rerank微调
简介(未完成)
Reward Mode用于评估某个状态/动作序列的好坏。
对于 Embedding 模型来说,它通常采用 Encoder 架构,它的训练目标是使得语义相似的文本在向量空间距离更近,而 Reranker ,则采用 Cross Encoder 架构,它的训练目标是预测查询和文档之间的分数。
为什么用rerank
是使用elasticsearch的retrieval召回的内容相关度有问题,多数情况下score最高的chunk相关度没问题,但是top2-5的相关度就很随机了,这是最影响最终结果的。我们看了elasticsearch的相似度算法,es用的是KNN算法(开始我们以为是暴力搜索),但仔细看了一下,在es8的相似度检索中,用的其实是基于HNSW(分层的最小世界导航算法),HNSW是有能力在几毫秒内从数百万个数据点中找到最近邻的。为了检索的快速,HNSW算法会存在一些随机性,反映在实际召回结果中,最大的影响就是返回结果中top_K并不是我们最想要的,至少这K个文件的排名并不是我们认为的从高分到低分排序的。
HNSW(最小可导航世界)的逻辑解释起来有点麻烦,但是我可以打一个比方:比如你需要从一个城市的南部坐公交去北部,我们要选择最短的坐车路线(含换乘),那么有两种方式选择:
- knn:将所有可能的公交路线(含换乘)做一个整理,假设有28900条路线,然后按花费时间进行排序,选择Top1或者Top n。抛开语义理解错误的问题,这种方法是非常精确的,但是耗时巨大,也可以认为是一种暴力检索;
- ann:还有一种就是相似最近邻,我们这里说到更多的是hnsw。为了让非技术专业的朋友可以听懂,不严谨地说,看着地图,从28900条路线中,选择出发地和目的地两点连线附近的50或100条公交路线。这种方法的效率极高,可能耗时只需要knn的万分之一,但它的问题在于无法确定这50或100条里面哪几条才是最好的。于是,如果你采用ann却不用rerank的话,就会比较拉垮了。
因为在搜索的时候存在随机性,这应该就是我们在RAG中第一次召回的结果往往不太满意的原因。但是这也没办法,如果你的索引有数百万甚至千万的级别,那你只能牺牲一些精确度,换回时间。这时候我们可以做的就是增加top_k的大小,比如从原来的10个,增加到30个。然后再使用更精确的算法来做rerank,使用一一计算打分的方式,做好排序。
原理
Embedding模型接受单文本输入,将最后一层的[EOS] Token 的隐藏状态向量,作为文本的语义向量;支持根据不同任务定制输入指令。 Reranking模型接受文本对输入,经过chat template拼接后,输入到模型中,预测下一个Token是“是”或“否”的概率,来判断两个文本的相关性。
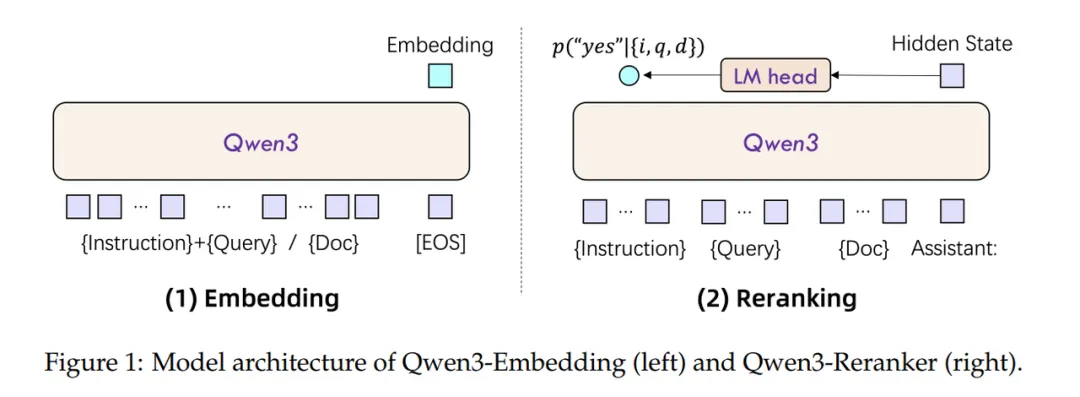
微调
微调数据集格式为[query,正样本集合,负样本集合]。微调在Embeding模型与Reranker模型采用同类型数据集,并将语义相关性任务视为二分类任务,采用BCE作为损失函数。
https://zhuanlan.zhihu.com/p/704562748 未细读
Reranker模型训练技巧:负样本挖掘,困难负样本挖掘的核心作用
