比特币 大杂烩
前言
为什么需要比特币
相关材料 漫谈比特币(一):信任 是一个系列,要点如下:
- 二进制数据 可复制性 与 现实世界 的价值转移的矛盾
- 对电子货币的信任,本质上是人们对(第三方)“记账者”的信任,而对于看得见摸得着的真实货币,人们对其价值的认同,从本质上讲,不是对这种货币本身,而是对其发行者的信任。
- 世界终究是不完美的,我们无法忍受黄金的缺点,更不可能回到物物交换的原始社会,我们发明人造货币的同时,就必须接受它的瑕疵:因为它是人造的,所以我们无法摆脱对人的信任。无论是支付宝,还是一个国家,本质上,归根结底,这些被信任的对象是人,而人是充满不确定性的,因而这种信任也是脆弱的。
- 比特币找到了一种全新的信任对象,作为一种革命性的电子货币,它既不基于虚无缥缈的上帝,也不基于充满不确定性的人类,而是基于数学这种特殊的存在。
- 将货币体系建立在对纯粹理性的信任之上,把铸币权从人类之手交给数学,抛弃了交易过程中的“第三方”比特币用一种脑洞大开的方式,彻底颠覆了有史以来人类的货币认知。
记账
传统记账
- 一般记账方法。收入xx,支出xx
- 复式记账法Double Entry Bookkeeping
- 三式记账法
重点说下复式记账法,目前找不到一个比较舒服的解释。
- 维基百科:因为每笔交易都至少记录在两个不同的账户当中。每笔交易的结果至少被记录在一个借方和一个贷方的账户,且该笔交易的借贷双方总额相等。
- 还有一种描述,比如你买房,那么你支持xx,甚至产生了负债xx,但同时你每月少缴纳了房租xx。按照知乎上的一些回答,第一种记账只记录静态信息,第二种呢,记录了动态信息。
- Asset(资产)+ Expense(费用) = Liability(负债) + Equity(所有者权益)+ Income (收入)公式右边呢是说明钱的来龙,左边呢是说明钱的去脉。复式记账(复式簿记)的基本原理是什么? - 知乎用户的回答 - 知乎
举个例子:小张给了小李一个苹果,小李后来还了两个苹果
传统记账方法:
小张的苹果 -1
(小李的苹果 +1)
(小李的苹果 -2)
小张的苹果 +2
这种方法没有准确反映小张和小李的借贷关系,或者是苹果(资产)的流动和变化的关系
复式的记账方法
小张的苹果 -1 | 小李的苹果 +1
小张的苹果 +2 | 小李的苹果 -2
为什么要有复式记账?因为假如条目增多,偿还时间不一致(小张借出两个,小李偿还5个,小张借出1个。。。),小张又和张三李四产生交易。到最后,无法清晰的判断小张苹果的来路和去向。
小张的苹果 -1 | 小李的苹果 +1
小张的苹果 +2 | 小李的苹果 -2
小张的苹果 +5 | 张三的苹果 -5
小张的苹果 -2 | 李四的苹果 +4
为什么说到记账
漫谈比特币(二):记账要点如下:
-
纸币、电子货币、数字货币, 如何判断真伪?如何回答你有多少钱?
