多集群管理
简介
CNStack 多集群服务:基于 OCM 打造完善的集群管理能力
多集群
浅析 Kubernetes 多集群方案为什么要有多集群调度?
- 单集群的容量限制:单集群的最大节点数不是一个确定值,其受到集群的部署方法和业务使用集群资源的方式的影响。在官方文档中的集群注意事项里提到单集群 5000 个节点上限,我们可以理解为推荐最大节点数。
- 多租户:因为容器没法做到完美的隔离,不同租户可以通过不同宿主机或者不同集群分割开。对企业内部也是如此,业务线就是租户。不同业务线对于资源的敏感程度也不同,企业也会将机器资源划分为不同集群给不同业务线用。
- 云爆发:云爆发是一种部署模式,通过公有云资源来满足应用高峰时段的资源需求。正常流量时期,业务应用部署在有限资源的集群里。当资源需求量增加,通过扩容到公有云来消减高峰压力。
- 高可用:单集群能够做到容器级别的容错,当容器异常或者无响应时,应用的副本能够较快地另一节点上重建。但是单集群无法应对网络故障或者数据中心故障导致的服务的不可用。跨地域的多集群架构能够达到跨机房、跨区域的容灾。
- 地域亲和性:尽管国内互联网一直在提速,但是处于带宽成本的考量,同一调用链的服务网络距离越近越好。服务的主调和被调部署在同一个地域内能够有效减少带宽成本;并且分而治之的方式让应用服务本区域的业务,也能有效缓解应用服务的压力。
多集群的主要攻克的难点就是跨集群的信息同步和跨集群网络连通方式。
- 跨集群网络连通方式一般的处理方式就是确保不同机房的网络相互可达,这也是最简单的方式。
- 跨集群的信息同步。多集群的服务实例调度,需要保证在多集群的资源同步的实时,将 pod 调度不同的集群中不会 pod pending 的情况。
- 定义专属的 API server:通过一套统一的中心化 API 来管理多集群以及机器资源。KubeFed 就是采用的这种方法,通过扩展 k8s API 对象来管理应用在跨集群的分布。
- 基于 Virtual Kubelet:Virtual Kubelet 本质上是允许我们冒充 Kubelet 的行为来管理 virtual node 的机制。这个 virtual node 的背后可以是任何物件,只要 virtual node 能够做到上报 node 状态、和 pod 的生命周期管理。
多集群的服务实例调度,需要保证在多集群的资源同步的实时,将 pod 调度不同的集群中不会 pod pending 的情况。控制平面的跨集群同步主要有两类方式:
- 定义专属的 API server:通过一套统一的中心化 API 来管理多集群以及机器资源。
- 基于 Virtual Kubelet:Virtual Kubelet 本质上是允许我们冒充 Kubelet 的行为来管理 virtual node 的机制。这个 virtual node 的背后可以是任何物件,只要 virtual node 能够做到上报 node 状态、和 pod 的生命周期管理。PS: 这导致后续干预多集群调度比较难,因为进行任何改动都不能超越kubelet 所提供的能力。
多云能力建设问题域总结要解决的几个问题
- 应用分发模型。
- 用户创建的Deployment 存在哪里?比如kubefed v2 部署Kubernetes资源需要熟悉一套的全新API,例如FederatedDeployment。
- 即用户创建的Deployment 的多个pod最终落在哪个集群中,如何表达这个诉求?是优先落在一个集群,还是各个集群都摊一点。
- 假如deployment有10个pod,两个cluster 分别运行2/8 个pod,用户创建的deployment 的status 等字段如何感知真实情况?如何方便的查看 deployment 当前在各个cluster的分布与状态。
- 分发时要考虑集群当前的可用资源情况, Karmada v1.3 新特性解读: 自定义资源模型
- 在不同的集群下发的模型怎样做到差异化?
