kaggle泰坦尼克问题实践
前言
pyhone 库安装命令:python3 -m pip install xx
kaggle泰坦尼克问题实践
基于上述文档,对机器学习过程做了进一步简化
- 只选取Sex、Age、Pclass 作为有效数据
- 空的数据全部 丢弃
- 将性别转换为0和1
- 使用
sklearn.preprocessing.StandardScaler将Age 转换为[-1,1] - 使用逻辑回归
sklearn.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
代码如下
import pandas as pd ## 数据分析
import numpy as np ## 科学计算
import sklearn.preprocessing as preprocessing
from sklearn import linear_model
data_train = pd.read_csv("train.csv")
# data_train.info()
## 性别、年龄、Pclass
data_train = data_train.filter(regex='Survived|Age|Sex|Pclass')
## 丢弃带有Nan 的行
data_train = data_train.dropna()
## 将性别数值化
data_train['Sex'] = pd.factorize(data_train['Sex'])[0].astype(np.uint16)
## 将年龄特征化到[-1,1]之内
scaler = preprocessing.StandardScaler()
age_scale_param = scaler.fit(data_train['Age'].values.reshape(-1, 1))
data_train['Age'] = scaler.fit_transform(data_train['Age'].values.reshape(-1, 1), age_scale_param)
print(data_train)
## 进行逻辑回归
train_np = data_train.values
# y即Survival结果
y = train_np[:, 0]
# X即特征属性值
X = train_np[:, 1:]
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(X, y)
## 对测试集进行和训练集一样的数据处理
data_test = pd.read_csv("test.csv")
data_t = data_test.filter(regex='PassengerId|Age|Sex|Pclass')
data_t = data_t.dropna()
data_t['Sex'] = pd.factorize(data_t['Sex'])[0].astype(np.uint16)
data_t['Age'] = scaler.fit_transform(data_t['Age'].values.reshape(-1, 1), age_scale_param)
## 预测下
test_np = data_t.values
X_t = test_np[:, 1:]
predictions = clf.predict(X_t)
## 处理结果
result = pd.DataFrame(
{'PassengerId': data_t['PassengerId'].values,
'Survived': predictions.astype(np.int32)
})
df = pd.merge(data_test, result, how='left', on='PassengerId')
r = df.filter(regex='PassengerId|Survived')
## NaN数据全部预测为Survived=0
r['Survived'] = r.Survived.fillna(0)
print(r)
r.to_csv("result.csv", index=False)
提交result.csv 到kaggle ,可能因为简化的太狠了,得了一个0分,尴尬
Matplotlib
十分钟入门Matplotlib Matplotlib 是 Python 的一个绘图库。它包含了大量的工具,你可以使用这些工具创建各种图形,包括简单的散点图,正弦曲线,甚至是三维图形。Python 科学计算社区经常使用它完成数据可视化的工作。
绘制数据集——包含xy数据
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(0, 2 * np.pi, 50)
plt.plot(x, np.sin(x)) # 如果没有第一个参数 x,图形的 x 坐标默认为数组的索引
plt.show() # 显示图形
上面的代码将画出一个简单的正弦曲线。np.linspace(0, 2 * np.pi, 50) 这段代码将会生成一个包含 50 个元素的数组,这 50 个元素均匀的分布在 [0, 2pi] 的区间上
绘制直方图
import matplotlib.pyplot as plt
import numpy as np
x = np.random.randn(1000)
plt.hist(x,50)
