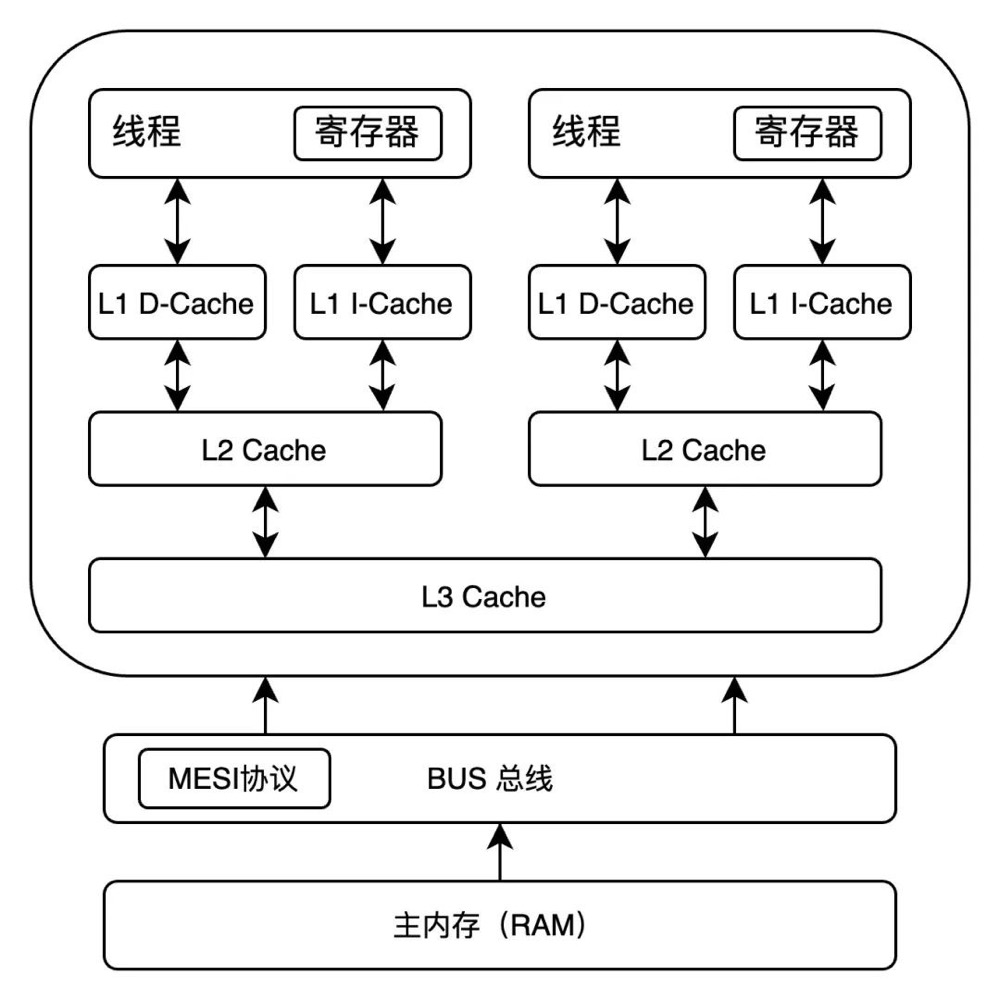
并发控制相关的硬件与内核支持
简介
多核的并行处理涉及到多核同时读写一个缓存行,所以很容易出现数据的脏读和脏写;单核的并发处理中因为任务内部的中间变量,所以有可能存在脏写的情况。
线程同步出现的根本原因是访问公共资源需要多个操作,而这多个操作的执行过程不具备原子性,被任务调度器分开了,而其他线程会破坏共享资源,所以需要在临界区做线程的同步。
有两个核心点,一个是原子操作,另一个则是中断;并发安全有以下几个办法(防中断,防其它执行体):
- 原子操作,x86中带lock 前缀的指令,lock 前缀表示锁定总线(中断是不能打断这个操作的),仅适用单体变量。PS: 可以认为lock 指令本身有锁总线的功能,然后因为锁总线的功能导致前后指令无法乱序,进而编译器和cpu 碰到lock 也不会乱序执行,进而用lock 锁总线之外附赠一个禁止乱序执行的效果(内存屏障)。java 或go 的 atomic 包会被编译带lock 的指令码。
- 关中断。当要操作的数据很多的情况下,用原子变量就不适合了。单 CPU同一时刻只有一条代码执行流,除了中断会中止当前代码执行流,转而运行另一条代码执行流(中断处理程序),再无其它代码执行流。这种情况下只要控制了中断,就能安全地操作全局数据。
- 自旋锁。多cpu时代,大家都自觉地点,操作数据之前先去检查下锁变量。首先读取锁变量,判断其值是否已经加锁,如果未加锁则执行加锁,然后返回,表示加锁成功;如果已经加锁了,就要返回第一步继续执行后续步骤,因而得名自旋锁。这个算法看似很好,但是想要正确执行它,就必须保证读取锁变量和判断并加锁的操作是原子执行的。否则,CPU0 在读取了锁变量之后,CPU1 读取锁变量判断未加锁执行加锁,然后 CPU0 也判断未加锁执行加锁,这时就会发现两个 CPU 都加锁成功,因此这个算法出错了。怎么解决这个问题呢?这就要找硬件要解决方案了,x86 CPU 给我们提供了一个原子交换指令,xchg,它可以让寄存器里的一个值跟内存空间中的一个值做交换。在使用自旋锁的时候我们仍然要注意中断。
- 信号量。如果长时间等待后才能获取数据,在这样的情况下,前面中断控制和自旋锁都不能很好地解决,于是我们开发了信号量。信号量由一套数据结构和函数组成,它能使获取数据的代码执行流进入睡眠,然后在相关条件满足时被唤醒,这样就能让 CPU 能有时间处理其它任务。所以信号量同时解决了三个问题:等待、互斥、唤醒。PS:通过等待队列来记录加锁失败的执行体,并后续通过一定的策略来选择唤醒,已经带入了调度的概念,这也是很多编程语言中信号量的实现方式。
硬件对并发控制的支持
- 可见性 ==> MESI 协议 ==> 总线嗅探和总线仲裁
- 有序性 ==> 禁止编译和处理器优化导致的重排序 ==> 内存屏障 ==> LOCK 指令
- 原子性 ==>
- 缓存加锁,缓存一致性协议(MESI)。强制当前处理器缓存行失效,并从内存读取其他处理器回写的数据。当有些无法被缓存或跨域多个缓存行的数据,依然需要使用总线锁。
- 总线加锁,通过 LOCK#信号锁住总线 BUS,使当前处理器独享内存空间,效率低
PS:这个思路方式很有意思。
原子操作
a++ 这行语句需要 3 条普通机器指令来完成变量 a 的自增:
- LOAD:将变量从内存加载到 CPU 寄存器;
- ADD:执行加法指令;
- STORE:将结果存储回原内存地址中。
这 3 条普通指令在执行过程中是可以被中断的。而原子操作的指令是不可中断的,原子操作由底层硬件直接提供支持,是一种硬件实现的指令级的“事务”。
// 常用的32位的原子变量类型
typedef struct {
int counter;
} atomic_t;
//原子读取变量中的值
static __always_inline int arch_atomic_read(const atomic_t *v){ return __READ_ONCE((v)->counter);}
//原子写入一个具体的值
static __always_inline void arch_atomic_set(atomic_t *v, int i){ __WRITE_ONCE(v->counter, i);}
//原子加上一个具体的值
static __always_inline void arch_atomic_add(int i, atomic_t *v){
