基础设施优化
简介
PS:cpu 要是能一直跑,利用率自然就高,但面临两个问题:io、线程间同步(毕竟总要沟通点信息)。为此整了很多花活儿。
2018 年 AWS ReInvent 大会上 AWS CTO Werner Volgels 提出的 21 世纪架构中 20 个有趣的事情中最后一个观点:All The Code You Ever Write Will Be Business Logic。开发者只应该关心业务逻辑,不用关心基础设施,不用关心开发工具链。
通用计算我们以云计算最核心的虚拟化为例,KVM 合入 Linux 内核是在 2007 年,OpenStack 第一个版本发布是在 2010 年,Open vSwitch 第一个版本是 2012 年合入 Linux 内核的,LSM 分布式存储的鼻祖 BigTable 论文是 2006 发表的。异构计算是从 2012 年 AlexNet 兴起,再到 2017 年 Transformer 论文发布进入快车道。这些云计算和 AI 领域的核心技术在行业内已经存在了很多年,短期内很难有革命性的创新出来,这意味着计算进入稳态。在上层的算法和软件进入稳态之后,出于对效率的追求就会催生底层体系结构的创新,来提升计算性能降低计算成本。通用计算方面 2017 年AWS ReInvent 上发布了 Nitro System,用硬件卸载来降低虚拟化开销提升性能。异构计算方面 NIVIDIA 在 2017 年发布了 Volta 架构 GPU V100 支持第一代 Tensor Core,加速深度学习的矩阵运算。
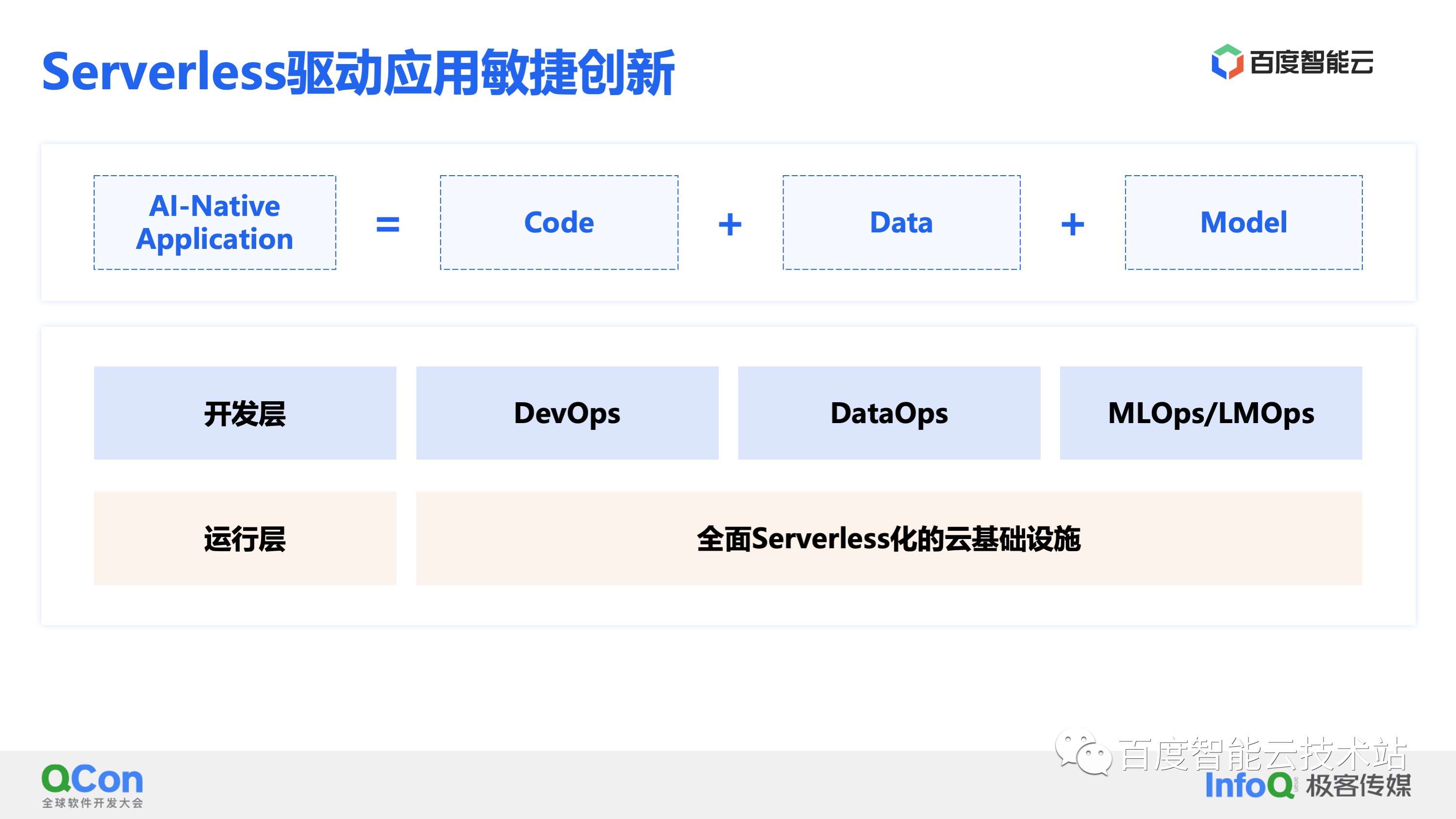
不同于传统应用,AI 原生应用是由代码、数据和模型组成的。
- 针对 Code,云原生时代已经有了成熟的 DevOps 解决方案,通过容器和微服务提升开发效率。
- 针对 Data,在传统 Hadoop 生态之外也涌现了一批优秀的开源数据管理软件来做 DataOps 提效。
- 针对 Model,深度学习兴起之后企业都会构建围绕 MLOps 的 AI 中台来加速模型生产效率。 这些工具链虽然能帮助开发者提升开发应用的效率,但是学习和维护这些工具链对开发者有一定成本,无形之中增加了开发者的心智负担。针对怎么降低开发者在基础设施管理、服务运维和服务扩展性等方面的心智负担这个问题,云计算给出了自己的答案。