平台支持类系统的几个点
简介
此处主要指 客户端版本管理系统、配置中心系统、abtest 系统、上传系统、推送系统等 跟app 业务不直接关联,但仍是每个app 的必要的 “业务” 系统。平台类系统演进就三件事:堆功能(用户需求能否直接/间接满足),效率/体验(用户视角和开发视角满足需求的速度),成本。
平台支持 系统 是笔者用以对这几个系统的统称,他们与一般业务系统有以下不同
- 一般业务系统 请求 ==> 响应 ==> 展示给用户 就结束了。而平台支持类系统则是 请求 ==> 响应 ==> 数据存在本地 ==> 在恰当的时机生效。
- 客户端 本地数据 需要与服务端 做同步
- 如果将app 分为 业务/基础环境 两个层次的话,其运行属于“基础环境”的一部分
下文以一个文件下发系统为例,即app 启动时/某个业务点击时 向服务端拉取 适配客户端的文件,客户端下载文件 并应用在本地。
平台支持类系统 有很多的共同点,这也就意味着,很多共同点可以作为框架抽取出来。无线运维的起源与项目建设思考
几个基本的功能点
基本构成
后端系统设计
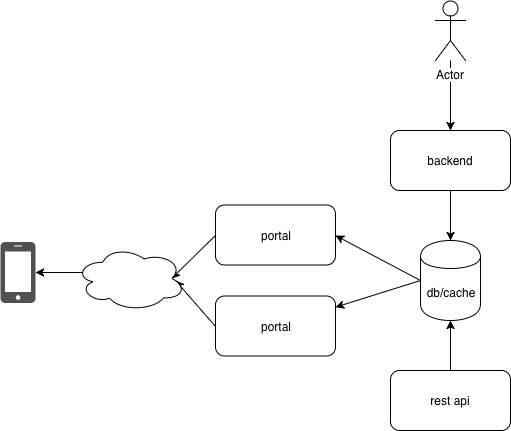
app sdk设计
匹配
-
条件匹配,将文件推送符合一定特征的用户
- 设备信息,比如android/ios 等
- app 信息,比如版本号、渠道号
- 用户画像信息,比如儿童、老人等。 用户画像构建流程与应用场景 未读。
- 测试信息,比如请求来自一个内部测试设备,可以访问未发布的文件
-
精确匹配,将文件推送给一个hdfs 文件(用户id 列表)
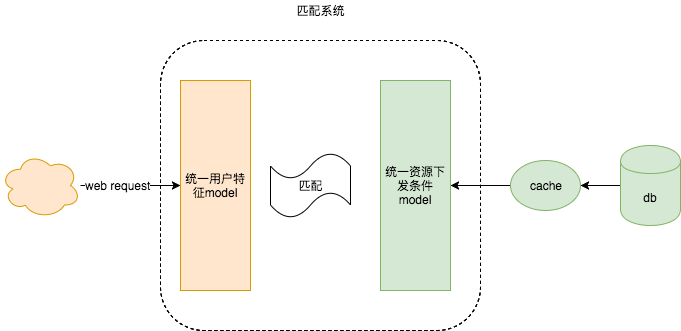
假设client 十几个properties,服务端资源十几个properties, 匹配算法有两个方面
- 提高每一个资源匹配的速度
- 避免重复计算,一般使用缓存
主要思路
| 单个匹配速度 | 避免重复计算 | |
|---|---|---|
| 使用es | es解决 | es解决 |
| 哈希 | 每个property 依次匹配 | 将client 十几个properties 组成一个字符串 作为cache key |
针对哈希算法,有以下优化的变种
- properties 按区分度 分为base 和 optional,使用base 作为cache key做初步过滤,对“漏网之鱼” 用optional 做一一匹配
- 将十几个properties 归类,每一列单独组成字符串,作为cache key。对每一类匹配得到的资源做交集,即为符合所有properties 约束的资源。
- 针对上一种方式,有些properties 作为基本属性,可以作为每一类 cache key的前缀
下发
下发什么?
