LangChain源码学习
- 前言
- LangChain
- 干活的基础:OPENAI接口
- 包构成
- LLM模型层
- Prompt 和 OutputParser 规范化输入输出
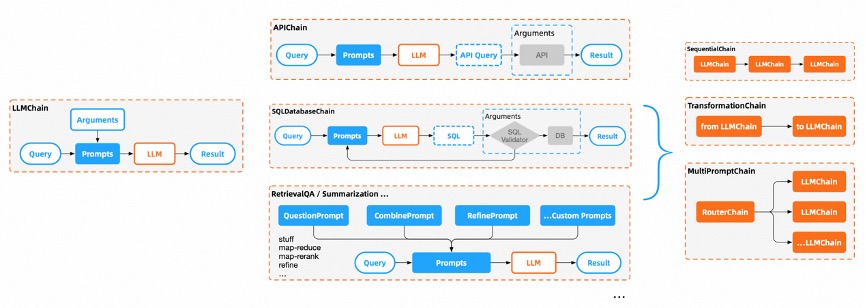
- Chain
- Memory
- 消除幻觉/Retriever
- Callback
- 一些理解
前言
LLM 不管是 GPT 还是 BERT,有且只有一个核心功能,就是预测你给定的语句的下一个词最有可能是什么(靠Prompt激发),除此之外的工作,比如解析 PDF、比如对话式搜索、甚至拿过来一个大任务分解、创建子任务,最终完成,都需要有一整套的工具来把核心功能包装,便于开发人员搭积木,这个工具就是 LangChain。LangChain底层就是Prompt、大模型API、以及三方应用API调用三个核心模块。对于LangChain底层不同的功能,都是需要依赖不同的prompt进行控制。PS:看LangChain的感受就是:遇事不决问LLM,基于自然语言对任务的描述进行模型控制,对于任务类型没有任何限制,只有说不出来,没有做不到的事情。这跟常规的工程项目 严丝合缝的逻辑 + ifelse控制流非常不一样。 比如外挂知识库,LLM 不只用于最后一步 对topk 匹配的chunk 做一下润色给出anwser,前期的文档切分、存储、history的存储、选用,用户query的意图识别、转换都可能用到LLM。
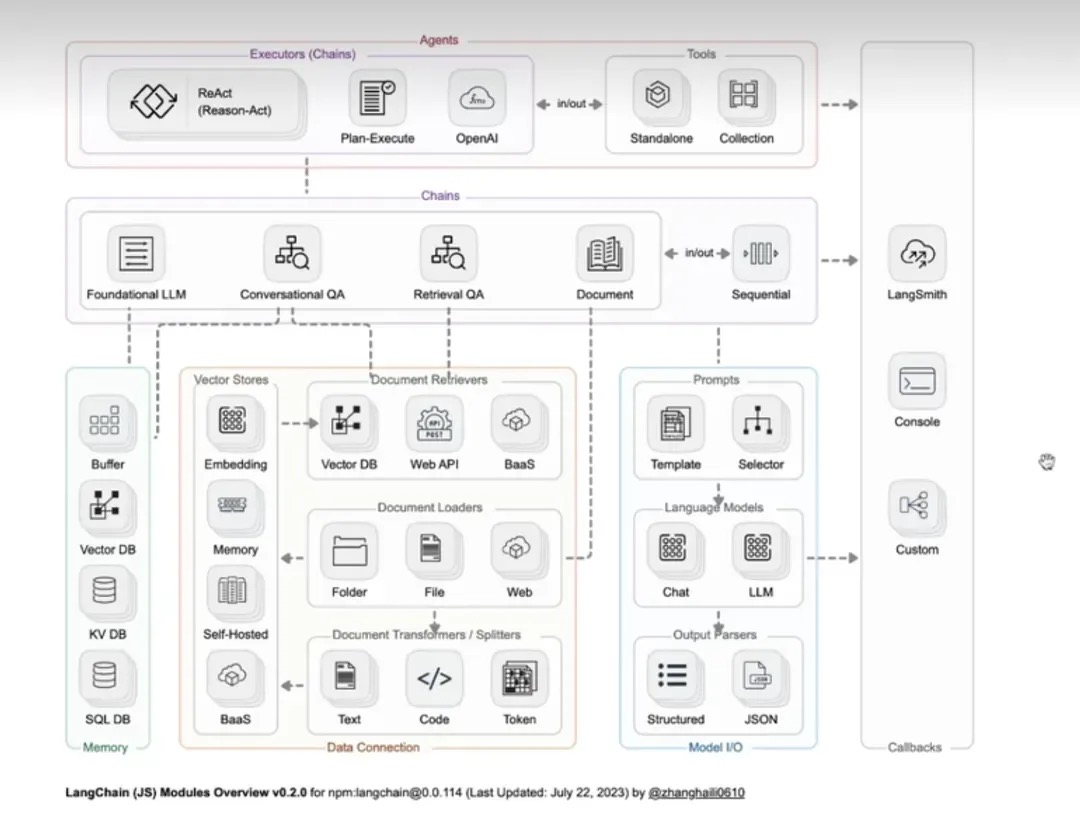
LangChain
LangChain is a framework for developing applications powered by language models. We believe that the most powerful and differentiated applications will not only call out to a language model, but will also be:
- Data-aware: connect a language model to other sources of data
- Agentic: allow a language model to interact with its environment
如果是一个简单的应用,比如写诗机器人,或者有 token 数量限制的总结器,开发者完全可以只依赖 Prompt。当一个应用稍微复杂点,单纯依赖 Prompting 已经不够了,这时候需要将 LLM 与其他信息源或者 LLM 给连接起来(PS:重点不是模型服务本身),比如调用搜索 API 或者是外部的数据库等。LangChain 的主要价值在于:
- 组件:用于处理语言模型的抽象,以及每个抽象的一系列实现。无论您是否使用 LangChain 框架的其他部分,组件都是模块化且易于使用的。PS: 既可以单独用,也可以组合用。
- 现成的链式组装:用于完成特定高级任务的结构化组件组装。一些例子包括:
- 将 LLM 与提示模板结合。
- 通过将第一个 LLM 的输出作为第二个 LLM 的输入,按顺序组合多个 LLM。
- 将 LLM 与外部数据结合,例如用于问答系统。
- 将 LLM 与长期记忆结合,例如用于聊天历史记录。
LangChain 中文入门教程基础功能:
- Model,主要涵盖大语言模型(LLM),为各种不同基础模型提供统一接口,然后我们可以自由的切换不同的模型。相关代码较少,大部分主要是调用外部资源,如 OPENAI 或者 Huggingface 等模型/API。
- 普通LLM:接收文本字符串作为输入,并返回文本字符串作为输出
- 聊天模型:将聊天消息列表作为输入,并返回一个聊天消息。支持流模式(就是一个字一个字的返回,类似打字效果)。
- Prompt,支持各种自定义模板
- 拥有大量的文档加载器,从指定源进行加载数据的,比如 Email、Markdown、PDF、Youtube …当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
- 对索引的支持。对用户私域文本、图片、PDF等各类文档进行存储和检索。为了索引,便不得不牵涉以下这些能力
- 在LangChain中,所有的数据源都可以认为是Document,任何的数据库、网络、内存等等都可以看成是一个Docstore。
- 文档分割器/Text Splitters,为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。比如我们将一份300页的 pdf 发给 openai api,让它进行总结,它肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
- 向量化,数据相关性搜索其实是向量运算。以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。
- 对接向量存储与搜索,向量化存储接口VectorStore, 比如 Chroma、Pinecone、Qdrand
- Chains,相当于 pipeline,包括一系列对各种组件的调用,每一个从Prompt到Answer的过程,都被标准化为不同类型的LLMChain。Chain可以相互嵌套并串行执行,通过这一层,让LLM的能力链接到各行各业。 内嵌了memory、cache、callback等组件。
- LLMChain
- 各种工具Chain
- LangChainHub
干活的基础:OPENAI接口
LangChain 本身不提供LLM,本质上就是对各种大模型提供的 API 的套壳,是为了方便我们使用这些 API,搭建起来的一些框架、模块和接口。因此,要了解 LangChain 的底层逻辑,需要了解大模型的 API 的基本设计思路。重点有两类模型:Chat Model 和 Text Model(当然,OpenAI 还提供 Image、Audio 和其它类型的模型),Chat 模型和 Text 模型的调用是完全一样的,只是输入(input/prompt)和输出(response)的数据格式有所不同
- Text Model,文本模型,一般对应base model。
- Chat Model,聊天模型,一般对应Instruct Model。用于产生人类和 AI 之间的对话,有两个专属于 Chat 模型的概念,一个是Message,一个是role。每个Message都有一个 role(可以是 system、user 或 assistant)和 content(消息的内容)。系统消息设定了对话的背景(比如你是一个很棒的智能助手),然后用户消息提出了具体请求。
- system:系统消息主要用于设定对话的背景或上下文。这可以帮助模型理解它在对话中的角色和任务。例如,你可以通过系统消息来设定一个场景,让模型知道它是在扮演一个医生、律师或者一个知识丰富的 AI 助手。系统消息通常在对话开始时给出。PS: prompt技巧之一就是设定角色
- user:用户消息是从用户或人类角色发出的。它们通常包含了用户想要模型回答或完成的请求。用户消息可以是一个问题、一段话,或者任何其他用户希望模型响应的内容。
- assistant:助手消息是模型的回复。例如,在你使用 API 发送多轮对话中新的对话请求时,可以通过助手消息提供先前对话的上下文。然而,请注意在对话的最后一条消息应始终为用户消息,因为模型总是要回应最后这条用户消息。
- observation: 比如chatglm3 为了强化Agent能力,新增了observation role 表示其内容是由tool返回的。
Completion response = openai.Completion.create(model="text-davinci-003",prompt="Say this is a test") (TEXT IN TEXT OUT)
{
"id":xx,
"object":"text_completion",
"created": xx,
"model": "text-davinci-003",
"choices": [
{
"text": "Yes, this is a test.",
"index": 0,
"logprobs": null,