- 增强模型区分能力。通过引入与正例语义高度相似但实际不相关的负样本(如主题相关但细节冲突的文档),强制模型学习细粒度语义差异,避免仅通过表面特征(如关键词重叠)判断相关性。例如在法律文档检索中,困难负样本可能是涉及同类法条但适用场景不同的案例,模型需通过条款适用条件等深层特征区分。
- 加速损失收敛效率。相比随机负样本,困难负样本与正例的相似度更高,能产生更大的梯度值,促使模型参数更快更新。实验显示,在相同训练步数下,使用困难负样本的模型MRR指标收敛速度提升约40%,且最终精度更高。
- 提升模型泛化能力。困难负样本通常来自真实场景中的边界案例,训练后模型对模糊查询的处理能力增强。例如用户查询”苹果产品推荐”时,模型需区分消费电子(Apple)与水果(apple)两类文档,经过困难负样本训练后,此类歧义查询的Top-1准确率可提升25%以上。
- 优化特征空间分布。通过动态调整负样本难度(如逐步提高Top-K负例的K值),模型能自适应地优化特征空间,使语义相似的文档在向量空间中聚类更紧密,不同类别的边界更清晰。这种优化可使后续检索阶段的召回效率提升15%-20%。
基于张量的重排序
评测 Embedding 模型和 Reranker 模型,通常可以观察 MTEB 榜单,在 2024 年上半年,Reranker 的榜单基本都是 Cross Encoder ,而到了下半年,榜单更多为基于 LLM 的重排序模型所占据。这类方案已经不是 Encoder 架构,而是标准 LLM 的 Decoder 架构,由于参数量更大,因此推理成本更高。
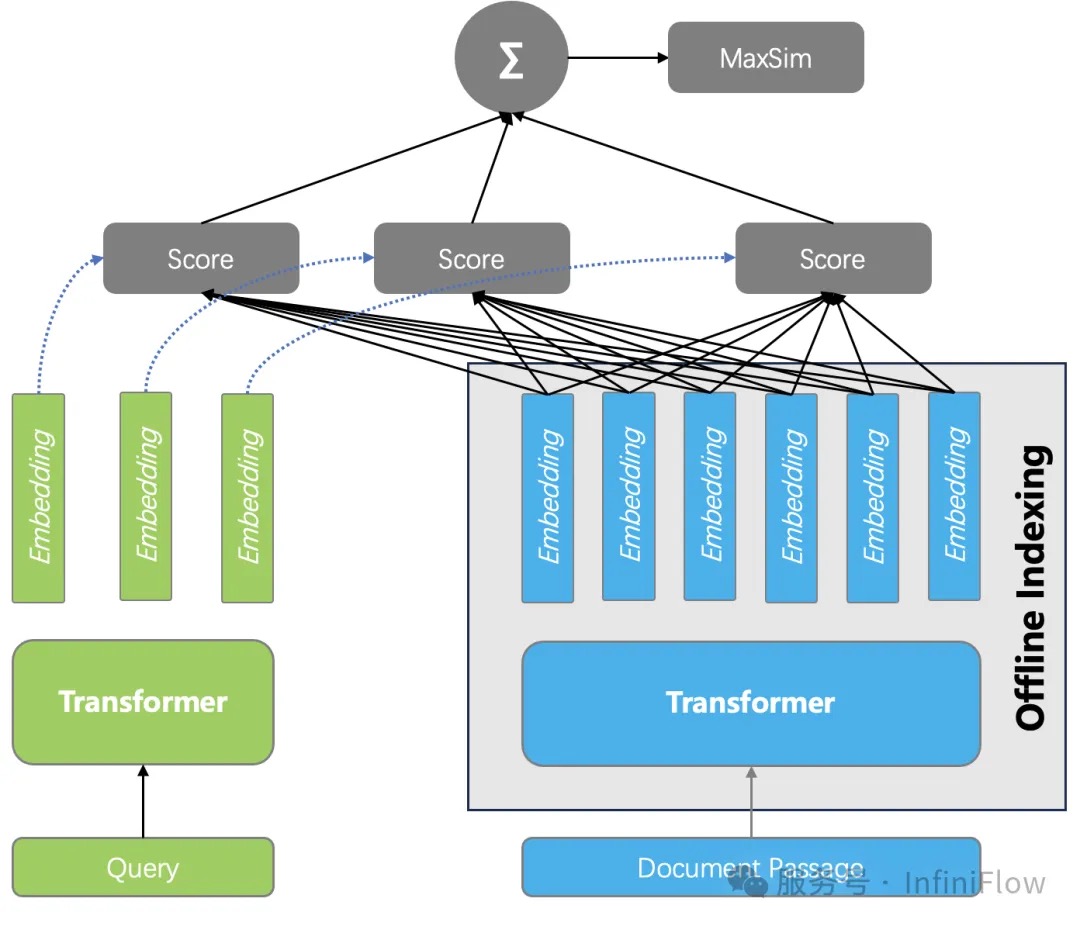
一种被称作延迟交互模型的重排序方案引起关注,这就是基于张量的重排序。它的具体做法是:在索引阶段,保存 Encoder 为每个 Token 生成的 Embedding,因此对于一个文档来说,就是用一个张量 Tensor (或者多向量)来表示一个文档,在查询的时候,只需要生成查询的每个 Token 的 Embedding,然后计算所有查询和 Text Çhunk 之间所有 Token 两两之间的相似度,然后累加就是最终文档得分。这种重排序,同样捕获了 Token 之间的交互信息,所以理论上可以做到跟 Cross Encoder 接近或者持平的效果。而另一方面,由于在查询时不涉及复杂的模型推理,所以它的成本相比 Cross Encoder,或者基于 LLM 的 Reranker要低得多,这甚至可以把排序做到数据库内部,因此带来的好处就是:即使粗筛的结果并不理想,但采用基于张量的重排序,可以对更多的结果进行重排,因此也有很大的概率弥补之前的召回。
评测(未完成)
Reranker模型的业务评估指标:Hit-Rate与MRR
- Hit-Rate(命中率,HR@K)
- 定义:衡量推荐列表中是否命中目标项,不考虑排名
- 公式:HR@K = 命中次数 / N(N为测试样本总数)
- 适用场景:召回阶段衡量覆盖能力
- MRR(平均倒数排名)
- 定义:衡量第一个正确命中位置的平均倒数
- 公式:MRR = (1/N) × Σ(1/rank_i)(rank_i为第i个测试样本第一个正确命中项的排名)
- 适用场景:关注前列推荐质量的场景
RM的发展方向
