通用分布式计算引擎Ray
前言
Ray 是一个并行和分布式 Python 的开源库。其定位是一个通用的分布式编程框架,提供了统一的分布式底盘,能帮助用户将自己的程序快速分布式化。从高层次上看,Ray 生态系统由三部分组成:。Ray Core 提供了 low level 的分布式语法,如 remote func、remote class; Ray AIR 提供了 AI 场景的相关库(包括原生库和第三方库),以及用于在任何集群或云提供商上启动集群的工具。
如何用 Python 实现分布式计算?Ray 是基于 Python 的分布式计算框架,采用动态图计算模型,提供简单、通用的 API 来创建分布式应用。使用起来很方便,你可以通过装饰器的方式,仅需修改极少的的代码,让原本运行在单机的 Python 代码轻松实现分布式计算,目前多用于机器学习。
- 提供用于构建和运行分布式应用程序的简单原语。
- 使用户能够并行化单机代码,代码更改很少甚至为零。
- Ray Core 包括一个由应用程序、库和工具组成的大型生态系统,以支持复杂的应用程序。比如 Tune、RLlib、RaySGD、Serve、Datasets、Workflows。
应用场景
传统AI 训练工作流是这样的:申请 GPU 资源 → 创建容器 → 安装依赖 → 上传代码 → 启动训练 → 训练结束 → 释放资源。每次跑实验都要走一遍这个流程,资源申请要排队,环境配置要踩坑,调试必须在 GPU 机器上进行。Ray 给出了一个新的范式:在容器之上再封装一层 Ray 集群。解决了两个核心痛点:
- 省去重复的环境准备。Ray 集群一旦创建,就是一个随时待命的计算资源池。你要做的只是
ray.init("ray://cluster-address:10001"),然后通过ray submit提交python任务。集群可以常驻,任务随来随跑,不用每次都从零开始。 - 代码和执行环境彻底解耦。你的训练脚本可以跑在本地笔记本上,通过 Ray Client 连接远程集群,计算自动发生在集群的 GPU 上。
一个应用场景: 笔者在做一个知识库应用,涉及到对文档的解析(一般用到gpu)、切片、向量化、存到vdb,抽象一下,一个workflow涉及到多个step,有的step很快有的很慢,有的用到cpu有的用到gpu,某个step出错了要支持重试,大批量文件时,可以自动扩展集群规模,提高实例速度。此时有几种实现方式
- 启动多个进程,一个进程干所有活儿,一个函数实现实现所有过程,一个子函数一个step,每个子函数配置重试策略(此时复函数无需重试)
- 启动多个进程,一个进程干一个step,进程之间通过mq/db 传递信息。相对与1的好处是,部分step可以指定使用gpu。缺点是代码开发、部署麻烦(多个进程嘛)。 怎么兼得?代码写在一起,一个step一个函数,指定有的step 用cpu,有的用gpu。代码回归到dsl 的本质,而处理方式则可以根据集群规模、资源诉求任意扩展。
将python分布式+并行化
# 一个装饰器就搞定分布式计算
ray.init() # 在本地启动 ray,如果想指定已有集群,在 init 方法中指定 RedisServer 即可
@ray.remote # 声明了一个 remote function,是 Ray 的基本任务调度单元,它在定义后,会被立马序列化存储到 RedisServer 中,并且分配一个唯一的 ID,这样就能保证集群所有节点都能看到这个函数的定义;
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures)) # [0, 1, 4, 9] 可以通过 ObjectID 获取 ObjectStore 内的对象并将之转换为 Python 对象,这个方法是阻塞的,会等到结果返回;
装饰器 @ray.remote 也可以装饰一个类:
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
counters = [Counter.remote() for i in range(4)]
tmp1 = [c.increment.remote() for c in counters]
