网络通信协议
简介
只要是数据协议,就有一个特点:和具体语言无关。数据协议格式只不过是对字节流的分析方式而已。TCP 连接上的数据是一个没有边界的字节流,但在业务层眼中,没有字节流,只有各种协议消息。因此,无论是从客户端到服务端,还是从服务端到客户端,业务层在连接上看到的都应该是一个挨着一个的协议消息流。
为什么RPC 框架不像消息队列一样,采用性能更好的专用的序列化实现呢?这个原因很简单,消息队列它需要序列化数据的类型是固定的,只是它自己的内部通信的一些命令。但 RPC 框架,它需要序列化的数据是,用户调用远程方法的参数,这些参数可能是各种数据类型,所以必须使用通用的序列化实现,确保各种类型的数据都能被正确的序列化和反序列化。
为什么需要协议?
- 需要明确的边界:开始,结束
- 能够携带什么信息。
整体设计
Dubbo 3.0 前瞻之:常用协议对比及 RPC 协议新形态探索一个简单的协议需要定义数据交换格式,协议格式和请求方式
- 数据交换格式(一般作为body部分,负责对象序列化反序列化),在 RPC 中也叫做序列化格式,评价序列化优劣一般从几个维度:
- 序列化后的字节数组大小
- 序列化和反序列化速度
- 序列化后的可读性
- 支持新增字段而不影响老的服务
- 协议格式(定义消息的边界,一般包含header 和 body,比如一个header 标记 body 部分是否压缩)。
- 紧凑型协议,只提供用于调用的简单元数据和数据内容。
- 复合型协议,会携带框架层的元数据用来提供功能上的增强
- 请求方式,和协议格式息息相关,常见的请求格式有同步 Request/Response 和异步 Request/Response,区别是客户端发出一个请求后,是否需要同步等待响应返回。如果不需要等待响应,一个链接上就可以同时存在多个未完成的请求,这也被叫做多路复用。另外的请求模型有 Streaming ,在一次完整的业务调用中存在多次 RPC,每次都传输一部分数据,适合流数据传输。
个人理解:
- 类比一下的话,协议格式类似于 文件系统格式(比如ext4等),序列化格式类似于文件格式(比如mp3/png等)。
- 协议格式中的字段,更多是 微服务普及以来,rpc 通信 涉及到熔断、限流、多路复用等,每一类消息 都会带 这些字段,比如streamId/messageId
- 序列化协议 更多是业务消息本身的编码
- mesh 和 通信协议
- 传统的rpc,因为服务发现、路由、 lb 这些事儿都是在 sdk 做,序列化协议只是最后 把对象序列化为二进制,可以简单一点
- 引入mesh后,sidecar 需要先反序列化 请求拿到 服务名 再做服务发现、路由这些事儿,req 一般分为header 和 body ,如果req 的header 和body 全部反解析,有点耗时,所以最好 服务名等路由依据 信息直接包含在header 里,这样sidecar 不用解析body 就可以做route lb 了
数据交换格式的几个套路
| 定位要调用的服务 | 消息长度 | 消息前后兼容 | |
|---|---|---|---|
| HTTP | URL | header里Content-Length | body里自己解决 |
| RPC | 指定Service和Method名 | 协议header里自行约定 | 交给具体IDL |
如何表达长度
古文就好比流,一个问题就是没有标点符号
- 在协议的起始位置(或其它约定位置)直接说长度
- 在协议的起始位置标识有几个元素,然后每个元素分别说明自己的长度。比如redis请求的协议格式
在流中也加上“标点符号”来断句不就行了?
- 这个办法是可行的,也有很多传输协议采用这种方法,比如 HTTP1 协议,它的分隔符是换行(\r\n)。但是,这个办法有一个问题比较难处理,在自然语言中,标点符号是专用的,它没有别的含义,和文字是有天然区分的。在数据传输的过程中,无论你定义什么字符作为分隔符,理论上,它都有可能会在传输的数据中出现。为了区分“数据内的分隔符”和真正的分隔符,你必须得在发送数据阶段,加上分隔符之前,把数据内的分隔符做转义,收到数据之后再转义回来。这是个比较麻烦的过程,还要损失一些性能。
- 更加实用的方法是,我们给每句话前面加一个表示这句话长度的数字
简单协议
- 请求和回复协议格式一致
复杂协议
- 大部分协议分为header和data部分,data部分经常随着header部分变化,比如http协议transfer-encoding:chunked或者multipart
- 需要复杂的初始化,比如ssl,在工作之前,要进行ssl握手。
- 一次语义动作的完成,需要多次通信。通常表现在,既有控制指令,又有数据指令。控制指令通常作为数据指令的上下文,需要协议框架进行存储。
协议的特点
- 文本协议 vs 二进制协议
举个例子,解析http 协议数据时,http header line 的边界是\r\n(header和 body的边界,http 协议header部分 没有长度,只能解析),给一个数据包从 []byte找 \r\n 常规来说没啥好办法,就是遍历,o(n)复杂度。
二进制安全
示例:图解Redis通信协议Redis客户端和服务端之间使用一种名为RESP(REdis Serialization Protocol)的二进制安全文本协议进行通信
Binary-safe is a computer programming term mainly used in connection with string manipulating functions. A binary-safe function is essentially one that treats its input as a raw stream of data without any specific format. It should thus work with all 256 possible values that a character can take (assuming 8-bit characters).