"finish_reason": "stop",
}
}
Chat Model响应(MESSAGE IN MEESAGE OUT)
{
'id': 'chatcmpl-2nZI6v1cW9E3Jg4w2Xtoql0M3XHfH',
'object': 'chat.completion',
'created': 1677649420,
'model': 'gpt-4',
'usage': {'prompt_tokens': 56, 'completion_tokens': 31, 'total_tokens': 87},
'choices': [
{
'message': {
'role': 'assistant',
'content': '你的花店可以叫做"花香四溢"。'
},
'finish_reason': 'stop',
'index': 0
}
]
}
Completions API 主要用于补全问题,用户输入一段提示文字,模型按照文字的提示给出对应的输出。
| model | 必选参数 | 调用的Completions模型名称,如text-davinci-003、text-curie-001等,不同模型参数规模不 同;在大模型领域,(就OpenAI提供的A、B、C、D四大模型来看)参数规模越大、越新版本的模型效果更好(费用也更高) |
| prompt | 必选参数 | 提示词 |
| suffix | 可选参数 | 默认为空,具体指模型返回结果的后缀 |
| max_tokens | 可选参数 | 默认为16,代表返回结果的token数量 |
| temperature | 可选参数 | 取值范围为0—2,默认值为1。参数代表采样温度,数值越小,则模型会倾向于选择概率较高的词汇,生成的文本会更加保守;而当temperature值较高时,模型会更多地选择概率较低的词汇,生成的文本会更加多样 |
| top_p | 可选参数 | 取值范围为0—1,默认值为1,和temperature作用类似,用于控制输出文本的随机性,数值越趋近与1,输出文本随机性越强,越趋近于0文本随机性越弱;通常来说若要调节文本随机性,top_p和temperature两个参数选择一个进行调整即可;更推荐使用temperature参数进行文本随机性调整 |
| n | 可选参数 | 默认值为1,表示一个提示返回几个Completion |
| stream | 可选参数 | 默认值为False,表示回复响应的方式,当为False时,模型会等待返回结果全部生成后一次性返回全部结果,而为True时,则会逐个字进行返回 |
| logprobs | 可选参数 | 默认为null,该参数用于指定模型返回前N个概率最高的token及其对数概率。例如,如果logprobs设为10,那么对于生成的每个token,API会返回模型预测的前10个token及其对数概率; |
| echo | 可选参数 | 默认为False,该参数用于控制模型是否应该简单地复述用户的输入。如果设为True,模型的响应会尽可能地复述用户的输入 |
| stop | 可选参数 | 该参数接受一个或多个字符串,用于指定生成文本的停止信号。当模型生成的文本遇到这些字符串中的任何一个时,会立即停止生成。这可以用来控制模型的输出长度或格式; |
| presence_penalty | 可选参数 | 默认为0,取值范围为[—2,2],该参数用于调整模型生成新内容(例如新的概念或主题)的倾向性。较高的值会使模型更倾向于生成新内容,而较低的值则会使模型更倾向于坚持已有的内容,当返回结果篇幅较大并且存在前后主题重复时,可以提高该参数的取值; |
| frequency_penalty | 可选参数 | 默认为0,取值范围为[—2,2],该参数用于调整模型重复自身的倾向性。较高的值会使模型更倾向于避免重复,而较低的值则会使模型更可能重复自身;当返回结果篇幅较大并且存在前后语言重复时,可以提高该参数的取值; |
| best_of | 该参数用于控制模型的生成过程。它会让模型进行多次尝试(例如,生成5个不同的响应),然后选择这些响应中得分最高的一个; | |
| logit_bias | 该参数接受一个字典,用于调整特定token的概率。字典的键是token的ID,值是应用于该token的对数概率的偏置;在GPT中可以使用tokenizer tool查看文本Token的标记。一般不建议修改; | |
| user | 可选参数 | 使用用户的身份标记,可以通过人为设置标记,来注明当前使用者身份。 |
Chat模型升级的核心功能是对话, 它基于大量高质量对话文本进行微调,能够更好的理解用户对话意图,所以它能更顺利的完成与用户的对话(大语言模型本质上都是概率模型,根据前文提示进行补全是⼤语⾔模型的原始功能,而对话类的功能则是加⼊额外数据集之后训练的结果)。
ChatCompletion.create函数的详细参数和Completion.create函数相比发生了以下变化:
- 基于消息而不是原始文本。用messages参数代替了prompt参数,使之更适合能够执行对话类任务
- 新增functions和function_call参数,使之能够在函数内部调用其他工具的API
- 其他核心参数完全一致,例如temperature、top_p、max_tokens、n、presence_penalty等参数的解释和使用方法都完全一致,且这些参数具体的调整策略也完全一致
- 剔除了best_of参数,即Chat模型不再支持从多个答案中选择一个最好的答案这一功能
所有语言模型,包括用于聊天的模型,都是基于线性序列的标记进行操作,并没有内在的角色处理机制。这意味着角色信息通常是通过在消息之间添加控制标记来注入的,以表示消息边界和相关角色。以单轮对话为例:
适配前--单轮对话:
user:我今早上吃了炒米粉。
assistant:炒米粉在广东是蛮常见的早餐,但是油太多,可以偶尔吃吃。
适配后--单轮对话:
<s><intp>我今早上吃了炒米粉。</intp> [ASST] 炒米粉在广东是蛮常见的早餐,但是油太多,可以偶尔吃吃。[/ASST] eos_token
这里除了区分user和 assistant加的special token 以外,必须要添加的是eos_token,必须要让模型知道什么时候next token生成结束,如果没有终止符,模型会陷入推理的无限循环。
不幸的是,目前还没有一个标准来确定使用哪些标记,因此不同的模型使用的格式和控制标记都可能大相径庭。聊天对话通常表示为字典列表,每个字典包含角色和内容键,表示一条单独的聊天消息。聊天模板是包含Jinja模板的字符串,用于指定如何将给定模型的对话格式化为一个可分词的序列。通过将这些信息存储在分词器中,我们可以确保模型以其期望的格式获取输入数据。对于一个模型来说,chat template 存储在tokenizer.chat_template 属性上(这个属性将保存在tokenizer_config.json文件中),如果chat template没有被设置,对那个模型来说,默认模版会被使用。
包构成
- langchain-core:提供底层抽象和接口定义,是整个框架的基石。包含了一些核心组件以及将它们组合在一起的方式,例如 ChatModels、Vector Stores、Tools 等。不包含任何集成包。
- langchain:实现具体功能组件,核心功能包括链(Chains)、智能体(Agents)、检索策略。
- langchan-*:langchain 集成包,由 langchain 团队和集成开发者共同维护。例如langchain-openai、langchain-deepseek、langchain-redis、langcahin-mongodb等。
- langchain-community:由社区维护的第三方集成包。
- langgraph:用于将 LangChain 组件编排为生产级应用的框架,支持持久化、流式处理等关键特性。
LLM模型层
LangChain的一个核心价值就是它提供了标准的模型接口;然后我们可以自由的切换不同的模型。一次最基本的LLM调用需要的prompt、调用的LLM API设置、输出文本的结构化解析(output_parsers 在 prompt 中尤其是system prompt中插入了需要返回的格式说明)等。从 BaseLanguageModel 可以看到模型层抽象接口方法predict 输入和输出是str,也就是 TEXT IN TEXT OUT。PS:底层Transformer比如 chatglm原输出不是直接str,langchain中要求模型返回必须是str的结果,因此 Transformers.Model 与 langchain.llm 要有一个适配。
