gc的基本原理
简介
内存回收/gc
int * func(void) {
int num = 1234;
/* ... */
return #
}
在各种流传甚广的 C 语言葵花宝典里,一般都有这么一条神秘的规则,不能返回局部变量。当函数返回后,函数的栈帧(stack frame)就会被销毁,引用了被销毁位置的内存,轻则数据错乱,重则 segmentation fault。依赖人去处理复杂的对象内存管理的问题是不科学、不合理的。C 和 C++ 程序员已经被折磨了数十年,我们不应该再重蹈覆辙了,于是,后来的很多编程语言就用上垃圾回收(GC)机制。
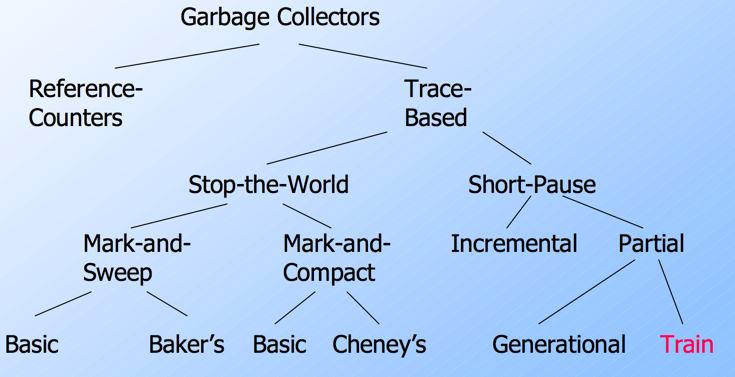
- reference counting
-
tracing 包含两个部分:gc root;gc heap。 有两种风格:copying gc;mark-sweep gc。
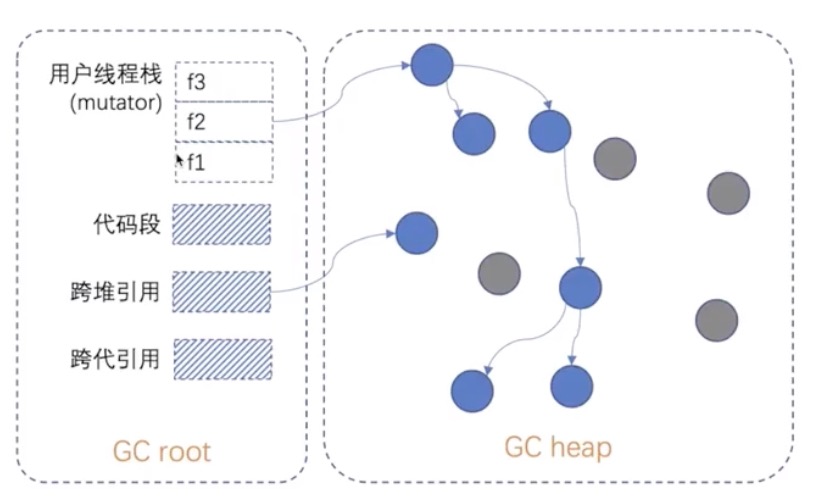
基本组件
- 精确扫描各种 gc root的 引用
- 精确扫描 gc heap中的引用
- 扫描过程中 对象图发生了变化怎么办
- 何时触发gc 对应用影响最小
- 让多个应用线程停顿下来
- 处理Finalizer
- 记录跨堆、跨代引用
- cgo/jni 访问gc heap
更多挑战
- 最小化/去除stw阶段
- partial stack scan
- work stealing
- read/write barrier 消除
- footprint 控制
- 并发扫描线程栈
- gc 硬件的设计
对象头是实现自动内存管理的关键元信息,内存分配器和垃圾收集器都会访问对象头以获取相关的信息。不同的自动内存管理机制会在对象头中存储不同的信息,使用垃圾回收的编程语言会存储标记位 MarkBit/MarkWord,例如:Java 和 Go 语言;使用自动引用计数的会在对象头中存储引用计数 RefCount,例如:Objective-C。编程语言会选择将对象头与对象存储在一起,不过因为对象头的存储可能影响数据访问的局部性,所以有些编程语言可能会单独开辟一片内存空间来存储对象头并通过内存地址建立两者之间的隐式联系。
gc 策略
- 基于引用计数的垃圾收集器是直接垃圾收集器,当我们改变对象之间的引用关系时会修改对象之间的引用计数,每个对象的引用计数都记录了当前有多少个对象指向了该对象,当对象的引用计数归零时,当前对象就会被自动释放。基于引用计数的垃圾收集是在用户程序运行期间实时发生的,所以在理论上也就不存在 STW 或者明显地垃圾回收暂停。缺点是递归的对象回收(一个对象引用计数归0 ==> 回收 ==> 其引用的对象都归0并回收)和循环引用。引用计数垃圾收集器是一种非移动(Non-moving)的垃圾回收策略,它在回收内存的过程中不会移动已有的对象,很多编程语言都会对工程师直接暴露内存的指针,所以 C、C++ 以及 Objective-C 等编程语言其实都可以使用引用计数来解决内存管理的问题。
- 标记清除。分代算法中一般用于老年代
- 一般需要在对象头中加入表示对象存活的标记位(Mark Bit),也可以 使用位图(Bitmap)标记
- 一般会使用基于空闲链表的分配器,因为对象在不被使用时会被就地回收,所以长时间运行的程序会出现很多内存碎片
- 标记压缩。会把活跃的对象重新整理,从头开始排列,减少内存碎片。一种 moving 收集器,如果编程语言支持使用指针访问对象,那么我们就无法使用该算法。
- 标记复制
- 复制阶段 — 从 GC 根节点出发遍历内存中的对象,将发现的存活对象迁移到右侧的内存中;
- 转发阶段 — 在原始对象的对象头或者在原位置设置新对象的转发地址(Forwarding Address),如果其他对象引用了该对象可以从转发地址转到新的地址;
- 修复指针 — 遍历当前对象持有的引用,如果引用指向了左侧堆中的对象,回到第一步迁移发现的新对象;
- 交换阶段 — 当内存中不存在需要迁移的对象之后,交换左右两侧的内存区域;
高级策略
- 分代垃圾收集。也是一种 moving 收集器
- 基于弱分代假设(Weak Generational Hypothesis)上 —— 大多数的对象会在生成后马上变成垃圾
- 常见的分代垃圾回收会将堆分成青年代(Young、Eden)和老年代(Old、Tenured)。为了处理分代垃圾回收的跨代引用,我们需要解决两个问题,分别是如何识别堆中的跨代引用以及如何存储识别的跨代引用,在通常情况下我们会使用写屏障(Write Barrier)识别跨代引用并使用卡表(Card Table)存储相关的数据。