- 怎样设计和解决在多集群的背景下,有状态服务的调度机制和访问机制?karmada FederatedHPA, MulitClusterIngress API。
- 多集群监控 阿里云注册集群+Prometheus 解决多云容器集群运维痛点 分布式云场景下的多集群监控方案最佳实践
- 多集群故障迁移 Karmada跨集群优雅故障迁移特性解析 主要包括发现故障、故障迁移、如何优雅故障迁移。
字节跳动多云演进及降本实践在分布式云原生平台上,为了支撑在线业务,提供了以下几种能力:
- 统一资源管理能力。这里包括多集群纳管能力,它可以连接多地域、多基础设施之上的集群,无缝接管业务在多种云上的存量集群,还有统一资源监管的能力,通过统一的控制链和界面,方便管理和调度资源。
- 统一应用管理。 统一的应用分发能力可以根据用户的策略、集群的特征、业务的层面和依赖关系,进行多样化的分发策略,让业务无需关心底层的细节。另外,为了连接不同云上的集群,还需要完全兼容现有的生态。如果在历史和业务层面上存在不兼容的问题,就会在接入过程中遇到挑战。因此,接管应用体系之后,还要提供更强的运维和治理能力。
- 统一应用观测, 通过对各种系统的集群层面上的统一收集,可以进行更强的感知。一旦遇到问题,除了集群本身具备的自我恢复能力,还可以通过智能化手段,让运维人员及时进行处理。
- 统一治理。为了解决地域性的稳定性问题,我们也提供了一些统一的授权管控、服务追踪、流量治理等能力,可以灵活地调配资源,保证业务的稳健运行。
clusternet
Clusternet - 新一代开源多集群管理与应用治理项目 Clusternet v0.5.0 重磅发布: 全面解决多集群应用分发的差异化配置难题
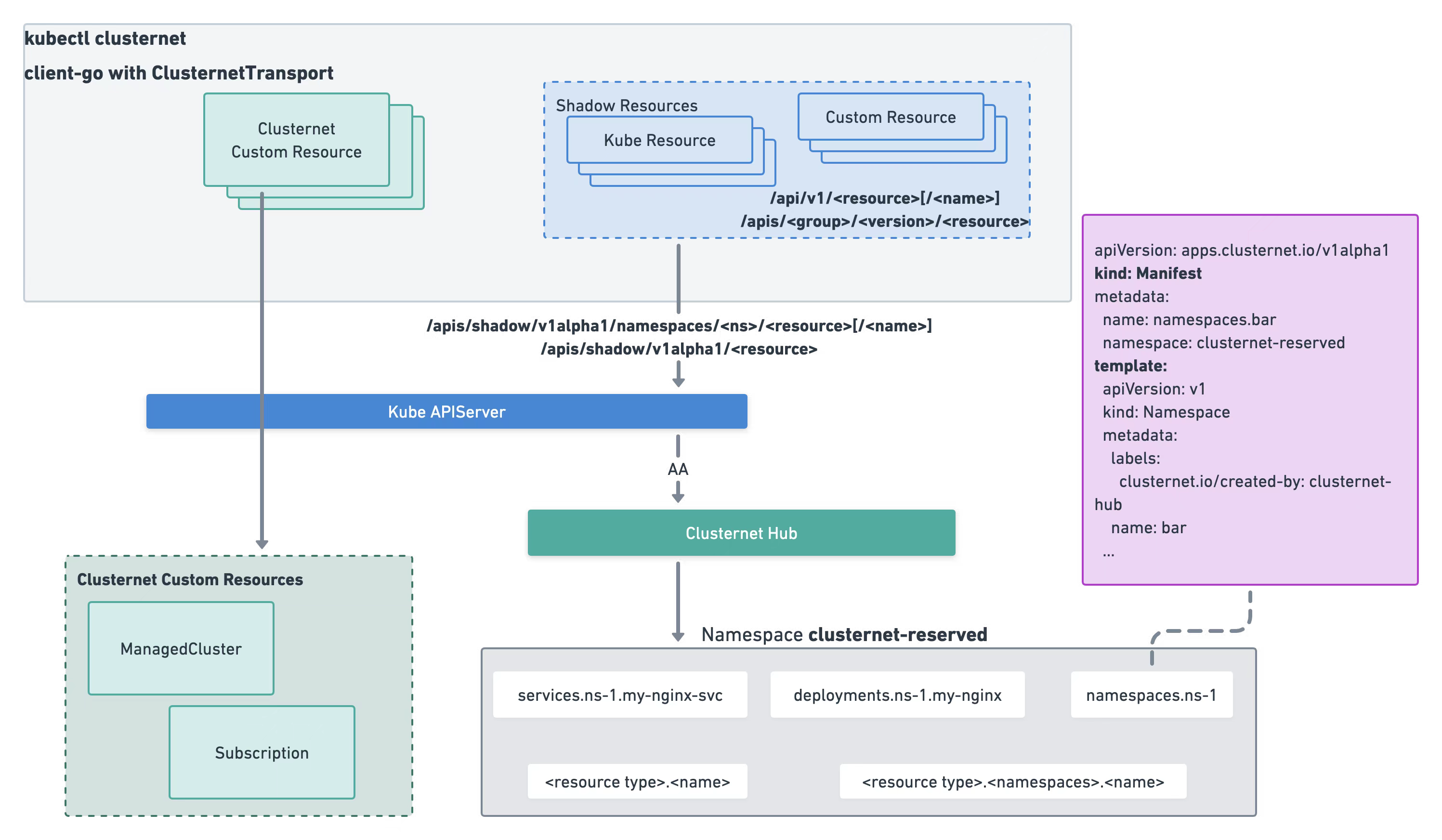
以创建Deployment 为例,请求url 前缀改为clusternet 的shadow api, 由clusternet 的agg apiserver 处理,agg 拿到deployment 后保存在了自定义 Manifest下(类似下图将 Namespace 对象挂在 Manifest 下),之后调度器根据 用户创建的Subscription 配置策略 决定应用分发(比如一个deployment 6个replicas,是spead 到2个集群,即按集群的空闲资源占比分配,还是binpack 到一个集群上)。hub 根据调度结果,拿到deployment 数据(底层涉及到 base 和 Description 等obj),通过目标cluster 对应的dynamic client在子集群真正的创建 deployment。
源码分析
clusternet
/cmd
/clusternet-agent
/clusternet-hub
/clusternet-scheduler
/pkg
/agent
/apis
/controllers // 不是单独运行的 k8s Controller ,只是封装了 infromer 各种crd 的逻辑,真正处理crd的处理逻辑 在hub 和agent 中
/apps
/feedinventory
/hub
/predictor
/scheduler
- hub 负责提供agg server 并维护 用户提交的obj 与内部的对象的转换,最终将用户提交的obj 分发到各个cluster 上。
- 自定义 REST 实现了 apiserver的 Creater 等接口
clusternet/pkg/registry/shadow/template/rest.go,由 InstallShadowAPIGroups 注入到agg 处理逻辑中。将 shadow api 传来的 deployment 改为创建Manifest。 - feedinventoryController.handleSubscription 将 deployment 需要的资源计算出来 写入到FeedInventory
