openkruise学习
简介
把 k8s 比喻为京东网站,提供的是平台的能力,Openkruise 可以看做是在京东开的第三方店铺。 站在平台层面,Deployment和CloneSet 都是店家,共同享用平台的基础能力。
Kubernetes的价值与不足
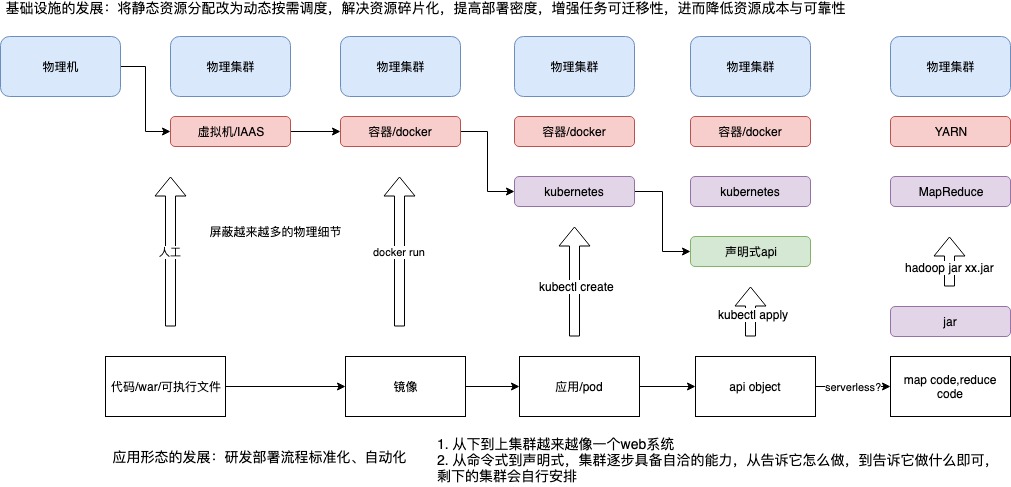
docker 让镜像和容器融合在一起,docker run 扣动扳机,实现镜像到 容器的转变。但docker run 仍然有太多要表述的,比如docker run的各种参数: 资源、网络、存储等,“一个容器一个服务”本身也不够反应应用的复杂性(或者 说还需要额外的信息 描述容器之间的关系,比如--link)。
我们学习linux的时候,知道linux 提供了一种抽象:一切皆文件。没有人会质疑基本单元为何是文件不是磁盘块?linux 还提供了一种抽象叫“进程”,没有人会好奇为何 linux 不让你直接操纵cpu 和 内存。一个复杂的系统,最终会在某个层面收敛起来,就好像一个web系统,搞到最后就是一系列object 的crud。类似的,如果我们要实现一个“集群操作系统”,容器的粒度未免太小。也就是说,镜像和容器之间仍然有鸿沟要去填平?kubernetes 叫pod,marathon叫Application,中文名统一叫“应用”。在这里,应用是一组容器的有机组 合,同时也包括了应用运行所需的网络、存储的需求的描述。而像这样一个“描述” 应用的 YAML 文件,放在 etcd 里存起来,然后通过控制器模型驱动整个基础设施的 状态不断地向用户声明的状态逼近,就是 Kubernetes 的核心工作原理了。“有了 Pod 和容 器设计模式,我们的应用基础设施才能够与应用(而不是容器)进行交互和响应的能力,实现了“云”与“应用”的直接对接。而有了声明式 API,我们的应用基础而设施才能真正同下层资源、调度、编排、网络、存储等云的细节与逻辑解耦”。
解读容器的 2020:寻找云原生的下一站面向终态的声明式 API 与其背后“辛勤”工作的控制器,为“构建基础设施层抽象”这个充满了挑战的技术难题,提供了一个能够在复杂度与可用性之间取得平衡的解决方案。但k8s 也并不完美。在绝大多数情况下,企业基于 Kubernetes 构建上层平台,都会引入各种各样其他的抽象作为补充,甚至取代或者隐藏掉 Kubernetes 的部分内置抽象:阿里巴巴开源的 CloneSet,腾讯的 GameStatefulSet 实践等扩展型工作负载等都是这个趋势的最好的案例。今天能够基于 Kubernetes 成体系构建出完整上层平台的团队,其实集中在一、二线大型互联网公司当中,并且其实践往往“仅供参考”,鲜有可复制性。
事实上,平台构建者之所以要基于 Kubernetes 进一步构建上层平台,其根本动机无非来自两个诉求:
- 更高的抽象维度:比如,用户希望操作的概念是“应用”和“灰度发布”,而不是“容器”和“Pod”;大家为 Kubernetes 构建的各种 Dashboard,其实就是一种“抽象”的实现方式:这些 Dashboard 本质上是在 Kubernetes API 对象的基础上暴露出了一组允许用户填写的字段,从而实现了‘’简化用户使用心智、提升用户体验‘’的目的
- 更多的扩展能力:比如,用户希望的应用灰度发布策略是基于“双 Deployment + Istio” 的金丝雀发布,而不是 Kubernetes 默认的 Pod 线性滚动升级。这些增强或者扩展能力,在 Kubernetes 中一般是以 CRD + Controller 的插件方式来实现的。Kubernetes将下层的容器运行时(Container Runtime)封装得太严实。Runtime 层的容器创建只有一个 Pod 资源,此外没有任何接口可以让用户能够通过 Kubernetes API 层面来执行一些 Runtime 相关操作,比如拉取镜像、重启容器等,但这些都是来自业务场景的现实诉求。
在云原生与 Kubernetes 项目极大程度的统一与标准化了基础设施层抽象之后,如何进一步帮助平台团队在此之上快速、轻松、可复制的构建上层平台,正在成为业界开始积极思考的一条关键路径。
随着我们对 K8s 的使用程度越来越深,会发现 K8s 面向 “工作负载” 的设计在一些场景下是需要提升的。围绕着这些问题的焦点,社区不断地在为 K8s 进行插件式的扩展。CNCF Landscape 中已有接近 400 个开源产品为 K8s 提供了额外能力,这些技术方向大致被分为了数据库、消息、应用定义和镜像构建等,产品数量仍然不断上升。
对kubernetes 的扩展
接口能力的扩展
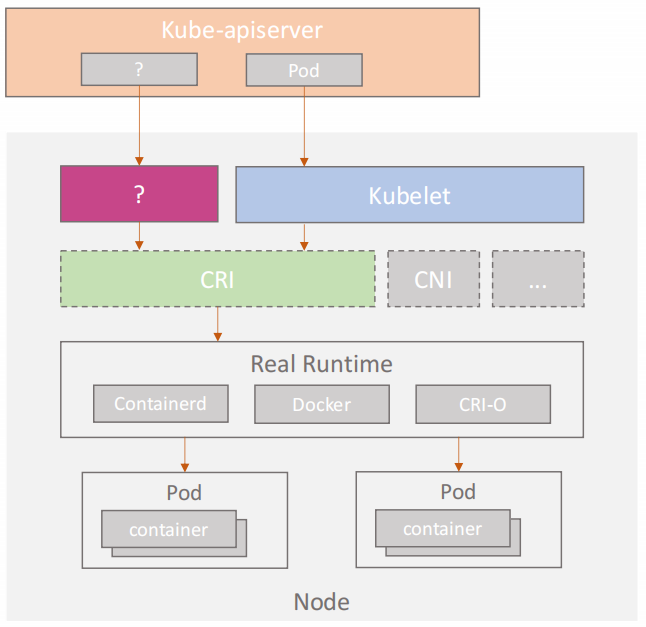
如何基于 OpenKruise 打破原生 Kubernetes 中的容器运行时操作局限?
- Kubernetes 的 API 层面限制了用户只能创建或删除 Pod ,除此之外,里面的容器只能做 Exec, Log 这样的操作。在 Kubernetes 接口层面,用户无法进行比如拉取镜像、重启容器等操作。
- CRI 的职责是对容器运行时以及对镜像做相关的管理,包括对容器的启停操作,对 Sandbox 容器的操作,容器 States 的数据采集,以及镜像的拉取和查询等操作。因此,CRI 提供了比较完善的容器接口
- Kubelet 目前没有提供任何 hook 解决 plugin 的这个操作,来让外层能去动态拓展 Kubelet 所做的事情。那是否可以加入一个与 Kubelet 类似的新组件,可以连接到 CRI API,来拓展 Kubernetes 容器进行时的操作呢?