# BaseLanguageModel 是一个抽象基类,是所有语言模型的基类
class BaseLanguageModel(...):
# 基于用户输入生成prompt
@abstractmethod
def generate_prompt(self,prompts: List[PromptValue],stop: Optional[List[str]] = None,...) -> LLMResult:
@abstractmethod
def predict(self, text: str, *, stop: Optional[Sequence[str]] = None, **kwargs: Any ) -> str:
@abstractmethod
def predict_messages(self, messages: List[BaseMessage],) -> BaseMessage:
# BaseLLM 增加了缓存选项, 回调选项, 持有各种参数
class BaseLLM(BaseLanguageModel[str], ABC):
1. 覆盖了 __call__ 实现 ==> generate ==> _generate_helper ==> prompt 处理 + _generate 留给子类实现。
2. predict ==> __call__
# LLM类期望它的子类可以更加简单,将大模型的调用方法完全封装,不需要用户实现完整的_generate方法,只需要对外提供一个非常简单的call方法就可以操作LLMs
class LLM(BaseLLM):
1. _generate ==> _call 留给子类实现。 输入文本格式提示,返回文本格式的答案
BaseLanguageModel ==> BaseLLM + BaseChatModel
| BaseLLM | BaseChatModel | |
|---|---|---|
| 基础大语言模型 | 对话大语言模型 | |
| 出口/invoke | generate_prompt(prompts,…) | generate_prompt(prompts,…) |
| 叶子子类 | bind_functions/bind_tools/with_structured_output |
Prompt 和 OutputParser 规范化输入输出
Langchain 中的提示工程我们只要让机器将下一个单词预测的足够准确就能完成许多复杂的任务!并且是自己写大部分让大模型补小部分。下面是一个典型的提示结构。并非所有的提示都使用这些组件,但是一个好的提示通常会使用两个或更多组件。让我们更加准确地定义它们。
- 指令 :告诉模型该怎么做,如何使用外部信息(如果提供),如何处理查询并构建 Out。
- 外部信息 或 上下文 :充当模型的附加知识来源。这些可以手动插入到提示中,通过矢量数据库 (Vector Database) 检索(检索增强)获得,或通过其他方式(API、计算等)引入。
- 用户 In 或 查询 :通常(但不总是)是由人类用户(即提示者)In 到系统中的查询。
- Out 指示器 :标记要生成的文本的 开头。如果生成 Python 代码,我们可以使用 import 来指示模型必须开始编写 Python 代码(因为大多数 Python 脚本以 import 开头)。
对于文本生成模型服务来说,实际的输入和输出本质上都是字符串,因此直接裸调用LLM服务带来的问题是要在输入格式化和输出结果解析上做大量的重复的文本处理工作,我们不太可能硬编码上下文和用户问题,比如用 f-strings(如 f”insert some custom text ‘{custom_text}’ etc”)替换。LangChain当然考虑到这一点,提供了Prompt和OutputParser抽象规范化这个过程,添加多个参数,并以面向对象的方式构建提示,用户可以根据自己的需要选择具体的实现类型使用,可以高效的复用(参数化的提示词模版)和组合提示词。PS:本质是f-string 的对象化,但是太薄了,国内一般一个prompt要准备中英文双份,这个抽象没cover住,再进一步,输入输出应该封在一起,比如从一段话中提取一个graph的三元组,则最好是有一个triplet:list[str] = extractor.extract(text) 的抽象出来。
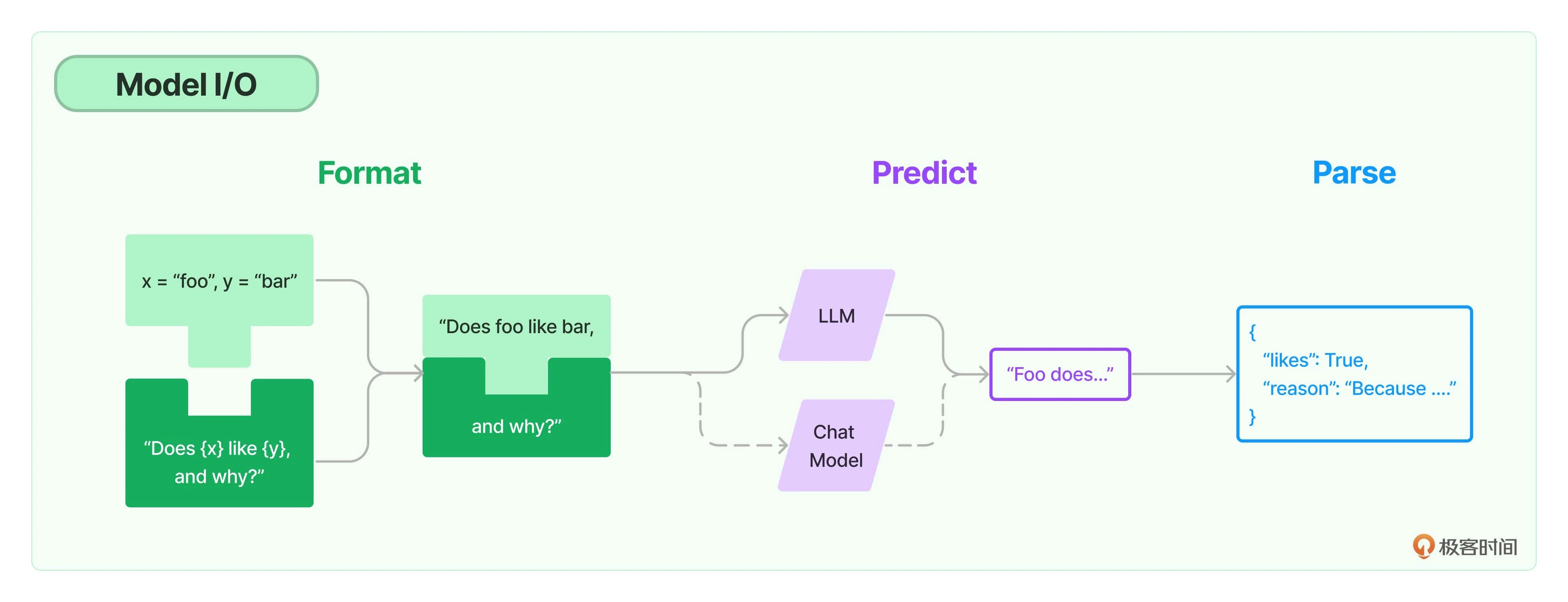
prompt
prompt template 是一个模板化的字符串,可以用来生成特定的提示(prompts)。可以将变量插入到模板中,从而创建出不同的提示。这对于重复生成相似格式的提示非常有用。 BasePromptTemplate ==> StringPromptTemplate + BaseChatPromptTemplate 所有的 PromptTemplate 父类都是BasePromptTemplate,它也是一个Runnable,它将Runnable.invoke 转为了PromptTemplate.format_xx,Runnable.invoke 输入转为PromptTemplate.format_xx输入,PromptTemplate.format_xx输出转为invoke 输出。
| PromptTemplate | ChatPromptTemplate | |
|---|---|---|
| 提示词模版 | 对话提示词模版 | |
| 构造/入口 | from_template | from_messages |
| 出口/invoke | format_prompt | format_messages |
PromptTemplate 核心成员是template,核心方法是format_prompt 返回PromptValue,之所以PromptValue而不是str,是因为现在llm的输入已经不只是text了,还有message list和image。
class BasePromptTemplate(RunnableSerializable[Dict, PromptValue], Generic[FormatOutputType], ABC):
input_variables: List[str]
def invoke(self, input: Dict, config: Optional[RunnableConfig] = None) -> PromptValue:
return self._call_with_config(self._format_prompt_with_error_handling,input,config,run_type="prompt",)
def _format_prompt_with_error_handling(self, inner_input: Dict) -> PromptValue:
_inner_input = self._validate_input(inner_input)
return self.format_prompt(**_inner_input)
@abstractmethod
def format_prompt(self, **kwargs: Any) -> PromptValue:
"""Create Prompt Value."""
class PromptTemplate(StringPromptTemplate):
input_variables: List[str]
template: str
def from_template(cls, template: str,*,template_format: str = "f-string",partial_variables: Optional[Dict[str, Any]] = None,**kwargs: Any,) -> PromptTemplate:
input_variables = get_template_variables(template, template_format)
...
