那些年追过的并发
简介
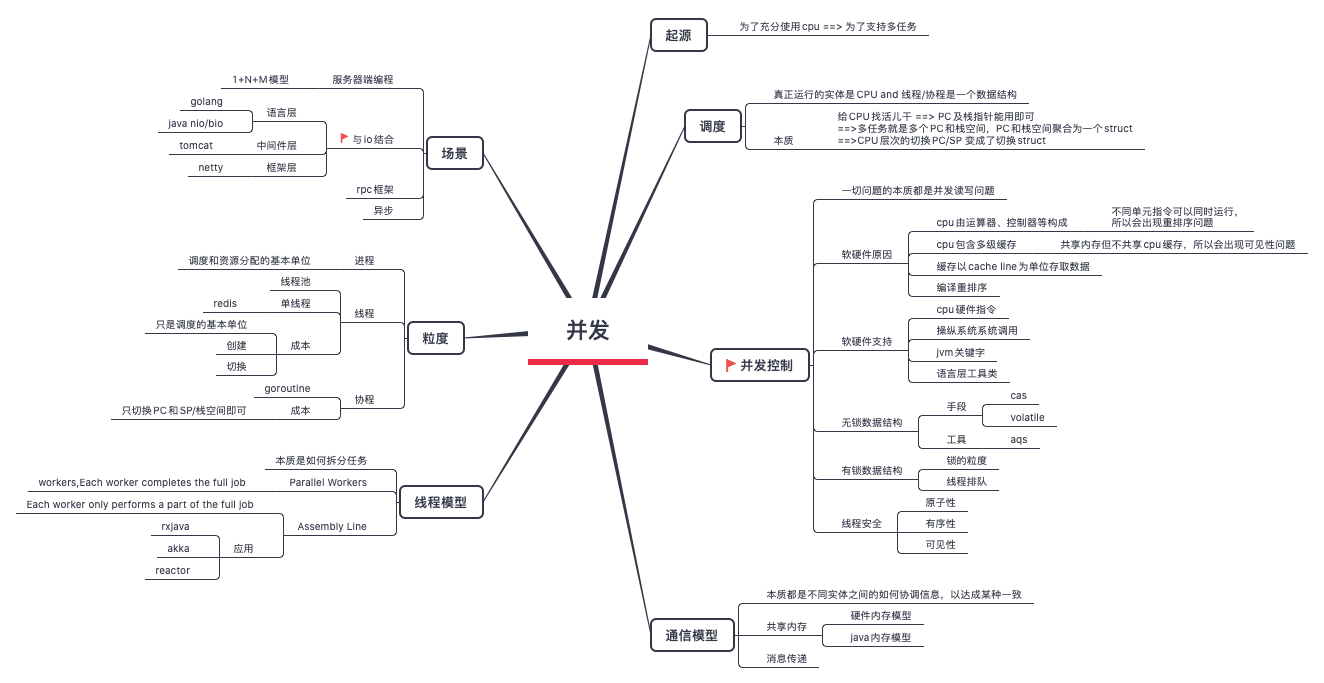
并发模型
多线程设计模式/《Concurrency Models》笔记
高伸缩性系统:我最早使用类似汇编语言进行编程,在那个层面上,所有变量都是全局的,而且没有奢侈的结构化控制流语句。你无拘无束,随时可能犯错,一旦做出修改,维护人员也不易理解代码。早期的BASIC 有FOR、GOSUB、RETURN 语句,依然没有局部变量概念,GOSUB不支持传递参数。后来我努力建立“结构化编程”概念(局部变量、函数参数等开始支持了),下一个挑战是面向对象,说到底,面向对象是具有更多约束和多态的结构化编程,信息被隐藏起来了,我不得不重新思考把数据放在什么地方,有些时候必须重构代码才能获取封装在一个对象中的信息。函数式编程又增加了其它约束,“不可变”是最难接受的概念。 然而一旦习惯了这些约束,就会发现一件幸事,写出的代码容易理解多了。缺乏约束是基于线程和锁进行并发编程的主要问题
- 线程可以访问任意可变的数据结构
- 调度程序几乎可以在任何时刻中断线程,包括执行a+=1 这种简单操作的过程中。在源码表达式层面,原子操作十分少见。
- 锁往往是建议性的,在更新共享的数据结构之前,你忘了持有锁,线程也会继续更新 相比之下,actor模式可以实施一些约束
- actor可以有内部状态,但不能与其它actor共享
- actor之间通过收发消息进行通信
- 消息中只能存有数据的副本,不能引用可变的数据
- 一个actor 一次只能处理一个消息,对于单个actor 没有并发执行的概念。
并发读写
《软件架构设计》要让各式各样的业务功能与逻辑最终在计算机系统里实现,只能通过两种操作:读和写。
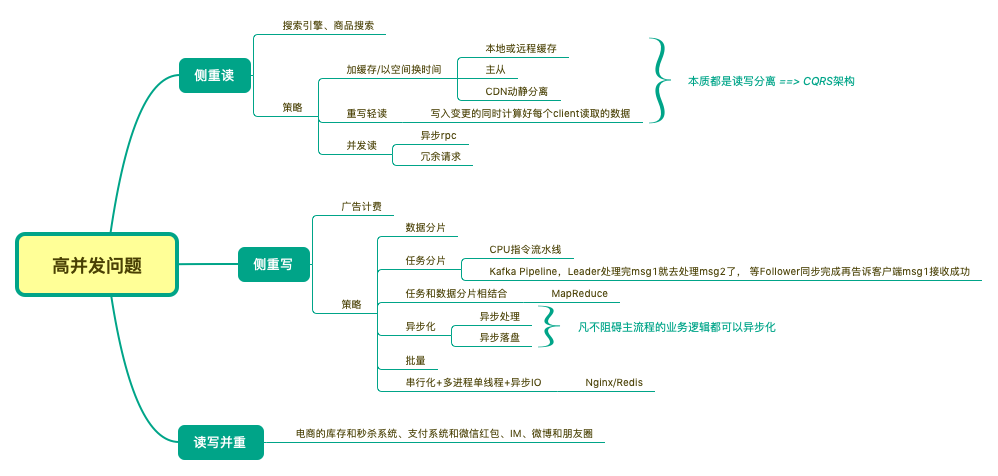
