kvm虚拟化
简介
- 简介
- cpu 虚拟化
- 用 KVM 跑一个函数,再跑一个 Linux
- 从“跑 Linux”到 microVM:直引导 + virtio
- 小结:进程 / 容器 / 虚拟机 三方对比
- 命令行方式创建一个传统虚拟机
- 其它
虚拟化技术的发展
- 主机虚拟化,一台物理机可以被划分为若干个小的机器,每个机器的硬件互不共享,各自安装操作系统
- 硬件虚拟化,同一个物理机上隔离多个操作系统实例
- 操作系统虚拟化,由操作系统创建虚拟的系统环境,使应用感知不到其他应用的存在
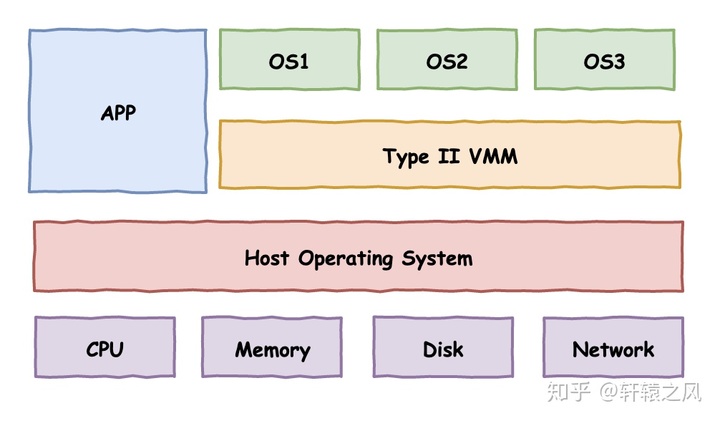
在数据中心里面用的虚拟机,我们通常叫作 Type-1 型的虚拟机,客户机的指令交给虚拟机监视器之后,可以直接由虚拟机监视器去调用硬件,指令不需要做什么翻译工作,可以直接往下传递执行就好了。因为虚拟机监视器需要直接和硬件打交道,所以它也需要包含能够直接操作硬件的驱动程序。所以 Type-1 的虚拟机监视器更大一些,同时兼容性也不能像 Type-2 型那么好。不过,因为它一般都是部署在我们的数据中心里面,硬件完全是统一可控的,这倒不是一个问题了。
在 Type-2 虚拟机里,我们上面说的虚拟机监视器好像一个运行在操作系统上的软件。你的客户机的操作系统呢,把最终到硬件的所有指令,都发送给虚拟机监视器。而虚拟机监视器,又会把这些指令再交给宿主机的操作系统去执行。
cpu 虚拟化
KVM 的「基于内核的虚拟机」是什么意思?早期比较常见的虚拟化解决方案,它的工作原理很简单:把CPU的所有寄存器都写在一组变量中(这组变量我们称为CPUFile),然后用一片内存当作被模拟CPU的内存(这片内存这里称为vMEM),然后在用一些数据结构表示IO设备的状态(这里称为vIO),三者的数据结构综合在一起,就是代表一个虚拟化的环境了(这里称之为VM),之后按顺序读出一条条的指令,根据这个指令的语义,更改VM的数据结构的状态(如果模拟了硬件,还要模拟硬件的行为,比如发现显存被写了一个值,可以在虚拟屏幕上显示一个点等),这样,实施虚拟的那个程序就相当于给被虚拟的程序模拟了一台计算机,这种技术,我称它为“解释型虚拟化技术”。指令是被一条一条解释执行的。随着技术的发展,有人就开始取巧了:很多时候,我们仅仅是在x86上模拟x86,这些指令何必要一条条解释执行?我们可以用CPU直接执行这些指令啊,执行到特权指令的时候,我们直接异常,然后在异常中把当前CPU的状态保存到CPUFile中,然后再解释执行这个特权指令,这样不是省去了很多”解释“的时间了?