tmp2 = [c.increment.remote() for c in counters]
tmp3 = [c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures)) # [3, 3, 3, 3]
为什么
分布式计算框架Ray介绍当我们要构建一个涉及大规模数据处理或者复杂计算的应用,传统的方式是使用现成的大数据框架,例如 Apache Flink 和 Apache Spark。这些系统提供的API通常基于某种特定的计算范式(例如DataStream、DataSet),要求用户基于这些特定的计算范式实现应用逻辑。对于传统的数据清洗、数据分析等应用,这种用法能够很好地适用。但是,随着分布式应用的逻辑越来越复杂(例如分布式机器学习应用),许多应用的逻辑并不能直接套用现有的计算范式。在这种情况下,开发者如果想要细粒度地控制系统中的任务流,就需要自己从头编写一个分布式应用。但是现实中,开发一个分布式应用并不简单。除了应用本身的代码逻辑,我们还需要处理许多分布式系统中常见的难题,例如:分布式组件通信、服务部署、服务发现、监控、异常恢复等。处理这些问题,通常需要开发者在分布式系统领域有较深的经验,否则很难保证系统的性能和健壮性。为了简化分布式编程,Ray提供了一套简单、通用的分布式编程API,屏蔽了分布式系统中的这些常见的难题,让开发者能够使用像开发单机程序一样简单的方式,开发分布式系统。
云原生场景下如何利用Ray快速构建分布式系统Ray 的通用性体现在哪里呢?Ray的设计思想是不绑定任何计算模式,把单机编程中的基本概念分布式化。从API 的设计可以看出,Ray并不是一个大数据系统,尤其是Ray Core这一层没有任何大数据相关的算子,而是从单机编程的基本概念进行分布式化的。具体如何分布式化?我们在单机编程中经常用到两个非常核心的概念,一个叫Function,一个叫Class,在面性对象的编程语言里面,基本上大家会围绕这两个概念进行代码开发,在Ray中会将这两个基本概念进行分布式化,对应到分布式系统就叫Task和Actor。
设计
Ray 的框架中最为重要的两个部分是 Ray Core 和 Ray AIR:
- Ray Core 是底层的分布式的计算框架,使用基于 actor 模型来实现的一套计算框架,它可以将 Python 的一个 Class 或者一个 Function 转成分布式的 actor 和 task,在所有的机器上分布式地进行运行,并且 tasks/actor 之间可以通过分布式的对象存储能力来达到共享的能力。基于这层api,可以非常容易将现有程序分布式化,这一层没有绑定任何计算模式以及语义。
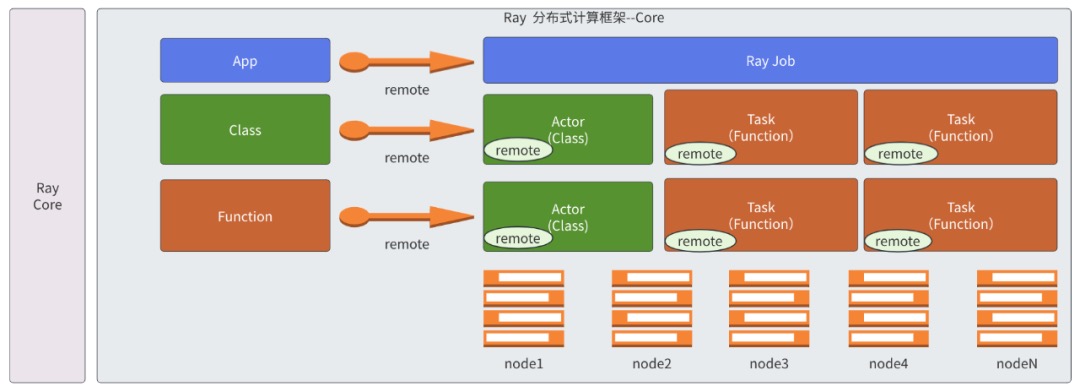
- Ray AIR是Ray的上层API,主要将Ray的各种应用整合在一起。比如 xgboost-ray/RayTrain/RayServe
Ray 提供了 init、remote、put、get 等基本原语。但是通过这些基本原语达不到更细粒度的控制,例如针对不同的计算配置不同的CPU、内存。或者调度的时候,能够提供人工设定调度的方法。Ray 希望通过参数配置来实现任务、故障和应用的细粒度控制。配置能够达到什么样粒度的控制。
Ray 寻找能够在分布式系统上开发的一种通用方法。Ray API 能够让开发者容易的组合在一个分布式框架上组合不同类型的库。举个例子,Ray 任务和 Actor 可以在分布式训练(例如,torch.distributed)里面调用或者被调用。在这种情况下,Ray 设计为一个分布式的粘合系统,因为它的 API 是通用的,足够支持在不同的工作类型中作为界面层服务
- Ray 架构的核心原则是 API 的简单和通用,而核心系统的目标是性能(低开销和横向扩展)和可靠性。有时候,我们愿意牺牲也挺好的目的。举个例子,Ray 包含了一些组件,例如,分布式引用计数和分布式内存,它增加了架构的复杂度,但是对于性能和可靠性来说这是必须的
- 为了性能,Ray 基于 gRPC 构建,并且能够在很多场景下匹配甚至超过原生 gRPC 的性能。相对于 gRPC 本身,Ray 让应用平衡并行和分布式操作,和分布式内存共享(通过一个共享的对象存储来实现)更简单