- 自定义 REST 实现了 apiserver的 Creater 等接口
- Scheduler 监听Subscription,针对用户设定的应用分发策略计算cluster层面的调度结果。
clusternet/pkg/scheduler/algorithm/generic.go Scheduler.Run ==> scheduleOne ==> scheduleAlgorithm.Schedule // Step 1: Filter clusters. feasibleClusters, diagnosis, err := g.findClustersThatFitSubscription(ctx, fwk, state, sub) // Step 2: Predict max available replicas if necessary. availableList, err := predictReplicas(ctx, fwk, state, sub, finv, feasibleClusters) // Step 3: Prioritize clusters. priorityList, err := prioritizeClusters(ctx, fwk, state, sub, feasibleClusters, availableList) // selectClusters takes a prioritized list of clusters and then picks a fraction of clusters in a reservoir sampling manner from the clusters that had the highest score. clusters, err := g.selectClusters(ctx, state, priorityList, fwk, sub, finv) 最终将 targetClusters 写入到 subscription.status.bindingClusters 中 - Hub, clusternet 会给每个cluster 建一个namespace,分配到 该cluster 下的obj 都会有对应的 base 和 Description 对象,也在该namespace 下。cluster-xx namespace 对象本身label 会携带一些cluster的信息。
- Deployer.handleSubscription(此时调度结果 已经写入了subscription.status.bindingClusters) ==> populateBasesAndLocalizations 。为每一个cluster 创建 Subscription 对应的 Base 和 Localization
- Deployer.handleManifest ==> resyncBase ==> populateDescriptions ==> syncDescriptions。clusterId 会从 Subscription 一路传到 Description 中
- Deployer.handleDescription ==> createOrUpdateDescription ==> deployer.applyResourceWithRetry。拿到对应cluster的dynamicClient (根据clusterId) 在cluster 中创建deployment 对象。
# examples/dynamic-dividing-scheduling/subscription.yaml
apiVersion: apps.clusternet.io/v1alpha1
