llm评测
简介(未完成)
揭秘大模型评测:如何用“说明书”式方法实现业务场景下的精准评估
大模型评测的目标是通过设计合理的测试任务和数据集来对大模型的能力进行全面、量化的评估。
- 性能测试通过压测实现。
- 基础模型的Benchmark(基准测试)
- 业务效果方面的评测。在基础模型发布时,模型厂商提供的测试报告无法覆盖用户实际业务场景。用户需要通过针对自己业务场景设计的评测来评估大模型的实际表现。
- 针对模型本身,
- 面向整个模型应用进行评测,覆盖RAG、MCP、工作流等构成的统一整体进行端到端的测试。
挑战
大模型评测相关工具平台随着各大模型平台厂商的持续投入以及开源社区的火爆,相关功能也在持续完善,目前已经不是主要的困难点。目前的主要困难更多聚焦在如何结合自己的业务场景开展大模型评测。
- 评测维度:评测维度如何设计才能更好的衡量大模型效果,并推动大模型优化?
- 评测集:如何设计评测集才能更好地仿真实际的线上场景。如何平衡不同场景的比例失衡的问题,确保不同场景的覆盖?
- 标注:标注人员质量参差不齐,不同人对标准的理解不一致。同一个人不同时间标注,也会导致结果不同,最终导致标注准确性稳定性差。除了标注效果外,人工标注非常耗时且需要投入额外的人工成本,导致无法开展大规模评测。
- 业务变化:随着技术方案和业务场景的变化,大模型本身也在持续迭代演进。不同大模型特点不同,评测标准和评测集的构成也各不相同。
评测流程
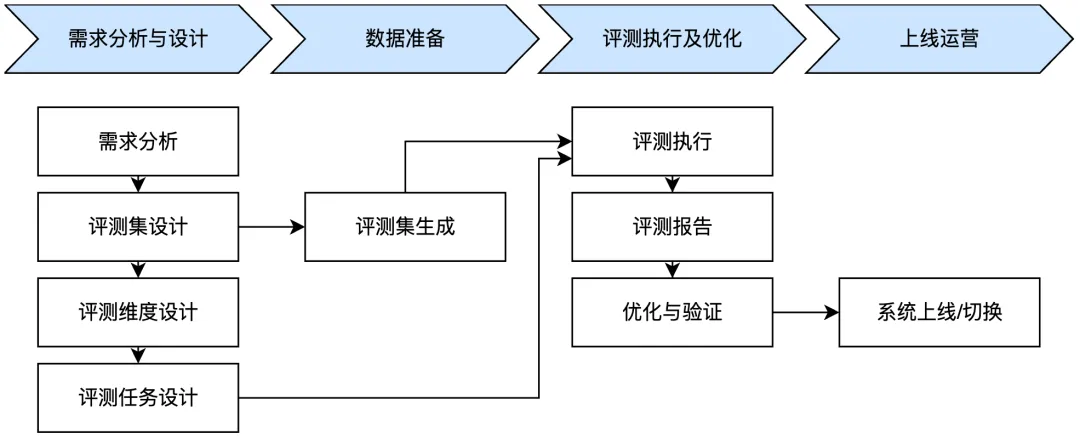
- 评测维度设计:举个例子,比如在“AI试衣”场景里,我们预先定义了“清晰度与分辨率”、“色彩准确性”、“人体与服饰的自然融合”、“姿势与角度匹配”、“光影与背景一致性”共5个评测维度。但是实际消费者使用时反馈部分场景的bad case在评测时给出好的评价。了解分析后发现消费者表示“我的体型穿这种衣服根本不是这个效果”。那基于消费者的这个反馈,我们就需要增加评测维度“人体比例与体型适配”。
- 模型效果量化。在完成分维度的设计后有一个最终的问题是,如何将各个维度的效果汇总成模型的整体效果的度量,从而评估模型是变好还是变坏,是否达到了上线等后续动作的标准。不同维度的优先级是不同的,安全类、客户投诉类一般都高于其他的业务指标。通过权重调整各个维度的重要性,最终通过加权后的得分来量化模型的最终效果,是一种相对比较简单的实现方案。对于总分,通过加权$ f(x) = \sum_{1 \leq i \leq n} a_i \bar{x}_i $ 计算总体效果。其中 $ n $ 表示场景数量,$ \bar{x}_i $ 表示某个场景的平均分,$ a_i $ 表示该场景样本的权重,可以设置为该场景样本的占比,也可以都是 1,或者业务人员根据业务需求设定。
与时俱进
讲一讲这两年大模型这整个领域到底发展了哪些方面更高的性能 ==> 更高质量输出/决策 ==> 使用工具 ==> 商业价值
- 在2023年初,LLM领域的发展遵循着一条清晰而有力的轨迹,规模决定能力,所以当年的爆火词就是Scaling Laws,更大的参数,更大的计算量,更大的数据规模。
- 随后到2024年,直到年底,一年多的时间该挖的数据、该买的算力、该请的人才都到位了,但还没出现GPT5,唯规模论的范式,迎来了深刻反思和系统性挑战。
- 对效率的迫切需求 ==> 架构改进:传统Transformer架构的注意力机制具有与序列长度成二次方关系的计算复杂度(O(L^2)复杂度),加之密集型(Dense)模型高昂的推理成本,共同构成了一个严重的性能瓶颈。这极大地限制了上下文长度的扩展和模型的实际部署,从而催生了对稀疏架构和新型注意力机制的迫切需求。
- 对推理的迫切需求 ==> 需要提升可解释性,找到新的增长范式:业界逐渐认识到,单纯的规模扩张并不能赋予模型强大的、多步骤的逻辑推理能力。模型在面对需要复杂规划和逻辑演绎的任务时,依然表现不佳。这一瓶颈促使研究方向发生根本性转变,从完全依赖预训练阶段的计算投入,转向在推理阶段分配额外计算资源,即思考(thinking)模型的诞生。在推理时进行thinking,也就是让模型在给出最终答案前进行一系列内部的、复杂的思考步骤,只有在底层架构已经足够高效的前提下才具有经济可行性,没有MoE或线性注意力等技术降低基础成本,为每一次查询增加数倍乃至数十倍的thinking计算量是无法想象的。
