大模型推理服务框架
简介
在大模型之前的时代,模型结构不断发散,但推理功能的形态是稳定的,因此推理框架演化的结果是重Builder,轻Runtime。但大模型时代恰恰相反,模型结构相对稳定,推理功能却花样迭出,因此需要一个灵活的,预留足够空间的Runtime模块,Builder的各种优化反而变得简单。综合几点来看,大模型对于推理框架的设计哲学的改变是革命性的,已有的成熟的推理框架显得过于陈旧,难以完成这些变化,而新的推理框架又过于简单(以vllm为代表),24年的博弈会非常精彩。
- vLLM是一个开源的大模型推理加速框架,通过PagedAttention高效地管理attention中缓存的张量,实现了比HuggingFace Transformers高14-24倍的吞吐量,就像在操作系统中管理CPU虚拟内存一样
- NVIDIA FasterTransformer (FT) 是一个用于实现基于Transformer的神经网络推理的加速引擎。它包含Transformer块的高度优化版本的实现,其中包含编码器和解码器部分。使用此模块,您可以运行编码器-解码器架构模型(如:T5)、仅编码器架构模型(如:BERT)和仅解码器架构模型(如:GPT)的推理。FT框架是用C++/CUDA编写的,依赖于高度优化的 cuBLAS、cuBLASLt 和 cuSPARSELt 库,这使您可以在 GPU 上进行快速的 Transformer 推理。与 NVIDIA TensorRT 等其他编译器相比,FT 的最大特点是它支持以分布式方式进行 Transformer 大模型推理。在底层,节点间或节点内通信依赖于 MPI 、 NVIDIA NCCL、Gloo等。因此,使用FasterTransformer,您可以在多个 GPU 上以张量并行运行大型Transformer,以减少计算延迟。同时,TP 和 PP 可以结合在一起,在多 GPU 节点环境中运行具有数十亿、数万亿个参数的大型 Transformer 模型。
- DeepSpeed-MII 是 DeepSpeed 的一个新的开源 Python 库,旨在使模型不仅低延迟和低成本推理,而且还易于访问。
使用大模型时,我们在huggingface或modelscope 看到的代码类似下面,很明显不能直接向用户提供服务。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:...
一般有几个需求
- 统一api,这样切换模型时上游应用无感,最好是 OpenAI-compatible,其api 被主要上游框架(比如langchain)兼容
- 支持流式输出和普通输出
- 支持多实例,进而支持灰度发布等
- 支持通用的加速库,比如vllm等
- prompt拼写:llm本质都是语言模型,因此提供的只有语言模型调用方式,将所有请求简化为输入一个string,输出一个string的模式。然而,从语言模型到chat应用之间仍然有一个gap:输入prompt的拼写。text-in-text-out的设计可以简化引擎开发,但是prompt拼写的难题就被丢给了用户。提供chat能力的核心需求是如何将多轮对话按照模型训练时的格式渲染成模型的input id。从Language Model到Chat Application:对话接口的设计与实现
- function call 的处理。以ReAct模板的prompt为例,在模型吐字时留上一小块buffer不返回,如果没有
\nAction:那就继续返回;如果遇到这个string,则说明模型可能要输出function call,在此收集输出直到遇到eos或者作为stop word 的\nObservation:,然后再把buffer一次性parse成函数并返回。
设计思路
- 因为要支持不同的llm 库或加速库,比如Transformer、vllm等,且不同的llm在一些细节上有差异,因此推理侧必须有一个统一的LLM 抽象,在Fastchat里是XXModelWorker,在xinference 里是XXLLM
- 将python llm 库 api化,一个api 要有一个api handler 函数,一般抽象为一个对象 作为api handler的载体,这个对象持有上面的XxLLM 执行chat/generate 方法,有时候还要支持/封装分布式、异步等细节。在Fastchat里是ModelWorker,在xinference 里是WorkerActor
- 不同的llm 还有很多差别的(比如加载 load_model、运行chat/generate、模型配置转换),也有很多共性,所以模型设计的分层抽象很重要,Fastchat 的思路是 提供了一个ModelAdapter(主要差异化了加载) 和一个 generate_stream_gate 函数成员(差异化text生成),inference的思路是一个模型(比如chatglm、llama等)一个XXLLM
- 这里的模型配置转换说的是,比如一个chat message 包含role 和content 两个部分,role=system/user/assistant 各家各有差异,但因为对外提供的接口一般是openai 风格,所以有一个转换的过程。
- 除了文本生成模型,还经常需要部署embedding模型、rerank模型、图生图、文生图等(入参出参与LLM 肯定不一样了),Fastchat 的方式是 让ModelWorker支持除了generate_stream_xx 外的get_embeddings、get_rerank方法,inference的思路除了LLM之外还定义了 EmbeddingModel、RerankModel等。