对模型自我进化的思考与设计首先做个简单的声明——我认为RM不应该仅仅是一个模型,更应该是一个系统,它可以使用各种工具来进行辅助——因此下面的RM模型指的是一个评估系统。RM模型是输出偏好的载体,用来高效表达输出偏好。它从收集的偏好数据中进行学习,将标注数据的偏好泛化到没有见过的样本上,提升数据标注的利用率。直观地说,RM模型的作用是高效地从SFT模型的多元化输出中挑选出符合用户要求的输出。
在输入形式上,目前的RM模型主要采用pairwise-response的形式,也即$(x,y_w,y_l)$的形式。这主要是从人工反馈效率的角度考虑——很多时候对于单个回复,标注人员很难给出一个恰当的绝对打分,用户更没有意愿做这样的事情;相对而言,人们更容易给出一个相对打分。于此同时,现实中还存在另一种易得的pointwise-response形式的打分数据,也即 $(x,y,0/1)$,其中1表示输出可接受0表示输出不可接受。在这种形式的数据上学习评估系统也是非常必要的,因为:
用户的很多反馈是pointwise的,以下常见的用户反馈形式有多种就是以pointwise形式存在的:
- pointwise点赞(+输出拷贝、同一query模板大规模调用)、点踩(多轮输出修正)
- pointwise SFT数据
- pairwise更好、更差、差不多
- 隐式pairwise比较:多轮交互输出修正(可以训练模型判断多轮指令是否是在做输出修正)
基于工具的判断(如长度约束满足判断、否定约束满足判断)更适合做正误判断,而很难做pairwise比较。因此,如何综合pointwise和pairwise数据形式的RM模型学习是非常必要的。
- 让模型根据其自身能力来调整输出形式,实现自我能力的进化。这一点可以通过在RM中为希望模型进化方向上的输出赋予更高的分值来实现。比如希望让模型的输出可以在保证正确性的前提下越来越简洁,那么可以建立如下的评估标准:简洁且正确 > 繁琐但正确 > 简洁但错误 > 繁琐且错误。在此标准下,通过大规模的反馈学习,即使是同一个任务,模型也可以根据case的具体难易程度来选择尽可能简洁的回复形式(当然,过程中模型可能会陷入local optimal,此时在offline PPO阶段需要配合一些策略鼓励模型探索更多、更好的输出形式,从而实现进一步的能力进化)。
- 基于RM的千人千面。RM一般需要收敛偏好,将目标用户感兴趣的输出从SFT模型中筛选出来。但是,一个通用模型往往会同时拥有大量不同的用户。对于同一个任务,不同用户的标准也很可能是不同的。从用户角度出发,不能用单个标准去满足不同用户的需求,也不能让模型在不同标准之间做随机选择,这样既无法稳定给出让用户满意的回复也会让用户觉得模型不稳定。因此,千人千面地为不同用户采用不同的标准是很有必要的,这样才能真正地构建数用户和数据壁垒,提高产品竞争力。
假设对于指令 x 存在两种类型的输出 $y, y’$ ,用户 $u, u’$ 分别倾向于这两种类型的输出。对此,千人千面的 RM 需要做到:$s(x,y,u)>s(x,y’,u), s(x,y,u’)<s(x,y’,u’)$,其中 $s(\cdot)$ 表示一个 RM 模型的打分。相较于普通的 RM 模型,千人千面的 RM 模型额外引入了用户这个因素。在技术上,基于RM的千人千面的关键在于如何表示用户 。一个最naive的方式是用id来进行表示,但是这样的数据过于稀疏,不利于模型的泛化。
留下评论