Spark 内存管理及调优
前言
内存划分及用途
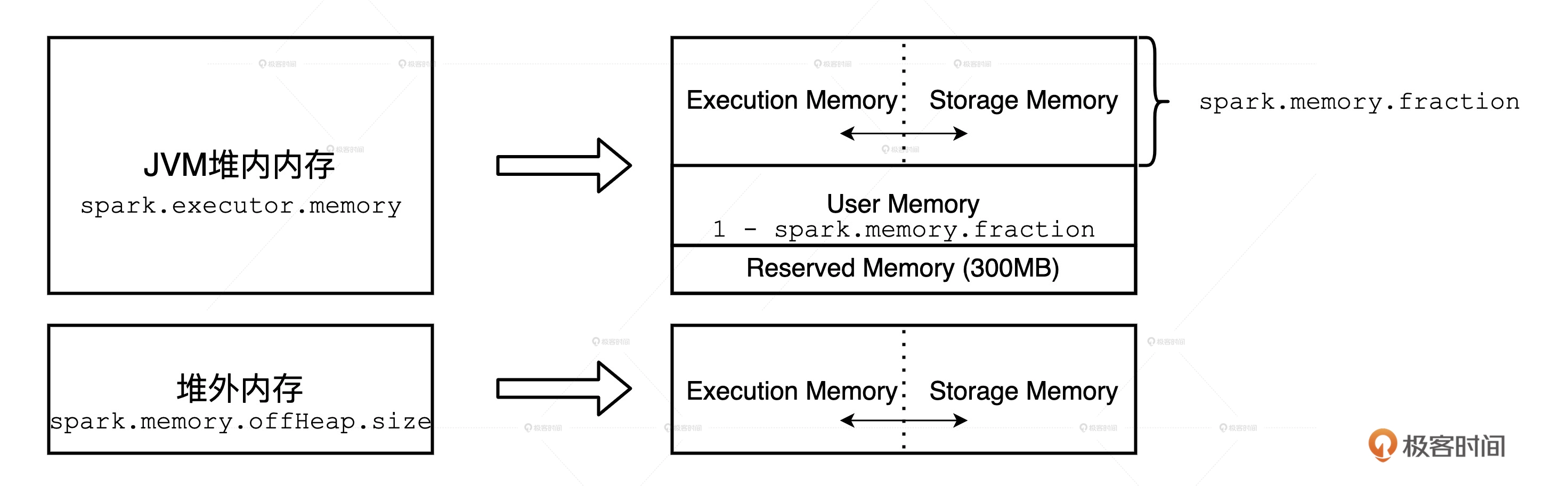
| 内存区域划分 | 堆内内存 | 对外内存 spark.memory.offHeap.enabled |
作用 |
|---|---|---|---|
| 内存空间总大小 | spark.executor.memory | spark.memory.offHeap.size | |
| Reserved memory | 固定为300M | 无 | 用于存储 Spark 内部对象 |
| User memory | 1-spark.memory.fraction | 无 | 用于存储用户自定义的数据结构 |
| Storage memory | spark.executor.memory * spark.memory.fraction * spark.memory.storageFraction |
spark.memory.offHeap.size * spark.memory.storageFraction |
用来容纳 RDD 缓存和广播变量 |
| Executor memory | spark.executor.memory * spark.memory.fraction * (1 - spark.memory.storageFraction) |
spark.memory.offHeap.size * (1-spark.memory.storageFraction) |
用于分布式任务执行,如 Shuffle、Sort 和 Aggregate 等操作 |
val dict: List[String] = List(“spark”, “scala”) // 字典在 Driver 端生成,它在后续的 RDD 调用中会随着任务一起分发到 Executor 端,Executor 将其存储在 User Memory 区域
val words: RDD[String] = sparkContext.textFile(“~/words.csv”)
val keywords: RDD[String] = words.filter(word => dict.contains(word))
keywords.cache // Storage Memory 内存区域
keywords.count
keywords.map((_, 1)).reduceByKey(_ + _).collect // reduceByKey 算子会引入 Shuffle,而 Shuffle 过程中所涉及的内部数据结构,如映射、排序、聚合等操作所仰仗的 Buffer、Array 和 HashMap,都会消耗 Execution Memory 区域中的内存