return cls(
input_variables=input_variables,
template=template,
template_format=template_format, # type: ignore[arg-type]
partial_variables=_partial_variables,
**kwargs,
)
ChatPromptTemplate 核心成员是messages,核心方法是format_messages返回List[BaseMessage]。PS:上层定义方法,下层负责实现,所谓实现,一般会带有对应的成员变量。
class BaseChatPromptTemplate(BasePromptTemplate, ABC):
def format_prompt(self, **kwargs: Any) -> PromptValue:
messages = self.format_messages(**kwargs)
return ChatPromptValue(messages=messages)
@abstractmethod
def format_messages(self, **kwargs: Any) -> List[BaseMessage]:
"""Format kwargs into a list of messages."""
class ChatPromptTemplate(BaseChatPromptTemplate):
input_variables: List[str]
messages: List[MessageLike]
def format_messages(self, **kwargs: Any) -> List[BaseMessage]:
...
result = []
for message_template in self.messages:
if isinstance(message_template, BaseMessage):
result.extend([message_template])
elif isinstance(
message_template, (BaseMessagePromptTemplate, BaseChatPromptTemplate)
):
message = message_template.format_messages(**kwargs)
result.extend(message)
else:
raise ValueError(f"Unexpected input: {message_template}")
return result
@classmethod
def from_messages(cls,messages: Sequence[MessageLikeRepresentation],template_format: Literal["f-string", "mustache"] = "f-string",) -> ChatPromptTemplate:
_messages = [_convert_to_message(message, template_format) for message in messages]
# Automatically infer input variables from messages
input_vars: Set[str] = set()
for _message in _messages:
...
input_vars.update(_message.input_variables)
return cls(input_variables=sorted(input_vars),messages=_messages,...)
OutputParser
Output parsers help structure language model responses. OutputParser 还可以生成特定格式的提示词,并将提示词插入到prompt,指导模型按照相应的格式输出内容。
Chain
LangChain是语言链的涵义,那么Chain就是其中的链结构,属于组合各个层的中间结构,可以称之为胶水层,将各个模块(models, document retrievers, other chains)粘连在一起,实现相应的功能,也是用于程序的调用入口。
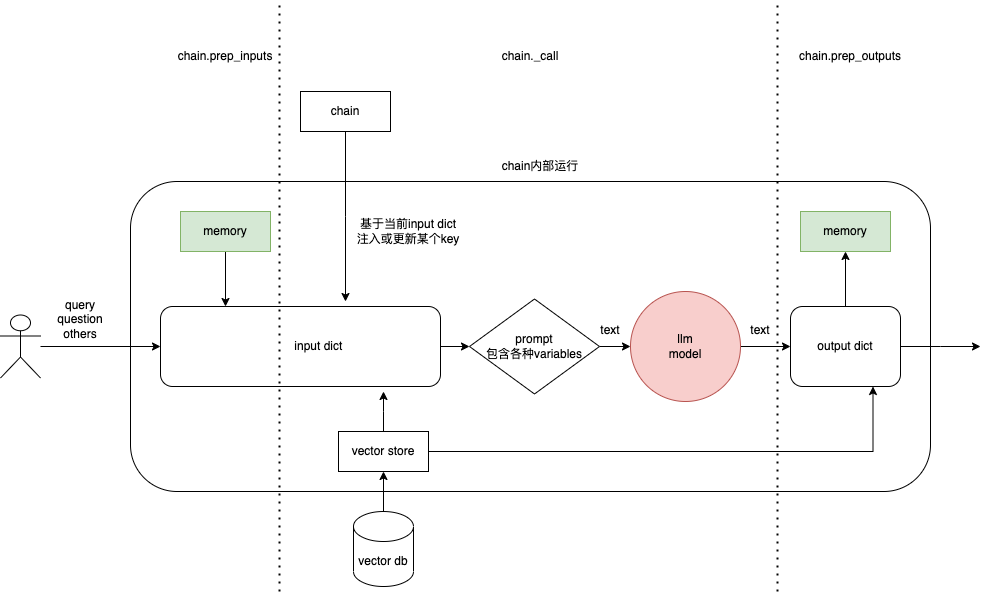
Chain模块有一个基类Chain,是所有chain对象的基本入口,与用户程序的交互、用户的输入、其他模块的输入、内存的接入、回调能力。chain通过传入String值,控制接受的输入和给到的输出格式。Chain的子类基本都是担任某项专业任务的具体实现类,比如LLMChain,这就是专门为大语言模型准备的Chain实现类(一般是配合其他的chain一起使用)。PS: 注意,这些是Chain 的事情,模型层不做这些
- 针对每一种chain都有对应的load方法,load方法的命名很有规律,就是在chain的名称前面加上
_load前缀 - 从 Chain可以看到核心方法run/_call输入输出是dict(DICT IN DICT OUT),有dict 自然有key,所以每个 Chain 里都包含了两个很重要的属性:input_keys 和 output_keys。 ||输入dict|输出dict| |—|—|—| |chain(question)|{chain.input_keys:question}|| |chain({“question”:question})|{“question”:question}|| |memory|{memory.memory_key:memory.buffer}|| |BaseConversationalRetrievalChain|{“input_documents”:xx}|| |llm||{“full_generation”:generation,chain.output_key:chain.output_parser.parse_result(generation)}| |memory||读取memory.output_key 保存| |BaseConversationalRetrievalChain||带上source_documents,generated_question| PS: 不准确的说,各种chain的核心是预定了很多prompt template的构建方法。
链有很多种调用方式。
- 直接调用,当我们像函数一样调用一个对象时,它实际上会调用该对象内部实现的 call 方法。
- 通过 run 方法,也等价于直接调用 call 函数。
- predict 方法类似于 run,只是输入键被指定为关键字参数而不是 Python 字典。
-
apply 方法允许我们针对输入列表运行链,一次处理多个输入。
input_list = [ {"flower": "玫瑰",'season': "夏季"}, {"flower": "百合",'season': "春季"}, {"flower": "郁金香",'season': "秋季"} ] result = llm_chain.apply(input_list) print(result) - generate 方法类似于 apply,只不过它返回一个 LLMResult 对象,而不是字符串。LLMResult 通常包含模型生成文本过程中的一些相关信息,例如令牌数量、模型名称等。
class Chain(...,ABC):
memory: Optional[BaseMemory] = None
callbacks: Callbacks = Field(default=None, exclude=True)
@abstractmethod
def _call(self,inputs: Dict[str, Any],run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, Any]:
1. 覆盖了 __call__ 实现 ==> 输入处理 + _call + 输出处理
def generate(self,input_list: List[Dict[str, Any]],run_manager)) -> LLMResult:
prompts, stop = self.prep_prompts(input_list, run_manager=run_manager)
return self.llm.generate_prompt(prompts,stop,callbacks=callbacks,**self.llm_kwargs,)
from langchain import PromptTemplate, OpenAI, LLMChain
llm = OpenAI(temperature=0.9)
prompt = PromptTemplate.from_template("将下面的句子翻译成英文:{sentence}")
llm_chain = LLMChain(
llm = llm,
prompt = prompt
)
result = llm_chain("今天的天气真不错")
print(result['text'])
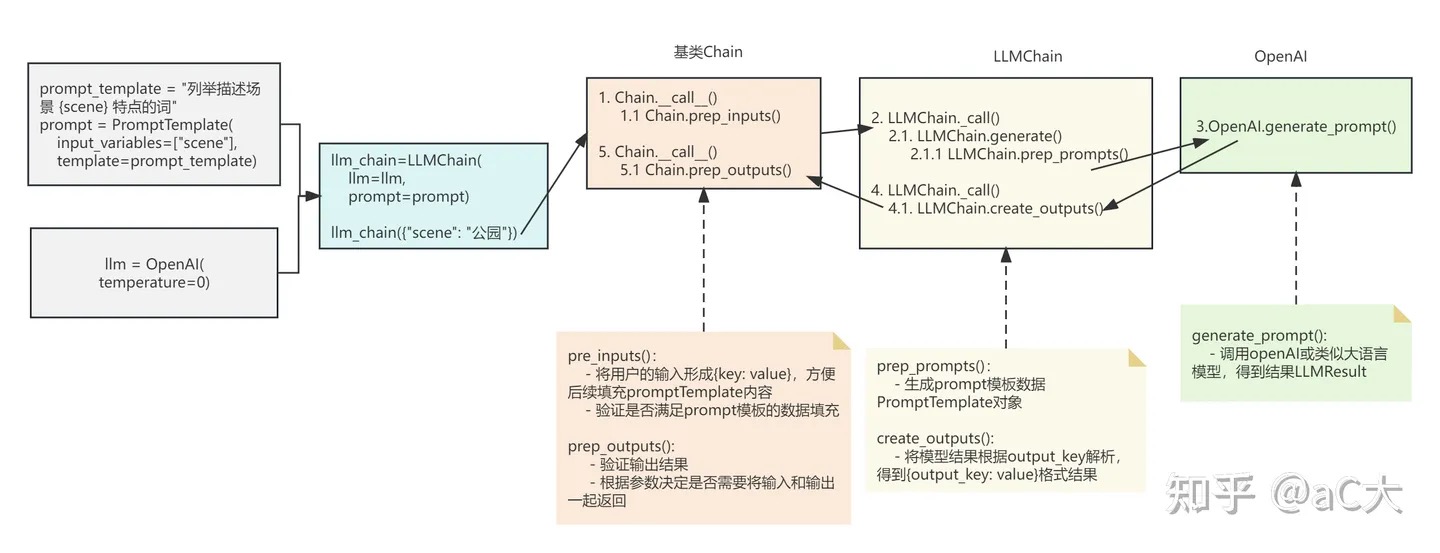
class Chain(Serializable, Runnable[Dict[str, Any], Dict[str, Any]], ABC):
@property
@abstractmethod
def input_keys(self) -> List[str]:
@property
@abstractmethod
def output_keys(self) -> List[str]:
# # Chain 的本质其实就是根据一个 Dict 输入,得到一个 Dict 输出
def __call__(self,inputs: Union[Dict[str, Any], Any],...) -> Dict[str, Any]:
inputs = self.prep_inputs(inputs)
outputs = (self._call(inputs, run_manager=run_manager) if new_arg_supported else self._call(inputs))
class LLMChain(Chain):
@property
def input_keys(self) -> List[str]:
return self.prompt.input_variables
def _call(self,inputs: Dict[str, Any],run_manager: Optional[CallbackManagerForChainRun] = None,) -> Dict[str, str]:
response = self.generate([inputs], run_manager=run_manager)
prompts, stop = self.prep_prompts(input_list, run_manager=run_manager)
for inputs in input_list:
selected_inputs = {k: inputs[k] for k in self.prompt.input_variables}
prompt = self.prompt.format_prompt(**selected_inputs)
prompts.append(prompt)
return self.llm.generate_prompt(prompts,stop) #
return self.create_outputs(response)[0]
继承 Chain 的子类主要有两种类型:
- 通用工具 Chain: 控制 Chain 的调用顺序, 是否调用,他们可以用来合并构造其他的 Chain 。比如MultiPromptChain、EmbeddingRouterChain、LLMRouterChain(使用 LLM 来确定动态选择下一个链)。
- 专门用途 Chain: 和通用 Chain 比较来说,他们承担了具体的某项任务,可以和通用的 Chain 组合起来使用,也可以直接使用。有些 Chain 类可能用于处理文本数据,有些可能用于处理图像数据,有些可能用于处理音频数据等。
__call__逻辑 |
|||
|---|---|---|---|
| Chain | prep_inputs inputs = inputs + memory external_context |
_call | prep_outputs memory.save_context |
| LLMChain | generate=prep_prompts+generate_prompt | ||
| docs = _get_docs(question) answer = combine_documents_chain.run(question,docs) |
|||
| AgentExecutor | while._should_continue agent.plan + tool.run |
||
| ConversationalRetrievalChain | chat_history_str = get_chat_history new_question = question_generator.run(new_question,chat_history_str) docs = _get_docs(new_question,inputs) answer = combine_docs_chain.run(new_question,docs) |
PS:用一个最复杂的场景比如 ConversationalRetrievalChain 打上断点,观察各个变量值的变化,有助于了解Chain的运行逻辑。 PS: 以编程视角来看,chain的核心是prompt,大部分时间都在在凑prompt 中提到的变量。
Memory
通过Chain,LangChain相当于以“工作流”的形式,将LLM与IO组件进行了有秩序的连接,从而具备构建复杂AI工程流程的能力。而我们都知道LLM提供的文本生成服务本身不提供记忆功能,需要用户自己管理对话历史。
消息历史主要通过不同类型的Message类:
- 如HumanMessage, AIMessage, SystemMessage等来表示对话中的各种消息。
- 这些消息可以被添加到 ChatMessageHistory 中,形成一个完整的对话记录。
Memory 记忆的内存管理则更为复杂和多样化。
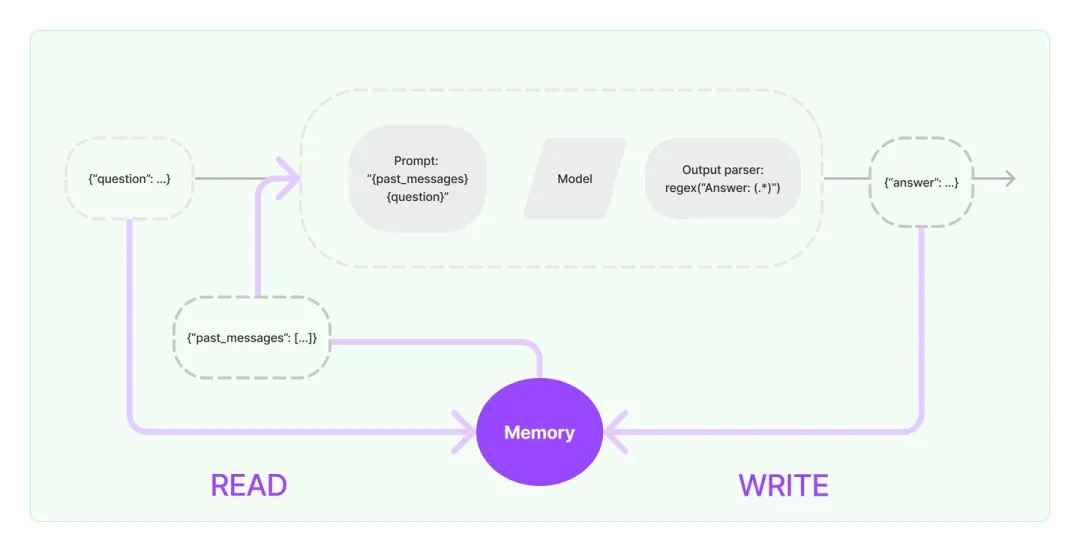
记忆 ( memory )允许大型语言模型(LLM)记住与用户的先前交互。默认情况下,LLM/Chain 是 无状态 stateless 的,每次交互都是独立的,无法知道之前历史交互的信息。对于无状态代理 (Agents) 来说,唯一存在的是当前输入,没有其他内容。memory 需要支持两个基本操作:读取和写入。LangChain通过Memory工具类为Agent和Chain提供了记忆功能(除了用户输入外地另一个输入,或者说增强用户输入),让智能应用能够记住前一次的交互,比如在聊天环境中这一点尤为重要。在核心逻辑执行完毕并返回答复之前,chain 会将这一轮的输入和输出都保存到memory中,以便在将来使用它们。
LangChain使用Memory组件保存和管理历史消息,这样可以跨多轮进行对话,在当前会话中保留历史会话的上下文。Memory组件支持多种存储介质,可以与Monogo、Redis、SQLite等进行集成,以及简单直接形式就是Buffer Memory。常用的Buffer Memory有
- ConversationSummaryMemory :以摘要的信息保存记录
- ConversationBufferWindowMemory:以原始形式保存最新的n条记录
- ConversationBufferMemory:以原始形式保存所有记录
通过查看chain的prompt,可以发现{history}变量传递了从memory获取的会话上下文。
memory = ConversationBufferMemory()
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
print(conversation.prompt)
print(conversation.predict(input="1+1=?"))
