用远程下载的方式(因为git 保存二进制文件 不太优雅),以安装tomcat 为例
RUN \
DIR=/tmp/tomcat && mkdir -p ${DIR} && cd ${DIR} && \
curl -sLO http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-8/v8.5.40/bin/apache-tomcat-8.5.40.tar.gz &&\
tar -zxvf apache-tomcat-8.5.40.tar.gz -C /usr/local/ && \
mv /usr/local/apache-tomcat-8.5.40 /usr/local/tomcat && \
rm -rf ${DIR}
docker构建提速 好文章
多阶段构建
在一个Dockerfile中使用多个FROM指令,每个FROM都可以使用不同的基镜像。在多阶段构建中,我们可以将资源从一个阶段复制到另一个阶段,在最终镜像中只保留我们所需要的内容。
#阶段1
FROM golang:1.16
WORKDIR /go/src
COPY app.go ./
RUN go build app.go -o myapp
#阶段2
FROM scratch
WORKDIR /server
COPY --from=0 /go/src/myapp ./ ## 通过--from=0指定资源来源,这里的0即是指第一阶段。
CMD ["./myapp"]
默认情况下构建阶段没有名称,我们可以通过整数0~N来引用,即第一个from从0开始。其实我们还可以在FROM指令中添加AS <NAME> 来命名构建阶段,接着在COPY指令中通过<NAME>引用。
#阶段1命名为builder
FROM golang:1.16 as builder
WORKDIR /go/src
COPY app.go ./
RUN go build app.go -o myapp
#阶段2
FROM scratch
WORKDIR /server
#通过名称引用
COPY --from=builder /go/src/myapp ./
CMD ["./myapp"]
- 只构建某个阶段,构建镜像时,您不一定需要构建整个 Dockerfile,我们可以通过–target参数指定某个目标阶段构建,比如我们开发阶段我们只构建builder阶段进行测试。
docker build --target builder -t builder_app:v2 . - 使用外部镜像,可以使用COPY –from指令从单独的镜像复制,如本地镜像名称、本地或 Dockerhub上可用的标签或标签 ID。Docker 客户端在必要时会拉取需要的镜像到本地。
COPY --from httpd:latest /usr/local/apache2/conf/httpd.conf ./httpd.conf
entrypoint 和 cmd
- ENTRYPOINT和CMD都是让用户指定一个可执行程序,这个可执行程序在container启动后自动启动。
- 在写Dockerfile时,ENTRYPOINT或者CMD命令会自动覆盖之前镜像的ENTRYPOINT或者CMD命令。
- 在docker镜像运行时,用户也可以在命令指定具体命令,覆盖在Dockerfile里的命令。
docker run -it imageName $command覆盖 CMD ,docker run -it imageName --entrypoint $entrypoint覆盖 ENTRYPOINT - CMD命令很容易被
docker run命令的方式覆盖,如果你希望你的docker镜像只执行一个具体程序,不希望用户在执行docker run的时候随意覆盖默认程序。建议用ENTRYPOINT.
ENTRYPOINT和CMD指令支持2种不同的写法: shell表示法和exec表示法,建议采用exec表示法
- shell表示法
CMD executable param1 param2,命令行程序作为sh程序的子程序运行,docker用/bin/sh -c的语法调用, pid=1 进程是/bin/sh,那么 sigterm 等信号就不会传给 executable - exec表示法
CMD ["executable","param1","param2"],有的镜像甚至连shell程序都可以没有,pid=1进程是 executable
ENTRYPOINT和CMD可以组合使用,ENTRYPOINT指定默认的运行命令, CMD指定默认的运行参数,此时只能使用Exec表示法
FROM ubuntu:trusty
ENTRYPOINT ["/bin/ping","-c","3"]
CMD ["localhost"]