kind: Subscription
metadata:
name: dynamic-dividing-scheduling-demo
namespace: default
spec:
subscribers: # filter out a set of desired clusters
- clusterAffinity:
matchExpressions:
- key: clusters.clusternet.io/cluster-id
operator: Exists
schedulingStrategy: Dividing
dividingScheduling:
type: Dynamic
dynamicDividing:
strategy: Spread # currently we only support Spread dividing strategy
feeds: # defines all the resources to be deployed with
- apiVersion: v1
kind: Namespace
name: qux
- apiVersion: v1
kind: Service
name: my-nginx-svc
namespace: qux
- apiVersion: apps/v1 # with a total of 6 replicas
kind: Deployment
name: my-nginx
namespace: qux
status:
bindingClusters:
- clusternet-v7wzq/clusternet-cluster-bb2xp
- clusternet-wlf5b/clusternet-cluster-skxd4
- clusternet-bbf20/clusternet-cluster-aqx3b
desiredReleases: 6
replicas:
apps/v1/Deployment/qux/my-nginx: # 这里会生成一个 Localization 在cluster 范围更新deployment 的replicas
- 1
- 2
- 3
v1/Namespace/qux: []
v1/Service/qux/my-nginx-svc: []
scheduler 如何为 deployment 选择cluster ?
- hub, clusternet 里有一个 PluginFactory 定义了如何从 deployment 中parse deployment 需要的资源,feedinventoryController.handleSubscription 将 deployment 需要的资源计算出来 写入到FeedInventory
- scheduler 拿到 deployment name 对应的 FeedInventory,在predict 时 向agent 发出http 请求
/replicas/predict,agent 返回自己cluster 针对deployment 最多可以运行几个replicaspredictReplicas(ctx, fwk, state, sub, finv, feasibleClusters) prePredictStatus := fwk.RunPrePredictPlugins(ctx, state, sub, finv, clusters) func (pl *Predictor) Predict(_ context.Context, ...) replica, err2 := predictMaxAcceptableReplicas(httpClient, predictorAddress, feedOrder.ReplicaRequirements) 发出http 请求 /replicas/predict availableList, predictStatus := fwk.RunPredictPlugins(ctx, state, sub, finv, clusters, availableList)
