JVM执行
前言
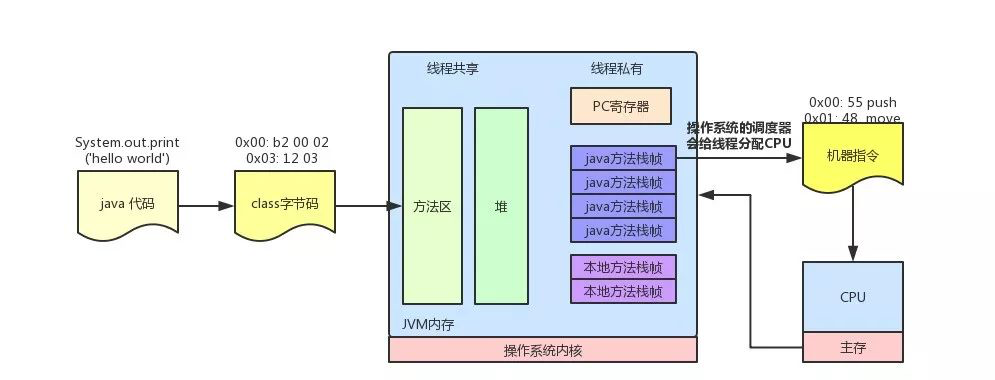
当class 文件加载解析完毕后,jvm 内存里是一系列 oop-kclass 对象放在约定的位置,在这些数据的支持下,结合执行引擎驱动cpu的执行。执行引擎以指令为单位读取Java字节码。字节码的每个命令都包含一个1字节的OpCode和附加的操作数。执行引擎获取一个OpCode并使用操作数执行任务,然后执行下一个OpCode。
如何进行方法调用
《jvm设计原理与实现》
- jvm 不参与java 程序的编译,只管运行,所以无法像C 一样在编译时确定每一个函数堆栈的空间大小。jvm 在传递jvm 函数参数时,传递的只不过是指针,因此在为java函数计算入参所需要的堆栈空间时,只需要入参的数量即可。
- 一个java 函数对应若干条字节码指令,一条jvm 字节码可以转换为若干条机器指令。物理机器能够自动取指,但无法对jvm字节码自动取指,因此对jvm 字节码的取指需要由jvm 自己去实现。
C++ 支持多态需要通过virtual 关键字,但java 不需要virtual,Java 类最终被表达为 JVM 内部的C++ 类,C++ 层面怎么知道Java 类中的哪些方法是虚函数?简单粗暴,将java 类中所有函数都视为是virtual 的。 正因如此,java 类的每个方法都可以晚绑定,在JVM 内部的C++ 层面,就必须维护一套函数分发表。
HotSpot 将Java class字节码文件中的方法信息(编译的结果不单纯是字节码指令)存储到内存中 methodOop+constMethodOop 中(方法名、返回值类型、入参、字节码指令、栈深、局部变量表、行号表等)。运行时,根据目标函数找到 instanceKlass ==> methodOop 实例,根据methodOop 找到constMethodOop,基于constMethodOop 定位到java 方法对应的字节码指令,并将首个字节码指令的内存地址保存到java 方法的栈帧中,jvm 通过jmp 指令跳转到这个地址,开始执行java 方法。
虚拟机如何执行一条字节码指令
jvm 与虚拟的物理机 执行指令的流程完全一样,都是循环往复的执行取指 ==> 译码 ==> 执行 ==> 取指的过程。JVM 内部所谓的 PC 计数器,其实是esi 集群器(x86平台)。当jvm 开始执行 main 函数时,esi 会指向main 第一条字节码指令的内存位置, 接着jvm 每执行完一条字节码指令便会对esi 执行一定的增量,从而让esi 总是指向即将要执行的字节码指令。在HotSpot内存也存在于CPU 内部类似的译码器,HotSpot 通常称为解释器。
如何将字节码指令翻译为机器指令?“查表”,每一个字节码关联一个c函数或者机器码序列。
字节码指令在 Intel x86 上对应的指令是什么呢?