- 纸币本身有真伪。在你手里,就是你有
- 电子货币,支付宝说你有,你就有
- 数字货币,没有支付宝证明了。防伪 ==> 本身无法证明,也没有中心化结构,那说清楚钱从哪里来 ==> 记账。 其实记账也没啥了不起,后来的以太坊还是支持记录余额的。
-
前一笔交易的output,成为当前这笔交易的input,而当前这笔交易的output,又会成为后面一笔交易的input,于是所有的交易记录环环相扣,形成了一个链条。
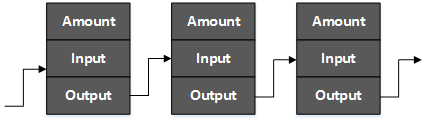
-
在这个链条的基础上,当发生了一笔新的交易,通过上一笔交易的验证脚本,来验证当前这笔交易的数字签名,从而判定当前交易的合法性。付款方通过 验证脚本 限定了收款方,你能接的上,就说明钱是你的。
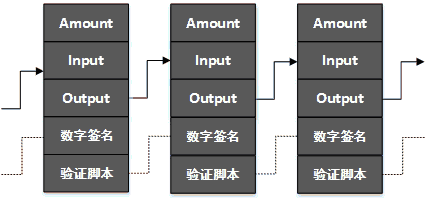
- 任何伪造的、非法的交易记录,都不可能成功加入交易链条,成为账本的一部分。这是比特币的最基本承诺,而实现这一承诺,借助的是现代密码学的公私钥非对称加密体系。
-
在现实生活中,我们可以把来自不同上家的钞票聚在一起,一次性花掉,也可以把一笔钱一次性支付(分配)给多个下家。在比特币的交易链条中,也是如此
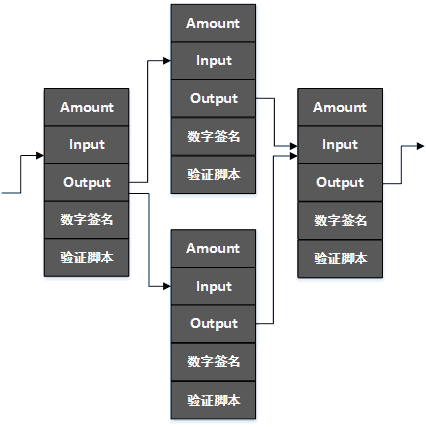
- 事实上的比特币交易链(注意不是区块链),并非是一根单链表,而是一个有向无环图(DAG)。中本聪称那些出度为0的节点为UTXO(Unspent Transaction Output),于是一个人(或者说一对公钥私钥代表的账户)在比特币账本上所拥有的财富,实际上就是其拥有的UTXO的金额总数。
因此,分布式环境下,可以使用记账 来 回答:如何识别货币真伪?如何表述拥有多少钱?
基本概念
- 账户地址,用户自己保留私钥,账户地址就是公钥经过一些列hash和编码得到的字符串
- 交易
- 交易脚本
- 区块
- 难度目标(一些文章会将其单列)
挖矿
前面提到,比特币采用记账的形式 来 描述交易,为此有一个交易链。 那么记账记在哪里?由谁来记?账本又如何 防止篡改呢?
挖矿是参与维护比特币网络的节点,通过协助生成新区块来获取一定量 新增比特币的过程。
比特币是如何防范双花的? - Ke Jiang的回答 - 知乎 中间提到一个名词:记账权。
- 比特币网络的运转就是矿工构造区块,链接区块的过程
- 构建区块的第一步是矿工把交易池中未处理的交易收集起来,区块有大小的限制,因此优先收集手续费高的交易,其次收集块龄长的交易。交易收集完成后构造所有交易的Merkle哈希树,并组装成一个区块,并立刻开始计算该区块的难度目标的解