Karmada
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1
---
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: example-override
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
targetCluster:
clusterNames:
- member1
labelSelector:
matchLabels:
failuredomain.kubernetes.io/region: dc1
overriders:
plaintext:
- path: /spec/template/spec/containers/0/image
operator: replace
value: 'dc-1.registry.io/nginx:1.17.0-alpine'
- path: /metadata/annotations
operator: add
value:
foo: bar
整体设计
karmada 对象部署相关的 crd 可分为
- 控制集群定义一个标准的k8s中原生API对象deployment,在member集群中实际部署的deployment会以此为模板进行创建。PS:因为控制集群没有 部署deploymentController,所以deployment 在控制集群就是表达一个静态数据。
- 用于设定策略的资源:PropagationPolicy,OverridePolicy(定义在特定member集群中具体修改deployment对象)。
- PropagationPolicy.spec.placement.clusterAffinity.clusterNames决定了对象需要被部署到哪些集群;
- PropagationPolicy.spec.resourceSelectors绑定需要部署的资源对象;
- PropagationPolicy.spec.replicaScheduling定义了deployment在集群中分发的方式
- 执行策略相关的资源:ResourceBinding,ClusterResourceBinding, Work。
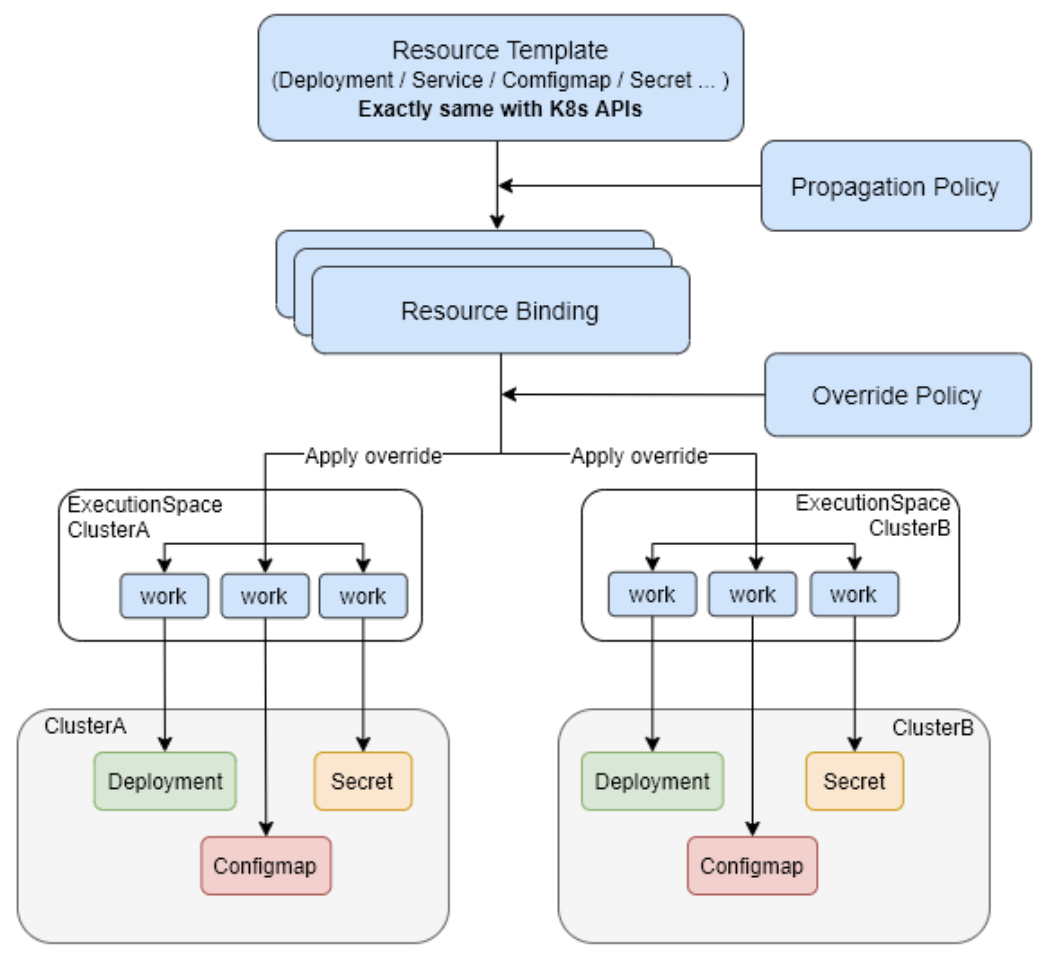
- Cluster Controller: attaches kubernetes clusters to Karmada for managing the lifecycle of the clusters by creating cluster objects.
- Policy Controller: watches PropagationPolicy objects. When a PropagationPolicy object is added, the controller selects a group of resources matching the resourceSelector and create ResourceBinding with each single resource object.
- Binding Controller: watches ResourceBinding objects and create a Work object corresponding to each cluster with a single resource manifest.