- 数据
- 状态,比如提前终止一个文件下发,除新的请求无法获取文件外,还要通知已获取文件的设备禁用该文件
下发方式:
-
全量
- 适用于一段时间有效文件 数量有限的业务
- 必然有一个逻辑:
select * from resource where status = on,随着时间的推迟,这个sql 会变慢。当然,你可以为每个资源设置 过期时间,查询时排除掉过期的资源。 - 从更宏观的角度看,全量方式对于客户端来说,客户端是无状态的。
-
增量
- 增量的本质是客户端有一个“版本”,服务端有一个数据版本,客户端与服务端版本增量同步。当然,也有系统采用时间戳 来标记数据版本。
- 增量的难点是,版本只能“增长”。对客户端逻辑要求比较高,笔者就碰到过状态同步失败,客户端数据不断累积的问题。
增量的两种同步方式:
-
明确告诉客户端增删改了哪些东西
{ "add":[...], "update":[...], "delete":[...] } -
返回给客户端所有变化的数据,由客户端合并。(这个方案更复杂)
[ { "id":xx, "status":xx }, { "id":xx, "status":xx } ]id 和本地资源的一样,则刷新到本地,否则视为新增。
灰度下发
有几种实现方案
- 参见abtest 系统设计汇总 “如何扩大客户端abtest 的应用范围” 小节,在具备一个成熟的abtest 系统之后,灰度下发的事情 可以交给abtest 来统一完成。
- 已有系统设计中,每一个资源通常都有标记 状态的字段,新增一个“灰度中“状态
- 灰度下发与 原来的portal系统 代码不耦合,portal返回 的数据 经过灰度逻辑的 整合后返回给用户
注意:假设对一个资源进行10%的灰度下发,且一个特定用户命中了10%,则其永远命中10%。当灰度增加到20%时,该用户也应该继续命中。
支持多应用
资源一般属于某个应用维度下,这意味着:
- 资源的创建要与 应用关联
- 系统提供restful api 接口供业务方 代码调用, 调用时应进行权限验证,以避免业务方操作到其它应用的资源
- 权限验证最简单的方式是 向业务方提供appkey 和 app secret
支持多环境
- 支持多环境的目的是 省去同一个资源配置 在多个环境下的重复操作
- 哪些操作可以多环境同步,哪些不能同步,要根据业务区分
数据的组织
对不同的业务 有以下场景:
- 获取所有适配的文件
- 获取某个类型的文件
- 获取某个模块的文件
数据的组织 应该后台界面设计时 有所体现
基本准备
客户端信息 标准化
为了匹配 服务端“资源”,客户端请求是 要携带客户端信息,分为
- 设备信息,比如设备id、andriod/ios、wifi/5g 等
- 应用信息,比如app version、channel 等
- 用户id,以此可以得到用户的画像信息
请求可以采用以下方式携带用户信息
- cookie,难以在各个客户端 共用
- 请求时 以json 描述用户信息
用户画像数据
通常需要根据用户画像数据 下发不同的资源,比如一个资源只下发给会员/新/儿童/上海用户等,此时需要
- 使用统一的枚举类 代表这些画像信息
- 画像信息归属于不同的业务组,应提供一个代理服务,聚合各类画像服务
画像数据如何获取?
- 画像数据由客户端一次请求(加上必要的同步),持久存储,每次请求时携带用户画像数据
- 每次请求时,由系统根据uid 调用画像聚合服务,向请求中注入画像信息,再进行业务匹配
字节基于用户画像标签的分析及业务场景应用 未细读。
安全
-
防篡改
- 更改返回json
- 比如返回json 中有一个图片/视频的url,客户端请求拿到图片url 后再下载图片本身,容易被拦截为非法图片。