ConversationChain 的提示模板 print(conversation.prompt.template):
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
{history}
Human: {input}
AI:
ConversationSummaryMemory 的提示模版
Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
Current summary:
{summary}
New lines of conversation:
{new_lines}
New summary:
使用这种方法,我们可以总结每个新的交互,并将其附加到所有过去交互的 summary 中。
使用了memory的chain的流程
使用了memory的chain的流程如下,整个执行的流程其实除来入口调用predict及标红部分,其他执行的步骤和流程一样。标红部分就是memory的使用部分。主要包括load_memory_variables和save_context。PS:跟BaseMemory的接口方法也都对上了。
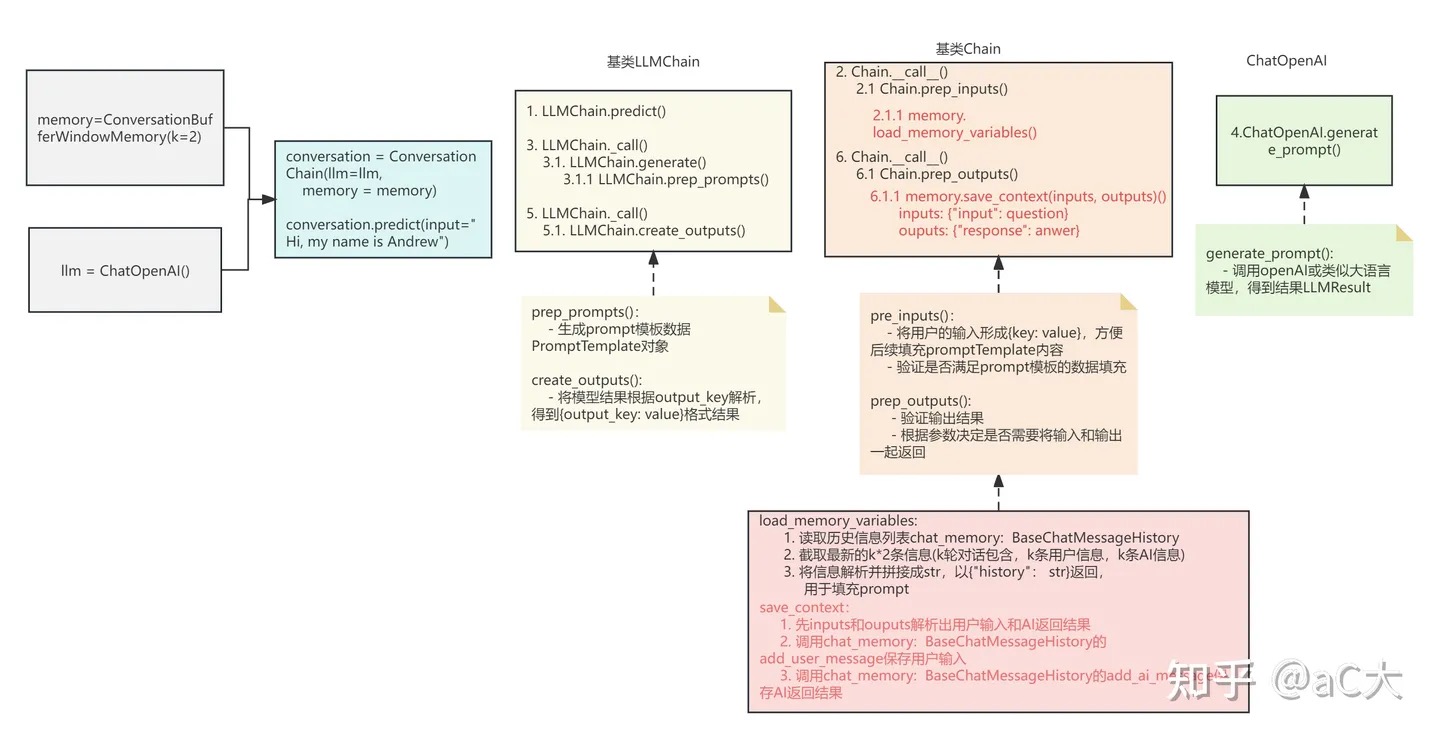
在llm 生成之前,首要工作就是填充PromptTemplate 中的变量。 Memory 有几个key
- input_key,save_context 用到
- output_key,save_context 用到
- memory_key,load_memory_variables(从内存加载变量) 用到
底层实现
一个Memory系统要支持两个基本操作:读和写。一个Chain对输入有特定的要求,一部分输入直接来自用户,另外一些可能来自Memory系统。在一个完整的对话轮次中,Chain会和Memory系统交互两次。具体为:
- 接收用户初始输入后,执行具体逻辑前,Chain会读取Memory来增强用户输入,将当前问题和历史会话合并生成完整的提示词内容。
- 执行具体逻辑后,返回应答之前,Chain会把当前轮次的输入与输出写进Memory,供以后使用。
Chain 与 Memory 相关有两处 prep_inputs 和 prep_outputs,Chain 是 DICT IN DICT OUT的,prep_inputs 会将 memory 数据{"history": messages }加入到dict=inputs,prep_outputs 会将 inputs、outputs 保存到 memory中: HumanMessage(content=inputs), AIMessage(content=outputs) 。
class Chain(Serializable, Runnable[Dict[str, Any], Dict[str, Any]], ABC):
memory: Optional[BaseMemory] = None
callbacks: Callbacks = Field(default=None, exclude=True)
def invoke( self,input: Dict[str, Any],...) -> Dict[str, Any]:
return self(input,callbacks=config.get("callbacks"),...)
@property
@abstractmethod
def input_keys(self) -> List[str]:
"""Keys expected to be in the chain input."""
@property
@abstractmethod
def output_keys(self) -> List[str]:
"""Keys expected to be in the chain output."""
def __call__(self,inputs: Union[Dict[str, Any], Any],callbacks,...)-> Dict[str, Any]:
inputs = self.prep_inputs(inputs)
callback_manager = CallbackManager.configure(callbacks,...)
run_manager = callback_manager.on_chain_start(inputs,...)
outputs = self._call(inputs, run_manager=run_manager)
run_manager.on_chain_end(outputs)
final_outputs = self.prep_outputs(inputs, outputs, return_only_outputs)
return final_outputs
@abstractmethod
def _call(self,inputs: Dict[str, Any],...) -> Dict[str, Any]:
"""Execute the chain.This is a private method that is not user-facing. It is only called within
`Chain.__call__`, which is the user-facing wrapper method that handles
callbacks configuration and some input/output processing."""
def prep_inputs(self, inputs: Union[Dict[str, Any], Any]) -> Dict[str, str]:
...
if self.memory is not None:
external_context = self.memory.load_memory_variables(inputs)
inputs = dict(inputs, **external_context)
return inputs
def prep_outputs(self,inputs: Dict[str, str],outputs: Dict[str, str],...)-> Dict[str, str]:
...
if self.memory is not None:
self.memory.save_context(inputs, outputs)
class BaseMemory(Serializable, ABC):
@property
@abstractmethod
def memory_variables(self) -> List[str]:
"""The string keys this memory class will add to chain inputs."""
@abstractmethod
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return key-value pairs given the text input to the chain."""
@abstractmethod
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save the context of this chain run to memory."""
class BaseChatMemory(BaseMemory, ABC):
"""Abstract base class for chat memory."""
chat_memory: BaseChatMessageHistory = Field(default_factory=ChatMessageHistory) # 这就是所谓的存在内存里了
output_key: Optional[str] = None
input_key: Optional[str] = None
return_messages: bool = False
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save context from this conversation to buffer."""
input_str, output_str = self._get_input_output(inputs, outputs)
self.chat_memory.add_user_message(input_str)
self.chat_memory.add_ai_message(output_str)
class ConversationBufferMemory(BaseChatMemory):
memory_key: str = "history"
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return history buffer."""