- Execution Controller: watches Work objects. When Work objects are created, the controller will distribute the resources to member clusters.
karmada 会为每一个分发的资源每个目标成员集群的执行命名空间(karmada-es-*)中创建一个 work。具体的说,BindingController 根据 Resource Binging 资源内容创建 work 资源到各个成员集群的执行命名空间, work 中描述了要分到目标集群的资源列表。被分发的资源不区分是自定义资源还是 kubernetes 内置资源先被转化为 Unstructured 类型的数据,然后在 woker 中以 JSON 字节流的形式保存,然后在 execution_controller 中再反序列化,解析出 GVR,通过 dynamicClusterClient 在目标成员集群中创建指定分发资源。
源码分析
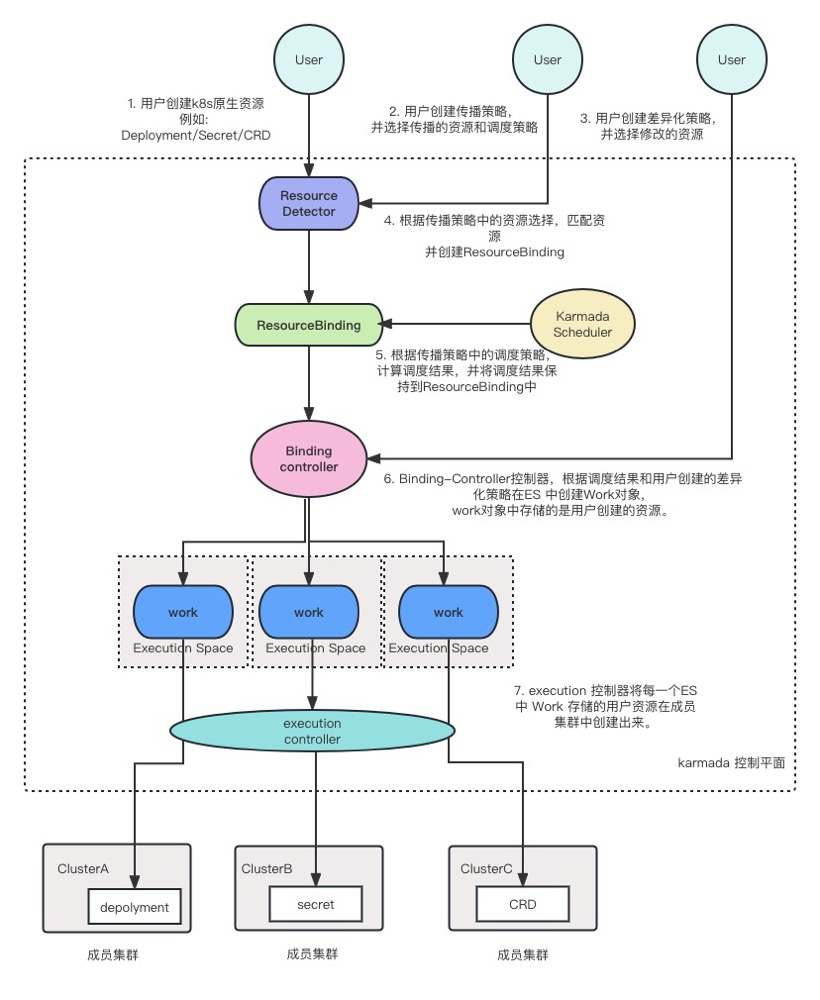
ResourceDetector 组件监听 用户创建的object,查找 object 匹配的 PropagationPolicy 并创建ResourceBinding
// ResourceDetector is a resource watcher which watches all resources and reconcile the events.
controllermanager.Run ==> ResourceDetector.Reconcile
object, err := d.GetUnstructuredObject(clusterWideKey)
propagationPolicy, err := d.LookForMatchedPolicy(object, clusterWideKey)
d.ApplyPolicy(object, clusterWideKey, propagationPolicy)
binding, err := d.BuildResourceBinding(object, objectKey, policyLabels, policy.Spec.PropagateDeps)
d.ResourceInterpreter.GetReplicas(object)
controllerutil.CreateOrUpdate(context.TODO(), d.Client, bindingCopy...)