KVM 介绍(二):CPU 和内存虚拟化 - Avaten的文章 - 知乎因为宿主操作系统是工作在 ring0 的,客户操作系统就不能也在ring0 了,但是它不知道这一点,以前执行什么指令,现在还是执行什么指令,但是没有执行权限是会出错的。所以这时候虚拟机管理程序(VMM)需要避免这件事情发生。虚机怎么通过 VMM 实现 Guest CPU 对硬件的访问,根据其原理不同有三种实现技术:
- 基于二进制翻译的全虚拟化。客户操作系统运行在 Ring 1,它在执行特权指令时,会触发异常(CPU的机制,没权限的指令会触发异常),然后 VMM 捕获这个异常,在异常里面做翻译,模拟,最后返回到客户操作系统内,客户操作系统认为自己的特权指令工作正常,继续运行。但是这个性能损耗,就非常的大,简单的一条指令,执行完,了事,现在却要通过复杂的异常处理过程。
- 半虚拟化/操作系统辅助虚拟化。修改操作系统内核,替换掉不能虚拟化的指令,通过超级调用(hypercall)直接和底层的虚拟化层hypervisor来通讯,hypervisor 同时也提供了超级调用接口来满足其他关键内核操作,比如内存管理、中断和时间保持。所以像XEN这种半虚拟化技术,客户机操作系统都是有一个专门的定制内核版本,这也是为什么XEN只支持虚拟化Linux,无法虚拟化windows原因,微软不改代码啊。
- 硬件辅助的全虚拟化。2005年后,CPU厂商Intel 和 AMD 开始支持虚拟化了,这种 CPU,有 VMX root operation 和 VMX non-root operation两种模式,VMM 可以运行在 VMX root operation模式下,客户 OS 运行在VMX non-root operation模式下。因为 CPU 中的虚拟化功能的支持,并不存在虚拟的 CPU,KVM Guest 代码是运行在物理 CPU 之上。对 KVM 虚机来说,运行在 VMX Root Mode 下的 VMM 在需要执行 Guest OS 指令时执行 VMLAUNCH 指令将 CPU 转换到 VMX non-root mode,开始执行客户机代码 ==> 运行某些指令或遇到某些事件时 ==> 硬件自动挂起 Guest OS ==> 切换到 VMX root operation 模式 ,恢复VMM 的运行 (而不是cpu 直接报错) ==> VMM 将操作转到 guest os 对应的内存、设备驱动等。
总结一下:cpu 虚拟化的核心难点是特权指令,对于特权指令,guest os 要么改自己不执行特权指令,要么VMM 为cpu 报错擦屁股,要么cpu 不报错。
《编程高手必学的内存知识》
在虚拟化技术中涉及的有三个核心角色,分别是宿主机Host,客户机Guest和虚拟机监控器 (Virtual Machine Monitor , VMM)。VMM负责为客户机准备虚拟 CPU,虚拟内存等虚拟资源,并同时对客户机进行管理。
- 我们可以很容易想到一个实现虚拟化技术的方案是:通过纯软件模拟 CPU 执行过程。也就是说,这里需要对完整的底层硬件进行模拟,包括处理器、物理内存和外部设备等等。这样的话,Guest 的所有程序都相当于运行在 Host 的一个解释器里,来一条指令就解释一条指令,资源限制以及运行等价的要求都很容易满足。不过这个方案的缺陷也非常明显,因为你是用软件来对 CPU 的指令进行了翻译,通常一条指令最终会被翻译成非常多的指令,那效率自然也是非常低的。既然对指令进行翻译的效率是如此低下,那我们为什么不能让 Guest 程序的代码直接运行在 Host 的 CPU 上呢?我们本来翻译指令的目的,是为了让 VMM 能够对 Guest 执行的指令进行监管,防止 Guest 对计算资源的滥用,那如果又让 Guest 的执行直接运行在 CPU 上,VMM 又哪里有机会能够对 Guest 进行监管呢?