# docker build -t pingimage .
- 可以不带任何参数运行
docker run命令:docker run pingimage - 可以覆盖CMD指令的值,如果你希望这个docker镜像启动后不是
ping localhost, 而是ping其他服务器,可以docker run pingimage docker.io
镜像下载
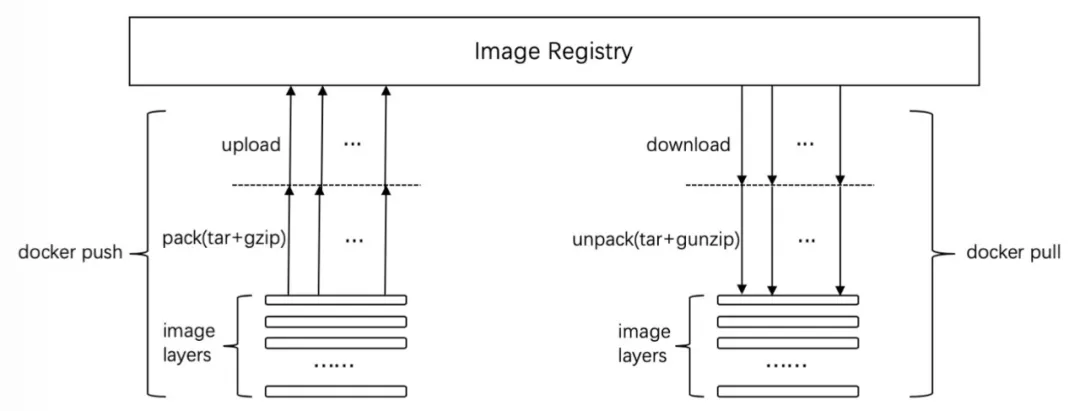
镜像一般会包括两部分内容,一个是 manifests 文件,这个文件定义了镜像的 元数据,另一个是镜像层,是实际的镜像分层文件。
镜像 = 一份文件清单 (manifest) + 一个或多个文件压缩包 (layer) + 一份配置文件 (config)。
- 文件清单列明了镜像所需的文件压缩包,同时指明了每种压缩包使用的压缩算法、哈希值和文件大小 (字节数)
- 配置文件包含了程序运行所需的硬件架构、操作系统、系统环境变量、启动命令、启动参数、工作目录等。
利用文件压缩包 hash 值的唯一性,镜像存储设施在交互时,只需根据文件清单检查本地存储,相同的压缩包只需存储一份即可,大幅提高了镜像分发的效率。在一个预热良好的机器上,传输镜像相当于只传输程序包。
docker login
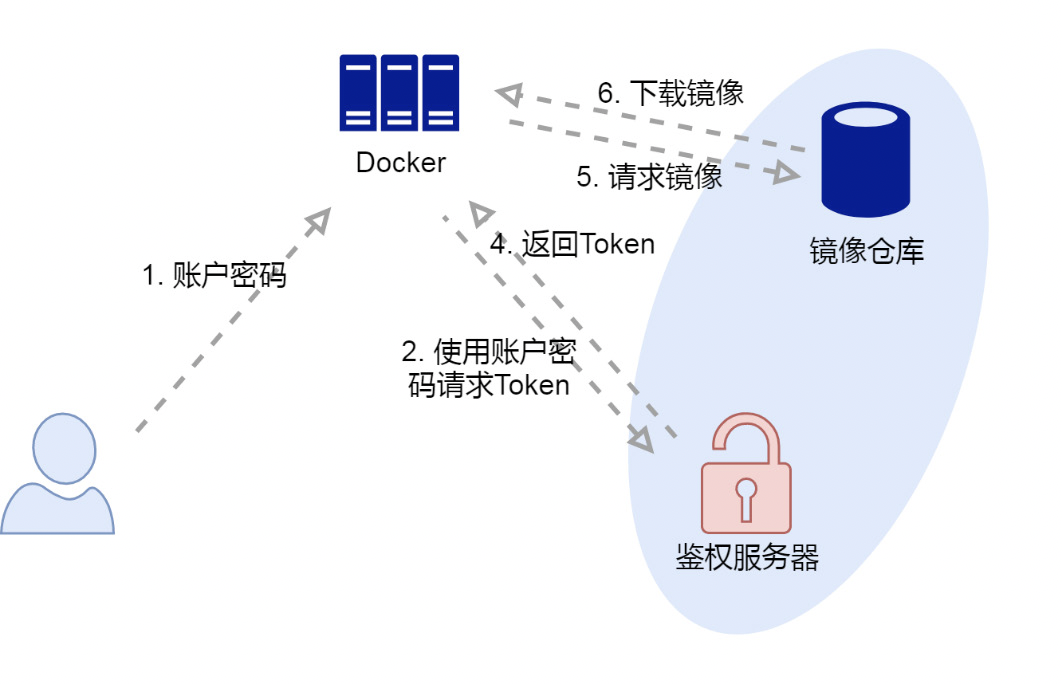
我们在拉取私有镜像之前,要使用 docker login 命令来登录镜像仓库。登录主要就做了三件 事情:
- 向用户要账户密码
- docker 访问镜像仓库的 https 地址,并通过挑战 v2 接口来确 认,接口是否会返回 Docker-Distribution-Api-Version 头字段。它的作用跟 ping 差不多,只是确认下 v2 镜像仓库是否在线,以及版本是否匹配。
- docker 使用用户提供的账户密码,访问 Www-Authenticate 头字段返回的鉴权服务器的地址 Bearer realm。如果这个访问成功,则鉴权服务器会返回 jwt 格式的 token 给 docker,然后 docker 会把账户密码编码并保存在用户目录的 .docker/docker.json 文件里。这个文件作为 docker 登录仓库的 唯一证据,在后续镜像仓库操作中,会被不断的读取并使用。
docker 镜像下载加速
两种方案
- 使用private registry
- 使用registry mirror,以使用daocloud的registry mirror为例,假设你的daocloud的用户名问
lisi,则DOCKER_OPTS=--registry-mirror=http://lisi.m.daocloud.io