asm volatile(LOCK_PREFIX "addl %1,%0" : "+m" (v->counter) : "ir" (i) : "memory");
}
//原子减去一个具体的值
static __always_inline void arch_atomic_sub(int i, atomic_t *v){
asm volatile(LOCK_PREFIX "subl %1,%0" : "+m" (v->counter) : "ir" (i) : "memory");
}
LOCK_PREFIX 是一个宏,根据需要展开成“lock;”或者空串。单核心 CPU 是不需要 lock 前缀的,只要在多核心 CPU 下才需要加上 lock 前缀。Linux 定义了 __READ_ONCE,__WRITE_ONCE 这两个宏,是对代码封装并利用 GCC 的特性对代码进行检查,把让错误显现在编译阶段。其中的“volatile int *”是为了提醒编译器:这是对内存地址读写,不要有优化动作,每次都必须强制写入内存或从内存读取。
深入剖析 split locksGCC 内置的__sync_fetch_and_add 函数、Kernel 中的 atomic_inc 函数、CAS 都是使用 lock 指令前缀实现的。LOCK指令前缀声明后,随同执行的指令会变为原子指令。原理就是在随同指令执行期间,锁住系统总线,禁止其他处理器进行内存操作,使其独占内存来实现原子操作。
现在处理器的核越来越多,如果每个核都频繁的产生 LOCK#信号,来独占内存总线,这样其余的核不能访问内存,导致性能会有很大的下降,该怎么办?INTEL 为了优化总线锁导致的性能问题,在 P6 后的处理器上,引入了缓存锁(cache locking)机制:通过缓存一致性协议保证多个 CPU 核访问跨 cache line 的内存地址的多次访问的原子性与一致性,而不需要锁内存总线。
缓存锁是依赖缓存一致性协议(MESI)来保证内存访问的原子性,因为缓存一致性协议会阻止被多个 CPU 缓存的内存地址被多个 CPU 同时修改。在代码指令前面声明了 LOCK 指令前缀,想要原子访问内存数据,如果内存数据可以被缓存在 CPU 的 cache 中,运行时通常不会在总线上产生 LOCK#信号,而是通过缓存一致性协议、总线仲裁机制与 cache 锁定来阻止两个或以上的 CPU 核,对同一块地址的并发访问。那么是不是所有的总线锁都可以被优化为缓存锁呢?答案是否定的,不能被优化的情况就是 split lock(产生条件:对数据执行原子访问;要访问的数据在 cache 中跨 cache line 存储)。因为原子操作是比较基础的操作,不能避免,如果数据只存储在一个 cache line 中,那就可以解决问题。
内存屏障
什么是内存屏障?它是一个CPU指令,用于控制处理器和内存系统中对内存操作的重新排序和优化(干预CPU内部执行的一种CPU API接口),在不同计算机架构下有不同的实现细节。
- 插入一个内存屏障,相当于告诉CPU和编译器先于这个命令的必须先执行,后于这个命令的必须后执行。确保指定的内存操作在屏障前后有一个明确的执行顺序。PS:CPU流水线 有异步的LoadBuffer,Store Buffer, Invalidate Queue,写屏障:阻塞直到把Store Buffer中的数据刷到Cache中;读屏障:阻塞直到Invalid Queue中的消息执行完毕。也就是有了禁止CPU 指令重排的效果。
- 强制更新一次不同CPU的缓存。例如,一个写屏障会把这个屏障前写入的数据刷新到缓存,这样任何试图读取该数据的线程将得到最新值。
为了 CPU 乱序的问题,从根本上来说只有通过插入所谓的 Memory Barrier 内存屏障指令来解决,这些指令会使得 CPU 保证特定的内存访问序及内存写入操作在多核间的可见性。然而由于不同处理器架构间的内存模型和具体 Memory Barrier 指令均不相同,需要在什么位置添加哪条指令并不具有通用性,因此 C++ 11 在此基础上做了一层抽象,引入了 atomic 类型及 Memory Order 的概念,有助于写出更通用的代码。从本质上看就是靠编译器来根据代码中指定的高层次 Memory Order 来自动选择是否需要插入特定处理器架构上低层次的内存屏障指令。
采用高速缓存 的写操作 有两种模式:
- 穿透(Write through)模式 ,每次写时,都直接将数据写回内存 中,效率相对较低;