- 为了解决这个问题。人们提出一个重要的模型,这就是陷入模拟(Trap-and-Emulate)模型。将 Guest 运行的指令进行分类,一类是安全的指令,也就是说这些指令可以让 Host 的 CPU 正常执行而不会产生任何副作用,例如普通的数学运算或者逻辑运算,或者普通的控制流跳转指令等;另一类则是一些“不安全”的指令,又称为“Trap”指令,也就是说,这些指令需要经过 VMM 进行模拟执行,例如中断、IO 等特权指令等。接下来,我们来看一下它的具体实现过程:
- 对于“安全”的指令,Guest 在执行时可以交由 Host 的 CPU 正常运行,这样可以保证大部分场景的性能。
- 不过,当 Guest 执行一些特权指令时就需要发出 Trap,通知 VMM 来接管 Guest 的控制流。VMM 会对特权指令进行模拟 (Emulate),从而达到资源控制的效果。当然在进行模拟的过程中需要保证执行结果的等价性。比如”int 0x80”这条指令就是一个特权指令,它会导致当前进程切入内核态执行。在虚拟化场景下遇到这种特权指令,我们不能直接交给宿主机的真实 CPU 去执行,因为宿主机 CPU 会使用宿主机的 IDT 来处理这次中断请求。而我们真正希望的是,使用客户机的 IDT 去查找相应的中断服务程序。这就需要 Guest 退回到 VMM,让 VMM 模拟 CPU 的动作去解析 IDT 中的中断描述符,找到 Guest 的中断服务程序并调用它。在这个例子中,Geust 退回 VMM 的操作就是 Trap,VMM 模拟 CPU 的动作去调用 Guest 的中断服务程序就是 Emulate。
- 不过,这里仍然存在一个问题:当 Guest 的内核代码在 Host 的 CPU 上执行的时候,Guest 没有办法区分“安全”指令和“非安全”指令,也就是说 Guest 不知道哪条指令应该触发 Trap。幸好,现代的芯片对这种情况做了硬件上的支持。现代的 X86 芯片提供了 VMX 指令来支持虚拟化,并且在 CPU 的执行模式上提供了两种模式:root mode 和 non-root mode,这两种模式都支持 ring 0 ~ ring 3 三种特权级别。VMM 会运行在 root mode 下,而 Guest 操作系统则运行在 non-root mode 下。所以,对于 Guest 的系统来讲,它也和物理机一样,可以让 kernel 运行在 ring 0 的内核态,让用户程序运行在 ring 3 的用户态, 只不过整个 Guest 都是运行在 non-root 模式下。有了 VMX 硬件的支持,Trap-and-Emulate 就很好实现了。Guest 可以在 non-root 模式下正常执行指令,就如同在执行物理机的指令一样。当遇到“不安全”指令时,例如 I/O 或者中断等操作,就会触发 CPU 的 trap 动作,使得 CPU 从 non-root 模式退出到 root 模式,之后便交由 VMM 进行接管,负责对 Guest 请求的敏感指令进行模拟执行。这个过程称为 VM Exit。而处于 root 模式下的 VMM,在一开始准备好 Guest 的相关环境,准备进入 Guest 时,或者在 VM Exit 之后执行完 Trap 指令的模拟准备,再次进入 Guest 的时候,可以继续通过 VMX 提供的相关指令 VMLAUNCH 以及 VMResume,来切换到 non-root 模式中由 Guest 继续执行。 这个过程也被称为 VM Entry。
PS:这段把Host、Guest和VMM的协作方式说清楚了,但是VMM 如何帮助Guest 操作外设没提。
Guest 内存管理 未读。
KVM + QEMU
kvm两大组件
- 内核中实现的一个KVM模块
- 用户态的QEMU工具 KVM(Kernel-based Virtual Machine)利用修改的QEMU提供BIOS、显卡、网络、磁盘控制器等的仿真,但对于I/O设备(主要指网卡和磁盘控制器)来说,则必然带来性能低下的问题。因此,KVM也引入了半虚拟化的设备驱动,通过虚拟机操作系统中的虚拟驱动与主机Linux内核中的物理驱动相配合,提供近似原生设备的性能。从此可以看出,KVM支持的物理设备也即是Linux所支持的物理设备。
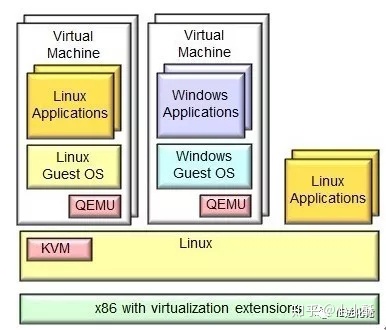
为了简化代码,KVM 在 QEMU 的基础上做了修改。VM 运行期间,QEMU 会通过 KVM 模块提供的系统调用进入内核,由 KVM 负责将虚拟机置于处理的特殊模式运行。遇到虚机进行 I/O 操作,KVM 会从上次的系统调用出口处返回 QEMU,由 QEMU 来负责解析和模拟这些设备。从 QEMU 的角度看,也可以说是 QEMU 使用了 KVM 模块的虚拟化功能,为自己的虚机提供了硬件虚拟化加速。除此以外,虚机的配置和创建、虚机运行说依赖的虚拟设备、虚机运行时的用户环境和交互,以及一些虚机的特定技术比如动态迁移,都是 QEMU 自己实现的。
guest os 与 物理机cpu 之间vmm 如何发挥作用的,还没找到直观感觉(未完成)。vm 是一个进程,vCpu 是其中的一个线程,由VMM 管理,这个味道咋跟docker 这么一样呢?