Serverless 场景下 Pod 创建效率优化解压镜像耗时会占拉取镜像总耗时很大的比例,测试的例子最大占比到了 77%,所以需要考虑如何提升解压效率。gzip/gunzip 是单线程的压缩/解压工具,可考虑采用 pigz/unpigz 进行多线程的压缩/解压,充分利用多核优势。containerd 从 1.2 版本开始支持 pigz,节点上安装 unpigz 工具后,会优先用其进行解压。通过这种方法,可通过节点多核能力提升镜像解压效率。这个过程也需要关注 下载/上传 的并发度问题,docker daemon 提供了两个参数来控制并发度,控制并行处理的镜像层的数量,--max-concurrent-downloads 和 --max-concurrent-uploads。默认情况下,下载的并发度是 3,上传的并发度是 5,可根据测试结果调整到合适的值。
通常内网的带宽足够大,是否有可能省去 解压缩/压缩 的逻辑,将拉取镜像的耗时集中在下载镜像方面?当然,这个动静有点大了,要修改docker daemon。
按需加载镜像。在镜像启动耗时中,拉取镜像占比 76%,但是在启动时,仅有 6.4% 的数据被使用到,即镜像启动时需要的镜像数据量很少。对于「Image 所有 layers 下载完后才能启动镜像」,需要改为启动容器时按需加载镜像,类似启动虚拟机的方式,仅对启动阶段需要的数据进行网络传输。但当前镜像格式通常是 tar.gz 或 tar,而 tar 文件没有索引,gzip 文件不能从任意位置读取数据,这样就不能满足按需拉取时拉取指定文件的需求,镜像格式需要改为可索引的文件格式。Google 提出了一种新的镜像格式,stargz,全称是 seeable tar.gz。它兼容当前的镜像格式,但提供了文件索引,可从指定位置读取数据。然后在 containerd 拉取镜像环节,对 containerd 提供一种 remote snapshotter,在创建容器 rootfs 层时,不通过先下载镜像层再构建的方式,而是直接 mount 远程存储层,要实现这样的能力,一方面需要修改 containerd 当前的逻辑,在 filter 阶段识别远程镜像层,对于这样的镜像层不进行 download 操作,一方面需要实现一个 remote snapshotter,来支持对于远程层的管理。当 containerd 通过 remote snapshotter 创建容器时,省去了拉取镜像的阶段,对于启动过程中需要的文件,可对 stargz 格式的镜像数据发起 HTTP Range GET 请求,拉取目标数据。PS:计算与存储分离,那干脆镜像也在远端得了,serverless 对冷启动极致的追求才有了这样的优化。
留下评论