- 为了可靠性,Ray 的内部协议设计提供了发生故障的时候的纠错性,同时减少了通用情况下的开销。Ray 开发了一个分布式引用计数协议来保障内存安全,并且提供了故障恢复的不同选项
通用分布式编程API:无状态计算单元Task
Task是对单机编程中的Function进行分布式化,是一个无状态的计算单元。Ray可以把一个任意的Python函数或Java静态方法转换成一个Task,在和调用程序不同的进程上的单个的函数调用。在这个过程中,Ray会在一个远程进程中执行这个函数。并且这个过程是异步的,这意味着我们可以并行地执行多个Task。PS:和python线程、进程的异步执行很像。

# `square`是一个普通的Python函数,`@ray.remote`装饰器表示我们可以把这个函数转化成Ray task,可以远程执行
@ray.remote
def square(x):
return x * x
obj_refs = []
# `square.remote` 会异步地远程执行`square`函数(该function就会被调度到远程节点的某个进程中执行)。通过下面两行代码,我们并发地执行了5个Ray task。`square.remote`的返回值是一个`ObjectRef`对象,表示Task执行结果的引用。
for i in range(5):
obj_refs.append(square.remote(i))
# 实际的task执行结果存放在Ray的分布式object store里,我们可以通过`ray.get`接口,同步地获取这些数据。
assert ray.get(obj_refs) == [0, 1, 4, 9, 16]
通用分布式编程API:分布式object
Obect Store是Ray架构中的一个关键组件,Task计算的中间结果会存放在分布式Object Store中。除此之外,我们也可以使用put接口,显式地把一个Python或Java对象存放到Object Store中。
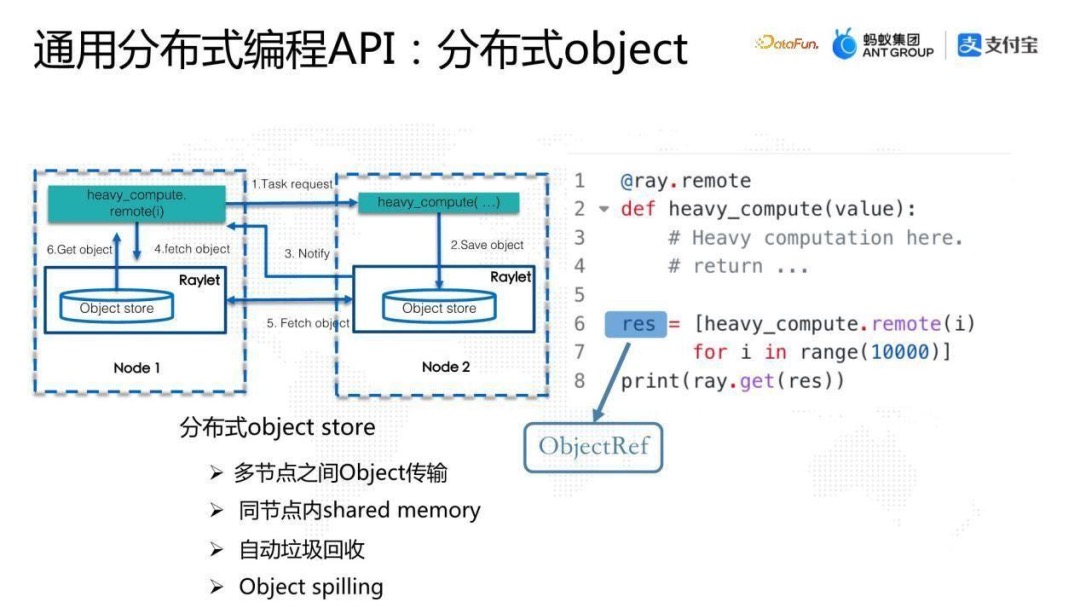
我们在Node 1运行heavy_compute function,这个 function 会使用remote通过Ray底层的调度系统调度到Node 2, Node 2会执行这个function,执行完成后,把结果put到本地的object store中,object store 是Ray中的一个核心组件,最终结果返回到Caller端是通过Ray底层的 object store之间的object传输,把结果返回来给Caller端。
从整个的流程看, heavy_compute.remote 返回的是一个ObjectRef,并不是最终的结果。ObjectRef类似于单机编程中的future,只不过它是分布式的future,可以通过ray.get获取最终结果。
Ray的分布式 object store是非常核心的组件,完美支撑了Ray整套分布式API 的设计,其特点如下:
- 可以实现多节点之间object 传输;
- 同节点内是基于shared memory的设计,在此基础上,分布式系统的online传输,如果发生在单机两个进程之间的话,理论上可以达到 Zero Copy 的效果;
- Ray object store 有一套比较完整的自动垃圾回收机制,可以保证分布式系统运算过程中一旦有ObjectRef在系统中没有引用的时候,会触发对该object 进行GC;
- Object store有object spilling 的功能,可以自动将内存中的object spill到磁盘上,从而达到扩容整个分布式系统存储的目的。 PS: 分布式计算的核心就是状态中心、任务的分发与收集。
通用分布式编程API:有状态计算单元Actor
Actor将单机编程的Class概念进行分布式化。Ray使用Actor来表示一个有状态的计算单元。在Ray中,我们可以基于任意一个Python class或Java class创建Actor对象。这个Actor对象运行在一个远程的Python或者Java进程中。同时,我们可以通过ActorHandle远程调用这个Actor的任意一个方法(每次调用称为一个Actor Task),多个Actor Task在Actor进程中会顺序执行,并共享Actor的状态。