就是为这些开发工具链提供全面 Serverless 化的云基础设施作为运行层,让开发者把精力都放在代码开发、数据开发和模型开发上,支持应用敏捷创新。
通过对上面三个发展趋势的展开分析,我们分析出 AI 原生时代云计算的三个关键技术:
- 计算模式进入稳态后,通过软硬协同体系结构创新,实现算力的 Scale-up。
-
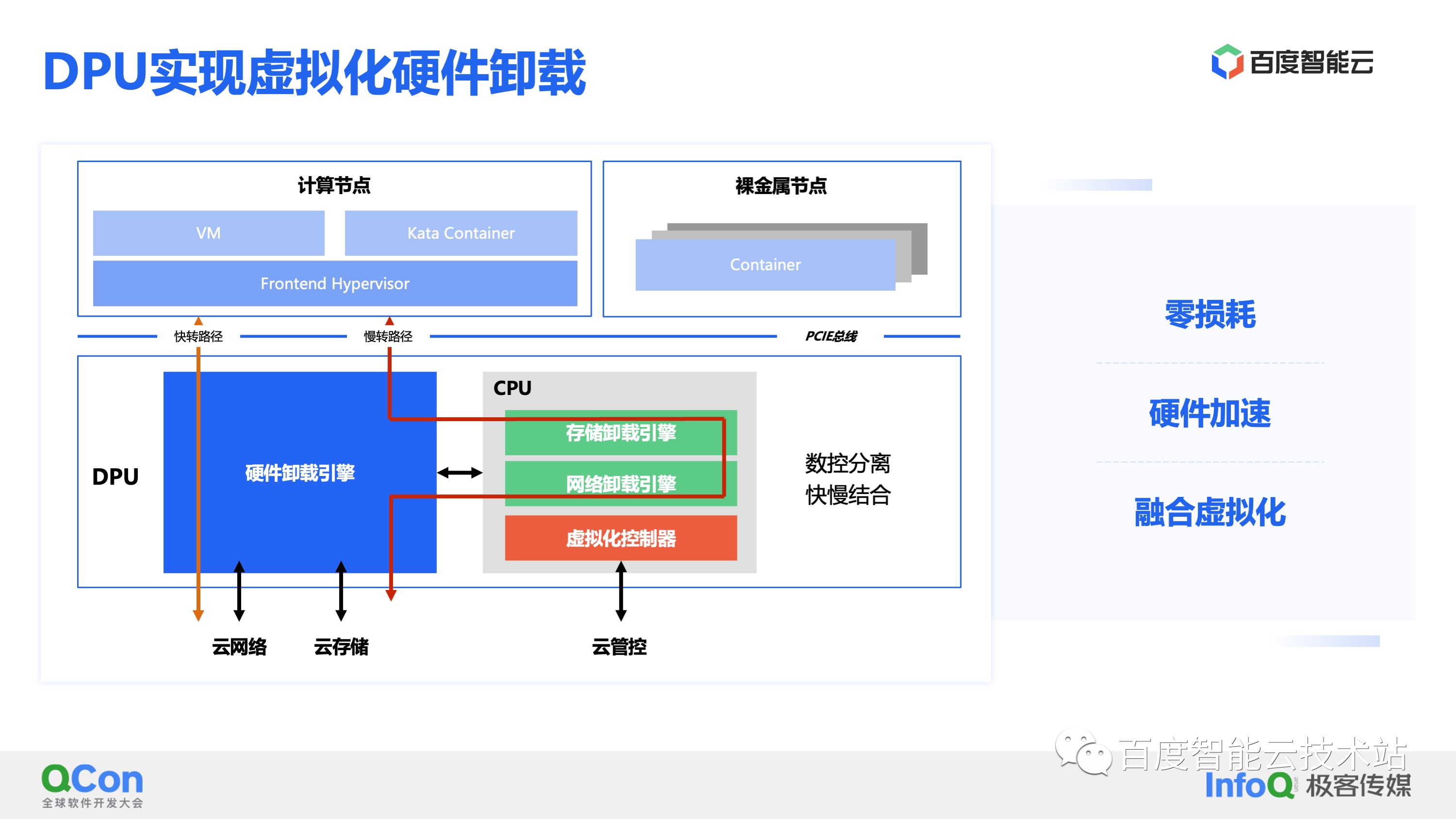
软件定义时代是内核实现虚拟化,性能较差,之后为了提升性能使用用户态 Pulling 提升性能。软件的极致优化下,虚拟化 I/O 性能依然不能匹配算力增长,而且付出了更多的 CPU 资源带来更多的成本。这些虚拟化税,一方面减少了可以售卖的资源量,另一方面也会影响调度的分配率,导致一些碎片。为了解决这些问题,云厂商开始使用 DPU 进行虚拟化的硬件卸载。DPU 对于服务器是一个 PCIe 的设备板卡,但是它上面五脏俱全可以认为是一台小型的服务器。在 DPU 上会有硬件实现的硬件卸载引擎,也有软件实现的管控和卸载引擎,通过软件和硬件协同实现快速的数据处理和转发。