执行引擎必须将OpCode/字节码更改为JVM中的机器可以执行的语言。字节码可以通过以下两种方式之一转化为合适的语言。
- 解释器:逐个读取,解释和执行字节码指令。当它逐个解释和执行指令时,它可以快速解释一个字节码,但是同时也只能相对缓慢的地执行解释结果,这是解释语言的缺点。
- JIT(实时)编译器:引入了JIT编译器来弥补解释器的缺点。执行引擎首先作为解释器运行,并在适当的时候,JIT编译器编译整个字节码以将其更改为本机代码。之后,执行引擎不再解释该方法,而是直接使用本机代码执行。本地代码中的执行比逐个解释指令要快得多。由于本机代码存储在高速缓存中,因此可以快速执行编译的代码。但是,JIT编译器编译代码需要花费更多的时间。因此,如果代码只执行一次,最好是选择解释而不是编译。
第一种是比较古老的字节码解释器,通过纯软件来模拟字节码的行为,效率很低。
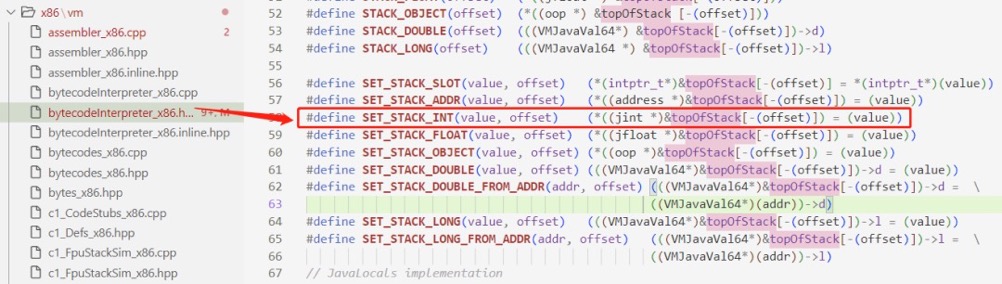
可以看到,实际上就是把数字 1 放入 topOfStack 数组中,这个数组就代表软件层面实现的 “操作数栈” 这个含义。可以理解为在软件层面实现了一个 “栈” 结构,即具体实现也是基于栈的。
第二种是模板解释器,即将每一个字节码指令和一个模板函数绑定,这个模板函数里会直接生成对应的机器码。
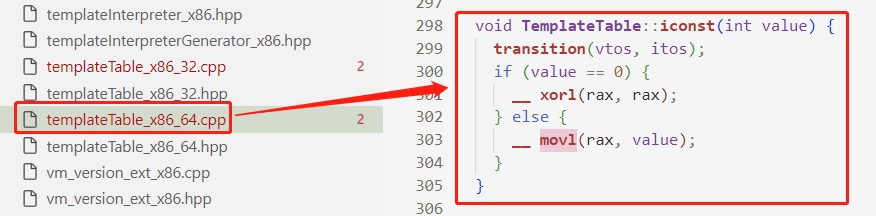
以iconst_1为例,iconst_1 会执行到 templateTable 里面的函数,如果立即数 value 为 0,也就是 iconst_0 指令将会生成 xorl 的机器码,即简单对寄存器进行清零操作。如果不为 0,那么将会生成 movl 的机器码。
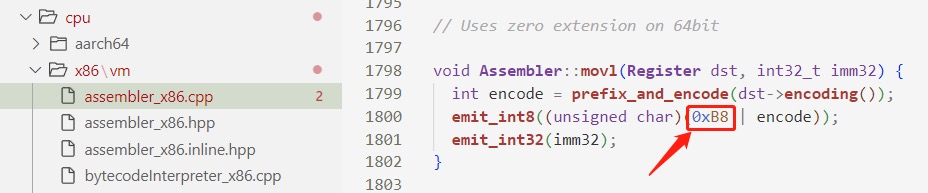
继续往里跟进,会发现最终就是使用 emit_int 函数直接往内存地址处写二进制数值,这里的 0xB8 是 x86 指令中的 Opcode 操作码,在 Intel 手册中可以看到,就是 mov 指令相关操作码的值。
在模板解释器中,最终翻译成 x86 实现后仅仅只是寄存器操作,没有通过内存,即具体实现是基于寄存器的。所以,虽然字节码这个 ISA 是基于栈来实现的,但具体再底层的实现是基于什么的,是不影响字节码是基于栈实现这个事实。
class字节码 ==> c/c++ ==> 机器码
使用C程序,将字节码的每一条指令,都逐行逐行地解释成C程序。当执行字节码的程序——JVM(Java虚拟机)程序本身被编译后,字节码指令所对应的C程序被一起编译成本地机器码,于是虚拟机在解释字节码指令时,自然就会执行对应的C程序(对应的本地机器码)。
int run(int code,int a ,int b){
if (code == 0x01){
return a + b;
}