- 如果有两个矿工A和B,同时算得区块的解。就会有分叉问题 ==> 谁最长听谁的 ==> 一笔交易 ,所属区块刚被加入链是不算的,要等该区块有了多个后向区块后,交易才算被可靠地确认了。
下图演化了处理分叉的过程,忽略中间的世界地图及各种网线,重点在两侧。
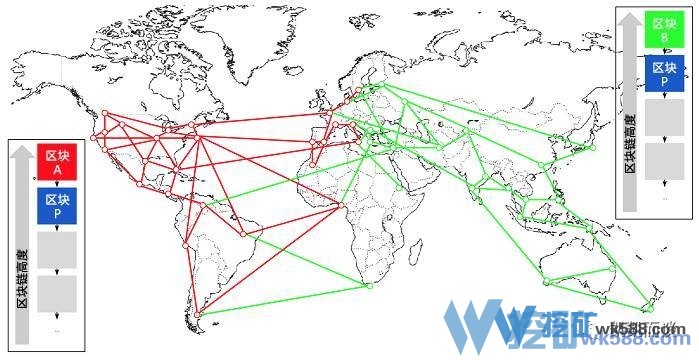
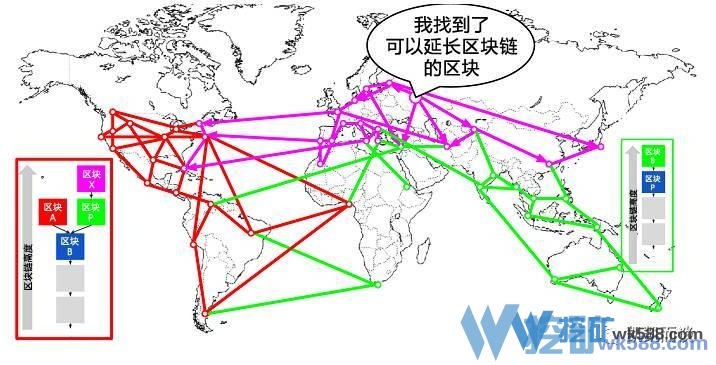
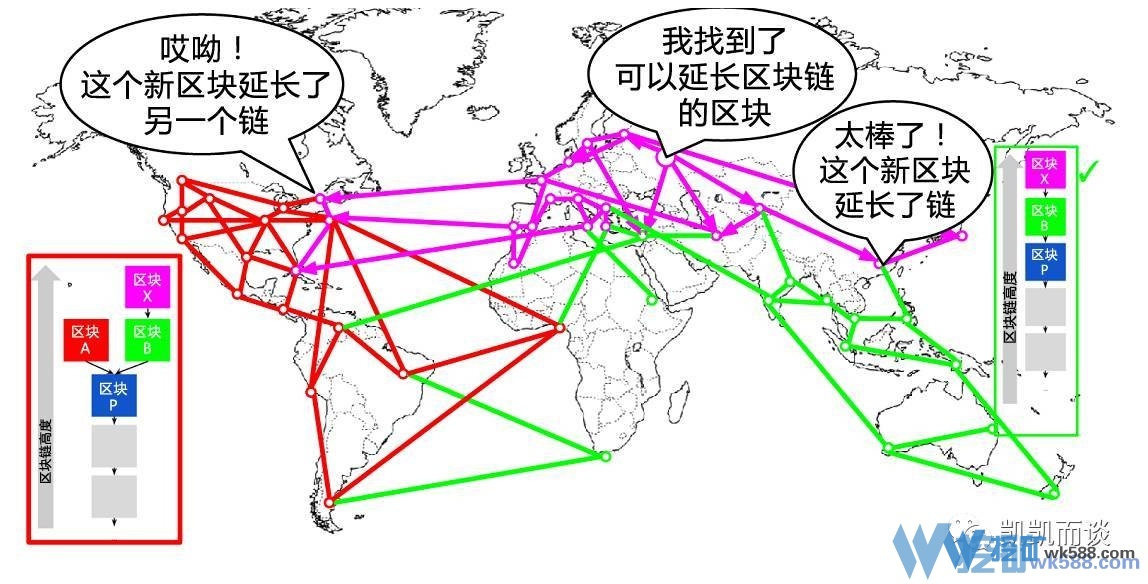
比特币挖矿原理要点如下:
- 在收到交易后,每一个节点都会在全网广播前对这些交易进行校验(校验规则见文章),并以接收时的相应顺序,为有效的新交易建立一个池(交易池)。A节点需要为内存池中的每笔交易分配一个优先级,并选择较高优先级的交易记录来构建候选区块。
- A节点已经构建了一个候选区块,那么就轮到A的矿机对这个新区块进行“挖掘”,以使这个区块有效
-
挖矿节点时刻监听着传播到比特币网络的新区块。假设当前A节点在挖277,316个区块,A挖矿节点一旦完成计算,立刻将这个区块发给它的所有相邻节点。
- 这些节点在接收并验证这个新区块后,也会继续传播此区块。
- 当这个新区块在网络中扩散时,每个节点都会将它作为第277,316个区块(父区块为277,315)加到自身节点的区块链副本中。
- 当挖矿节点收到并验证了这个新区块后,它们会放弃之前对构建这个相同高度区块的计算,并立即开始计算区块链中下一个区块的工作。
- 区块中的第一笔交易是笔特殊交易,称为创币交易或者coinbase交易。这个交易是由挖矿节点构造并用来奖励矿工们所做的贡献的。假设此时一个区块的奖励是25比特币,A挖矿的节点会创建“向A的地址支付25.1个比特币(包含矿工费0.1个比特币)”这样一个交易,把生成交易的奖励发送到自己的钱包。这个交易记录应该是算法生成的,否则岂不是爽歪歪。
小结一下,每个节点三个事儿:
- 接收交易,校验交易,转发交易
- 接收区块,校验区块,转发区块
- 计算自己的候选 区块,若是收到 其它节点的区块之前挖到,则加入链中并转发
回顾本小节刚开始提出来的问题:
- 记账记在哪里?记在区块链上,所有节点都维护一个副本
- 由谁来记?谁算的快,由谁来记
- 如何防篡改?假设现在链是A-B-C,然后你篡改了C成为C1。别人是A-B-C-D,你是A-B-C1-D1。你需要以后的所有步骤 都比别人算的快。其它的矿机与你是竞争者关系,理论上,当你拥有一半以上的矿机时,是可以做到的。且不说这不现实,真到你拥有了一半以上的矿机,你挖矿赚钱就行了,何必造假,造假导致比特币公信力下降,进而使得造假得来的比特币不值钱。