return {self.memory_key: self.buffer} # self.buffer = self.chat_memory.messages
把Memory集成到系统中涉及两个核心问题:存储的历史信息是什么、如何检索历史信息。
# 消息在内存中的形态
class BaseChatMessageHistory(ABC):
messages: List[BaseMessage]
def add_user_message(self, message: str) -> None: # 带有Chat字样的类是为聊天设计的,主要保存聊天的历史信息,实现了add_xx_message方法
def add_ai_message(self, message: str) -> None:
# 消息格式
class BaseMessage(Serializable):
content: str
additional_kwargs: dict = Field(default_factory=dict)
消除幻觉/Retriever
RAG中关键组件:DocumentLoader/TextSplitter/EmbeddingsModel/VectorStore/Retriever。
检索器(retriever)是一个接口,它需要实现的功能是:对于给定的一个非结构化的查询,返回Document对象;它本身不需要存储数据,只是简单地返回数据。A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) them. Vector stores can be used as the backbone of a retriever, but there are other types of retrievers as well. 比如 EnsembleRetriever 本身不存储数据,只是基于rrf 算法对 持有的Retriever 的返回结果进行汇总排序。
Document 对象的艺术之旅(从加载、转换、存储、到查询结果都用Document 表示)
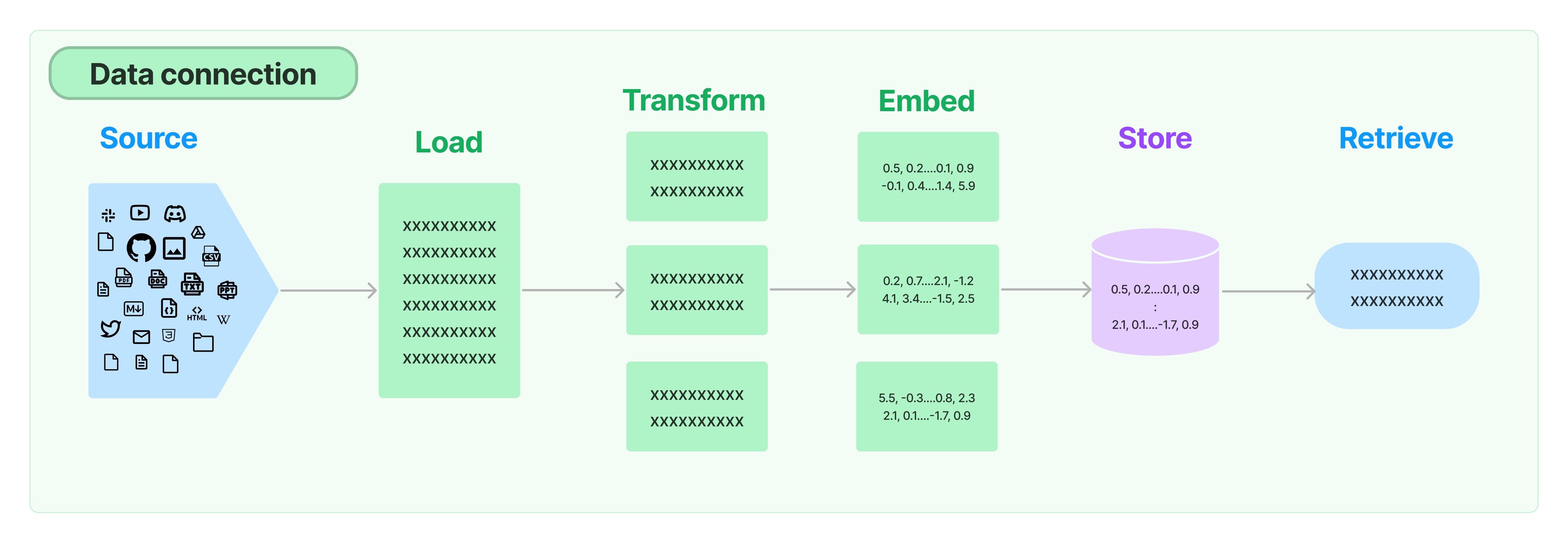
loader = TextLoader('./test.txt', encoding='utf8')
docs = loader.load()
print(docs)
# [Document(page_content='ChatGPT是OpenAI开发的一个大型语言模型,...', metadata={'source': './test.txt'})]
text_splitter = CharacterTextSplitter(separator = "\n\n",chunk_size = 1000,chunk_overlap = 200,length_function = len,is_separator_regex = False,)
texts = text_splitter.create_documents([d.page_content for d in docs])
print(texts)
# [
# Document(page_content='ChatGPT是OpenAI开发的一个大型语言模型,...', metadata={}),
# Document(page_content='我们将探讨如何使用不同的提示工程技术来实现不同的目标。...', metadata={}),
# Document(page_content='无论您是普通人、研究人员、开发人员,...', metadata={}),
# Document(page_content='在整本书中,...', metadata={})
#]
embeddings = HuggingFaceEmbeddings(model_name='BAAI/bge-large-en',multi_process=True)
db = Chroma.from_documents(texts, embeddings)
query = "ChatGPT是什么?"
docs = db.similarity_search(query)
print(docs[0].page_content)
# ChatGPT是OpenAI开发的一个大型语言模型,可以提供各种主题的信息
retriever = db.as_retriever()
retrieved_docs = retriever.invoke(query)
print(retrieved_docs[0].page_content)
retriever.invoke(query) ==> retriever.get_relevant_documents ==> VectorStoreRetriever.similarity_search
class BaseRetriever(ABC):
def invoke(self, input: str, config: Optional[RunnableConfig] = None) -> List[Document]:
config = config or {}
return self.get_relevant_documents(input,...)
def get_relevant_documents(self, query: str, *, callbacks: Callbacks = None, **kwargs: Any) -> List[Document]:
@abstractmethod
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
async def aget_relevant_documents(self, query: str, *, callbacks: Callbacks = None, **kwargs: Any) -> List[Document]:
class VectorStoreRetriever(BaseRetriever):
def _get_relevant_documents( self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
docs = self.vectorstore.similarity_search(query, **self.search_kwargs)
return docs
BaseRetriever 的基本工作就是 get_relevant_documents(留给子类 _get_relevant_documents实现),核心是vectorstore.similarity_search,对于 BaseRetriever 的扩展,则是在vectorstore.similarity_search 之前或之后做一些事情,这也是 retriever 和 VectorStore 要分为两个接口的原因,比如做以下的事儿
- 处理query,比如生成多个新的query,比如 MultiQueryRetriever
- 对找回的documents 进一步的查询、转换等,比如ParentDocumentRetriever(父文档回溯)
- 提供add_documents 接口,在存入 vectorstore 时即将 get_relevant_documents 用到的一些关联数据存入到docstore
- 比如 EnsembleRetriever 本身不存储数据,只是基于rrf 算法对 持有的Retriever 的返回结果进行汇总排序。也就是 BaseRetriever 的主要子类是 VectorStoreRetriever,但也不全是VectorStoreRetriever。
- Retriever 查询过程中支持回调 RetrieverManagerMixin 的 on_retriever_end 和 on_retriever_error方法,而vectorstore的执行过程不会触发回调。
class MultiQueryRetriever(BaseRetriever):
retriever: BaseRetriever
llm_chain: LLMChain
def _get_relevant_documents(self,query: str,*,run_manager: CallbackManagerForRetrieverRun,) -> List[Document]:
queries = self.generate_queries(query, run_manager)
documents = self.retrieve_documents(queries, run_manager)
return self.unique_union(documents)
class MultiVectorRetriever(BaseRetriever):
id_key: str = "doc_id"
vectorstore: VectorStore
docstore: BaseStore[str, Document]
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
sub_docs = self.vectorstore.similarity_search(query, **self.search_kwargs)
ids = [] # We do this to maintain the order of the ids that are returned
for d in sub_docs:
if d.metadata[self.id_key] not in ids:
ids.append(d.metadata[self.id_key])
docs = self.docstore.mget(ids)
return [d for d in docs if d is not None]
# 将文档拆分为较小的块,同时每块关联其父文档的id,小块用于提高检索准确度,大块父文档用于返回上下文
class ParentDocumentRetriever(MultiVectorRetriever):
child_splitter: TextSplitter
parent_splitter: Optional[TextSplitter] = None
def add_documents(self,documents: List[Document],ids: Optional[List[str]] = None,add_to_docstore: bool = True,) -> None:
documents = self.parent_splitter.split_documents(documents)
docs = []
full_docs = []
for i, doc in enumerate(documents):
sub_docs = self.child_splitter.split_documents([doc])
for _doc in sub_docs:
_doc.metadata[self.id_key] = _id
docs.extend(sub_docs)
full_docs.append((_id, doc))
self.vectorstore.add_documents(docs)
self.docstore.mset(full_docs)
RetrievalQA 则是retriever 的包装类,有点retriever 工厂的意思,根据不同的参数 选择不同的llm、retriever 来实现QA。
qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff",retriever=self.vector_db.as_retriever())
answer = qa(query)
其实质是 通过retriever 获取相关文档,并通过BaseCombineDocumentsChain 来获取答案。
RetrievalQA.from_chain_type
==> load_qa_chain ==> _load_stuff_chain ==> StuffDocumentsChain(xx)
==> RetrievalQA(chain, retriever)
# langchain/chains/retrieval_qa/base.py
@classmethod
def from_chain_type(cls,llm: BaseLanguageModel,chain_type: str = "stuff",chain_type_kwargs: Optional[dict] = None,**kwargs: Any,) -> BaseRetrievalQA:
"""Load chain from chain type."""