return -1;
}
上面这个只能解释iadd=0x01字节码的解释器,第一代jvm就是这么干的。
// HOTSPOT/src/share/vm/intercepter/bytecodeintercepter.cpp
BytecodeInterpreter::run(interpreterState istate){
...
switch (opcode){
...
CASE(_istore):
CASE(_fstore):
// 实际上便是C++代码
SET_LOCALS_SLOT(STACK_SLOT(-1), pc[1]);
UPDATE_PC_AND_TOS_AND_CONTINUE(2, -1);
...
}
...
}
Java 并发——基石篇(中)Java 程序编译之后,会产生很多字节码指令,每一个字节码指令在 JVM 底层执行的时候又会变成一堆 C 代码,这一堆 C 代码在编译之后又会变成很多的机器指令,这样一来,我们的 java 代码最终到机器指令一层,所产生的机器指令将是指数级的,因此就导致了 Java 执行效率非常低下。
模版执行器:class字节码 ==> 机器码
怎么优化这个问题呢?字节码是肯定不能动的,因为 JVM 的一处编写,到处运行的梦想就是靠它完成的。其实,我们会发现,问题的根本就在于 Java 和机器指令之间隔了一层 C/C++,而例如 GCC 之类的编译器又不能做到绝对的智能编译,所产生的机器码效率仍然不是非常高。因此,我们会想,能不能跳过 C/C++ 这个层次,直接将 java 字节码和本地机器码进行一个对应呢?是的!可以的!HotSpot 工程师们早就想到了,因此早期的解释执行器很快就被废弃了,转而采用模版执行器。什么是模版执行器,顾名思义,模版就是将每一个 java 字节码通过「人工手动」的方式编写为固定模式的机器指令,执行字节码时直接跳转到对应的一串机器码执行。
JIT:C 支持动态执行 机器码
char* 可以认为是一个字符串的开始地址,也可以理解为一个二维字符数组的首地址。C语言在编译时,C函数将被直接编译为机器指令,而这个函数指针将直接指向这段机器指令的首地址。于是可以打一个插边球,在源码编译阶段就定义好一段机器指令,然后直接将一个C函数指针指向这段机器指令的首地址。从而间接实现C语言直接调用机器指令的目的。
/*
* 机器码,对应下面函数的功能:
* int foo(int a){
* return a + 2;
* }
*/
uint8_t machine_code[] = {
0x55, 0x48, 0x89, 0xe5,
0x8d, 0x47, 0x02, 0x5d, 0xc3
};
/*
* 执行动态生成的机器码。
*/
int main(int argc, char **argv) {
//分配一块内存,设置权限为读和写