Spark 区分堆内内存和堆外内存:对于堆外内存来说,Spark 通过调用 Java Unsafe 的 allocateMemory 和 freeMemory 方法,直接在操作系统内存中申请、释放内存空间,管理成本较高;对于堆内内存来说,无需 Spark 亲自操刀而是由 JVM 代理。但频繁的 JVM GC 对执行性能来说是一大隐患。
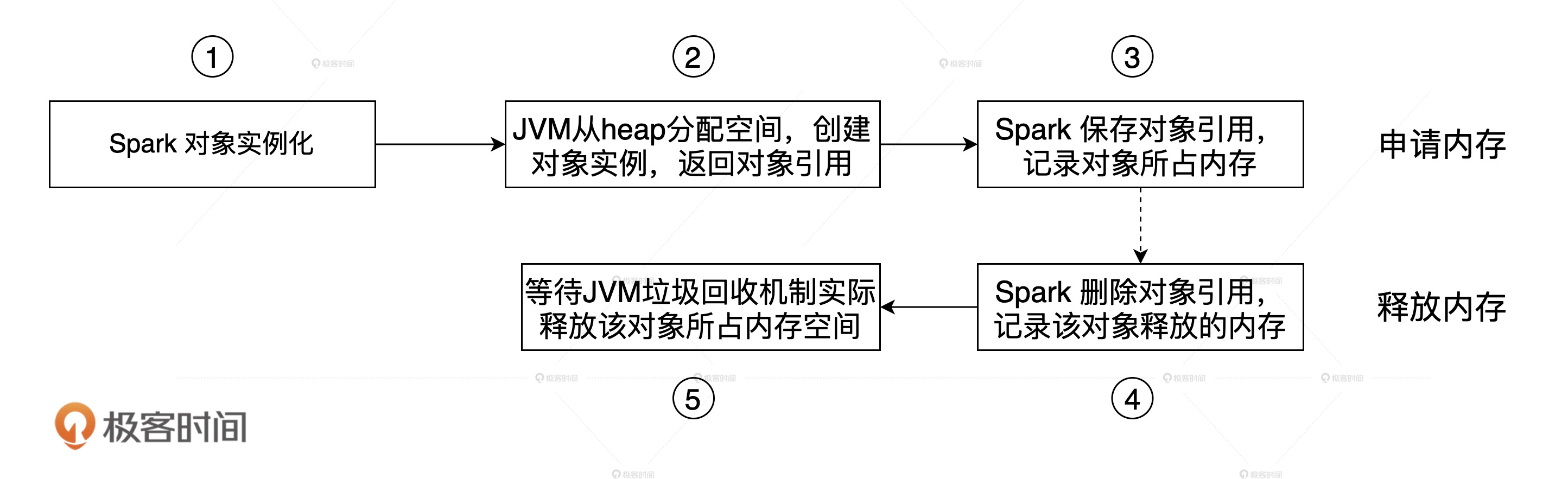
execution memory、storage memory的划分是逻辑上的。Spark在JVM之上的内存管理,实际上是一种基于“审计”的管理,也就是Spark会记录不同内存区域的内存消耗,但实际的内存申请与释放,还是依赖JVM本身,比如对象的实际删除,是要等到GC的时候。
Spark性能调优之资源分配
大体上是core 和mem两个方面,分配哪些资源?executor、core per executor、memory per executor、driver memory。
yarn资源队列。hadoop/spark/storm 每一个队列都有各自的资源(cpu mem),比如500G内存;100个cpu core;50个executor。平均每个executor:10G内存;2个cpu core。
并行度
Spark的并行度指的是什么?spark作业中,各个stage的task的数量,也就代表了spark作业在各个阶段stage的并行度!比如50个executor ,每个executor 有3个core ,也就是说,Application 任何一个stage运行的时候,都有总数150个cpu core 可以并行运行。但如果并行度只设置为100,平均分配一下,那么同时在运行的task只有100个,每个executor 只会并行运行 2个task,每个executor 剩下的一个cpu core 就浪费掉了。
如何去提高并行度?
- task数量,官方推荐,task数量设置成spark Application 总cpu core数量的2到3倍 ,比如150个cpu core ,可以设置 task数量为 300到500。 有些task 会运行快一点,比如50s 就完了,有些task 可能会慢一点,要一分半才运行完,所以如果你的task数量,刚好设置的跟cpu core 数量相同,可能会导致资源的浪费。比如150task ,10个先运行完了,剩余140个还在运行,但是这个时候,就有10个cpu core空闲出来了,导致浪费。如果设置2~3倍,那么一个task运行完以后,另外一个task马上补上来,尽量让cpu core不要空闲。同时尽量提升spark运行效率和速度。提升性能。
- 如何设置一个Spark Application的并行度?