由于像GPU 这样的加速器具有大量的并行计算单元,推理服务系统通常会对作业进行批处理,以提高硬件利用率和系统吞吐量。启用批处后,来自多个作业的输入会被合并在一起,并作为整体输入模型。但是此前推理服务系统主要针对确定性模型进行推理(LLM输出长度未知,使得一个推理任务总执行时间未知),它依赖于准确的执行时间分析来进行调度决策,而这对LLM并不适用。此外,批处理与单个作业执行相比,内存开销更高,因此LLM的尺寸限制了其推理的最大批处理数量。传统的作业调度将作业按照批次运行,直到一个批次中的所有作业完成,才进行下一次调度,这会造成提前完成的作业无法返回给客户端,而新到达的作业则必须等当前批次完成。因此提出 iteration-level 调度策略,在每次批次上只运行单个迭代,即每个作业仅生成一个token。每次迭代完成后,完成的作业可以离开批次,新到达的作业可以加入批次。
简单封装
ChatGLM-6B 在github 有一个仓库,一般包含
- 模型介绍 README.md
- 模型的对外接口 api.py/cli_demo.py/web_demo.py。 自己使用 fastapi 基于python库直接对外提供RESTful APIs.
以api.py 为例
from fastapi import FastAPI, Request
from transformers import AutoTokenizer, AutoModel
import uvicorn, json, datetime
import torch
app = FastAPI()
@app.post("/")
async def create_item(request: Request):
global model, tokenizer
json_post_raw = await request.json()
json_post = json.dumps(json_post_raw)
json_post_list = json.loads(json_post)
prompt = json_post_list.get('prompt')
history = json_post_list.get('history')
max_length = json_post_list.get('max_length')
top_p = json_post_list.get('top_p')
temperature = json_post_list.get('temperature')
response, history = model.chat(tokenizer,prompt, history=history,
max_length=max_length if max_length else 2048,
top_p=top_p if top_p else 0.7,
temperature=temperature if temperature else 0.95)
now = datetime.datetime.now()
time = now.strftime("%Y-%m-%d %H:%M:%S")
answer = {"response": response,"history": history,"status": 200,"time": time}
log = "[" + time + "] " + '", prompt:"' + prompt + '", response:"' + repr(response) + '"'
print(log)
torch_gc()
return answer
if __name__ == '__main__':
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model.eval()
uvicorn.run(app, host='0.0.0.0', port=8000, workers=1)
FastChat
如何理解FastChat 都干了什么?本质是对下面的 原始的大模型推理代码进行抽象(模型加载、模型推理=tokenizer+model)和封装,对外提供rest api。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:...
一文入门最热的LLM应用开发框架LangChainFastChat功能覆盖训练,推理,评估的全过程。设计目标非常明确,就是在性能、功能及风格上全面对标OpenAI ChatGPT,以成为ChatGPT的开源平替。在生态集成上,由于它完全兼容OpenAI的风格,基于ChatGPT的langchain应用,可以无缝地使用FastChat替代。 推理侧类似工具Xinference/OpenLLM/RayLLM
FastChat是一个用于训练、服务和评估基于聊天机器人的大型语言模型的开放平台。The core features include:
- The training and evaluation code for state-of-the-art models (e.g., Vicuna).
- A distributed multi-model serving system with web UI and OpenAI-compatible RESTful APIs.