分布式货币的问题
- 货币的防伪
- 货币的交易,比如如何记录交易?前一小节 讲到了
- 避免双重支付/双花。什么是“双重支付”问题,怎样解决?这个问题在物理货币世界并不存在,因为你无法复制黄金。在纸币中,由于纸币是造币厂发行的,设计有复杂的防伪技术,如果有人制造了假币,可以通过法律来制止这些行为。了解 双重支付,得详细了解比特币的交易确认过程。
- 货币的发行,任何矿机挖到矿就可以“印刷“出bitcoin,发行的对象不可控(旷工谁干的多谁拿的多),发行节奏由数学保证。有别于央行通过 棚改货币化安置 等中心化方式
比特币是如何防范双花的? - Ke Jiang的回答 - 知乎可以发下,双花得以实现有两个前提:
- 即使交易者也是矿工
- 交易被纳入块后,即认为交易成功。此时,该区块也许只是在备选链中。
因此在实际的经济活动中,A发起交易, B等到 交易被纳入块,且该块之后有五六块(此时该块基本可以确定在主链中),再给A发货。
比特币为什么值钱
- 总量有限。比特币(Bitcoin,缩写BTC)是一种总量恒定2100万的数字货币。揭秘区块链:为什么比特币总量固定却不能一次性挖出来? 比特币不依靠特定货币机构发行,它依据特定算法,通过大量的计算产生,比特币经济使用整个P2P网络中众多节点构成的分布式数据库来确认并记录所有的交易行为,并使用密码学的设计来确保货币流通各个环节安全性。P2P的去中心化特性与算法本身可以确保无法通过大量制造比特币来人为操控币值。挖矿的过程就是通过庞大的计算量不断的去寻求这个方程组的特解,旷工求得一个特解,奖励一定量的比特币。在不改“方程组”的前提下,总量是恒定的
- 不可复制。双花问题
- 其流通方式安全,去中心化
- 保密
小结一下
- 主要脉络:实物货币的问题 ==> 纸币的信任问题 ==> 电子货币为什么要中心化/电子货币的中心化问题 ==> 数字货币去中心化的各种问题比如双花 ==> 解决办法
- 区块链 及其 承载 的交易链 区块链是什么
- 交易是被存储在区块链上的实际数据, 而区块则是记录确认某些交易是在何时,以及何种顺序成为区块链数据库的一部分
- 任何节点可以创建交易,而区块 则是旷工 负责创建
- 《区块链原理、设计与应用》:网络上的旷工通过“挖矿” 来完成对交易记录的记账过程(这就跟 中心化 银行等有具体的不同)。区块链网络 提供一个公共可见的记账本,该记账本并非记录每个账户的余额,而是用来记录发生过的交易的历史信息。重要的部分应该读三遍
问题:如果一个“矿机”运行的代码被改写,大部分逻辑一样,小部分逻辑偷偷改了点, 那么 整个网络如何识别这样的节点?
留下评论