- 卡表与位图比较相似,它也由一系列的比特位组成,其中每一个比特位都对应着老年区中的一块内存,如果该内存中的对象存在指向青年代对象的指针,那么这块内存在卡表中就会被标记,当触发 Minor GC 循环时,除了从根对象遍历青年代堆之外,我们还会从卡表标记区域内的全部老年代对象开始遍历青年代。
- 增量并发收集器。今天的计算机往往都是多核的处理器,有条件在用户程序执行时并发标记和清除垃圾
- 需要使用屏障技术保证垃圾收集的正确性;与此同时,应用程序也不能等到内存溢出时触发垃圾收集,因为当内存不足时,应用程序已经无法分配内存,这与直接暂停程序没有什么区别
- 增量式的垃圾收集需要与三色标记法一起使用,为了保证垃圾收集的正确性,我们需要在垃圾收集开始前打开写屏障,这样用户程序对内存的修改都会先经过写屏障的处理,保证了堆内存中对象关系的强三色不变性或者弱三色不变性。
- 用户程序可能在标记执行的过程中修改对象的指针(改变引用关系),所以三色标记清除算法本身是不可以并发或者增量执行的,它仍然需要 STW。想要并发或者增量地标记对象还是需要使用屏障技术。
内存屏障技术是一种屏障指令,它可以让 CPU 或者编译器在执行内存相关操作时遵循特定的约束,目前的多数的现代处理器都会乱序执行指令以最大化性能,但是该技术能够保证代码对内存操作的顺序性,在内存屏障前执行的操作一定会先于内存屏障后执行的操作。垃圾收集中的屏障技术更像是一个钩子方法,它是在用户程序读取对象、创建新对象以及更新对象指针时执行的一段代码,根据操作类型的不同,我们可以将它们分成读屏障(Read barrier)和写屏障(Write barrier)两种,因为读屏障需要在读操作中加入代码片段,对用户程序的性能影响很大,所以编程语言往往都会采用写屏障保证三色不变性。写屏障是当对象之间的指针发生改变时调用的代码片段。PS:内存屏障保障指令有序执行 ==> 编译器针对类似*slot = ptr代码A 插入内存屏障及代码片段B ==> 可以保证代码片段B 在A 之前执行。
垃圾回收:如何避免内存泄露? 未整理。
最基本的 mark-and-sweep 算法伪代码
mutator 通过 new 函数来申请内存
new():
ref = allocate()
if ref == null
collect()
ref = allocate()
if ref == null
error "Out of memory"
return ref
collect 分为mark 和 sweep 两个基本步骤
atomic collect(): // 这里 atomic 表明 gc 是原子性的,mutator 需要暂停
markFromRoots()
sweep(heapStart, heapEnd)
从roots 对象开始mark
markFromRoots():
initialize(worklist)
for each reference in Roots // Roots 表示所有根对象,比如全局对象,stack 中的对象
if ref != null && !isMarked(reference)
setMarked(reference)
add(worklist, reference)
mark() // mark 也可以放在循环外面
initialize():
// 对于单线程的collector 来说,可以用队列实现 worklist
worklist = emptyQueue()
//如果 worklist 是队列,那么 mark 采用的是 BFS(广度优先搜索)方式来遍历引用树
mark():
while !isEmpty(worklist):
ref = remove(worklist) // 从 worklist 中取出第一个元素
for each field in Pointers(ref) // Pointers(obj) 返回一个object的所有属性,可能是数据,对象,指向其他对象的指针
child = *field
if child != null && !isMarked(child)
setMarked(child)
add(worklist, child)
sweep逻辑,实质也是调用free
sweep(start, end):
scan = start
while scan < end
if isMarked(scan)
unsetMarked(scan)
else
free(scan)
scan = nextObject(scan)
其他
留下评论