# 命令行方式与llm 交互
python3 -m fastchat.serve.cli --model-path lmsys/vicuna-7b-v1.3
# webui方式与llm交互,此时需启动3个组件 web servers ==> controller ==> model workers
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.3
python3 -m fastchat.serve.gradio_web_server
# 提供OpenAI-compatible RESTful APIs openai_api_server ==> controller ==> model workers
python3 -m fastchat.serve.controller
python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.3
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
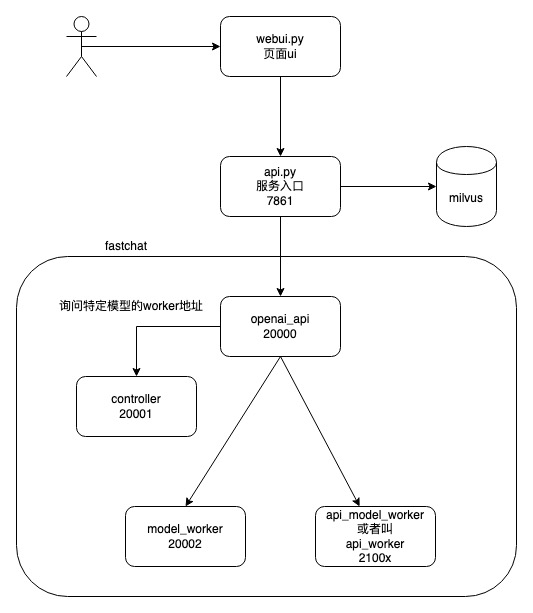
FastChat源码分析
fastchat
/fastchat
/model
/model_adapter.py # BaseModelAdapter ChatGLMAdapter
/model_chatglm.py # generate_stream_chatglm
/model_exllama.py
/model_registry.py
/protocol
/api_protocol.py
/openai_api_protocol.py
/serve
/multi_model_worker.py # 维护了一个 worker_map, key=model name,value = ModelWorker
/model_worker.py # app = FastAPI() ModelWorker
/controller.py. # app = FastAPI(). Controller
/openai_api_server.py # app = fastapi.FastAPI()
/train
使用ModelWorker 加载model 提供http 接口
# /fastchat/serve/model_worker.py
app = FastAPI()
@app.post("/worker_generate")
async def api_generate(request: Request):
params = await request.json()
await acquire_worker_semaphore()
output = worker.generate_gate(params)
release_worker_semaphore()
return JSONResponse(output)
if __name__ == "__main__":
...
worker = ModelWorker(...,args.model_path,)
uvicorn.run(app, host=args.host, port=args.port, log_level="info")
ModelWorker实现
class BaseModelWorker
init_heart_beat
# 将modelWorker id注册到controller,并保持心跳。均通过http接口
# 加载模型,调用模型(底层都是调用流式接口)
class ModelWorker(BaseModelWorker):
def __init__():
self.model, self.tokenizer = load_model(model_path, device=device,...)
# load_model 对应一个专门的 ModelAdapter 抽象,用来适配模型的加载
adapter = get_model_adapter(model_path)
model, tokenizer = adapter.load_model(model_path, kwargs)
generate_stream_gate(self, params)
generate_gate(self, params) # 根据参数返回输出,调用generate_stream_gate
for x in self.generate_stream_gate(params):
pass
return json.loads(x[:-1].decode())
从api handler 到请求被处理的过程: api => ModelWorker.generate_gate ==> ModelWorker.generate_stream_gate ==> ModelWorker.model.stream_generate,这里ModelWorker持有的model 是Transformer model 。
def generate_stream_gate
get_generate_stream_function(model: torch.nn.Module, model_path: str)
# 根据模型不同选择对应的函数
generate_stream_chatglm
prompt = params["prompt"]
inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
for total_ids in model.stream_generate(**inputs, **gen_kwargs):
response = tokenizer.decode(output_ids)
response = process_response(response)
请求参数转换
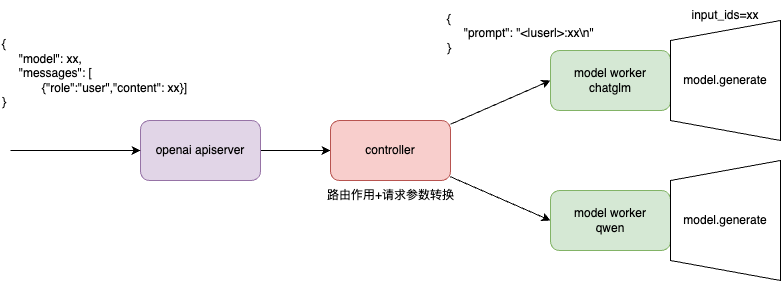
openai 参数转为 model_worker api 参数,最终转为 (Transformer库或类似)model.generate参数(比如input_ids、attention_mask等)。
- 用户输入(对于completion 接口是prompt,对于chat 接口是messages)被转为prompt,最终被model 对应的tokenizer 转为input_ids。
-
用户输入 在被转为prompt 过程对不同的模型有一些不同,因此要进行一些转换(其它的诸如stop token每个模型也有差异)。比如对于会话数据,转为chatglm3 的prompt 会类似于以下形式
<|user|> 今天北京的天气怎么样? <|assistant|> 好的,让我们来查看今天的天气当使用openai chat 接口时,传入的数据一般为
completion = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "user", "content": "今天北京的天气怎么样?"} ] )
FastChat, How to support a new model?