一般采用签名来防止 篡改,使用签名 要注意 包含转义字符字符串的 转义问题
权限管理
- 超级管理员 可以做一切事情
- app 管理员 app 范围内可以做一切事情
- 文件某个组织维度的管理员 审核
- 文件创建者 创建、修改
权限的分配一般有两种方式:
- 授权,实现方便,但坑在于:不够直观,开发人员经常被用户打扰要权限。PS:一个典型的维护 影响设计的例子。
- 申请/审批
下发进度统计
测试设备管理
- 测试设备 可以访问到 未发布状态的资源,以备测试人员测试。
- 测试设备信息的 管理可以 在各个项目中共用。
精确到个人的日志记录
后端系统整体设计
后端系统一般由运营人员操作,用来录入数据。有的系统数据简单,对于复杂数据的系统,一般分阶段设计页面,由用户逐步提交数据。比如一个电商业务,采集用户信息,包括:身份信息(姓名,身份证等)、收获地址(可能多个)、兴趣信息等,每个信息一个小的页面/浮动窗口。分阶段提交信息 有几种可能
- 每一个阶段的信息 刚好是一个数据库表,则“下一步”往往意味着保存当前数据到数据库
-
每一个阶段的信息 与 数据库表 不具备明显的一对一关系,则数据的保存与回显 就有点复杂,这时可以
- 前端页面 保存所有数据,在最后提交时 将所有数据一起提交
- 前端每一个阶段都提交一次数据,后端只是保存在缓存里,在最后提交时同步到db。设计思路参见 ddd(三)——controller-service-dao的败笔
整体来说,在实现后端系统时,在有意识的向ddd 靠近,逐步学习ddd的理念。
性能
缓存/打掉缓存
- 为提高性能,一般会使用缓存
- 当用户后台变更资源及状态时,应打掉缓存
-
打掉缓存的方式
- 较短的缓存时间,到期自动重建缓存
- backend 变更操作直接打掉缓存,这种方式无法打掉portal 本地缓存
- backend 通过消息队列通知portal打掉缓存
- portal 监控db主动感知变化,打掉缓存
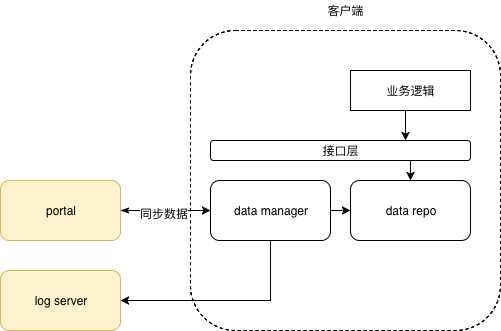
推拉
- app 启动时,发送请求向portal 同步数据。该http请求一般是异步处理的
- 异步带来的问题是:app 启动获取的更改,通常在下次启动之后才会被业务逻辑感知到
- 如果app 与 公司后台维护有长连接,则可以通过长连接 通知app 发生变化,触发app 主动向portal 同步数据
维护
数据采集
汇报方式
- 直接发http请求。客户端在收到推送时会向服务端发送数据(数据分析依据),但对于全局推送,会导致同一时间所有客户端都在向服务端发送请求,打垮nginx。
- 用户行为日志收集
全局关闭开关
警惕app 发版、新数据 对系统的影响
文档
平台支持项目一定要有文档,否则各种新人(不熟悉项目的人)的问题一定“教你做人”,文档包括
- 设计文档
- 接口文档
- 常见错误文档
文档给谁看:
- 接入新的应用时的开发人员
- 业务使用方
- 接管业务的新人
- 测试人员,包括测试项目本身,或者业务项目(依赖了支持类项目)的测试
能界面设计上防止出错的,就别指望用户自觉了
文档表述上,可以多使用图片、脑图等表现力强的展现形式。你或许很反感别人老是来问你认为很简单的事情,但那一定说明你文档写的不够好。
字节工程师自研基于 IntelliJ 的终极文档套件 字节有一个很有脑洞的放那,md中加入 codeRef关键字来引用代码,最终实现代码变更时自动同步(脑洞值得肯定,不过感觉用处一般)
项目管理
平台支持项目与 一般业务系统有以下不同:
- 业务系统 需求来自产品经理,变动也来自产品经理,进度推进与资源协调 也一般由产品经理负责,技术相对省心
- 业务系统 几乎没有 支持工作,平台支持系统多应用的接入 不可避免的会有一些调整及支持