- 回写(Write back)模式 ,写的时候先写回告诉缓存,然后由高速缓存的硬件 再周转复用缓冲线 (Cache Line)时自动将数据写回内存,或者由软件主动地“冲刷”有关的缓冲线(Cache Line)。PS: 有点redis+db访问呢的意思。
出于性能的考虑,系统往往采用的是模式2 来完成数据写入 。正是由于存在高速缓存 这一层,正是由于采用了Write back模式的数据写入,才导致在SMP架构 下,程序 中编排好的内存访问顺序 (指令序 : program ordering)是先写入x ,再写入y 。而实际上出现在该CPU外部,即系统总线上的次序 (处理器序 : processor ordering),可能是先写入y ,再写入x 。在SMP架构中,每个CPU 都只知道自己何时会改变内存 的内容,但是都不知道别的CPU 会在什么时候改变内存 的内容,也不知道自己本地的高速缓存 中的内容是否与内存 中的内容不一致 。反过来,每个CPU 都可能因为改变了内存内容 ,而使得其他CPU的高速缓存 变的不一致 了。可能影响到CPU间的同步与互斥,因此需要有一种手段,使得在某些操作之前 ,把这种“欠下”的内存操作全都最终地、物理地完成,这种手段就是内存屏障,其本质原理 就是对系统总线加锁 。
volatile意味着编译器应该防止对这些变量的访问被优化掉,即每次对 volatile 变量的读写都应该直接从内存中进行,而不能使用缓存的值。有 volatile 修饰的变量,赋值后多执行了一个lock addl $0x0,(%esp)操作,这个操作相当于一个内存屏障,指令addl $0x0,(%esp)显然是一个空操作,关键在于 lock 前缀,查询 IA32 手册,LOCK 前缀的指令在多核处理器会引发两件事:使得本 CPU 的 Cache 写入了内存,该写入动作也会引起别的 CPU invalidate 其 Cache。上述的操作是通过总线嗅探和总线仲裁来实现。而基于总线嗅探和总线仲裁,现代处理器逐渐形成了各种缓存一致性协议,例如 MESI 协议。所以通过这样一个空操作,可让前面 volatile 变量的修改对其他 CPU 立即可见。说白了,这是除cas 之外,又一个暴露在 java 层面的指令。
volatile 也是有成本的 剖析Disruptor:为什么会这么快?(二)神奇的缓存行填充
| 从CPU到 | 大约需要的 CPU 周期 | 大约需要的时间 |
|---|---|---|
| 主存 | 约60-80纳秒 | |
| QPI 总线传输(between sockets, not drawn) | 约20ns | |
| L3 cache | 约40-45 cycles | 约15ns |
| L2 cache | 约10 cycles | 约3ns |
| L1 cache | 约3-4 cycles | 约1ns |
| 寄存器 | 1 cycle |
操作系统对并发控制的支持
自旋锁
spinlock_t 以及操作函数spin_lock 和spin_unlock
// 最底层的自旋锁数据结构
typedef struct{
volatile unsigned long lock; // 真正的锁值变量,用volatile标识
}spinlock_t;
void spin_lock_bh(spinlock_t *lock) // 禁止CPU软中断,获取锁
void spin_unlock_bh(spinlock_t *lock)
int spin_trylock(spinlock_t *lock) // 尝试获取锁,失败返回0
void spin_lock_irq(spinlock_t *lock) // 禁止本地中断,获取锁
void spin_unlock_irq(spinlock_t *lock)spin_lock_irqsave(lock, flags) // 保存本地中断状态,禁止本地中断,获取锁
void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags)int spin_is_locked(spinlock_t *lock) //判断锁的状态
// 释放自旋锁
static inline void spin_unlock(spinlock_t*lock){
__asm__ __volatile__( spin_unlock_string );
}
spinlock的本质是一个广播,实现的方式就很多。现代操作系统应该用的都是标志位法,具体的实现方法是:
- 先给每个核准备一个spinlock的状态标志;
- 当有代码要持有spinlock的时候,先关闭当前核心的中断;
- 通过原子操作把当前核心的spinlock标志置为已经持有的状态;
- 如果持有当前核心的spinlock失败,那么进入忙等的状态,直到持有当前核心的spinlock状态为止;
- 继续尝试持有其它核心的spinlock状态,如果发现其它核心的spinlock是占用的状态,那么不同操作系统的设计思路可能就是不一样了:
- 有的操作系统采用的是回退法,所有核心都放弃自己的spinlock状态,然后随机延迟几个tick,再重新尝试持有;
- 有的操作系统采用的是不同核心不同优先级的做法,按照CPU核心的编号去排序分配优先级;
- 有的操作系统会根据持有的spinlock的核心数量做比较,数量多的优先级更高,如果两个spinlock持有的核心一样多,那么随机选一个;
- 经过5的抢占操作,终于有一个核心的spinlock函数拿到了所有的核心的spinlock状态,此时其它核心都会进入等待的状态,总之,是不能继续跑了,至少不能继续抢占某个内存区域了。然后持有spinlock的核心就可以放心的修改mutex的占用状态,广播到所有核心,完成锁的状态的更新。
spinlock能实现多核的锁定,spinlock锁定多核以后,再操作锁的占用标志就是被保护的状态,操作完以后还要用memory barriar(内存屏障)保证锁的状态可以同步到所有的核心。
互斥锁
mutex的本质就是一个内存标志,这个标志可以是一个flag(占用标志),也可以是一个指针,指向一个持有者的线程ID,也可以是两个都有,以及一个等待(阻塞)队列,以及若干其它信息等。当这个flag被标记成被占用的时候,或者持有者指针不为空的时候,那么它就不能被被别的任务(线程)访问。只有等到这个mutex变得空闲的时候,操作系统会把等待队列里的第一任务(线程)取出来,然后调度执行,如果当前CPU很忙,那么就把取出的这个任务(线程)标记为就绪(READY)状态,后续如果CPU空闲了,就会被调度。
// 结构
struct mutex {
atomic_long_t owner; // 指向占用锁的线程
spinlock_t wait_lock;
#ifdef CONFIG_MUTEX_SPIN_ON_OWNER
struct optimistic_spin_queue osq; /* Spinner MCS lock */
#endif
struct list_head wait_list;
#ifdef CONFIG_DEBUG_MUTEXES
void *magic;
#endif
#ifdef CONFIG_DEBUG_LOCK_ALLOC
struct lockdep_map dep_map;
#endif
};
mutex_init(struct mutex* lock) // 定义互斥锁lock
mutex_lock(struct mutex *lock) // 获取
mutex_unlock(struct mutex *lock) // 释放
占用标志怎么实现的?
- 利用硬件的原子操作来实现,比如x86汇编里有CMPXCHG指令,就可以实现比较+原子交换,单核CPU就是用这个实现的。操作mutex之前,还会关中断,保证这个操作的唯一性。
- 多核怎么实现的?spinlock能实现多核的锁定,spinlock锁定多核以后,再操作锁的占用标志就是被保护的状态,操作完以后还要用memory barriar(内存屏障)保证锁的状态可以同步到所有的核心。
信号量
信号量使得 多个线程可以进入临界区,semaphore 及接口函数 down和up
struct semaphore{
raw_spinlock_t lock; // 保护信号量自身的自旋锁
unsigned int count; // 可以同时进入临界区的线程数量
struct list_head wait_list; // 挂载睡眠等待进程的链表
};
void down(struct semaphore *sem); //废弃
// 信号量的获取操作
int down_trylock(struct semaphore *sem);
int down_interruptible(struct semaphore *sem);
void up(struct semaphore *sem); // 信号量的释放操作