KVM原理简介 写的更好一些。KVM是作为一个内核模块出现的,所以它还得借助用户空间的程序QEMU 来和用户进行交互。QEMU是一套由法布里斯·贝拉(Fabrice Bellard)所编写的以GPL许可证分发源码的模拟处理器,在GNU/Linux平台上使用广泛。其本身是一个纯软件的支持CPU虚拟化、内存虚拟化及I/O虚拟化等功能的用户空间程序。借助KVM提供的虚拟化支持可以将CPU、内存等虚拟化工作交由KVM处理,自己则处理大多数I/O虚拟化的功能,可以实现极高的虚拟化效率。
- 正常我们在执行WFI指令时会使CPU进入一个低功耗的状态,但是对于HOST OS来说,如果让CPU真正进入低功耗状态,显然会影响其他VM的运行。如果我们配置了HCR_EL2.TWI==1时,那么Guest OS在执行WFI时就会触发EL2的异常,然后陷入(PS: 感觉跟异常调用一样)Hypervisor,那么此时Hypervisor就可以将对应VCPU所处的线程调出出去,将CPU让给其他的VCPU线程使用。PS: Hypervisor 感觉就是提供了 系统调用处理这个场景
- 内存虚拟化的目的是给虚拟客户机操作系统提供一个从0开始的连续的地址空间,同时在多个客户机之间实现隔离与调度。arm主要通过Stage 2转换来提供对内存虚拟化的支持,其允许Hypervisor控制虚拟机的内存视图,而在这之前则是使用及其复杂的影子页表技术来实现。Stage 2转换可以控制虚拟机是否可以访问特定的某一块物理内存,以及该内存块出现在虚拟机内存空间的位置。这种能力对于虚拟机的隔离和沙箱功能来说至关重要。这使得虚拟机只能看到分配给它自己的物理内存。为了支持Stage 2 转换, 需要增加一个页表,我们称之为Stage 2页表。操作系统控制的页表转换称之为stage 1转换,负责将虚拟机视角的虚拟地址转换为虚拟机视角的物理地址。而stage 2页表由Hypervisor控制,负责将虚拟机视角的物理地址转换为真实的物理地址。虚拟机视角的物理地址在Armv8中有特定的词描述,叫中间物理地址(intermediate Physical Address, IPA)。
- I/O虚拟化,有四种方案:设备模拟,比如qemu 模拟具体的I/O设备的特性;前后端驱动接口;设备直接分配,将一个物理设备直接分配给Guest OS使用;设备共享分配,其主要就是让一个物理设备可以支持多个虚拟机功能接口,将不同的接口地址独立分配给不同的Guest OS使用。如SR-IOV协议。
汇总下
硬件辅助虚拟化(Intel VT-x)给 CPU 两个模式:root(跑 VMM)和 non-root(跑整个 guest)。guest 的普通指令、以及大部分特权指令都直接在物理 CPU 上原生执行,只有”敏感”操作(真实 I/O、访问未映射内存等)才触发 VM Exit 陷出到 VMM 处理。cpu/mem/io(虚拟化)操作入口都是指令执行
- guest 普通指令。 non-root mode + ring3, 物理 CPU 直接跑,add/mov/jmp、算术逻辑、用户态访存等
- guest 非敏感特权指令。 non-root + ring0, 物理 CPU 直接跑。 cli/sti(开关本地中断)、lidt/lgdt/ltr(装自己的 IDT/GDT)等。
- guest 敏感特权指令。 non-root + ring0, 触发 VM Exit → 切到 root,会触及宿主/别的 VM/真实硬件/全局状态,必须让 VMM 接管。
- 2和3的边界是 VMCS 配的,不是写死的。除少数无条件陷出(cpuid/vmcall),”哪些算敏感”由 VMM 通过 VMCS 的 I/O bitmap / MSR bitmap / 各种 exec controls 决定。 业界的演进就是把第3类指令转为第2类。
用 KVM 跑一个函数,再跑一个 Linux