# `Counter`是一个普通的Python类,`@ray.remote`装饰器表示我们可以把这个类转化成Ray actor.
@ray.remote
class Counter(object):
def __init__(self):
self.value = 0
def increment(self):
self.value += 1
def get_value(self):
return self.value
# `Counter.remote`会基于`Counter`类创建一个actor对象,这个actor对象会运行在一个远程的Python进程中。在另外一台机器的另外一个节点上面去实例化这个class。
counter = Counter.remote()
# `Counter.remote`的返回值是一个`ActorHandle`对象。通过`ActorHandle`,我们可以远程调用Actor的任意一个方法(actor task)。通过.remote实现远程调用。
[counter.increment.remote() for _ in range(5)]
# Actor task的返回值也是一个`ObjectRef`对象。同样地,我们通过`ray.get`获取实际的数据。
assert ray.get(counter.get_value.remote()) == 5
ray 与rpc的区别
RPC 就像是你去饭店点菜,。饭店(Server)必须先有这道菜的菜谱和食材,你才能点。Ray 就像是你租了一个共享厨房,在通用的厨房里跑自己的菜谱,你不仅带了食材,还带了自己的菜谱(代码)。厨师(Worker)并不关心你会做什么菜,你把菜谱给他,他就按你的方子现场做。
- 数据移动,Server 侧需预置好代码。对于rpc 来说,client.func() 底层持有net_client 将func_name/func_arg 等传给server侧,而server 根据func_name/func_arg运行方法并返回结果。
- 状态维护。rpc通常是无状态的。如果要在不同请求间共享状态,Server 必须显式连接数据库或 Redis。
- 数据流。数据流通常是 Client -> Server -> Client。如果 Task A 的结果要给 Task B 用,数据必须先回到 Client,再发给第二个 Server。
- 容错与调度。如果 Server 挂了,Client 需要自己实现重试机制、负载均衡、服务发现(如通过 Nacos/Consul)。
- 代码移动,Server 侧(Ray Worker)是一个通用的计算载体。ray 则更进一步,server 无需事先持有func 代码,clinet.func() 实质是net_client将方法/函数及其依赖(通过 cloudpickle 序列化) 传输给server,由server 执行并拿到返回值。
- 状态维护。Ray 不仅能传函数(Task),还能传类(Actor)。当 Client Actor.remote() 时,Ray 会在远程实例化一个对象。这个对象在集群中持久存在,并持有私有变量。
- 数据流。Task A 在 Node 1 执行完,结果存在 Node 1 的共享内存里。Task B 如果在 Node 1 执行,可以直接通过指针读取该数据(零拷贝);如果在 Node 2 执行,Ray 引擎会自动在底层进行 Node-to-Node 的搬运。
- 容错与调度。
- 资源调度:你不需要指定哪台机器跑,Ray 根据 CPU/GPU 空闲情况自动分配。
- 自动容错:如果执行 Task 的节点挂了,Ray 知道该 Task 的依赖树,会自动在其他节点“重构”(Reconstruction)并重新运行该任务。 这就解释了为什么 Ray 特别适合 AI 场景: AI 的逻辑变化极快(模型参数、处理流程),如果用 RPC,每次改代码都要重启整个集群的服务;而用 Ray,你只需要在本地改完代码,直接 remote 提交即可。
其它
在Ray中,我们可以把一个Task输出的ObjectRef传递给另一个Task(包括Actor task)。在这种情况下,Ray会等待第一个Task执行结束之后,再开始执行第二个Task。同时,我们也可以把一个ActorHandle传递给一个Task,从而实现在多个远程Worker中同时远程调用一个Actor。通过这些方式,我们可以动态地、灵活地构建各种各样复杂的分布式任务流。
# 通过把一个task输出的`ObjectRef`传递给另一个task,我们定义了两个task的依赖关系。Ray会等待第一个task执行结束之后,再开始执行第二个task。
obj1 = square.remote(2)
obj2 = square.remote(obj1)
assert ray.get(obj2) == 16
除了Task和Actor两个基本概念,Ray还提供了一系列高级功能,来帮助开发者更容易地开发分布式应用。这些高级功能包括但不限于:设置Task和Actor所需的资源、Actor生命周期管理、Actor自动故障恢复、自定义调度策略、Python/Java跨语言编程。
如果没有Ray,在纯云原生的实现思路中,资源定制是写到 yaml 里边的。比如说训练需要多少GPU 或者计算节点需要多少CPU,都是在 yaml 中定制 container 的规格。Ray提供了另外一个选择,完全无感知的代码化的配置,用户可以在 runtime 的时候,或者在Ray的Task 或 Actor 的decorator 中加一个参数,就可以通过Ray系统的调度能力分配相应的资源,达到整个分布式系统资源定制的目的。Ray的资源定制除了支持GPU、CPU、Memory 之外,还可以插入自定义资源。然后Ray的调度还有一些高级功能,比如资源组,或者亲和性和反亲和性的调度,目前都是支持的。ray的调度中,所有的资源都是逻辑资源不是物理资源,ray会按照task/actor的资源需求来进行调度,但不会限制task/actor对资源的真实使用,没有资源隔离。比如一个节点有10cpus,actor(num_cpus=2)只能创建5个,每个actor使用多少线程/进程ray是不控制的。另外cpu/gpu可以是小数,但不代表ray会为进程做cpu/gpu共享。
@ray.remote(num_gpus=1)
def train_and_evaluate(model,train_indices,test_indices):
...