应用模型的扩展
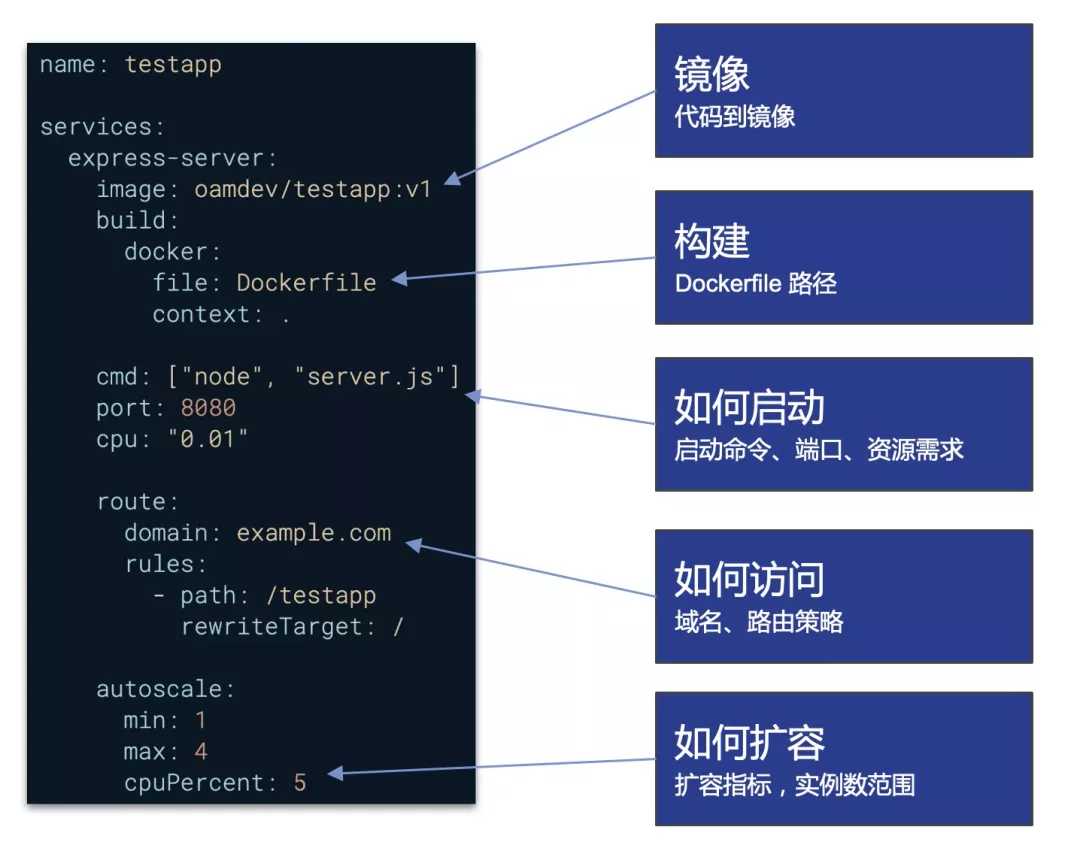
从工作负载层面上讲,Kubernetes 只通过 Deployment、Statefulset 等抽象描述单个组件的特征,然而多数情况下,开发人员开发出的业务系统会包含若干微服务组件。那么如何对整个业务系统进行统一的管理就变成了一个问题。解决方案之一,就是通过云原生应用平台,在单个组件之上,抽象出应用这个概念。应用应该是由人为规定的一组服务组件(workload)组成,服务组件之间具有显式或隐式的关联调用关系,彼此之间有机组合成为一个整体,作为一套完整的业务系统对外提供服务。PS:比如AI 训练任务的一系列workload
Kruise Rollout v0.3.0:教你玩转 Deployment 分批发布和流量灰度 未读
代码结构
Kruise 控制器分类指引Controller 命名惯例
- Set 后缀:这类 controller 会直接操作和管理 Pod,比如 CloneSet, ReplicaSet, SidecarSet 等。它们提供了 Pod 维度的多种部署、发布策略。
- Deployment 后缀:这类 controller 不会直接地操作 Pod,它们通过操作一个或多个 Set 类型的 workload 来间接管理 Pod,比如 Deployment 管理 ReplicaSet 来提供一些额外的滚动策略,以及 UnitedDeployment 支持管理多个 StatefulSet/AdvancedStatefulSet 来将应用部署到不同的可用区。
- Job 后缀:这类 controller 主要管理短期执行的任务,比如 BroadcastJob 支持将任务类型的 Pod 分发到集群中所有 Node 上。
github.com/openkruise/kruise
/pkg
/client
/controller // 支持crd 对应实现
/cloneset
/cloneset_controller.go
/controllers.go // 将各个Controller/Reconciler 实现注册到 Manager 中
/webhook
/main.go