- FastChat uses the Conversation class to handle prompt templates and BaseModelAdapter class to handle model loading.
- Implement a conversation template for the new model at
fastchat/conversation.py. You can follow existing examples and use register_conv_template to add a new one. Please also add a link to the official reference code if possible. PS: 毕竟fastcaht 服务chat 场景嘛,对话请求传入的时候 一般是prompt = "\n###user:天为什么这么蓝?\n###",要把这个还原为history = [{"role": "user", "content": "天为什么这么蓝?"}],不同的模型 对role的称呼不同。 - Implement a model adapter for the new model at
fastchat/model/model_adapter.py. You can follow existing examples and use register_model_adapter to add a new one. PS:不同的模型加载时有一些特定的参数,比如 chatglm 的trust_remote_code 参数,model = AutoModel.from_pretrained(model_path, trust_remote_code=True, **from_pretrained_kwargs) - ModelWorker 主要逻辑是执行
generate_stream(model,tokenizer,params),很常规的input_ids = tokenizer(prompt); output_ids = model(input_ids,xx)。 如果模型的generate 逻辑有一些特别的处理,则需要自定义generate_stream_xx,并加入get_generate_stream_function 逻辑(根据模型名等 路由到不同的generate_stream_xx) - (Optional) add the model name to the “Supported models” section above and add more information in
fastchat/model/model_registry.py.
TensorRT-LLM
揭秘NVIDIA大模型推理框架:TensorRT-LLM 未读
LLM推理:GPU资源和推理框架选择TensorRT-LLM是Nvidia开源的LLM推理引擎,由开源项目FastTransformer演进而来,TensorRT-LLM需要结合Triton Inference Server才能构建完整的LLM推理服务。如果需要支持基于RESTFul API的流式输出(例如,类似OpenAI的LLM推理API接口),还需要进一步配合FastAPI才能支持流式输出。TensorRT-LLM目前还不是完全开源的,例如,Batch Manager 目前是不开源的。
大语言模型推理提速:TensorRT-LLM 高性能推理实践TensorRT-LLM 主要利用以下四项优化技术提升 LLM 模型推理效率。
- 量化
- In-Flight Batching
- Attention,Attention 机制按照演进顺序可以分为 MHA(Multi-head Attention)、MQA(Multi-query Attention)以及 GQA(Group-query Attention)机制。MQA 和 GQA 都是 MHA 的变种。MHA 是标准的多头注意力机制,每个 query 存储一份 KV,因此需要使用较多的显存。MQA 所有 query 共享一份 KV,推理时容易丢失一些细节信息。GQA 将 query 进行分组,组内共享一份 KV,可以有效避免 MHA 和 MQA 的问题。
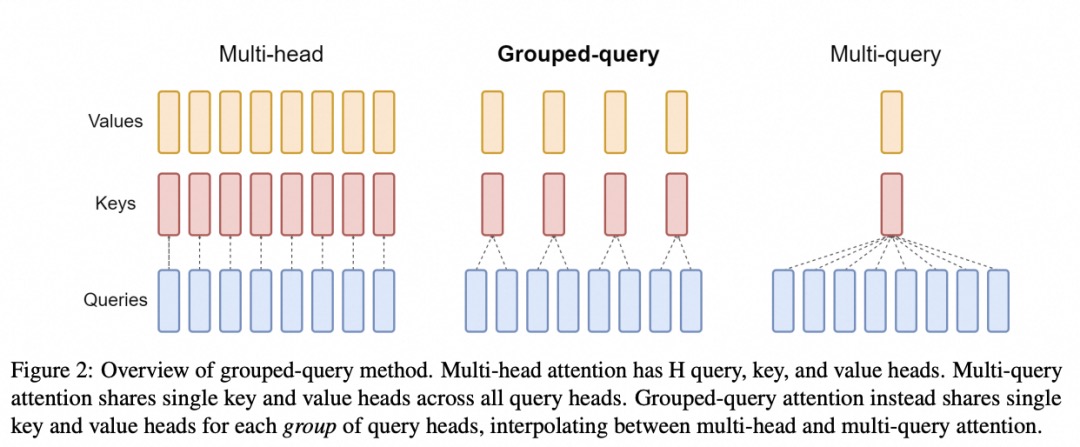
- Graph Rewriting,TensorRT-LLM提供了一组 Python API 用于定义 LLMs,并且使用最新的优化技术将 LLM 模型转换为 TensorRT Engines,在将 LLM 模型编译为 TensorRT Engines 时会对神经网络进行优化,推理时直接使用优化后的 TensorRT Engines。
留下评论