软硬协同的核心思想是:数控分离和快慢结合,慢速灵活的控制面和快速固定的数据面。通过 DPU 硬件卸载虚拟化,可以实现零损耗,也就消除了服务器上的虚拟化税。通过硬件加速虚拟化 I/O 性能,消除虚拟设备和物理设备之间的性能鸿沟。从管控层面也可以统一裸金属、虚拟机和容器的架构,方便统一资源调度。
-
- 通过高速互联通信,进行分布式计算实现算力的 Scale-out,满足算力爆炸式增长需求。
- 说到网络互联进行计算的 Scale,我们可以看到最近几年数据中心网络最大的一个变化就是 RDMA 开始普及,并且从商用 RMDA 开始走向自研 RDMA,并且将 RDMA 协议也进行 DPU 硬件卸载。
- 通过云产品全面 Serverless 化,实现极致弹性、开箱即用的体验,降低用户开发心智负担,满足应用敏捷创新。 Scale-up 和 Scale-out 实现了算力的弹性,弹性算力又是 Serverless 的基础,全面 Serverless 是云计算的终局,是云计算加速应用创新的根本。
零拷贝
把文件内容发送到网络。这个过程发生在用户空间,文件和网络socket属于硬件资源,读取磁盘或者操作网卡都由操作系统内核完成。在操作系统内部,整个过程为:
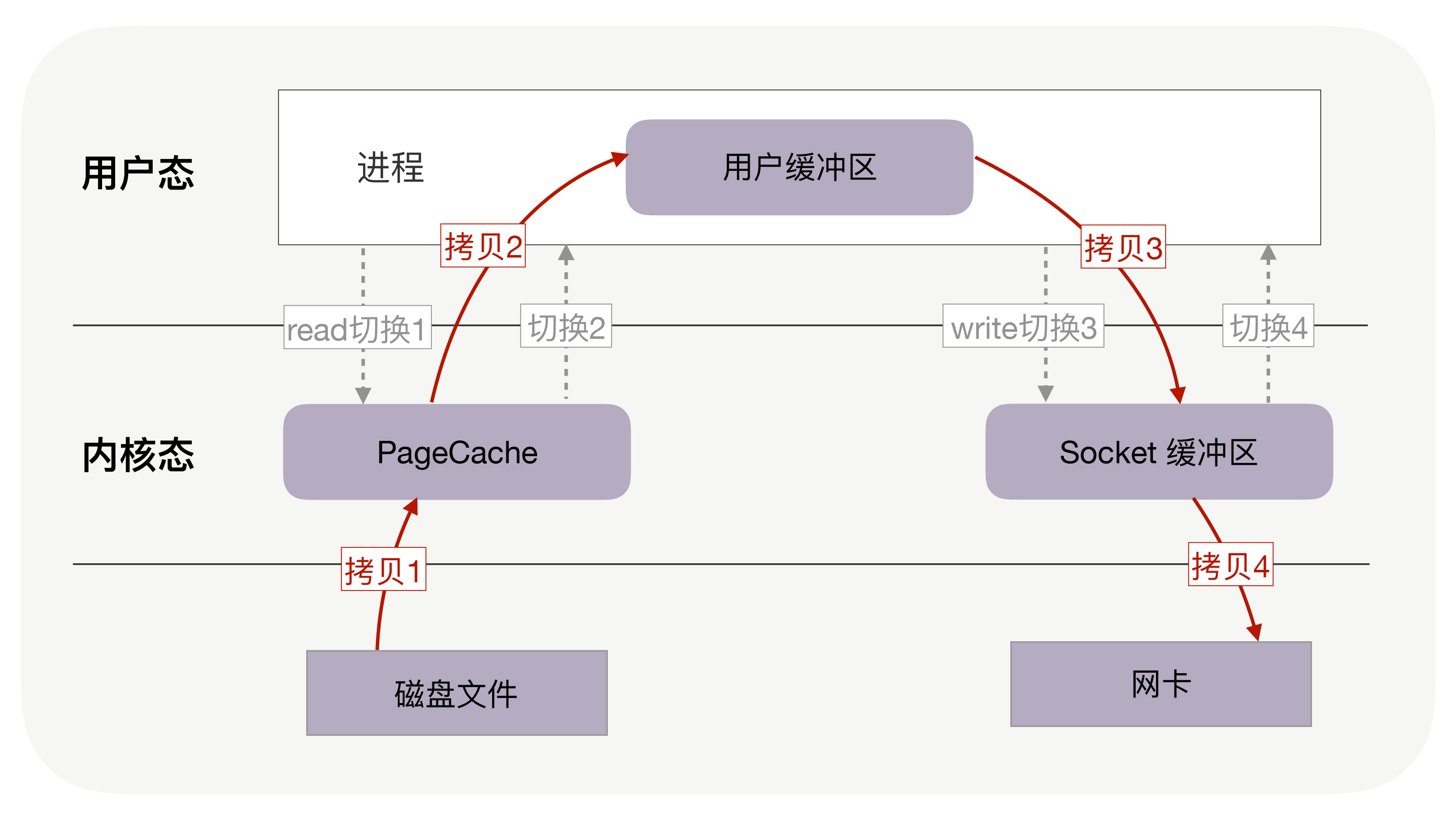
在Linux Kernal 2.2之后出现了一种叫做“零拷贝(zero-copy)”系统调用机制,就是跳过“用户缓冲区”的拷贝,建立一个磁盘空间和内存空间的直接映射,数据不再复制到“用户态缓冲区”,系统上下文切换减少2次,可以提升一倍性能。
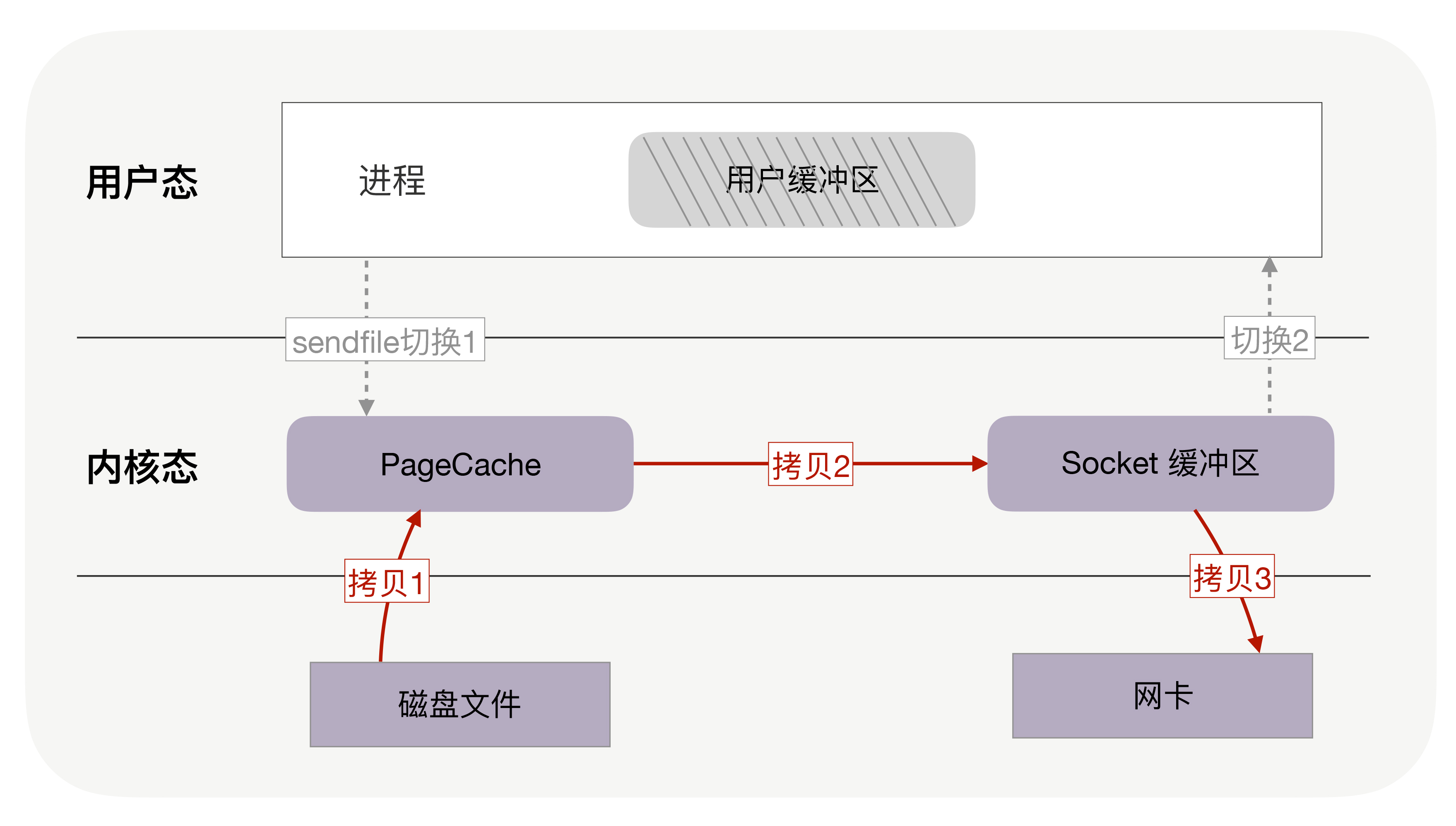
如果网卡支持 SG-DMA(The Scatter-Gather Direct Memory Access)技术,还可以再去除 Socket 缓冲区的拷贝,这样一共只有 2 次内存拷贝。
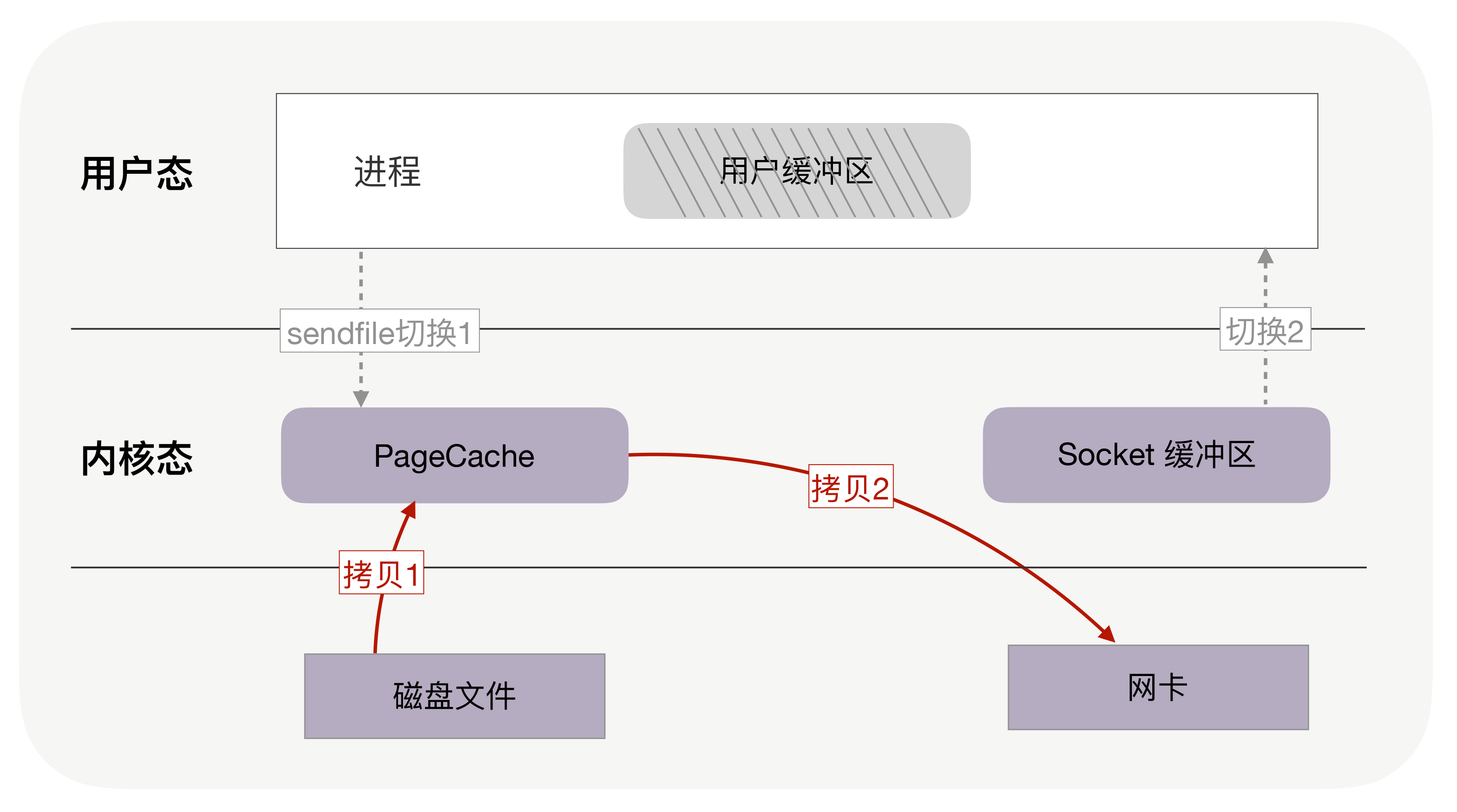
DMA 是一种外设绕开CPU独立直接访问内存的机制,零拷贝是一种绕开CPU 进行用户态和内核态之间数据拷贝的技术,包括mmap+write、sendfile、sendfile+DMA收集、splice等。kafka 的零拷贝即为磁盘通过sendfile实现DMA 拷贝Socket buffer,减少内核态到用户态的拷贝。PS:所谓零拷贝,活儿没有少,只是由DMA在干活儿,省了CPU
