go打包机制
前言
作为一种分布式计算的语言,Go没有提供用于发布Go软件包的中央服务器。相反,每个以域名开始的导入路径都被解释为一个URL(有一个隐含的前导https://),提供远程源代码的位置。例如,导入 “github.com/google/uuid”可以获取托管在相应的GitHub仓库的代码。仅仅下载软件包是不够的,我们还必须知道要使用哪些版本。当构建一个特定的程序时,Go通过选择最大版本来解决竞争的依赖module的所需版本:如果程序的一部分需要某个依赖module的1.2.0版本,而另一部分需要1.3.0版本,Go会选择1.3.0版本–也就是说,Go要求使用语义版本划分,其中1.3.0版本必须是1.2.0的直接替换(译注:1.3.0保持与1.2.0的兼容性)。另一方面,在这种情况下,即使1.4.0版本可用,Go也不会选择它,因为程序中没有任何部分明确要求使用该较新的版本。这个规则保持了构建的可重复性,并最大限度地减少了因意外破坏新版本所引入的变化而造成的潜在风险。
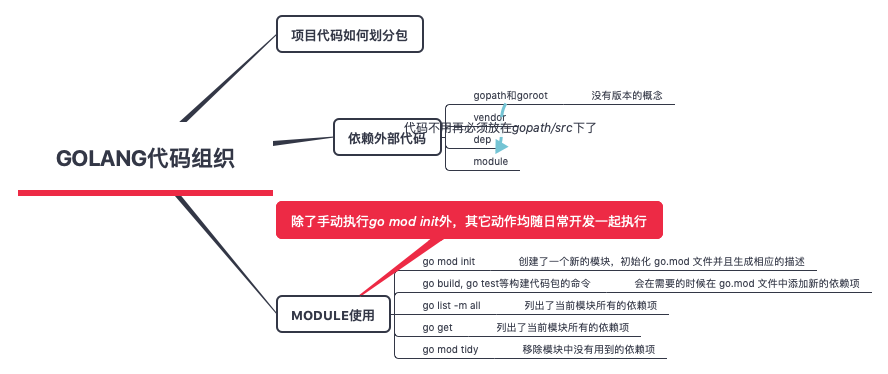
如何组织一个大项目的go 代码
宏观
$tree -F exe-layout
exe-layout
├── cmd/
│ ├── app1/
│ │ └── main.go
│ └── app2/
│ └── main.go
├── go.mod
├── go.sum
├── internal/
│ ├── pkga/
│ │ └── pkg_a.go
│ └── pkgb/
│ └── pkg_b.go
├── pkg1/
│ └── pkg1.go
├── pkg2/
│ └── pkg2.go
└── vendor/
- cmd 目录就是存放项目要编译构建的可执行文件对应的 main 包的源文件
- pkgN 目录,这是一个存放项目自身要使用、同样也是可执行文件对应 main 包所要依赖的库文件,同时这些目录下的包还可以被外部项目引用。有的项目偏好 只有一个pkg 目录。
- 存放仅项目内部引用的 Go 包,这些包无法被项目之外引用;
- 对于以生产可复用库为目的的 Go 项目,可以在 Go 可执行程序项目的基础上去掉 cmd 目录和 vendor 目录。
具体业务
-
可见性和代码划分
- c++ 在类上,即哪怕在同一个代码文件中,仍然无法访问一个类的私有方法
- java 是 类 + 包名
- go 在包上,从其他包中引入的常量、变量、函数、结构体以及接口,都需要加上包的前缀来进行引用。Golang 也可以 dot import 来去掉这个前缀。不幸的是,这个做法并不常规,并且不被建议。
-
假设有一个用户信息管理系统,直观感觉上的分包方式
- 单一package
- 按mvc划分,比如controller包、model包,缺点就是你使用 controller类时 就只得
controller.UserController,controller 重复了 - 按模块划分。比如
user/UserControler.go,user/User.go,缺点就是使用User类时只得user.User
-
按依赖划分,即根包下 定义接口文件
servier.go,包含User和UserController 接口定义,然后定义postgresql/UserService.go或者mysql/UserService.go
github 也有一些demo 项目layout golang-standards/project-layout
并发中处理的内容才是关键,新启一个线程或者协程才是万里长城的第一步,如果其中的业务逻辑有10个分支,还要多次访问数据库并调用远程服务,那无论用什么语言都白搭。所以在业务逻辑复杂的情况下,语言的差异并不会太明显,至少在Java和Go的对比下不明显 Organizing Go source code part 2 未读
import
import(
// 第一部分 标准库
// 第二部分 第三方依赖
// 第三部分 自己的依赖
)
包管理
Golang使用包(package)这种语法元素来组织源码,所有语法可见性均定义在package这个级别,与Java 、python等语言相比,这算不上什么创新,但与C传统的include相比,则是显得“先进”了许多。参见理解Golang包导入
| 编译 | install | |
|---|---|---|
| maven | mvn package/compile | mvn install |
| go | go build | go install |
Go 依赖包管理
| 版本 | ||
|---|---|---|
| vendor机制 | 1.5发布,1.6默认启用,1.7去掉环境变量设置默认开启 | |
| govendor | 1.5以后可用 | 基于 vendor 目录机制的包管理工具 |