并发竞争的几种处理
- 靠锁把并发搞成顺序的
- 发现有人在操作数据,就先去干点别的,比如自旋、sleep 一会儿
- 发现有人在操作数据,找个老版本数据先用着,比如mvcc
- 相办法不共享数据
异步
服务器端编程
分布式锁
如何使用Redis实现分布式锁?为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。基本思路是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,就认为客户端成功地获得分布式锁了,否则加锁失败。
聊聊分布式锁未读。
- 单体应用:使用本地锁 + 数据库中的行锁解决
- 分布式应用:
- 使用数据库中的乐观锁,加一个 version 字段,利用CAS来实现,会导致大量的 update 失败
- 使用数据库维护一张锁的表 + 悲观锁 select,使用 select for update 实现。
- 使用Redis 的 setNX实现分布式锁
- 使用zookeeper的watcher + 有序临时节点来实现可阻塞的分布式锁
- 使用Redisson框架内的分布式锁来实现
- 使用curator 框架内的分布式锁来实现
解决高并发的方法论
技术方案设计的方法论及案例分享高并发的矛盾就是有限的资源对大量的请求,解决了这个矛盾就解决了高并发的问题。接下来就是平衡这对矛盾,一般是采用”中和”的思想,就像中医治病:寒病用热药、热病用寒药,因此就会站在资源和请求两个维度去思考。资源能不能变多:常见的有水平扩展;资源能不能变强:常见的是性能优化,性能优化又会分成前端优化、网络优化、计算优化、存储优化、程序优化……。请求能不能减少呢?比如通过答题错峰,合并请求等等
留下评论