#define down_console_sem() do { \
down(&console_sem);\
} while (0)
static void __up_console_sem(unsigned long ip) {
up(&console_sem);
}
#define up_console_sem() __up_console_sem(_RET_IP_)
//加锁console
void console_lock(void)
{
might_sleep();
down_console_sem();//获取信号量console_sem
if (console_suspended)
return;
console_locked = 1;
console_may_schedule = 1;
}
//解锁console
void console_unlock(void)
{
static char ext_text[CONSOLE_EXT_LOG_MAX];
static char text[LOG_LINE_MAX + PREFIX_MAX];
//……删除了很多代码
up_console_sem();//释放信号量console_sem
raw_spin_lock(&logbuf_lock);
//……删除了很多代码
}
static inline int __sched __down_common(struct semaphore *sem, long state,long timeout)
{
struct semaphore_waiter waiter;
//把waiter加入sem->wait_list的头部
list_add_tail(&waiter.list, &sem->wait_list);
waiter.task = current;//current表示当前进程,即调用该函数的进程
waiter.up = false;
for (;;) {
if (signal_pending_state(state, current))
goto interrupted;
if (unlikely(timeout <= 0))
goto timed_out;
__set_current_state(state);//设置当前进程的状态,进程睡眠,即先前__down函数中传入的TASK_UNINTERRUPTIBLE:该状态是等待资源有效时唤醒(比如等待键盘输入、socket连接、信号(signal)等等),但不可以被中断唤醒
raw_spin_unlock_irq(&sem->lock);//释放在down函数中加的锁
timeout = schedule_timeout(timeout);//真正进入睡眠
raw_spin_lock_irq(&sem->lock);//进程下次运行会回到这里,所以要加锁
if (waiter.up)
return 0;
}
timed_out:
list_del(&waiter.list);
return -ETIME;
interrupted:
list_del(&waiter.list);
return -EINTR;
//为了简单起见处理进程信号(signal)和超时的逻辑代码我已经删除
}
//进入睡眠等待
static noinline void __sched __down(struct semaphore *sem)
{
__down_common(sem, TASK_UNINTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
//获取信号量
void down(struct semaphore *sem)
{
unsigned long flags;
//对信号量本身加锁并关中断,必须另一段代码也在操作该信号量
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(sem->count > 0))
sem->count--;//如果信号量值大于0,则对其减1
else
__down(sem);//否则让当前进程进入睡眠
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
//实际唤醒进程
static noinline void __sched __up(struct semaphore *sem)
{
struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list, struct semaphore_waiter, list);
//获取信号量等待链表中的第一个数据结构semaphore_waiter,它里面保存着睡眠进程的指针
list_del(&waiter->list);
waiter->up = true;
wake_up_process(waiter->task);//唤醒进程重新加入调度队列
}
//释放信号量
void up(struct semaphore *sem)
{
unsigned long flags;
//对信号量本身加锁并关中断,必须另一段代码也在操作该信号量
raw_spin_lock_irqsave(&sem->lock, flags);
if (likely(list_empty(&sem->wait_list)))
sem->count++;//如果信号量等待链表中为空,则对信号量值加1
else
__up(sem);//否则执行唤醒进程相关的操作
raw_spin_unlock_irqrestore(&sem->lock, flags);
}
为啥要有条件变量?互斥量是多线程间同时访问某一共享变量时,保证变量可被安全访问的手段。互斥只要求线程间访问某一资源时不存在同时处理或者交替处理的可能,而对线程本身的调度顺序没有限制,光靠mutex 无法实现wait condition 的效果。一般来说,条件变量衍生于锁,不同条件变量只是同一锁空间下的不同等待队列。Java 可以使用 synchronized 代码块保护特定代码路径,兼而可以在 synchronized 代码块中使用 Object wait 和 notify、notifyall 方法实现单一条件等待。如果需要多个条件,可以使用官方库提供的 Lock 实现和 Condition 实现。
条件变量自身并不包含条件。因为它通常和 if (或者while) 一起用,所以叫条件变量。条件变量,是为了解决等待需求。考虑实现生产者消费者队列,生产者和消费者各是一个线程。一个明显的依赖是,消费者线程依赖生产者线程 push 元素进队列。没有条件变量,你会怎么实现消费者呢?让消费者线程一直轮询“队列是否为空”(需要加 mutex),轮询时自旋或sleep。一般条件变量,锁和用户提供的判定条件这三个因素一起组合使用。PS:或者说没有一个抽象 直接表示“有则消费、无则等待”的效果,go 用channel可以做到,这也说明的channel 的抽象更高。
linux 线程
Understanding Linux Process States
| 进程的基本状态 | 运行 | 就绪 | 阻塞 | 退出 |
|---|---|---|---|---|
| Linux | TASK_RUNNING | TASK_INTERRUPTIBLE、TASK_UNINTERRUPTIBLE | TASK_STOPPED/TASK_TRACED、TASK_DEAD/EXIT_ZOMBIE | |
| java | RUNNABLE | BLOCKED、WAITING、TIMED_WAITING | TERMINATED |
操作系统提供的手段:
| 可以保护的内容 | 临界区描述 | 执行体竞争失败的后果 | |
|---|---|---|---|
| 硬件 | 一个内存的值 | 某时间只可以执行一条指令 | 没什么后果,继续执行 |
| os-自旋 | 变量/代码 | 多用于修改变量(毕竟lock指令太贵了) | 自旋 |
| os-信号量 | 变量/代码 | 代码段不可以同时执行 | 挂起(修改状态位) |
一个复杂项目由n行代码实现,一行代码由n多系统调用实现,一个系统调用由n多指令实现。那么从线程安全的角度看:锁住系统总线,某个时间只有一条指令执行 ==> 安全的修改一个变量 ==> 提供一个临界区。通过向上封装,临界区的粒度不断地扩大。
反过来说,无锁的代码仅仅是不需要显式的Mutex来完成,但是存在数据竞争(Data Races)的情况下也会涉及到同步(Synchronization)的问题。从某种意义上来讲,所谓的无锁,仅仅只是颗粒度特别小的“锁”罢了,从代码层面上逐渐降低级别到CPU的指令级别而已,总会在某个层级上付出等待的代价,除非逻辑上彼此完全无关
一个博客系列的整理
并发的核心:
- 一个是有序性,可见性,原子性. 从底层角度, 指令重排和内存屏障,CPU的内存模型的理解.