| godep | 1.5之前可以用,1.6依赖vendor | |
| Go Modules | 1.11 发布,1.12 增强,1.13正式默认开启 |
最早的GOPATH
用代码的仓库地址作为依赖标识:对于go来说,其实并不在意你的代码是内部还是外部的,总之都在GOPATH里,任何import包的路径都是从GOPATH开始的;唯一的区别,就是内部依赖的包是开发者自己写的,外部依赖的包是go get下来的。Go 语言原生包管理的缺陷:
- 能拉取源码的平台很有限,绝大多数依赖的是 github.com
- 不能区分版本(对于依赖的同一个包只能从master分支上导入最新的提交,且不能导入包的指定的版本),以至于令开发者以最后一项包名作为版本划分。
- 依赖 列表/关系 无法持久化到本地,需要找出所有依赖包然后一个个 go get
- 只能依赖本地全局仓库(GOPATH/GOROOT),无法将库放置于局部仓库($PROJECT_HOME/vendor)
- 所有的项目都必须在GOPATH/src指向的目录下,或者必须更改GOPATH环境变量所指向的目录。
vendor
vendor属性就是让go编译时,优先从项目源码树根目录下的vendor目录查找代码(可以理解为切了一次GOPATH),如果vendor中有,则不再去GOPATH中去查找。
通过如上vendor解决了部分问题,然而又引起了新的问题:
- vendor目录中依赖包没有版本信息。这样依赖包脱离了版本管理,对于升级、问题追溯,会有点困难。
- 如何方便的得到本项目依赖了哪些包,并方便的将其拷贝到vendor目录下?依靠人工实在不现实。
godep/govendor
在支持vendor机制之后, gopher 们把注意力都集中在如何利用 vendor 解决包依赖问题,从手工添加依赖到 vendor、手工更新依赖,到一众包依赖管理工具的诞生,比如:govendor、glide 以及号称准官方工具的 dep,努力地尝试着按照当今主流思路解决着诸如 “钻石型依赖” 等难题。
godep go build main.go godep中的go命令,就是将原先的go命令加了一层壳,执行godep go的时候,会将当前项目的workspace目录加入GOPATH变量中。
godep save命令将会自动扫描当前目录所属包中import的所有外部依赖库(非系统库),并将所有的依赖库下来下来到当前工程中,产生文件 Godeps/Godeps.json 文件。把所有依赖包代码从GOPATH路径拷贝到Godeps目录下(vendor推出后也改用vendor了)
govendor init生成vendor/vendor.json
govendor add +external更新vendor/vendor.json,并拷贝GOPATH下的代码到vendor目录中。
vendor机制有一个问题:同样的库,同样的版本,就因为在不同的工程里用了,就要在vendor里单独搞一份,不浪费吗?所有这些基于vendor的包管理工具,都会有这个问题。
Go Modules 一统天下
一个 Go Module 是一个 Go 包的集合。module 是有版本的,所以 module 下的包也就有了版本属性。这个 module 与这些包会组成一个独立的版本单元,它们一起打版本、发布和分发。
- repo,仓库,用来管理modules
- modules是打tag的最小单位,也是go mod的最小单位
- packages是被引用的最小单位
一文读懂Go Modules原理 手把手教你如何创建及使用Go module Go Modules 依赖管理,这篇总结的挺全
版本
Go Modules 提供了统一的依赖包管理工具 go mod 基本思想semantic version(社区实际上做不到)
- MAJOR version when you make incompatible API changes(不兼容的修改)
- MINOR version when you add functionality in a backwards compatible manner(特性添加,版本兼容)
- PATCH version when you make backwards compatible bug fixes(bug修复,版本兼容)
依赖包统一收集在 $GOPATH/pkg/mod 中进行集中管理,有点mvn .m2 文件夹的意思。$GOPATH/pkg/mod 中的按版本管理
由 go mod tidy 下载的依赖 module 会被放置在本地的 module 缓存路径下,默认值为 $GOPATH/pkg/mod,Go 1.15 及以后版本可以通过 GOMODCACHE 环境变量,自定义本地 module 的缓存路径,有点maven .m2 文件夹的意思。go build 命令会读取 go.mod 中的依赖及版本信息,并在本地 module 缓存路径下找到对应版本的依赖 module,执行编译和链接。