用户态与内核态切换有什么代价呢?
用户态的程序只能通过调用系统提供的API/系统调用来申请并使用资源,比如有个read 系统调用 用户态程序不能直接调用read,而是要systemcall read系统调用号。为了避免用户态程序绕过操作系统,直接执行对于硬件的控制和操作,操作系统利用CPU所提供的特权机制,封锁一些指令,并且将内存地址进行虚拟化(Ring 3无法执行一些指令,访问一些地址),使得存储有关键数据(比如IO映射)的部分物理内存无法从用户态进程进行访问。PS: 就好像看日志,你可以上物理机直接看,干其它事儿就只能给运维提交工单,而不能直接操作一样。
我们的应用程序运行在 Ring 3(我们通常叫用户态,cpu的状态),而操作系统内核运行在 Ring 0(我们通常叫内核态)。所以一次中断调用,不只是“函数调用”,更重要的是改变了执行权限,从用户态跃迁到了内核态。栈切换,内核态用的是内核栈,SS/ESP/EFLAGS/CS/EIP寄存器全部需要切换,L1/L2/L3缓存命中率出现下降。
Understanding User and Kernel Mode
- 在操作系统中,In Kernel mode, the executing code has complete and unrestricted access to the underlying hardware. It can execute any CPU instruction and reference any memory address. 而用户态可以访问的指令和地址空间是受限的
- 用户态和内核态的切换通常涉及到内存的复制,比如内核态read 得到的数据返回给 用户态,因为用户态访问不了内核态的read 返回数据。
- jvm 则再插一腿,因为jvm 数据不仅在用户态,jvm 还希望数据是由jvm heap管理,所以对于read 操作来讲,数据从内核态 ==> 用户态 ==> jvm heap 经历了两次复制,netty 中允许使用堆外内存(对于linux来说,jvm heap和堆外内存都在进程的堆内存之内) 减少一次复制
- linux 和jvm 都可以使用 mmap来减少用户态和内核态的内存复制,但一是应用场景有限,二是代码复杂度提升了好多。
留下评论