Scheduler 监听 ResourceBinding,并根据调度策略 计算调度结果更新到 ResourceBinding 字段上
// ResourceBinding
Scheduler.Run ==> worker ==> scheduleNext ==> doSchedule ==> doScheduleBinding
err = s.scheduleResourceBinding(rb)
placement, placementStr, err := s.getPlacement(resourceBinding)
s.Algorithm.Schedule(..)
feasibleClusters, err := g.findClustersThatFit(ctx, g.scheduleFramework, placement, spec, clusterInfoSnapshot)
clustersScore, err := g.prioritizeClusters(ctx, g.scheduleFramework, placement, spec, feasibleClusters)
clusters, err := g.selectClusters(clustersScore, placement, spec)
clustersWithReplicas, err := g.assignReplicas(clusters, placement.ReplicaScheduling, spec)
s.patchScheduleResultForResourceBinding(resourceBinding, placementStr, scheduleResult.SuggestedClusters) // 设置到 newBinding.Spec.Clusters
s.patchBindingScheduleStatus(rb, condition)
ResourceBindingController 监听ResourceBinding 根据调度结果创建work 对象
ResourceBindingController.Reconcile ==> syncBinding
workload, err := helper.FetchWorkload(c.DynamicClient, c.InformerManager, c.RESTMapper, binding.Spec.Resource)
err = ensureWork(c.Client, c.ResourceInterpreter, workload, c.OverrideManager, binding, apiextensionsv1.NamespaceScoped)
targetClusters = bindingObj.Spec.Clusters
clonedWorkload, err = resourceInterpreter.ReviseReplica(clonedWorkload, desireReplicaInfos[targetCluster.Name])
cops, ops, err := overrideManager.ApplyOverridePolicies(clonedWorkload, targetCluster.Name)
helper.CreateOrUpdateWork(c, workMeta, clonedWorkload)
Kubernetes多集群管理利器:Karmada 控制器 K8s 多集群管理 – Karmada 调度器 多云环境下的资源调度:Karmada scheduler的框架和实现
集群调度
karmada调度策略想要实现,这三个组件必须了解karmada-scheduler 的主要作用就是将 k8s 原生 API 资源对象(包含 CRD 资源)调度到成员集群上。
karmada
/cmd
/scheduler
/main.go
/pkg
/scheduler
/cache
/core
/framework
/metrics
/event_handler.go
/scheduler.go
Scheduler.Run ==> worker ==> scheduleNext ==> doSchedule ==> doScheduleBinding,ClusterResourceBindings/ResourceBindings 的add和update,ClusterPropagationPolicies/PropagationPolicies 的update,Clusters的add/update/delete 事件都会 找到事件相关的 ClusterResourceBindings/ResourceBinding 加入到workqueue 来触发Schedule。实现了三种场景的调度:
- 分发资源时选择目标集群的规则变了
- 副本数变了,即扩缩容调度
- 故障恢复调度,当被调度的成员集群状态不正常时会触发重新调度
// karmada/pkg/scheduler/scheduler.go
func (s *Scheduler) doScheduleBinding(namespace, name string) (err error) {
rb, err := s.bindingLister.ResourceBindings(namespace).Get(name)
policyPlacement, policyPlacementStr, err := s.getPlacement(rb) // 作为下面几种情况的判断了解
// policy placement changed, need schedule
err = s.scheduleResourceBinding(rb)
// binding replicas changed, need reschedule
// Duplicated resources should always be scheduled. Note: non-workload is considered as duplicated even if scheduling type is divided.
// TODO(dddddai): reschedule bindings on cluster change
klog.V(3).Infof("Don't need to schedule ResourceBinding(%s/%s)", namespace, name)
return nil
}
func (s *Scheduler) scheduleResourceBinding(resourceBinding *workv1alpha2.ResourceBinding) (err error) {
placement, placementStr, err := s.getPlacement(resourceBinding)
scheduleResult, err := s.Algorithm.Schedule(context.TODO(), &placement, &resourceBinding.Spec, &core.ScheduleAlgorithmOption{EnableEmptyWorkloadPropagation: s.enableEmptyWorkloadPropagation})
return s.patchScheduleResultForResourceBinding(resourceBinding, placementStr, scheduleResult.SuggestedClusters)
}
对于一个 PropagationPolicy 示例
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: test-propagation
spec:
...