void *mem = mmap(NULL, sizeof(machine_code), PROT_READ | PROT_WRITE,
MAP_ANONYMOUS | MAP_PRIVATE, -1, 0);
if (mem == MAP_FAILED) {
perror("mmap");
return 1;
}
//把机器码写到刚才的内存中
memcpy(mem, machine_code, sizeof(machine_code));
//把这块内存的权限改为读和执行
if (mprotect(mem, sizeof(machine_code), PROT_READ | PROT_EXEC) == -1) {
perror("mprotect");
return 2;
}
//用一个函数指针指向这块内存,并执行它
int32_t(*fn)(int32_t) = (int32_t(*)(int32_t)) mem;
int32_t result = fn(1);
printf("result = %d\n", result);
//释放这块内存
if (munmap(mem, sizeof(machine_code)) == -1) {
perror("munmap");
return 3;
}
return 0;
}
《编程高手必须的内存知识》JVM 在运行之初将 class 文件加载进内存,然后就开始解释执行。如果一个函数被执行多次,JVM 就会认为这个函数是一个热点 (hotspot) 函数,然后就将它翻译成机器码执行。
- JIT是申请一块既有写权限又有执行权限的内存,然后把你要编译的 Java 方法,翻译成机器码,写入到这块内存里。当再需要调用原来的 Java 方法时,就转向调用这块内存。
-
基于采样的编译优化和退优化,下面是一个 C 语言编译器没有办法优化,但是 JIT 编译却能进一步优化的例子。C 编译器无法知道在第 9 行 b 的真实取值是什么。只能严格按照这个函数的逻辑去生成比较,跳转,赋值等等
public static int test(boolean flag) { int b = 0; if (flag) { b = 3; } else { b = 2; } return b + 4; }JIT 编译器在开始之前,test 方法是由解释器执行的。解释器一边执行,一边会统计 flag 的取值,这种统计就叫做性能采样(Profiling)。当 JIT 编译器发现,test 方法被调用了 500 次(这个阈值可以以 JVM 参数指定),每一次 flag 的值都是 true,那它就可以合理地猜测,下一次可能还是 true,它就会把 test 方法优化成这个样子:
public static int test(boolean flag) { if (!flag) deoptimize() // 由 JIT 编译器退回到解释器进行执行 return 7; }