依赖管理:在分布式系统中,往往不同分布式系统的组件对环境的要求是不一样的。如果使用常规思路,就需要把环境固化到image里面,通过 Dockerfile 去定制环境。Ray实现了更灵活的选择,也是代码化的,可以在runtime创建Task或Actor之前的任意时刻定制指定计算单元的运行时环境。上图中给worker 的 Task 设定一个runtime_env,定制一个专属的Python版本,并在该版本里面装入一些pip包,完成面向Python的隔离环境的定制。这时Ray集群内部会在创建这个Task之前去准备该环境,然后将该Task调度到该环境执行。
@ray.remote(runtime_env={"python_version":"3.9","pip"=["scikit-learn"]})
def train_and_evaluate(model,train_indices,test_indices):
...
Ray的运行时环境是插件化的设计,用户可以根据自己的需求实现不同的插件,在Ray中原生支持了一些插件如Pip、Conda、Container等,只要是跟环境相关,不只是代码依赖,也可以是数据依赖,都可以通过插件去实现。
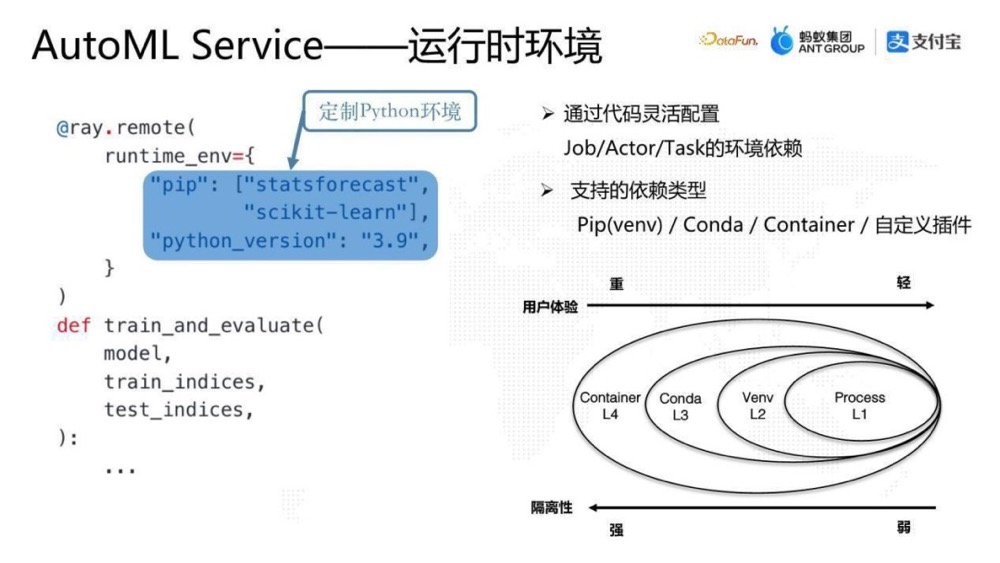
Ray中用户可以根据自己的环境定制的需求选择需要定制的环境的粒度。以Python为例,隔离性的支持力度有如下几个维度,一个是 Process 级别的隔离,第二是 Virtual env 级别的隔离,第三是 Conda 级别的隔离,最后是 Container级别隔离。从隔离性来说,从右到左是由弱到强的,Process 的隔离性是非常弱的,Container 隔离性是更强的。从用户体验来说,环境定制上 Container 是更重的而Process 是更轻的。
底层架构
整体设计
基于 Ray 的大规模离线推理 Ray 项目是 UC Berkeley 的 RISElab 实验室在 2017 年前后发起的,定位是通用的分布式编程框架——Python-first。理论上通过 Ray 引擎用户可以轻松地把任何 Python 应用做成分布式,尤其是机器学习的相关应用,目前 Ray 主攻的一个方向就是机器学习。Ray 的架构分为三层
- 最下面一层是各种云基础设施,也就是说 Ray 帮用户屏蔽了底层的基础设施,用户拉起一个 Ray Cluster之后就可以立即开始分布式的编程,不用考虑底层的云原生或各种各样的环境;
- 中间层是 Ray Core 层。这一层是 Ray 提供的核心基础能力,主要是提供了 Low-level 的非常简洁的分布式编程 API。基于这套 API,用户可以非常容易地把现有的 Python 的程序分布式化。值得注意的是,这一层的 API 是 Low-level,没有绑定任何的计算范式,非常通用;
- 最上层是 Ray 社区基于 Ray Core 层做的丰富的机器学习库,这一层的定位是做机器学习 Pipeline。比如,数据加工读取、模型训练、超参优化、推理,强化学习等,都可以直接使用这些库来完成整个的 Pipeline,这也是 Ray 社区目前主攻的一个方向。
Ray Cluster
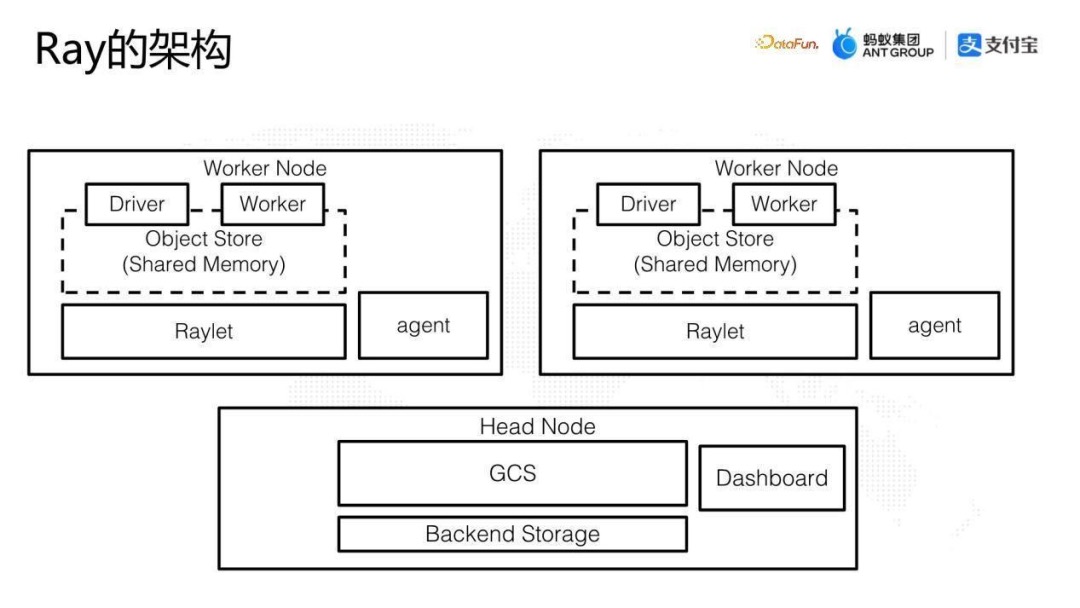
上图展示的是 Ray Cluster 的基本架构,每一个大框就是一个节点。(这里的节点是一个虚拟的概念,可以是一个物理机,一个 VM 或一个 Linux 的 Docker。比如在 K8s 上,一个节点就是一个 Pod。)