几项创新
- 语义导入版本:如果同一个包的新旧版本是兼容的,那么它们的包导入路径应该是相同的。如果新旧两个包不兼容,那么我们就应该采用不同的导入路径。将包主版本号引入到包导入路径中,我们可以像下面这样导入 logrus v2.0.0 版本依赖包:
import "github.com/sirupsen/logrus/v2" - 最小版本选择原则:主流编程语言,以及 Go Module 出现之前的很多 Go 包依赖管理工具都会选择依赖项的“最新最大 (Latest Greatest) 版本”,Go 会在该项目依赖项的所有版本中,选出符合项目整体要求的“最小版本”。
如果这个仓库下的布局是这样的:
./srsm
├── go.mod # 类似于 maven pom.xml
├── go.sum
├── pkg1/
│ └── pkg1.go
└── pkg2/
└── pkg2.go
module 的使用者可以很轻松地确定 pkg1 和 pkg2 两个包的导入路径,一个是 github.com/bigwhite/srsm/pkg1,另一个则是 github.com/bigwhite/srsm/pkg2。如果 module 演进到了 v2.x.x 版本,那么以 pkg1 包为例,它的包的导入路径就变成了 github.com/bigwhite/srsm/v2/pkg1。
go.mod
$GOPATH/pkg/mod/k8s.io
api@v0.17.0
client-go@v0.17.0
kube-openapi@v0.0.0-20191107075043-30be4d16710a
go.mod
- module:代表go模块名,也即被其它模块引用的名称,位于文件第一行
- require:最小需求列表(依赖模块及其版本信息)
- replace:通过replace将一个模块的地址转换为其它地址(开发者github 上给自己的项目换个地址,删除某个版本等,常事),用于解决某些依赖模块地址发生改变的场景。同时import命令可以无需改变(无侵入)。
- exclude:明确排除一些依赖包中不想导入或者有问题的版本
replace
- replace 只在 main module 里面有效。什么叫 main module? 打个比方,项目 A 的 module 用 replace 替换了本地文件,那么当项目 B 引用项目 A 后,项目 A 的 replace 会失效,此时对 replace 而言,项目 A 就是 main module。因为对于包进行替换后,通常不能保证兼容性,对于一些使用了这个包的第三方module来说可能意味着潜在的缺陷
- replace 指定中需要替换的包及其版本号必须出现在 require 列表中才有效。replace命令只能管理顶层依赖(无法管理间接依赖)
- 假如存在
replace golang.org/x/text => github.com/golang/text,代码 import 的还是golang.org/x/text。
replace (
golang.org/x/crypto v0.0.0-20180820150726-614d502a4dac => github.com/golang/crypto v0.0.0-20180820150726-614d502a4dac
golang.org/x/net v0.0.0-20180821023952-922f4815f713 => github.com/golang/net v0.0.0-20180826012351-8a410e7b638d
golang.org/x/text v0.3.0 => github.com/golang/text v0.3.0
)
replace 的使用场景
- 替换无法下载的包,比如在国内访问golang.org/x的各个包都需要翻墙,你可以在go.mod中使用replace替换成github上对应的库。
- 替换本地自己的包
- 替换 fork 包,有时候我们依赖的第三方库可能有 bug,我们就可以 fork 一份他们的库,然后自己改下,然后通过 replace 将我们 fork 的替换成原来的
- 固化依赖包的版本,比如
a/b/c@v0.4.0使用了 go 1.17 的某些特性,但是当前项目环境是 go 1.16,则可以尝试 依赖a/b/c@v0.3.0,但考虑到 go get/mod tidy 等操作 可能会改动a/b/c的版本,可以在replace 部分明确指定依赖a/b/c@v0.3.0。- 很多时候报错 是
a/b/c但不知道是哪个包import 的,可以通过go mod graph | gmchart来查看,比如a/b/dimporta/b/c,降低a/b/d版本也可以起到类似效果。
- 很多时候报错 是
冲突解决(还不清晰)
如何欺骗 Go Mod ?