_chain_type_kwargs = chain_type_kwargs or {}
combine_documents_chain = load_qa_chain(llm, chain_type=chain_type, **_chain_type_kwargs)
return cls(combine_documents_chain=combine_documents_chain, **kwargs)
# langchain/chains/question_answering/__init__.py
def load_qa_chain(llm: BaseLanguageModel,chain_type: str = "stuff",verbose: Optional[bool] = None,callback_manager: Optional[BaseCallbackManager] = None,**kwargs: Any,) -> BaseCombineDocumentsChain:
loader_mapping: Mapping[str, LoadingCallable] = {
"stuff": _load_stuff_chain,
"map_reduce": _load_map_reduce_chain,
"refine": _load_refine_chain,
"map_rerank": _load_map_rerank_chain,
}
return loader_mapping[chain_type](
llm, verbose=verbose, callback_manager=callback_manager, **kwargs
)
def _load_stuff_chain(...)-> StuffDocumentsChain:
_prompt = prompt or stuff_prompt.PROMPT_SELECTOR.get_prompt(llm)
llm_chain = LLMChain(llm=llm,prompt=_prompt,verbose=verbose,callback_manager=callback_manager,callbacks=callbacks,)
return StuffDocumentsChain(llm_chain=llm_chain,...)
class RetrievalQA(BaseRetrievalQA):
retriever: BaseRetriever = Field(exclude=True)
Callback
LangChain 的 Callback 机制允许你在应用程序的不同阶段进行自定义操作,如日志记录、监控和数据流处理,这个机制通过 CallbackHandler(回调处理器)来实现。回调处理器是 LangChain 中实现 CallbackHandler 接口的对象,为每类可监控的事件提供一个方法。当该事件被触发时,CallbackManager 会在这些处理器上调用适当的方法。
- BaseCallbackHandler 是最基本的回调处理器,你可以继承它来创建自己的回调处理器。它包含了多种方法,如 on_llm_start/on_chat(当 LLM 开始运行时调用)和 on_llm_error(当 LLM 出现错误时调用)等。
- LangChain 也提供了一些内置的处理器,例如 StdOutCallbackHandler,它会将所有事件记录到标准输出。还有 FileCallbackHandler,会将所有的日志记录到一个指定的文件中。
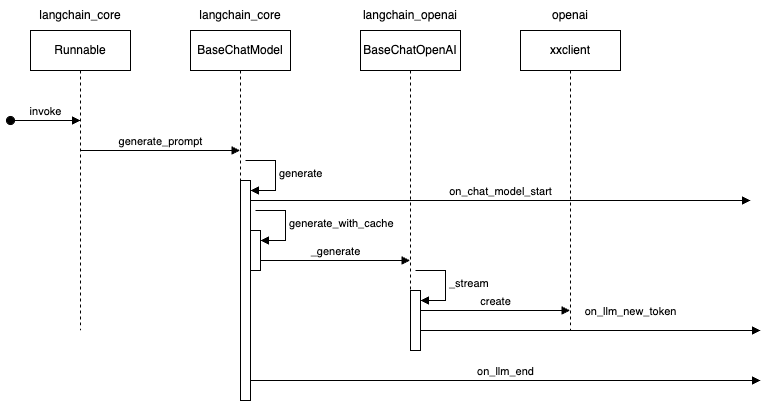
看 AsyncCallbackHandler 各个回调方法的参数,再结合langhcain 各个抽象的作用,很对口。
class AsyncCallbackHandler(BaseCallbackHandler):
async def on_llm_start(self,prompts: List[str],...)
"""Run when LLM starts running."""
async def on_llm_end(self,response: LLMResult,...):
"""Run when LLM ends running."""
async def on_chat_model_start(self,serialized: Dict[str, Any],messages: List[List[BaseMessage]],...):
"""Run when a chat model starts running."""
async def on_llm_new_token(self,token: str,...):
"""Run on new LLM token. Only available when streaming is enabled."""
async def on_chain_start(self,inputs: Dict[str, Any],...):
"""Run when chain starts running."""
async def on_chain_end(self,outputs: Dict[str, Any],...):
"""Run when chain ends running."""
async def on_chain_error(self,error: BaseException,...):
"""Run when chain errors."""
async def on_tool_start(self,serialized: Dict[str, Any],input_str: str,...):
"""Run when tool starts running."""
async def on_tool_end(self,output: str,...):
"""Run when tool ends running."""
async def on_tool_error(self,error: BaseException, ...):
"""Run when tool errors."""
async def on_agent_action(self,action: AgentAction,...):
"""Run on agent action."""
async def on_agent_finish(self,finish: AgentFinish,...):
"""Run on agent end."""
async def on_retriever_start(self,serialized: Dict[str, Any],query: str,...):
"""Run on retriever start."""
async def on_retriever_end(self,documents: Sequence[Document],...):
"""Run on retriever end."""
async def on_retriever_error(self,error: BaseException,...):
"""Run on retriever error."""
- callback 可以在构建runnable 时传入,也可在invoke 时传入,一个runnable 有多个callbacks,因此要有一个对象统一管理这些callback,叫callbackmanager。callbackmanager 只负责触发on_xx_start,on_xx_start 返回一个runManager,on_xx_start 一般会返回一个callbackManagerForXX(就是一个runManager) 封装父runable的所有callback,runManager 主要触发on_xx_end 和 on_xx_error。
- on_xx_start 会判断如果有传入的run_id 就使用传入的,没有则自己new一个。run_id保证了,如果多个llm共用一个callback实例,在callback on_xx 执行时的run_id可以区分不同的调用链路。这些信息 也是callbackmanager/runManager 负责构建并传给callback的,这也是为何要有callbackmanager/runManager存在,光在runable 之间传递callback list是不够的。PS:至于为何区分callbackManager/runManager还有待观察。
- runnable 有父子关系,执行child_runnable.invoke 时也要执行parent_runnable.callbacks,实际上在父子runnable.invoke 传递的不是callback list 而是callbackManager(runManager.get_child 又可以返回一个 CallbackManager)。连带着callbackManager/runManager 通过parent_run_id 关联也有了父子关系。
runManager = cm.on_xx_start();child_cm = runManager.get_child()- child_cm.parent_run_id = cm/runManager.run_id
- callbackhandler 分为是否inheritable。child_cm 只保留了cm.inheritable_callbacks。 Runnable 自身是不包含callbacks的,只有invoke时可以传递RunnableConfig.callbacks。Runnable 子类 比如Chain 包含callbacks 成员。 也就是有两种类型的回调设置方法:构造函数回调和invoke 等方法。一种是可以透传到子Runnable,一种只应用于本次执行。
- langchain 提了一个handle_event 方法(由callbackmanager/runManager 调用)负责真正触发callback.on_xx,这样不管callback 是同步还是异步的,都可以被触发执行。
LLM 可观测性组件都是基于callbackhandler 实现的,分为服务端、客户端、与langchain集成套件,会预先定义好类似trace/span的概念。
- langfuse
- 概念:user ==> session/conversation ==> trace ==> span,run/span包含input、output、tags、metadata的等
- LangSmith提供了一套完整的SDK用于您在自己的LLM应用中对每一次的AI应用的“Run”进行灵活管理。
- LangSmith 有一套概念 trace和run(一对多关系),什么是一次Run?这通常代表你的LLM应用中一次完整任务的执行过程。通常以用户输入(或系统输入)开始,以最终输出结束。一次Run的过程中会包含一次或者多次的LLM调用与交互,并最终完成整个思维链获得输出。
- 提供了langsmith-sdk(python) 来向LangSmith录入数据,且实际上也是通过callbackhandler(在langchain trace包下) 来调用langsmith-sdk client上传run数据(tracehandler)
- 因为LangSmith是内置的,所以callmanager 内部会根据开关决定是否加入tracehanlder,不用显式在够着Runnable或invoke时注入callbackhandler。
为了落实 LLM 可观测性,我们具体应该关注哪些方面?
- Prompt 输入输出交互信息
- Token 消耗
- 模型响应时间
- Agent workflow
- 用户反馈
一些理解
- 一次llm的调用的基本组成是llm(llm client) 和prompt
- llm client 负责text in text output 抽象
- prompt 负责variables 到text 抽象。text 到output 因为output 领域特定,但json是一个相对普及和通用的格式。prompt 抽象也该负责起来,langchain 将这两个活儿分拆到PromptTemplate 和 OutputParser。
-
chain = prompt llm output_parser 组成一次调用。
- 一次干活儿,光有chain 不够,还有为 chain 准备数据,以及将chain的输出 进一步格式化和使用的过程。
- 提供一个XXChain。
input_struct = get_xx() xx_chain = XXChain(llm, ...) output_struct = xx_chain(input_struct) - 自己提供一个 XXComponent,干一个活儿定义一个XXComponent,可以抽一个BaseComponent出来,明显的共性就是都需要持有llm_client
class BaseComponent(ABC): def __init__(config): self.llm_client = OpenAIClient(config) class XXComponent(BaseComponent): def __init__(**kwargs): xx def run(input_struct) -> output_struct: xx - 如果没有这样一个封装,再对prompt 和 output_parser 没有合理的管理,你的代码将经常在 业务代码langchain 概念之间跳跃。
- 提供一个XXChain。
- 在看了一些框架之后,个人发现将prompt 和 output_parser 分开是不对的,因为prompt 一般定义了输出格式,改prompt 也得改output_parser实现,以及output_parser解析失败的默认值等,为此应有一个统一抽象比如叫Prompt
- llm 负责 text in text output
- Prompt 负责input_struct to text, text to output_struct
- Component 负责config + input_struct in, output_struct output,根据需要聚合其它逻辑或Component
留下评论