- Head 节点:是 Ray Cluster 的调度中心,比较核心的组件是 GCS(Global Control Service),GCS 储存了代码、输入参数、返回值,一些元数据比如actor的地址,负责整个集群的资源调度和节点管理,类似于Hadoop架构中Yarn里边的 Resource Manager。Head节点也有可观测性 Dashboard。
- Worker 节点:除了 Head 节点之外,其他都是 Worker 节点,承载具体的工作负载。
每个节点包含几个物理进程
- Worker:是 Ray 中 Task 和 Actor 的载体。负责task的提交和运行,运行用户自定义的代码。
- Raylet:每个节点上面都有一个守护进程 Raylet,它是一个 Local Scheduler,负责Server内部的调度: Task 的调度以及 Worker 的管理。
- Object Store 组件:每个节点上都有 Object Store 组件,负责节点之间 Object 传输。在整个 Cluster 中每个节点的 Object Store 组件组成一个全局的分布式内存。同时,在单个节点上,Object Store 在多进程之间通过共享内存的方式减少 copy。
- 其它: 集中式的管理能够提供很好的调度监控,但是也会影响性能。GCS 希望能够较少被 worker 访问,因此采用了一些 Local Scheduler 的方式,避免 worker 对 GCS 的频繁调用。
- Driver:用来执行python中的main函数,可以提交task,但是不会真正运行他们。当用户向 Ray Cluster 上提交一个 Job,或者用 Notebook 连接的时候,Ray挑选节点来运行 Driver 进行。作业结束后 Driver 销毁。可以运行在任意节点,但是一般默认都在head节点中。
- Global Control Service, GCS:是集群中的核心组件,用于管理集群中的状态、调度任务、资源管理、运行监控。在ray 2.0中GCS支持容错,允许运行在任意或多节点,而不是在head节点上。
Ray 如何远程执行 Python 代码
Ray 如何远程执行 Python 代码f 是用 python 定义的一个函数,Ray 本身是基于 C++ 实现的分布式计算。那怎么把 python 的代码 remote 到 C++ 的runtime 来执行呢?Ray 并不是真的把 .py 文件发过去,而是通过序列化(Serialization)技术将函数“打包”。
import ray
import time
ray.init()
@ray.remote
def f(i):
time.sleep(1)
return i
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures))
GCS 是 Global State Service,管理全局的状,Header 和 Worker 的不同点就在于 GCS。Raylet 是一个连接器,把 Worker (Header 也是一种 Worker) 都连接起来。Head node 有一个 Driver,支持 Python 和 Java。怎么理解支持 Python 和 Java(后面主要说 Python)。就是提供上面代码的样子,支持 import ray 以及后面 ray.init 和 remote 注解的方式来提交计算到各个节点,Raylet 在这个过程主要存储,以及和 GCS 通讯,传递计算状态和信息。Python 调用封装好的 C++ 库来和其他 Node 通讯。
Remote 注解在 remote_function.py 里面,简化如下(… 代表省略内容):
def _remote(...):