本地编译
对于C
int add(int a,int b){
return a+b;
}
// 本地编译后的机器码
push1 %ebp
movl%esp %ebp
movl12(%ebp) %eax
movl8(%ebp) %edx
addl%edx %eax
popl%ebp
ret
对于 java
Class A{
int add(int a,int b){
return a+b;
}
}
// 本地编译后的字节码, 每一个字节码都会对应一大堆机器指令
iload_1
iload_2
iadd
ireturn
中间语言由于其本身不能直接被CPU执行,为了能够被CPU执行,中间语言在完成同样一个功能时,需要准备更多便于自我管理的上下文环境,最后才能执行目标机器指令。准备上下文环境最终也是依靠机器码去实现,因此中间语言最终便生成了更多机器码,当然执行效率就降低了。
基于栈的虚拟机
为什么 JVM 叫做基于栈的 RISC 虚拟机说 JVM 是基于栈的虚拟机,指的是 JVM 所支持的指令集架构 ISA 是基于栈的,即字节码是基于栈的指令集架构。
- 有了指令集架构ISA这层抽象,我们就无需关心其背后的实现是虚拟机还是物理机,甚至假如实际的执行是基于寄存器实现的,但指令集架构里是基于栈的,我们也可以说这套指令集架构是基于栈的。
- 对于 JVM 这台虚拟计算机来说,字节码就是它的 ISA,它的官方手册就是:Java Language and Virtual Machine Specifications。字节码指令的数量非常少,且大部分是零地址指令,即指令长度大部分是固定的 1 字节,所以是典型的 RISC 指令集架构。
虚拟机的设计有两种技术:一是基于栈的虚拟机;二是基于寄存器的虚拟机。java是一种跨平台的编程语言,为了跨平台,jvm抽象出了一套内存模型和基于栈的解释器,进而创建一套在该模型基础上运行的字节码指令(零地址的指令集)。为了跨平台,不能假定平台特性,因此抽象出一个新的层次来屏蔽平台特性,因此推出了基于栈的解释器,与以往基于寄存器的cpu执行有所区别。操作数栈在java 方法的栈帧中,随栈帧一起销毁。
| 基于栈的虚拟机 | 基于寄存器的虚拟机 | |
|---|---|---|
| 操作数 | 指令的操作数是由栈确定的,我们不需要为每个操作数显式地指定存储位置 | 基于寄存器的虚拟机的运行机制跟机器码的运行机制是差不多的,它的指令要显式地指出操作数的位置(寄存器或内存地址) |
| 优点 | 指令可以比较短,指令生成也比较容易 | 可以更充分地利用寄存器来保存中间值,从而可以进行更多的优化 |
| 典型代表 | jvm | Google 公司为 Android 开发的 Dalvik 虚拟机和 Lua 语言的虚拟机 |