- 智能体的迫切需求 ==> 需要有商业价值,有用:随着模型推理能力的增强,下一个重点目标是让模型能够根据推理结果采取行动。这要求模型不仅能思考,还能与外部工具和环境进行交互,从而执行复杂任务,这标志着智能体AI(Agentic AI)时代的产生。因此,Agent能力的开发,成为应用推理能力的自然延伸。它是这条因果链的第三个环节,也是最高阶的体现。一个模型只有在能够高效地进行深度思考之后,才能可靠地决定何时、如何以及使用何种工具来完成任务。
- 2025年来推理Thinking走向台前。核心理念是,模型在生成最终答案之前,花费额外的计算资源来生成一段内部的思考链(CoT,chain of thought),从而在需要逻辑、数学和规划的复杂任务上实现性能的巨大飞跃。这标志着模型从静态的知识检索向动态的问题解决能力的演进。
- 强化学习(RL)的角色在这一时期发生了根本性的转变。它不再仅仅是用于对话对齐(如RLHF)的工具 ,而是成为了教授模型如何进行推理的核心方法,推理时间也成为了新的Scaling Laws。o系列及同类模型证明,对于一组固定的模型权重,通过增加推理期间使用的计算量,可以极大地提升模型在复杂任务上的表现。这一转变带来了深远的、高阶的影响。首先,它预示着对推理硬件的需求将大规模增长,而不仅仅是训练硬件。运行一次查询的成本不再是固定的,而是根据问题的难度动态变化,这为硬件市场带来了新的增长点。其次,它将研究重点从单纯地扩大预训练规模,转向开发更高效的推理算法(如在思考链中进行更优的搜索或规划)和更有效的RL技术来引导推理过程。
- 从理想到行动:智能体工具使用的黎明。一旦模型具备了推理和规划的能力,合乎逻辑的下一步就是让它能够通过与外部工具交互来执行计划。这正是AI智能体的定义。OpenAI的o3和o4-mini是首批被描述为具备“智能体工具使用”(agentic tool use)能力的模型。它们能够自主地决定何时以及如何组合使用网页搜索、Python代码分析和DALL-E图像生成等工具来解决一个复杂的用户请求。Claude 4的发布伴随着一套专为构建智能体而设计的新API功能:一个代码执行Sandbox、一个用于访问本地文件的Files API和一个MCP工具。这些功能,再结合独特的“计算机使用”(computer use)能力(即生成鼠标和键盘操作),使Claude成为构建能够与数字信息和图形用户界面(UI)进行交互的强大智能体的理想平台。
模型架构的演进直接导致了Benchmark评估的分化。传统的NLP基准测试,如MMLU(大规模多任务语言理解),正迅速变得饱和,对于区分前沿模型的能力越来越有限。与此同时,一类专注于复杂推理(如GPQA, AIME)和智能体执行(如SWE-bench, Terminal-bench)的新基准,已成为衡量SOTA的真正标准。这一转变的背后逻辑是:随着模型普遍能力的提升,它们在MMLU等知识密集型、选择题式的基准上的得分开始聚集在高端区间,难以拉开差距。2025年AI指数报告明确指出了MMLU、GSM8K和HumanEval等传统AI基准的饱和。作为回应,学术界和工业界将注意力转向了能够有效测试新一代推理能力的基准。AIME(高难度数学竞赛)、GPQA(需要研究生水平知识的问答)以及特别是SWE-bench(要求模型像软件工程师一样修复真实的GitHub问题),现在已成为Claude 4、o3和DeepSeek-R1等模型发布公告中反复引用的事实标准。
这一转变的更高阶影响是,SOTA的定义本身发生了变化。它不再是一个单一的、普适的头衔。一个模型可能在一个维度上是SOTA,但在另一个维度上则不是。例如,根据SWE-bench的领先表现,Anthropic的Claude 4被定位为SOTA的编码智能体。而OpenAI的o3/o4-mini则凭借在AIME上的卓越成绩,成为数学和推理领域的SOTA。
留下评论