- 另一个是线程的管理, 阻塞, 唤醒, 相关的线程队列管理(内核空间或用户空间)
并发相关的知识栈
- 硬件只是、cpu cache等
- 指令重排序、内存屏障,cpu 内存模型等
- x86_64 相关的指令:lock、cas等
- linux 进程/线程的实现,提供的快速同步/互斥机制 futex(fast userspace muTeXes)
- 对于 C11 标准之前的 C 语言来说,想要构建多线程应用,只能依赖于所在平台上的专有接口,比如 Unix 与类 Unix 平台上广泛使用的 POSIX 模型(windows可能是别的)。自 C11 标准后,C 语言为我们专门提供了一套通用的并发编程接口,你可以通过标准库头文件 threads.h 与 stdatomic.h 来使用它们。
- java 内存模型,java 并发基础原语 在 jvm hotspot 上的实现
- java.util.concurrent
从中可以看到
- 内存模型,有cpu 层次的,java 层次的
- 并发原语,有cpu 层次的,linux 层次的,glibc/c++ 层次的,java 层次的。 首先cpu 层次根本没有 并发的概念,限定的是cpu 核心。glibc 限定的是pthread,java 限定的是Thread
所有这一切,讲的都是共享内存模式的并发。 所以 go 的协程让程序猿 少学多少东西。
其它
如何使用Redis实现分布式锁?我们通常说的线程调用加锁和释放锁的操作,到底是啥意思呢?实际上,一个线程调用加锁操作,其实就是检查锁变量值是否为 0。如果是 0,就把锁的变量值设置为 1,表示获取到锁,如果不是 0,就返回错误信息,表示加锁失败,已经有别的线程获取到锁了。而一个线程调用释放锁操作,其实就是将锁变量的值置为 0,以便其它线程可以来获取锁。
当你无法判断锁住的代码会执行多久时,应该首选互斥锁,互斥锁是一种独占锁。当 A 线程取到锁后,互斥锁将被 A 线程独自占有,当 A 没有释放这把锁时,其他线程的取锁代码都会被阻塞。阻塞是如何实现的呢?对于 99% 的线程级互斥锁而言,阻塞都是由操作系统内核实现的(比如 Linux 下它通常由内核提供的信号量实现)。当获取锁失败时,内核会将线程置为休眠状态,等到锁被释放后,内核会在合适的时机唤醒线程,而这个线程成功拿到锁后才能继续执行。互斥锁通过内核帮忙切换线程,简化了业务代码使用锁的难度。但是,线程获取锁失败时,增加了两次上下文切换的成本:从运行中切换为休眠,以及锁释放时从休眠状态切换为运行中。上下文切换耗时在几十纳秒到几微秒之间,或许这段时间比锁住的代码段执行时间还长。
互斥锁能够满足各类功能性要求,特别是被锁住的代码执行时间不可控时,它通过内核执行线程切换及时释放了资源,但它的性能消耗最大。如果你能确定被锁住的代码执行时间很短,就应该用自旋锁取代互斥锁。自旋锁比互斥锁快得多,因为它通过 CPU 提供的 CAS 函数(全称 Compare And Swap),在用户态代码中完成加锁与解锁操作。
多线程竞争锁的时候,加锁失败的线程会“忙等待”,直到它拿到锁。什么叫“忙等待”呢?它并不意味着一直执行 CAS 函数,生产级的自旋锁在“忙等待”时,会与 CPU 紧密配合 ,它通过 CPU 提供的 PAUSE 指令,减少循环等待时的耗电量;对于单核 CPU,忙等待并没有意义,此时它会主动把线程休眠。
并发控制的基本手段(没有好不好,只有合适不合适)
- 悲观锁:假定冲突的概率很高。
- 当你无法判断锁住的代码会执行多久时,互斥
- 如果你能确定被锁住的代码执行时间很短,自旋
- 如果能区分出读写操作
- 乐观锁,假定冲突的概率很低,先修改完共享资源,再验证这段时间内有没有发生冲突。如果没有其他线程在修改资源,那么操作完成。如果发现其他线程已经修改了这个资源,就放弃本次操作。至于放弃后如何重试,则与业务场景相关。无锁编程中,验证是否发生了冲突是关键。
留下评论