栈机并不是不用寄存器,实际上,操作数栈是可以基于寄存器实现的,寄存器放不下的再溢出到内存里。只不过栈机的每条指令,只能操作栈顶部的几个操作数,所以也就没有办法访问其它寄存器,实现更多的优化。
Virtual Machine Showdown: Stack Versus Registers
虚拟机随谈(一):解释器,树遍历解释器,基于栈与基于寄存器,大杂烩
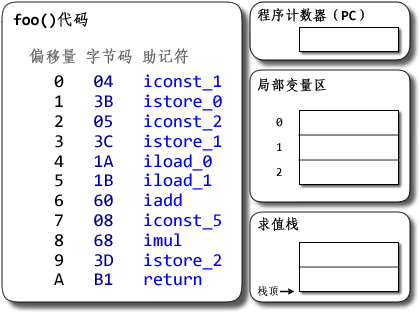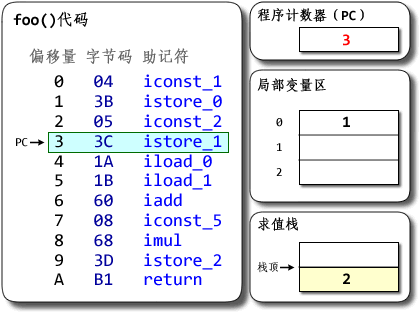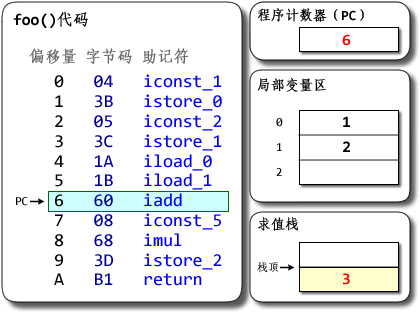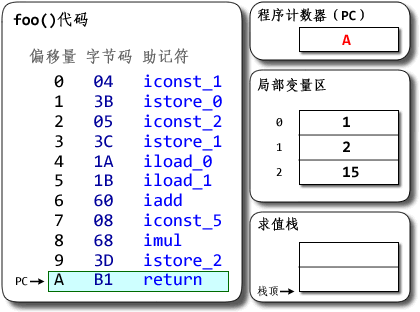
public class MyClass {
public int foo(int a){
return a + 3;
}
}
翻译后的部分字节码
public int foo(int);
Code:
0: iload_1 //把下标为1的本地变量入栈
1: iconst_3 //把常数3入栈
2: iadd //执行加法操作
3: ireturn //返回
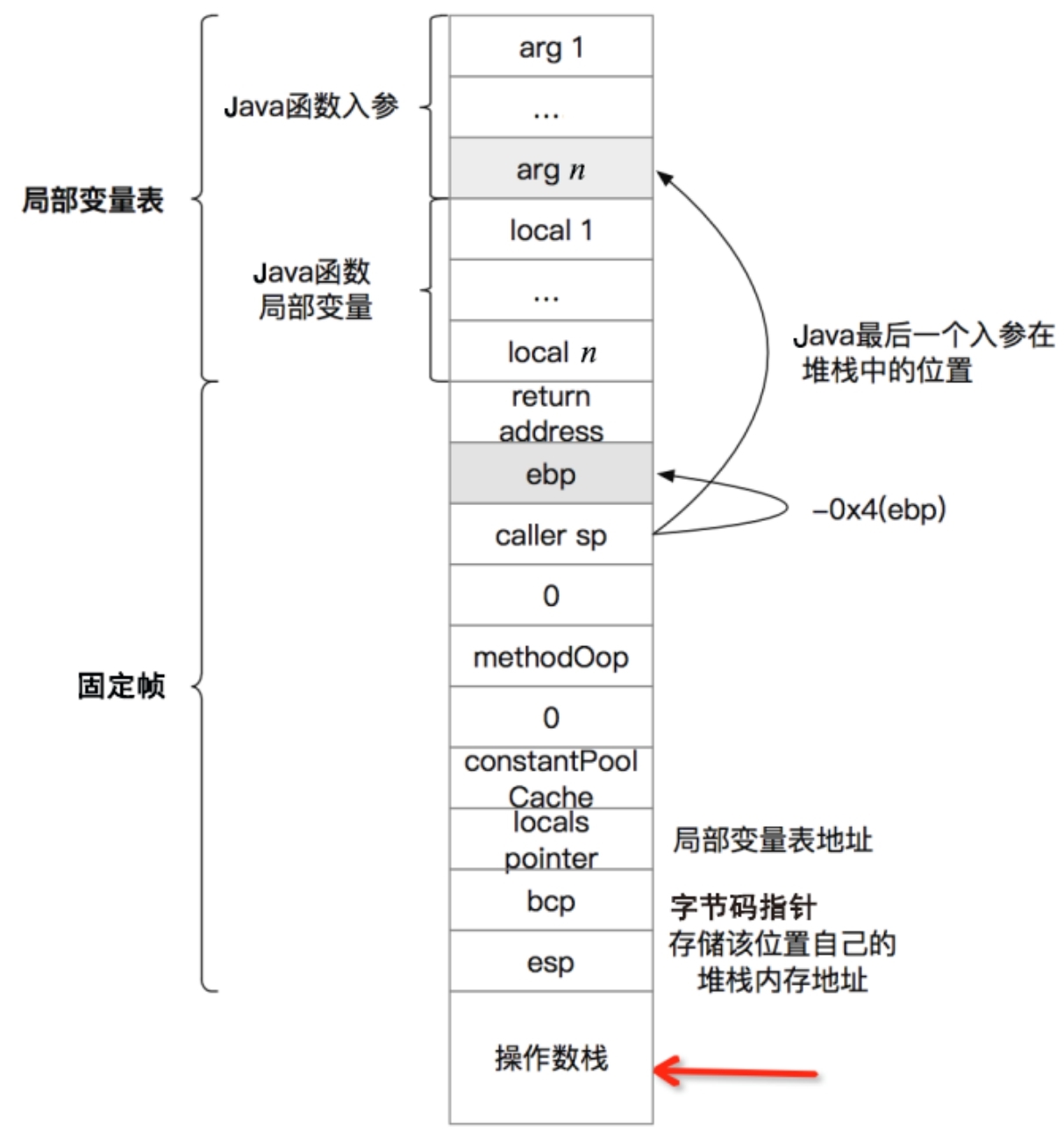
虚拟机的一个通用优势:栈/寄存器 可以每个线程一份,一直存在内存中。对于传统cpu执行,线程之间共用的寄存器,在线程切换时,借助了pcb(进程控制块或线程控制块,存储在线程数据所在内存页中),pcb保存了现场环境,比如寄存器数据。轮到某个线程执行时,恢复现场环境,为寄存器赋上pcb对应的值,cpu按照pc指向的指令的执行。而在jvm体系中,每个线程的栈空间是私有的,栈一直在内存中(无论其对应的线程是否正在执行),轮到某个线程执行时,线程对应的栈(确切的说是栈顶的栈帧)成为“当前栈”(无需重新初始化),执行pc指向的方法区中的指令。
每一个JavaThread都有一个JavaFrameAnchor,即最后一个调用栈的sp、fp。通过这两个值可以构造栈帧结构, 并根据栈帧的内容遍历整个JavaThread运行时的所有调用链。PS:我们说java 可以print 异常栈,arthas 可以展示方法的调用链、正在运行的方法的参数 都是以栈帧的这些数据存在为基础的。
多态的实现
C++ 中多态的实现:C++ 在类实例对象中嵌入虚函数表vtable(分配在对象实例的起始位置),就是一个普通的表,存储方法指针。C++ 的vtable 在编译时编程 分析和 构建。