plt.show()
pandas
Pandas 有两种自己独有的基本数据结构:Series 和 DataFrame,其功能非常强大,可以从execl/csv 行列处理的视角来入手学习。
DataFrame
DataFrame 的需求来源于把数据看成矩阵和表。但是,矩阵中只包含一种数据类型,未免过于受限;同时,关系表要求数据必须要首先定义 schema。对于 DataFrame 来说,它的列类型可以在运行时推断,并不需要提前知晓,也不要求所有列都是一个类型。因此,DataFrame 可以理解成是关系系统、矩阵、甚至是电子表格程序(典型如 Excel)的合体。PS: spark 中也有dataframe的概念
DataFrame 是一个二维带标记的数据结构,每column 数据类型可以不同。假设有一个学生表,想知道是女生多还是男生多,用sql 来表示就是select sex,count(*) from student group by sex。那么给定一个数据集/csv文件等,如何用python 做类似的分析呢?pandas与sql 对比,持续更新…
Pandas DataFrame: A lightweight IntroPandas DataFrame is nothing but an in-memory representation of an excel sheet via Python programming language
创建DataFrame
my_dict = {
'name' : ["a", "b", "c", "d", "e","f", "g"],
'age' : [20,27, 35, 55, 18, 21, 35],
'designation': ["VP", "CEO", "CFO", "VP", "VP", "CEO", "MD"]
}
df = pd.DataFrame(my_dict)
my_list = [[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,14,15,16],
[17,18,19,20]]
df = pd.DataFrame(my_list)
DataFrame 操作
df.head() # Displays 1st Five Rows
df.head(2) # Displays 1st two Rows
df.tail() # Displays last Five Rows
df.tail(7) # Displays last 7 Rows
df.drop('age',1) # Delete Column "age" 1表示列0表示行
df.drop(3,0) # Delete the Row with Index "3"
df * df
df * 10
df + 100
df & 0
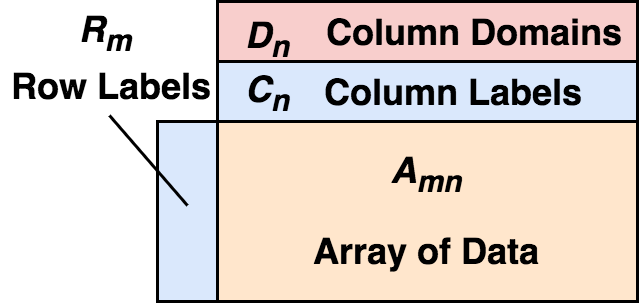
DataFrame 由二维混合类型的数组、行标签、列标签、以及类型(types 或者 domains)组成。在每列上,这个类型是可选的,可以在运行时推断。从行上看,可以把 DataFrame 看做行标签到行的映射,且行之间保证顺序;从列上看,可以看做列类型到列标签到列的映射,同样,列间同样保证顺序。行标签和列标签的存在,让选择数据时非常方便。
Series
Pandas Series: A Lightweight Intro
In layman terms, Pandas Series is nothing but a column in an excel sheet. 通俗的说, Series 代表excel的一列
Creating Pandas Series from python Dictionary
series_list = pd.Series([1,2,3,4,5,6])
series_index = pd.Series(
np.array([10,20,30,40,50,60]),
index=['a', 'b', 'c', 'd', 'e', 'f' ]
)
Getting a Series out of a Pandas DataFrame
my_dict = {
'name' : ["a", "b", "c", "d", "e"],
'age' : [10,20, 30, 40, 50],
'designation': ["CEO", "VP", "SVP", "AM", "DEV"]
}
df = pd.DataFrame( my_dict,
index = [
"First -> ",
"Second -> ",
"Third -> ",
"Fourth -> ",
"Fifth -> "])
series_name = df.name
series_age = df.age
series_age.mean() # 求平均年龄
sklearn
所谓逻辑回归,正向传播、反向传播、梯度下降等 体现在python上,就是两行代码:
clf = linear_model.LogisticRegression(C=1.0, penalty='l1', tol=1e-6)
clf.fit(xx)
predictions = clf.predict(xx)
前两个参数c 和 penalty 都和正则化相关,tol是停止求解的标准,float类型,默认为1e-4。就是求解到多少的时候,停止,认为已经求出最优解。
留下评论