spark.defalut.parallelism用于设置 RDD 的默认并行度 - RDD.repartition,给RDD重新设置partition的数量
- reduceByKey的算子指定partition的数量
val rdd2 = rdd1.reduceByKey(_+_,10) val rdd3 = rdd2.map.filter.reduceByKey(_+_) val rdd3 = rdd1.join(rdd2)rdd3里面partiiton的数量是由父RDD中最多的partition数量来决定,因此使用join算子的时候,增加父RDD中partition的数量。
Executor 并发度
分布式任务由 Driver 分发到 Executor 后,Executor 将 Task 封装为 TaskRunner,然后将其交给可回收缓存线程池(newCachedThreadPool)。线程池中的线程领取到 TaskRunner 之后,向 Execution Memory 申请内存,然后开始执行任务。
- RDD在计算的时候,每个分区都会起一个task,所以rdd的分区数目决定了总的的task数目。
- 每个节点可以起一个或多个Executor。
- Executor 的线程池大小由参数 spark.executor.cores 决定,每个任务在执行期间需要消耗的线程数由 spark.task.cpus 配置项给定。两者相除得到的商就是并发度,也就是同一时间内,一个 Executor 内部可以同时运行的最大任务数量。又因为,spark.task.cpus 默认数值为 1,并且通常不需要调整,所以,并发度基本由 spark.executor.cores 参数敲定。在同一个 Executor 中,当有多个(记为 N)线程尝试抢占执行内存时,需要遵循 2 条基本原则:
- 可用内存总大小(记为 M)为两部分之和,一部分是 Execution Memory 初始大小,另一部分是 Storage Memory 剩余空间。在统一内存管理模式下,在 Storage Memory 没有被 RDD 缓存占满的情况下,执行任务可以动态地抢占 Storage Memory。
- 每个线程分到的可用内存有一定的上下限,下限是 M/N/2,上限是 M/N
- 申请的计算节点(Executor)数目和每个计算节点核数,决定了你同一时刻可以并行执行的task。Task被执行的并发度 = Executor数目(SPARK_EXECUTOR_INSTANCES) * 每个Executor核数(SPARK_EXECUTOR_CORES)
- 就 Executor 的线程池来说,尽管线程本身可以复用,但每个线程在同一时间只能计算一个任务,每个任务负责处理一个数据分片。因此,在运行时,线程、任务与分区是一一对应的关系。
在一个 Executor 内,每个 CPU 线程能够申请到的内存比例是有上下限的。在给定执行内存总量 M 和线程总数 N 的情况下,为了保证每个线程都有机会拿到适量的内存去处理数据,Spark 用 HashMap 数据结构,以(Key,Value)的方式来记录每个线程消耗的内存大小,并确保所有的 Value 值都不超过 M/N。在一些极端情况下,有些线程申请不到所需的内存空间,能拿到的内存合计还不到 M/N/2。这个时候,Spark 就会把线程挂起,直到其他线程释放了足够的内存空间为止。换句话说,尽管一个 Executor 中有 N 个 CPU 线程,但这 N 个线程不一定都在干活。在 Spark 任务调度的过程中,这 N 个线程不见得能同时拿到分布式任务,所以先拿到任务的线程就有机会申请到更多的内存。在某些极端的情况下,后拿到任务的线程甚至连一寸内存都申请不到。PS:线程挂起是CPU 低效原因之一
建议
提升性能的办法
- 增加executor:如果executor数量比较少,那么,能够并行执行的task数量就比较少,就意味着,我们的Application的并行执行的能力就很弱。比如有3个executor,每个executor有2个cpu core,那么同时能够并行执行的task,就是6个。6个执行完以后,再换下一批6个task。增加了executor数量以后,那么,就意味着,能够并行执行的task数量,也就变多了。
- 增加每个executor的cpu core:也是增加了执行的并行能力。原本20个executor,每个才2个cpu core。能够并行执行的task数量,就是40个task。现在每个executor的cpu core,增加到了5个。能够并行执行的task数量,就是100个task。执行的速度,提升了2倍左右。
-
增加每个executor的内存量。增加了内存量以后,对性能的提升,有三点:
- 如果需要对RDD进行cache,那么更多的内存,就可以缓存更多的数据,将更少的数据写入磁盘,甚至不写入磁盘。减少了磁盘IO。
- 对于shuffle操作,reduce端,会需要内存来存放拉取的数据并进行聚合。如果内存不够,也会写入磁盘。如果给executor分配更多内存以后,就有更少的数据,需要写入磁盘,甚至不需要写入磁盘。减少了磁盘IO,提升了性能。
- 对于task的执行,可能会创建很多对象。如果内存比较小,可能会频繁导致JVM堆内存满了,然后频繁GC,垃圾回收,minor GC和full GC。(速度很慢)。内存加大以后,带来更少的GC,垃圾回收,避免了速度变慢,性能提升。
在给定执行内存 M、线程池大小 N 和数据总量 D 的时候,想要有效地提升 CPU 利用率,我们就要计算出最佳并行度 P,计算方法是让数据分片的平均大小 D/P 坐落在(M/N*2, M/N)区间,让每个Task能够拿到并处理适量的数据。怎么理解适量呢?D/P是原始数据的尺寸,真正到内存里去,是会翻倍的,至于翻多少倍,这个和文件格式有关系。不过,不管他翻多少倍,只要原始的D/P和M/N在一个当量,那么我们大概率就能避开OOM的问题,不至于某些Tasks需要处理的数据分片过大而OOM。Shuffle过后每个Reduce Task也会产生数据分片,spark.sql.shuffle.partitions 控制Joins之中的Shuffle Reduce阶段并行度,spark.sql.shuffle.partitions = 估算结果文件大小 / [128M,256M],确保shuffle 后的数据分片大小在[128M,256M]区间。PS: 核心思路是,根据“定下来的”,去调整“未定下来的”,就可以去设置每一个参数了。
假定Spark读取分布式文件,总大小512M,HDFS的分片是128M,那么并行度 = 512M / 128M = 4
- Executor 并发度=1,那么Executor 内存 M 应在 128M 到 256M 之间。
- Executor 并发度=2,那么Executor 内存 M 应在 256M 到 512M 之间。
留下评论