# ...
# There is an interesting question here. If the remote function is
# used by a subsequent driver (in the same script), should the
# second driver pickle the function again? If yes, then the remote
# function definition can differ in the second driver (e.g., if
# variables in its closure have changed). We probably want the
# behavior of the remote function in the second driver to be
# independent of whether or not the function was invoked by the
# first driver. This is an argument for repickling the function,
# which we do here.
self._pickled_function = pickle.dumps(self._function)
self._function_descriptor = PythonFunctionDescriptor.from_function(
self._function, self._pickled_function
# ...
首先把 pickled_function 用 pickle 来序列化。然后用 PythonFunctionDescriptor 来打包前后两个函数,PythonFunctionDescriptor 是用 cython 实现的的对 python 函数的封装,如下:
def from_function(cls, function, pickled_function):
# ...
module_name = function.__module__
function_name = function.__name__
class_name = "
pickled_function_hash = hashlib.sha1(pickled_function).hexdigest()
return cls(module_name, function_name, class_name, pickled_function_hash)
这里用 hash 把函数内容封装,然后调用 f.remote() 提交这个计算任务。在 remote_function.py 的 _remote 函数里的 invocation ,如下:
# ...
object_refs = worker.core_worker.submit_task(
self._language,
self._function_descriptor,
list_args,
name,
num_returns,
resources,
max_retries,
placement_group.id,
placement_group_bundle_index,
placement_group_capture_child_tasks,
worker.debugger_breakpoint,
override_environment_variables=override_environment_variables
or dict())
上面描述了 Ray 是怎么封装 Python 代码成一个 hash 和 pickle 化了的代码。下面再看看 worker 是怎么调用这个代码的,Ray 的 Worker 执行部分的代码如下:
Status CoreWorker::ExecuteTask(...) {
// ...
RayFunction func{task_spec.GetLanguage(), task_spec.FunctionDescriptor()};
// ...
status = options_.task_execution_callback(
task_type, task_spec.GetName(), func,
task_spec.GetRequiredResources().GetResourceMap(), args, arg_reference_ids,
return_ids, task_spec.GetDebuggerBreakpoint(), return_objects);
提交了任务和 python 代码之后, Ray 怎么在后台处理和执行这些任务呢。这里面包含了 Ray 的任务机制,还有基于 boost asio 的异步执行规范。
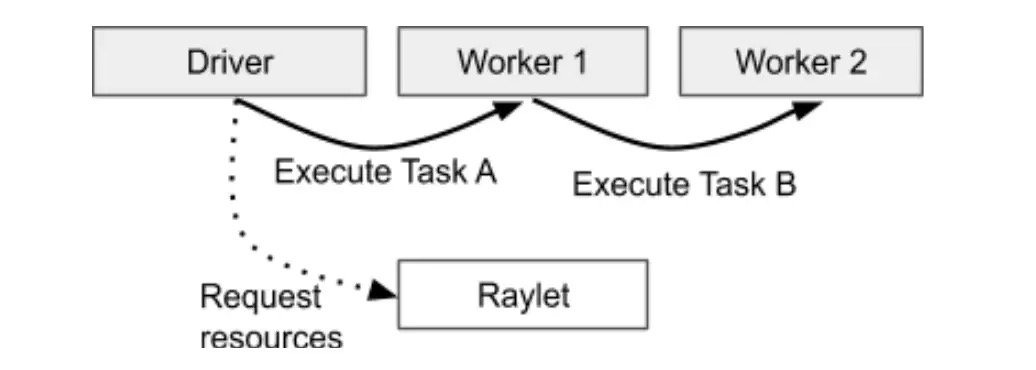
- Driver (Client):将函数序列化成二进制流。
- GCS (Global Control Store):存储这些代码导出信息(Export)。
- Worker (Server):发现有新任务,从 GCS 下载字节码,并在本地进程中反序列化成一个可执行的 Python 对象。