java 类在jvm 内部对应的对象是instanceKlass,在jvm 加载Java 类的过程中,会动态解析java 类的方法进而构建出一个vtable,并将vtable 分配到instanceKlass 的末尾。vtable 每一个位置存放一个指针,指向内存中对应methodOop 的内存首地址。如果一个java 类继承了父类,则该java 类会直接继承父类的vtable。如果该java 类重写了父类方法,则jvm会更新 vtable 中被重写方法的指针,使其指向子类该方法的内存地址。如果不是对父类方法的重写,则jvm 会向vtable 中插入一个新的元素。Java中所有类都会继承自Object,Object 有5个虚方法,所以一个java 类不声明任何方法,其vtable 长度为5。
java 字节码中方法的调用分为4种指令
- invokevirtual,最常见,包含virtual dispatch机制
- invokespecial,调用private 和构造方法, 绕过了virtual dispatch
- invokeInterface,与invokevirtual 类似
- invokestatic,调用静态方法
重排序
为什么会出现重排序
重排序的影响
主要体现在两个方面,详见Java内存访问重排序的研究
-
对代码执行的影响
常见的是,一段未经保护的代码,因为多线程的影响可能会乱序输出。少见的是,重排序也会导致乱序输出。
-
对编译器、runtime的影响,这体现在两个方面:
- 运行期的重排序是完全不可控的,jvm经过封装,要保证某些场景不可重排序(比如数据依赖场景下)。提炼成理论就是:happens-before规则(参见《Java并发编程实践》章节16.1),Happens-before的前后两个操作不会被重排序且后者对前者的内存可见。
- 提供一些关键字(主要是加锁、解锁),也就是允许用户介入某段代码是否可以重排序。这也是“which are intended to help the programmer describe a program’s concurrency requirements to the compiler” 的部分含义所在。
Java内存访问重排序的研究文中提到,内存可见性问题也可以视为重排序的一种。比如,在时刻a,cpu将数据写入到memory bank,在时刻b,同步到内存。cpu认为指令在时刻a执行完毕,我们呢,则认为代码在时刻b执行完毕。
其它
《编程高手必须的内存知识》Java 字节码是一种基于栈的中间格式,每一条字节码的语义都是由 Java 语言规范规定的,不管在什么平台上,模拟栈和变量表这两个数据结构都是相同的。本质上,字节码就是对模拟栈和变量表不断地进行操作。这种逐条取出字节码,逐条执行的方式被称为解释执行。对字节码进行解释执行的执行器叫做解释器。解释器的运行效率肯定很差,对于加法操作,C++ 的加法语句会被翻译成加法指令,只需要一条就够了。但是 Java 的加法语句却要经历两次出栈操作、一次加法操作和一次入栈操作。PS: 字节码有点像dsl
留下评论