二进制安全是一种主要用于字符串操作函数相关的计算机编程术语。一个二进制安全功能(函数),其本质上将操作输入作为原始的、无任何特殊格式意义的数据流。其在操作上应包含一个字符所能有的256种可能的值(假设为8为字符)。
何为特殊格式呢?Special characters:Most functions are not binary safe when using any special or markup characters, such as escape(转义) codes or those that expect null-terminated strings.
c中的strlen函数就不算是binary safe的,因为它依赖于特殊的字符’\0’来判断字符串是否结束。而在php中,strlen函数是binary safe的,因为它不会对任何字符(包括’\0’)进行特殊解释。
协议层的实现
文本协议
http 太普遍以至于我们都不感觉到它们是协议了
Redis 这个文本协议的实现性能仍然可以和二进制协议一样快。因为 Redis 协议将数据的长度放在数据正文之前, 所以程序无须像 JSON 那样, 为了寻找某个特殊字符而扫描整个 payload
自定义二进制
又包括两个分类:
- 传统的变长协议,比如bolt/dubbo。
- 基于帧的协议,比如http2
一般序列化时,必须同时传递序列化的输出目标和被序列化的对象。
vector<int> v = {1,2,3,4,5}; // vector容器
msgpack::sbuffer sbuf; // 输出缓冲区
msgpack::pack(sbuf, v); // 序列化
java/c/golang
以thrfit 为例
Facebook 在 2007 年发表的《Thrift: Scalable Cross-Language Services Implementation》技术论文,它的背后也就是这 Apache Thrift 这个开源项目。
CSV格式有两个缺点:
- 数据里面没有告诉我们数据类型是什么,我们只能根据字段的名称,以及查看少数几条数据来猜测。
- 很多数据用文本来保存有些浪费空间。比如“点击时间”,如果我们用一个整型数来存储,那么只需要占用 4 个 byte,但是用纯文本的话,需要 10 个 byte。
CSV 也好,JSON 也好,乃至 XML 也好,这些针对结构化数据进行编码主要想解决的问题是提升开发人员的效率,所以重视的是数据的“人类可读性”。因为在小数据量的情况下,程序员的开发效率是核心问题,多浪费一点存储空间算不了什么。但是在“大数据”的场景下,除了程序员的效率,存储数据本身的“效率”就变得非常重要了。
protobuf、thrift一个特点是数据有“模式”(schema),必须要先写一个 IDL(Interface Description Language)文件,在里面定义好数据结构,只有预先定义了的数据结构,才能被序列化和反序列化。这个特点既有好处也有坏处:一方面,接口就是清晰明确的规范文档,沟通交流简单无歧义;而另一方面,就是缺乏灵活性,改接口会导致一连串的操作,有点繁琐。
优化存储空间为目标的二进制序列化有没有什么解决办法呢?
- 通过 Schema 文件,定义出一个结构体,然后在里面列清楚字段的顺序、类型以及名称。
- 写一个程序,能够解析这个 Schema 文件,然后自动生成可以根据结构体的 Schema 进行序列化和反序列化的代码。这个序列化和反序列化的代码是非常简单的,只要按照 Schema 里面出现的字段顺序,一个个对着字节数组去读或者写数据就好了。
- 向前向后兼容的能力:Thrift 里的 TBinaryProtocol 的实现方式也很简单,那就是顺序写入数据的过程中,不仅会写入数据的值(field-value),还会写入数据的编号(field-id)和类型(field-type);读取的时候也一样。并且,在每一条记录的结束都会写下一个标志位。这样,在读取数据的时候,老版本的 v1 代码,看到自己没有见过的编号就可以跳过。新版本的 v2 代码,对于老数据里没有的字段,也就是读不到值而已,并不会出现不兼容的情况。在这个机制下,我们顺序排列的编号,就起到了版本的作用,而我们不需要再专门去进行数据版本的管理了。写下编号还带来了一个好处,就是我们不再需要确保每个字段都填上值了,可以废弃字段,并且这些废弃的字段不会占用存储空间。
- 通过编号和类型的确让我们有了向前向后兼容性,但是似乎又让我们的数据冗余变大了。不过,为了向前向后兼容性,编号和类型都是少不了的。那么,有没有什么别的办法能够进一步减少需要的存储空间呢?