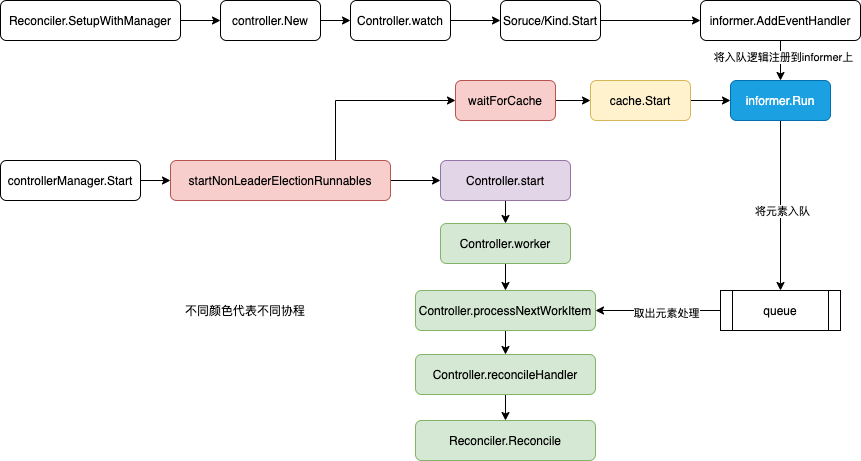
kubebuilder 脚手架生成的项目代码 一般假设只有一个crd 和Controller/Reconciler,因此main.go 的核心逻辑是: Reconciler 注册到Manager; Manager.Start。 对于kruise 来讲因为有多个 Controller,所以每一个controllr pkg 都实现了一个Add 方法负责 将自己注册到 Manager
阿里巴巴云原生应用安全防护实践与 OpenKruise 的新领域
其它
OpenKruise v0.9.0 版本发布:新增 Pod 重启、删除防护等重磅功能Pod 容器重启/重建;级联删除防护;配合原地升级的镜像预热;先扩再缩的 Pod 置换方式;sidecar 热升级功能 实现原理还挺好玩的。
OpenKruise v1.3:新增自定义 Pod Probe 探针能力与大规模集群性能显著提升Kubernetes 提供了三种默认的 Pod 生命周期管理:Readiness Probe/Liveness Probe/Startup Probe。都已经限定了特定的语义以及相关的行为。除此之外,其实还是存在自定义 Probe 语义以及相关行为的需求,例如: GameServer 定义 Idle Probe 用来判断该 Pod 当前是否存在游戏对局,如果没有,从成本优化的角度,可以将该 Pod 缩容掉。
apiVersion: v1
kind: Pod
status:
conditions:
# podConditionType
- type: game.io/idle
# Probe State 'Succeeded' indicates 'True', and 'Failed' indicates 'False'
status: "True"
lastProbeTime: "2022-09-09T07:13:04Z"
lastTransitionTime: "2022-09-09T07:13:04Z"
# If the probe fails to execute, the message is stderr
message: ""
留下评论