前面《编程高手必学的内存知识》那段一直没找到“VMM 到底怎么发挥作用”的直观感觉。其实把 KVM 当成一个“能让物理 CPU 去跑任意机器码”的设备来用,一下就通了。
/dev/kvm:用户态进内核的唯一入口
KVM 是一个内核模块,它对外只暴露一个字符设备 /dev/kvm。所有用户态程序(QEMU、Firecracker,以及下面这个最小 VMM)想用上 CPU 的硬件虚拟化能力,唯一的办法就是 open("/dev/kvm") 拿到一个 fd,然后全程用 ioctl 跟它打交道——没有别的接口。
这些 ioctl 按作用域分三层,每层对应一个 fd(拿到上一层 fd 才能开下一层):
- system fd(
open("/dev/kvm")得到):全局能力。KVM_GET_API_VERSION、KVM_CREATE_VM、KVM_GET_VCPU_MMAP_SIZE等。 - vm fd(对 system fd 发
KVM_CREATE_VM得到):一台虚机级别。KVM_SET_USER_MEMORY_REGION(给 guest 配内存)、KVM_CREATE_VCPU、建虚拟中断控制器等。 - vcpu fd(对 vm fd 发
KVM_CREATE_VCPU得到):一个 vCPU 级别。KVM_RUN(让它跑)、KVM_GET/SET_REGS/SREGS(读写寄存器)等。
用法范式就一句话:ioctl(某层 fd, KVM_XXX, 参数)。下面骨架里 open → CREATE_VM → SET_USER_MEMORY_REGION → CREATE_VCPU → KVM_RUN,正好把这三层 fd 顺着走了一遍。
前提:宿主 CPU 支持并开启了硬件虚拟化(Intel VT-x / AMD-V),内核也加载了 kvm + kvm_intel/kvm_amd 模块,系统里才会有 /dev/kvm 这个设备节点。很多云主机/容器里没透传虚拟化、压根没有这个节点,就用不了 KVM 加速,只能退回纯软件模拟(前面说的二进制翻译那条慢路)——所以判断“这台机器能不能跑 microVM”,第一道关就是 ls /dev/kvm。
有了这层认识,一个最小的用户态 VMM 骨架就这么几步(QEMU 本质也是这套,只是把设备模拟做全了):
int kvm = open("/dev/kvm", O_RDWR);
int vmfd = ioctl(kvm, KVM_CREATE_VM, 0);
// 给 guest 一块“物理内存” = host 上 mmap 的一段;guest 看到的 GPA → host 的 HPA 由 EPT 翻译
void *mem = mmap(...);
ioctl(vmfd, KVM_SET_USER_MEMORY_REGION, ®ion); // region.guest_phys_addr = 0x1000
int vcpufd = ioctl(vmfd, KVM_CREATE_VCPU, 0); // 一个 vCPU = 后面一个线程在跑它
struct kvm_run *run = mmap(..., vcpufd, 0); // VM Exit 的信息就写在这块共享内存里
while (1) {
ioctl(vcpufd, KVM_RUN, NULL); // CPU 进 non-root 跑 guest;返回 = 一次 VM Exit
switch (run->exit_reason) { ... } // 读 exit_reason,VMM 来“擦屁股”
}
ioctl(KVM_RUN) 返回的那一刻就是一次 VM Exit;exit_reason 告诉你 guest 撞了哪条敏感(第 3 类)指令;switch 里写的就是 VMM 该做的事。第 1/2 类指令根本不返回、对性能免费。“vm 是进程、vCPU 是线程”就落在这里:某个线程在 ioctl(KVM_RUN)。
例子:用 KVM 跑一个 sum(n) 函数