- Delta Encoding,Thrift 的 IDL 都是从 1 开始编号的,而且通常两个字段的编号是连续的。所以这个协议在存储编号的时候,存储的不是编号的值,而是存储编号和上一个编号的差。比如,第一个编号是 1,第二个编号是 5,编号 2、3、4 没有值或者已经被我们废弃掉了,那么,第二个编号存储的直接就是 4。然后,我们再通过另外 4 个 bit 表示类型信息。那么通常来说,通过一个字节,我们就能把编号和类型表示出来。毕竟,我们的类型不到 16 种,4 个 bit 就够了,而通常两个字段之间的差,也不会超过 15,也就是 4 个 bit 能表示的最大整型数。不过,如果两个序号的差如果超过 15 怎么办呢?那么,我们就通过 1 个字节来表示类型,然后再用 1~5 个字节来表示两个连续编号之间的差,也就是下面我要介绍的 ZigZag+VQL 的编码方式。
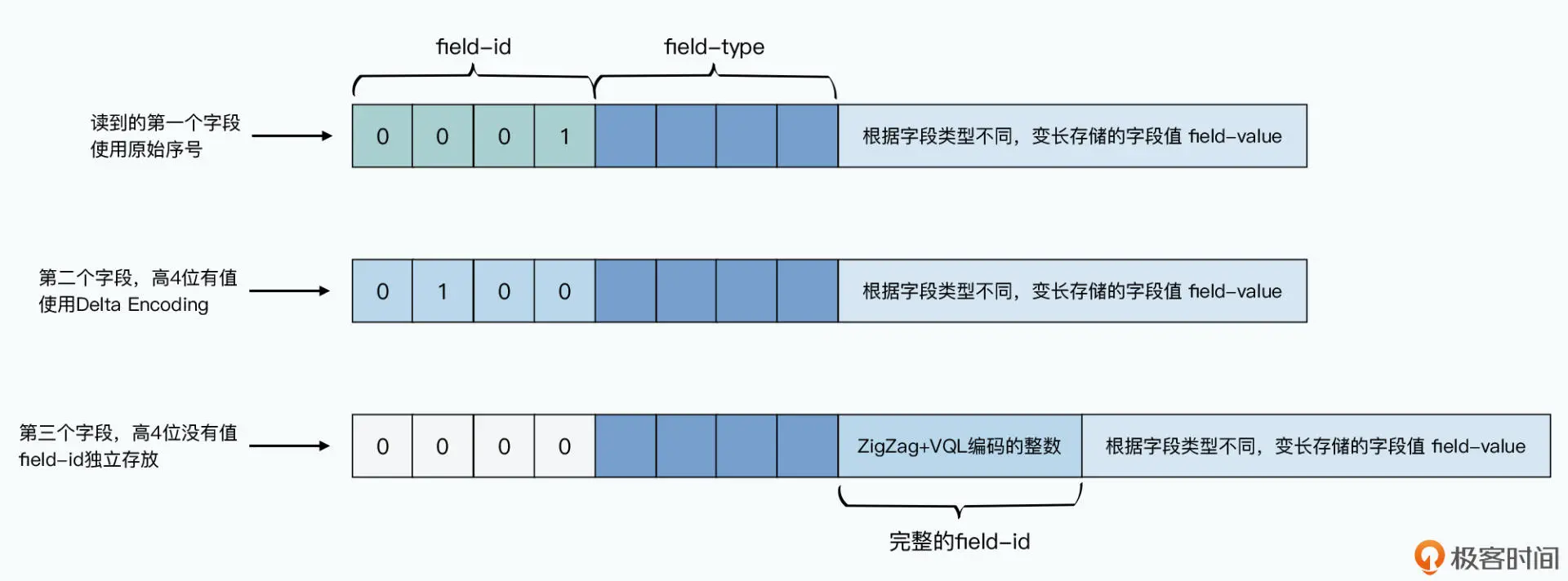
- ZigZag+VQL 的编码方式。
- Delta Encoding,Thrift 的 IDL 都是从 1 开始编号的,而且通常两个字段的编号是连续的。所以这个协议在存储编号的时候,存储的不是编号的值,而是存储编号和上一个编号的差。比如,第一个编号是 1,第二个编号是 5,编号 2、3、4 没有值或者已经被我们废弃掉了,那么,第二个编号存储的直接就是 4。然后,我们再通过另外 4 个 bit 表示类型信息。那么通常来说,通过一个字节,我们就能把编号和类型表示出来。毕竟,我们的类型不到 16 种,4 个 bit 就够了,而通常两个字段之间的差,也不会超过 15,也就是 4 个 bit 能表示的最大整型数。不过,如果两个序号的差如果超过 15 怎么办呢?那么,我们就通过 1 个字节来表示类型,然后再用 1~5 个字节来表示两个连续编号之间的差,也就是下面我要介绍的 ZigZag+VQL 的编码方式。
其它
思考:为什么不用http作为rpc协议?当然,springcloud就是用的http。 HTTP 协议的数据包大小相对请求数据本身要大很多;HTTP 协议属于无状态协议,客户端无法对请求和响应进行关联,每次请求都需要重新建立连接,响应完成后再关闭连接。
函数调用有 函数调用规范,规定了参数、返回值在函数栈中的位置,目的是比如方便 c 与汇编语言之间互操作。 rpc 远程函数调用 自然也需要一个调用规范,即IDL 。
留下评论