Task 生命周期
Ray 1.0 架构解读进程提交了 task,进程就作为 task 返回的所有者。可以通过 raylet 获取资源来执行 task。在这里,driver 是结果 “A” 的所有者,“Worker 1” 是结果 “B” 的所有者。当一个 task 被提交后,task 的所有者等待任何依赖在集群里可用。例如 ObjectRef 是我们作为参数带入到 task里的依赖。当这些依赖准备好的时候,所有者从分布式调度里面获得资源来执行这个 task。一旦资源可用,调度就批准这个提交。task 所有者在所在的 worker 通过 gRPC 发送一个特定的 “task 描述”来调度 task 。当执行 task 的时候,worker 必须存储这个执行的返回值。如果返回值很小,worker 就直接在所有者 worker 的内部返回,把返回值拷贝到进程内的对象存储。如果返回值很大,worker 在它的本地共享内存对象存储这个结果,并且反馈给所有者这个对象在分布式内存。这就允许所有者可以在它所在的本地 node 引用这个对象和获取这个对象(在 raylet 之间有一层通讯机制,调度 raylet 所在的共享内存的数据。worker 本身也有个消息传递机制/grpc,小的数据可以直接传输)。
Task的owner就是触发Task代码的(worker)进程,负责task的运行以及objectref与真实值的维护。
- 当task第一次调用时,owner负责生成task的配置声明,并把task序列化后保存到GCS里面。
- 调度申请并等待资源和对象依赖。owner可以传递普通的python对象作为task的参数,如果task的参数值很小,会通过task配置声明直接拷贝到owner所在的运行时对象存储中。如果task的参数很大,owner会先调用ray.put()保存对象,然后通过objectref传递参数。当任务提交后,owner会等待所有依赖的objectref变成可用状态。
- 注意这种依赖可能并不是本地的,owner认为objectref在集群中任何节点可用就表示依赖就绪。
- 一旦task依赖的object都就绪,owner就会向分布式调度器申请资源运行。分布式调度器尝试申请资源并获取task配置中objectref对应的参数,一旦资源和参数都就绪,调度器就会批准请求,并返回worker对应的地址。
- owner向申请好的worker发送gRPC并传递task配置声明。worker再去GCS里面下载task定义并运行。
- 当执行完task后,worker需要存储返回值。如果返回值很小,一般是小于100KB,worker会直接拷贝到owner;如果返回值很大,worker就需要在本地共享内存存储中保存,然后通知task的owner对象保存在分布式内存中。类似传递objectref作为task的参数,这允许owner引用返回值而不需要把物理值拷贝到本地。
- Task可能会因为失败而停止,大概会遇到两种错误失败:
- 应用级别,这种是worker的进程还在存活,但是里面的task异常终止,比如task遇到IndexError。应用级别的错误系统不会自动重试,异常会被捕获并保存在task的返回值里面。在2.0里面,用户可以配置应用异常的白名单,允许ray自动重试。
- 系统级别,这种是所在的worker进程异常结束,比如进程分段错误或者本地raylet停止。系统级别的错误会重试指定次数,可以通过配置参数来控制。
Ray 的Low-level和 High-level API
在部署 Ray 时,开源社区有完整的解决方案 Kuberay 项目。每个 Ray Cluster 由 Head 节点和 Worker 节点组成,每个节点是一份计算资源,可以是物理机、Docker 等等,在 K8s 上即为一个 Pod。启动 Ray Cluster 时,使用 Kuberay 的 Operator 来管理整个生命周期,包括创建和销毁 Cluster 等等。Kuberay 同时也支持自动扩展和水平扩展。Ray Cluster 在内部用于收集负载的 Metrics,并根据 Metrics 决定是否扩充更多的资源,如果需要则触发 Kuberay 拉起新的 Pod 或删除闲置的 Pod。
用户可以通过内部的平台使用 Ray,通过提交 Job 或使用 Notebook 进行交互式编程。平台通过 Kuberay 提供的 YAML 和 Restful API 这两种方式进行操作。
ray 如何控制并发度?Ray 的调度器会动态地根据当前系统资源和任务负载情况来决定启动几个 raylet 进程。Ray 的设计目标之一是能够自适应地处理不同规模和负载的工作负载。 工作负载可以通过@ray.remote 指定 运行它所需要的cpu/gpu等资源。 PS: 不一定对。
其它
RayCore提供的是low level的API,直接使用它进行开发需要自行处理很多问题,包括不限于:
- 数据切片和分片管理,需要手动管理数据分片和分布,这无疑增加了复杂性
- 数据读取和加载效率低的问题,缺乏高效的自动化数据读取和加载机制,会影响整体效率;
- 缺乏高级数据操作功能,需要手动实现常见的数据操作,开发成本高。 ==> RayData 理解Ray Data分布式数据处理原理-源码分析 未读。
留下评论