int sum(int n){ int s=0; while(n){ s+=n; n--; } return s; } 编成 16 位机器码,正好 8 字节:
; 入参 bx=n 出参 ax=sum
31 C0 xor ax,ax ; s=0
01 D8 add ax,bx ; s+=n ┐
4B dec bx ; n-- │ 循环体,全是第 1/2 类指令
75 FB jnz -5 ; n!=0 ┘
F4 hlt ; 完事,叫 VMM 来取结果 ← 唯一的第 3 类
host 侧跟上面骨架一样,只多“传参 / 跑 / 取返回值”三步:
const uint8_t func[] = {0x31,0xC0, 0x01,0xD8, 0x4B, 0x75,0xFB, 0xF4};
memcpy(mem, func, sizeof(func));
struct kvm_regs regs = { .rip=0x1000, .rbx=5, .rflags=0x2 }; // ① 传参:n=5
ioctl(vcpufd, KVM_SET_REGS, ®s);
while (1) { ioctl(vcpufd, KVM_RUN, NULL); // ② 跑
if (run->exit_reason == KVM_EXIT_HLT) break; } // 跑到 hlt = 返回
ioctl(vcpufd, KVM_GET_REGS, ®s); // ③ 取返回值
printf("sum(5)=%d\n", (int)(regs.rax & 0xffff)); // → 15
n=5 要跑 5 轮 add/dec/jnz,这 15 条指令全程零 VM Exit——它们在 non-root 由物理 CPU 原生执行,KVM 根本不插手;整个函数只有最后 hlt 把 VMM 叫醒一次。所以“用 KVM 跑一个函数”就是一套调用约定:
| 函数概念 | KVM 对应 |
|---|---|
| 传参(走寄存器) | KVM_SET_REGS 设 rbx |
| 函数体执行 | guest 字节在 non-root 原生跑,无 VM Exit |
| return | hlt → KVM_EXIT_HLT(约定“我跑完了”) |
| 取返回值 | KVM_GET_REGS 读 rax |
| “调用”这个动作 | ioctl(KVM_RUN) |
hlt 本是第 3 类敏感指令,这里被借用成了“函数返回”的信号——这就是 VMM 和 guest 之间最朴素的一次握手。
从一个 func 到一个 Linux main
把这个例子放大,就是 KVM 跑 Linux——机制完全一样,区别只在“字节多大、参数多复杂、跑完会不会停”:
| 上面的 sum 函数 | Linux 内核 | |
|---|---|---|
| guest 字节 | 8 字节机器码 | 几 MB 的 bzImage(VMM 自己 load 进内存,不走 BIOS/GRUB) |
| “参数” | rbx=n | rsi → boot_params(内存布局 / initramfs 位置 / cmdline) |
| 函数体 | 一个循环 | 一个永不返回的 main()(调度、跑进程……) |
| return | hlt | 不 hlt——一直跑 |
| 取结果 | KVM_GET_REGS 读 ax |
不断 KVM_EXIT_IO/MMIO:它要读写设备(串口、virtio 磁盘/网卡) |
所以 Linux 不过是一个“大号、不返回、还会不停做 I/O 的 main()”:VMM 把内核字节放进 guest 内存、用 boot_params 当“参数”、KVM_RUN 让 CPU 去跑;guest 自己的普通/特权指令在 non-root 原生跑,只有遇到 I/O 等敏感操作才陷出来让 VMM(KVM + QEMU)模拟。microVM(如 Firecracker)就是把这套做到极致:内核直接引导(省掉 BIOS/GRUB)、设备模型砍到只剩 virtio——本质仍是这个 KVM_RUN 循环。