placement:
clusterAffinity:
clusterNames:
- member1
- member2
spreadConstraints: ## 限定调度结果只能在 1 个cluster 上
- spreadByField: cluster
maxGroups: 1
minGroups: 1
replicaScheduling:
replicaDivisionPreference: Weighted #划分副本策略
replicaSchedulingType: Divided #调度副本策略
调度过程除了通用的预选、优选外,包括集群调度特有的 分发限制 和 副本拆分策略。
- 预选/过滤,已有插件:APIInstalled/ClusterAffinity/SpreadConstraint/TaintToleration
- 优选/打分,已有插件:ClusterLocality
- 考虑 SpreadConstraint,选择资源足够运行crd 的 cluster集合,且满足 spreadConstraint的要求, 比如应用最多分发到2个cluster上。
- 考虑 ReplicaSchedulingStrategy,如果配了divided 分发策略,决定如何将crd 拆分到各个cluster的具体 replica
// karmada/pkg/scheduler/core/generic_scheduler.go
func (g *genericScheduler) Schedule(..., placement *policyv1alpha1.Placement, spec *.ResourceBindingSpec, scheduleAlgorithmOption) (ScheduleResult, error) {
clusterInfoSnapshot := g.schedulerCache.Snapshot()
if clusterInfoSnapshot.NumOfClusters() == 0 {
return result, fmt.Errorf("no clusters available to schedule")
}
// filter 逻辑
feasibleClusters, err := g.findClustersThatFit(ctx, g.scheduleFramework, placement, spec, clusterInfoSnapshot)
if len(feasibleClusters) == 0 {
return result, fmt.Errorf("no clusters fit")
}
klog.V(4).Infof("feasible clusters found: %v", feasibleClusters)
// score 逻辑
clustersScore, err := g.prioritizeClusters(ctx, g.scheduleFramework, placement, spec, feasibleClusters)
klog.V(4).Infof("feasible clusters scores: %v", clustersScore)
// selectClusters 先用 ReplicaEstimator 计算每一个cluster.AvailableReplicas,选择出一个cluster集合可以运行 crd,且满足 spreadConstraint的要求
clusters, err := g.selectClusters(clustersScore, placement, spec)
klog.V(4).Infof("selected clusters: %v", clusters)
// 根据分发策略 计算 选中的cluster 分领几个replica
clustersWithReplicas, err := g.assignReplicas(clusters, placement.ReplicaScheduling, spec)
if scheduleAlgorithmOption.EnableEmptyWorkloadPropagation {
clustersWithReplicas = attachZeroReplicasCluster(clusters, clustersWithReplicas)
}
result.SuggestedClusters = clustersWithReplicas
return result, nil
}
手动访问多个kubernetes 集群
- 一般情况,kubernetes 单独搭建在一个集群上,开发者通过开发机 或某一个跳板机上 通过kubectl 操作kubernetes,kubectl 会读取
~/.kube/config文件读取集群信息 - kubernetes 一般会有多个集群:测试环境(运行公司测试环境的服务),开发环境(用来验证新功能)==> developer 需要在本机 上使用kubectl 访问多个k8s集群
~/.kube/config 是一个yaml 文件,可以配置多个集群的信息
apiVersion: v1
kind: Config
clusters:
users:
contexts:
可以看到 几个核心配置都是数组
apiVersion: v1
kind: Config
clusters:
- cluster:
name: development
- cluster:
name: scratch
users:
- name: developer
- name: experimenter
contexts:
- context:
cluster: development
user: developer
name: dev-frontend
name: dev-frontend
- context:
cluster: scratch
user: experimenter
name: exp-scratch
其它
阿里
还在为多集群管理烦恼吗?OCM来啦! CNCF 沙箱项目 OCM Placement 多集群调度指南
其它: vivo大规模 Kubernetes 集群自动化运维实践 未读。
B站多云管理平台建设 多云管理不只是 多k8s 集群管理。
字节跳动开源KubeAdmiral:基于 K8s 的新一代多集群编排调度引擎 v1的KubeFed FederatedDeployment ==> v2 KubeAdmiral 迎合 Kubernetes 单集群用户的使用习惯,提供了原生 Kubernetes API 的支持。用户创建原生资源(如 Deployment)后,由 Federate Controller 将其自动转化为联邦内部对象供其他 controller 使用。KubeAdmiral 提供了 status 汇聚的能力,Status Aggregator 将多个成员集群中资源的 status 进行合并与融合,并写回原生资源,让用户无需感知多集群拓扑,就可以一目了然地观测到资源在整个联邦中的状态。
留下评论