《Concurrency Models》笔记
前言
并发模型是什么
Concurrency Models Concurrent systems can be implemented using different concurrency models. A concurrency model specifies how threads in the the system collaborate to complete the jobs they are are given. Different concurrency models split the jobs in different ways, and the threads may communicate and collaborate in different ways. 可以看到,并发模型主要关注两件事:
- 如何分解任务,准确的说如何分解任务序列
- 线程如何协作
很多时候,我们认为很tricky 的代码技巧,其实不是技巧,而是一个宏观方法论的一部分。
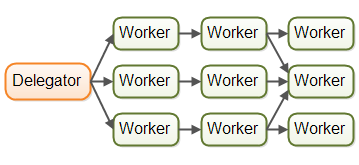
Parallel Workers
Incoming jobs are assigned to different workers,Each worker completes the full job.
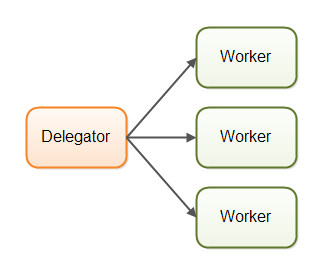
If the parallel worker model was implemented in a car factory, each car would be produced by one worker. The worker would get the specification of the car to build, and would build everything from start to end.
Parallel Workers Disadvantages
-
Shared State Can Get Complex
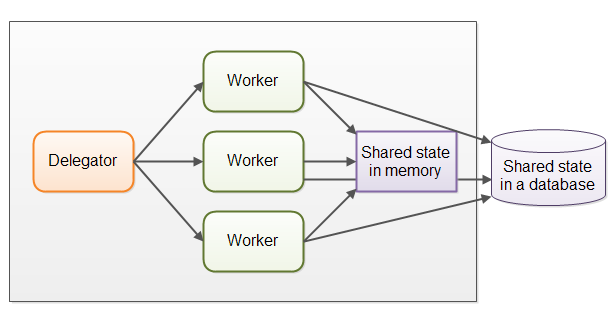
- As soon as shared state sneaks into the parallel worker concurrency model it starts getting complicated. 并发读写、可见性、race condition
- part of the parallelization is lost when threads are waiting for each other when accessing the shared data structures. 访问线程安全的数据结构 会降低并发度
-
Stateless Workers
Shared state can be modified by other threads in the system. Therefore workers must re-read the state every time it needs it, to make sure it is working on the latest copy. This is true no matter whether the shared state is kept in memory or in an external database. A worker that does not keep state internally (but re-reads it every time it is needed) is called stateless . 线程不得不 每次 Re-read data 以确保 cas 的效果。 无论是内存还是数据库(曾经为了线程安全的改一个业务表,专门加了一个version字段,也就是所谓的乐观锁)。
Re-reading data every time you need it can get slow. Especially if the state is stored in an external database.
-
Job Ordering is Nondeterministic. Another disadvantage of the parallel worker model is that the job execution order is nondeterministic. There is no way to guarantee which jobs are executed first or last. Job A may be given to a worker before job B, yet job B may be executed before job A.
The nondeterministic nature of the parallel worker model makes it hard to reason about the state of the system at any given point in time.(你无法确定 一个时间点 内系统所处的状态) It also makes it harder (if not impossible) to guarantee that one jobs happens before another.
Assembly Line
流水线
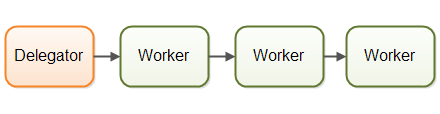
The workers are organized like workers at an assembly line(流水线上的工人) in a factory. Each worker only performs a part of the full job. When that part is finished the worker forwards the job to the next worker.
这种模式有几种场景
- commons-pipeline, Data objects flowing through the pipeline are processed by a series of independent user-defined components called Stages
-
Systems using the assembly line concurrency model are usually designed to use non-blocking IO. the IO operations determine the boundary between workers. A worker does as much as it can until it has to start an IO operation. Then it gives up control over the job. When the IO operation finishes, the next worker in the assembly line continues working on the job, until that too has to start an IO operation etc. 第一次看到这种表述:以 io 操作作为worker 的边界
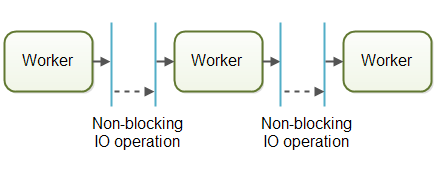
netty 就有点这意思
-
实际操作过程中,根据业务可能有多条流水线,并且Jobs may even be forwarded to more than one worker for concurrent processing.
-
流水线 的变种 有时也被称为 Reactive,有时Event Driven Systems,从文章的潜台词看,两者本质差不多。 根据 worker是否 communicate directly with each other,流水线还可以分为
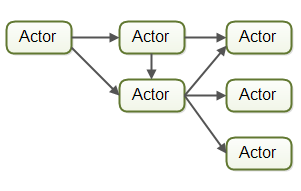
akka 就是这种
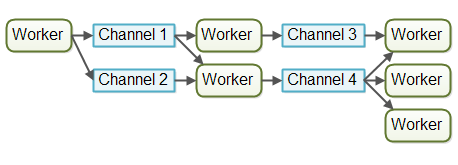
go 语言就是这种
Assembly Line Advantages
- No Shared State
- Stateful Workers
- Better Hardware Conformity
就是你 可以肆无忌惮的 使用数据记录状态,充分利用缓存加速你的code,比如磁盘上的缓存到内存中,内存的缓存到cpu cahe 中。
Assembly Line Disadvantages
The main disadvantage of the assembly line concurrency model is that the execution of a job is often spread out over multiple workers, and thus over multiple classes in your project.
It may also be harder to write the code. Worker code is sometimes written as callback handlers. Having code with many nested callback handlers may result in what some developer call callback hell. 将 callback hell 与 Assembly Line 线程模型联系起来,callback hell 是一种变相的流水线。
With the parallel worker concurrency model this tends to be easier. You can open the worker code and read the code executed pretty much from start to finish. Of course parallel worker code may also be spread over many different classes, but the execution sequence is often easier to read from the code.
好在我们有很多现成的框架
Functional Parallelism
The basic idea of functional parallelism is that you implement your program using function calls. Functions can be seen as “agents” or “actors” that send messages to each other, just like in the assembly line concurrency model (AKA reactive or event driven systems). When one function calls another, that is similar to sending a message.
All parameters passed to the function are copied,so no entity outside the receiving function can manipulate the data(对于传入的data,除了function,谁都无法篡改). This copying is essential to avoiding race conditions on the shared data. This makes the function execution similar to an atomic operation(这个类比有意思). Each function call can be executed independently of any other function call.
When each function call can be executed independently, each function call can be executed on separate CPUs.
Coordinating function calls across CPUs comes with an overhead(耗费). The unit of work completed by a function needs to be of a certain size to be worth this overhead。比如使用 ForkJoinPool 计算1到100000000000 的和,任务分成10个小 function 也许是值得的,但计算1~10 的和就毫无必要。
小结
which concurrency model is better?it depends on what your system is supposed to do. If your jobs are naturally parallel, independent and with no shared state necessary, you might be able to implement your system using the parallel worker model.Many jobs are not naturally parallel and independent though. For these kinds of systems I believe the assembly line concurrency model has more advantages than disadvantages
不准确的说,可以将多线程模式归类为
- 单线程
- 多线程
- 主从线程,主从线程与多线程的区别在于,多线程中的每个线程干的是一样的活儿,主从线程中的线程则有任务分工
留下评论