- 业务系统有问题,基本上线之后就可以发现,之后基本稳定,因此可以一人维护多个业务系统。支持类系统 则全周期内维护工作比较多,bug、权限授予、辅助数据查询等
也因此,平台支持类系统 在进度管理、人员分配上与 业务系统有所不同。
生命周期
平台支持类的项目,基本在跟着 客户端发版走,所以很多开发节点 要跟得上 客户端发版。
通用架构
前文都是从 单个项目来考虑的,多个类似的项目放在一起,我们就可以发现,其实有很多共用的部分。
一切皆配置
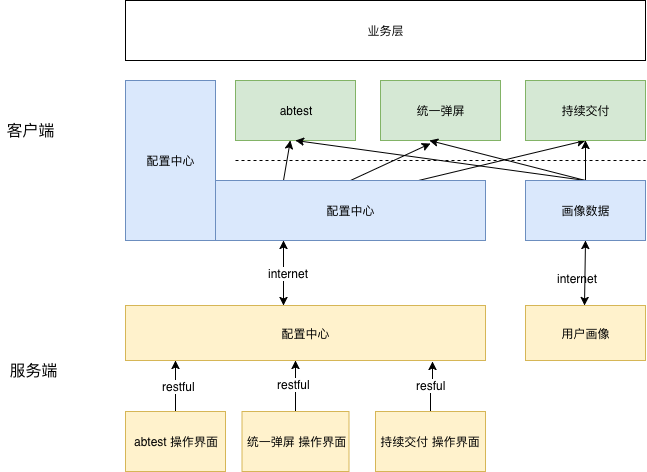
所有业务 以配置形式存在,通过配置中心 下发到客户端,客户端同时拉取 用户画像数据,据此根据 相应的配置数据 进行 匹配,进而产生 相应的业务行为。
各自为政
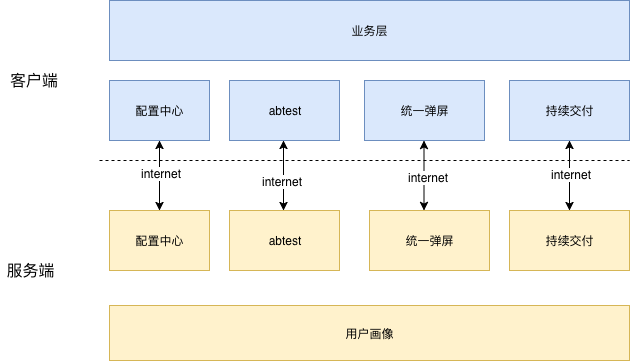
当然,在实际实施的过程作用,还可以有一个变种:即数据还是走配置中心全量下发,客户端另外发请求 查询匹配的数据(下发和匹配过程分开),此时服务端只返回匹配的id 即可。
对比
两个方案 一个侧重客户端,一个侧重服务端。理论上,第一个更轻省些,但对客户端的能力要求较高。业务架构 影响/被影响 团队架构,笔者第一次有如此切身的体会。
小结
支持类系统的意义
大致一个app,小到一个项目都需要支持类系统
- 一个app 需要推送、文件下发、弹屏这类支持系统
- 同一类型项目需要业务相关的支持系统,比如本文的系统都用到了匹配与统计等
- 一个系统需要用户登录注册、权限 这类支持功能
我总结了一下,希望可以做到
- 快速复制一个具备 较强功能的 app 的能力,这体现了一个技术团队的战斗力
- 加快实现一个支持类后台系统的速度
一样与不一样
上文提到了一个平台支持类项目的多个环节,针对每一个环节,在实现的时候,在利弊差不多的情况下,我们尽量使用了不同的实现方案。 比如权限控制,在A系统中我们使用了注解方式来描述权限,在B系统中我们在配置文件中描述权限,然后使用一个权限filter 拦截检查所有的请求。
通过这种方式
- 一个是看到了不同的风景,切身体会到了方案的优缺点
- 促进了优秀方案的沉淀
bug
bug是免不了的
- 自己能力有限
- 协作带来的认知误差
- 环境,比如追求业务速度,负责业务比较多等
如何看待bug
- 自测、他测,从源头上消灭bug
- 在项目运行阶段,提高项目可观察性,提前预判可能出现的问题
- 出现问题后,可一键回退/关闭/清空等。面向故障编程
从案例:百度的评论系统是怎么设计的?来看,我做好多系统的深度是不够的。
API 管理
B站微服务API管理 值得细读。首先需要保证接口元信息完备性和准确性
- 我做的时候吃了大亏,一直在想办法做maven 插件,一键生成api,通过降低维护成本的方式让大家用。有的厂 是让大家提供rpc 服务,有工具自动将rpc 服务转为http 服务,而rpc 一般就有idl 文件,接口数据就最规范、最全了。PS:再低的成本,不如强制定义一套规范。
- 强schema:需要一种统一的编程语言无关的方式来定义服务的接口,它就是文档,而且一定是最新的文档。它需要足够有表达力,又足够简洁明了,其实就是IDL(可选:pb thrift)。json 没有 schema,今天加个字段,明天改个类型,到时候上下游对接都不知道 json里面到底传什么类型。有了idl变更的时候在代码仓库里至少知道改了那个字段,上下游对接只要根据 schema 定义就知道。
- 在IDL的前提下,找生态最好的,支持语言最多的(pb)
- 在2的前提下找性能尽可能高的(不用挑了)
- b 站对java 应用的做法是,使用 swagger 的注解。
留下评论