go mod 的智障版本选择
+incompatible :如果 major version 升级至 v2 时,如果该版本没有打算向前兼容,且不想把module path添加版本后缀,则可以在build tag时以 +incompatible 结尾即可,则别的工程引用示例为 require github.com/anqiansong/foo v2.0.0+incompatible
示例
// go.mod
module A1
go 1.14
require (
B1.2
C1.3
D1.4 // indirect
E1.3 // indirect
X v0.0.0-20120604004816-cd527374f1e5
)
- 依赖管理可以归纳为如下四个操作 ,尽量不要手动修改go.mod文件,通过go命令来操作go.mod文件
- 构建项目当前build list
go build - 升级所有依赖模块到它们的最新版本
go get -u - 升级某个依赖模块到指定版本
go get C@1.3 - 将某个依赖模块降级到指定版本
go get D@1.2 - 移除某个依赖
go mod tidy。 仅从源码中删除对依赖项的导入语句不够的
- 构建项目当前build list
- 通过go build编译项目时
- 如果在go.mod文件中指定了直接依赖模块版本,则根据最小版本选择算法会下载对应版本;
- 否则go build会默认自动下载直接依赖模块的最新semantic version
- 若没有semantic version则自动生成标签:
(v0.0.0)-(提交UTC时间戳)-(commit id前12位)作为版本标识/伪版本pseudo-version
- indirect,非本项目所直接依赖,但在本项目中指定依赖项的版本,可能原因
- 依赖项没有使用 go mod
- 不是所有依赖项都在go.mod 中。
- 手动为依赖的依赖指定较新的版本。
- incompatible 该依赖项未使用go mod 管理依赖
运行go build或是go mod tidy时golang会自动更新go.mod导致某些修改无效,所以一个包是顶层依赖还是间接依赖,取决于它在本module中是否被直接import,而不是在go.mod文件中是否包含// indirect注释。
Go Module 生成的伪版本主要有两种
- v0.0.0开头的:是因为依赖模块的代码仓库上不存在任何tag,所以
go get默认拉取的是主干分支最新一次commit对应版本的代码,格式为v0.0.0-主干分支最新一次commit的时间-commit哈希。 - 非 v0.0.0 开头的伪版本:这种一般是作为依赖包的项目本身代码仓库里有打标签发布版本,可是后续我们需要更新包,在测试阶段的时候在项目使用go get 模块名@CommitHash 获取还未正式发布的内容:
go get code.xxx.com/libs/xyz@6c1f3628ef7a,这个时候 Go Module 就会给我们在依赖已发布的版本上进行累加,然后生成伪版本。比如前面那个例子,模块的伪版本以v1.0.10开头就代表模块上一次发布的版本是v1.0.9,你打开模块所在的代码仓库看一下,一定会有一个v1.0.9的标签在那。
这里提醒一下大家,项目使用的内部依赖包,上线前一定要确定使用这些软件包在主干上打的标签版本,项目不要还依赖着模块的伪版本呢就上线了。
减少不必要的依赖
在我们使用的现有语言中,导入一个库可能导致编译器递归加载所有导入的库。在2007年的一次C++编译中,我们观察到编译器(在#include预处理后)在编译一组总共4.2MB的文件时,居然读取了超过8GB的数据,在一个已经很大的程序上,扩展系数几乎达到2000。如果为编译一个给定的源文件而读取的头文件的数量随着源代码树线性增长,那么整个源树的编译成本就会呈现指数级增长。为了弥补速度的减慢,我们开始研究一个新的、大规模并行和可缓存的编译系统,它最终成为开源的Bazel编译系统。但是并行性和缓存对于修复低效的系统只能起到这么大的作用了,我们相信语言本身可以做更多的事情来为编译大型程序提供帮助。
一个Go程序是由一个或多个可导入的包组成的,每个包包含一个或多个文件。一个包使用显式的import语句导入另一个包,这与许多语言一样。与大多数语言不同的是,Go安排每个导入语句只读取一个文件(译注:仅会读取依赖包对应的.a文件,以fmt为例,读取的是fmt.a)。例如,fmt包的公共API引用了io包的类型。
package fmt
import io
func Fprintf(w io.Writer,...){
...
}
在大多数语言中,编译器处理fmt包的导入时(import),也都会加载所有io的符号来满足fmt包的需要,这可能又需要加载额外的包来满足所有io包中符号的需要。依此类推,一条导入语句可能最终要加载并处理几十个甚至几百个包。
一个包导入fmt包并不能使io.Writer这个名字对当前这个包可用。如果main包想使用io.Writer这个类型,它必须自己使用import “io”语句导入io包。因此,一旦所有使用fmt限定名称的引用被从源文件中删除– 例如,如果上面例子中fmt.Fprintf的调用被删除,import “fmt”语句就可以安全地从源文件中删除,而无需做进一步分析。这个属性使得自动管理源代码中的导入语句成为可能。事实上,Go不允许未使用的导入,以避免将未使用的代码链接到程序中而产生的可执行文件膨胀。PS: Java 是允许存在这种无用的 import,依赖jar 版本冲突了编译时也不能及时发现,classloader 先加载哪个版本就靠碰运气了。
其它
go mod vendor 可以把依赖项 写入到当前项目vendor 目录中,这样搜索依赖的代码比较方便。PS:查问题时用
- 大多数成功的 Go 应用程序的结构并不能从一个项目复制/粘贴到另一个项目。
- 使用一个远比需要复杂的程序结构,实际上对项目的伤害比帮助更大。
- 对于一个几乎没有 Go 代码经验的人来说,发掘项目的理想结构并不是一个现实的目标。它需要实践、实验和重构来获得正确的结果。
留下评论