启动一个容器就是启动一个 ENTRYPOINT/CMD 进程(数据 在mount namespace 挂好了),linux 启动一个进程(fork + execve)是创建一个task struct,各种信息配好,然后把task struct.pc 拨到一个合适位置,等着linux 调度task struct。启动一个vm = 内核建 struct kvm + 每 vCPU 一个 struct kvm_vcpu。VMM 进程里跑着 1 个管理/IO 线程(跑 VMM 那段ioctl 管理程序)+ 每 vCPU 一个 vCPU 线程(都是 task_struct,被 Linux 正常调度)。vCPU 线程一被调度,就 KVM_RUN → VMENTER → CPU 在 non-root 从 guest rip(指向guest os内核入口)开始跑 guest。
从“跑 Linux”到 microVM:直引导 + virtio
上一节的 KVM_RUN 循环已经是 VMM 的心脏。要变成一个真能用的 microVM(如 Firecracker),只差两件事:内核怎么进来、设备怎么来。
直引导:跳过 BIOS 和 GRUB
真机启动 = 上电 → BIOS(自检、枚举硬件)→ GRUB(读盘、菜单)→ 内核,几秒起。microVM 让 VMM 自己当 bootloader:把内核 bzImage 直接 load 进 guest 内存、填好 boot_params(内存布局 / initramfs 位置 / cmdline)、rip 指向内核 64 位入口——BIOS、GRUB 全省掉。这套约定叫 Linux/x86 boot protocol,RustVMM 的 linux-loader 替你干。
initramfs 里的 /init 就是 guest 的 PID 1,要跑的 init / agent 程序塞这。再加上下面只有 virtio、不枚举 PCI 的设备模型,整个冷启压到 ~125ms。
virtio:填上那个空的 KVM_EXIT_MMIO 分支
Virtqueues and virtio ring: How the data travels 内核要磁盘/网卡/控制台。模拟真硬件的话,guest 每戳一次寄存器就 VM Exit,太慢;virtio 改成 host 和 guest 共用一块内存里的环批量传请求:
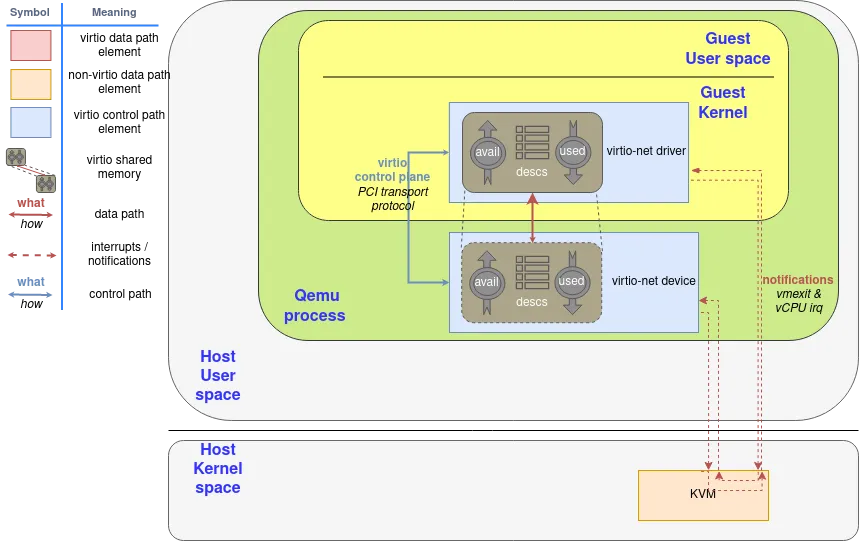
一次读盘:guest 把请求填进描述符表、把头索引塞进 avail 环 → 写 QueueNotify 寄存器敲门铃(落到上一节那个空的 KVM_EXIT_MMIO 分支)→ host 读环、pread 镜像文件、把数据直接写进 guest 缓冲(guest 内存就是 host 的 mmap,host_addr = mmap基 + (GPA-基))→ 把结果塞进 used 环 → KVM_IRQ_LINE 注入完成中断。门铃进、中断出——正好一个指令入口加一个事件入口。再用 ioeventfd / irqfd 把门铃和中断挪进内核、设备后端独立线程跑,vCPU 就能一直满速。
microVM 的设备就这么几个 virtio:blk(盘)/ net(网)/ vsock(host↔agent,见下)/ 串口。没有 PCI、没有 GPU——既是启动快(不枚举 PCI),也是攻击面小的来源。
vsock:host↔guest 的控制通道(不走网络)
有盘有网之后还差一件事:host 上的控制面要能指挥 guest 里的 agent 跑命令、读写文件、管生命周期。用网络(virtio-net + TCP)也行,但要给每个 sandbox 分 IP、配路由、设防火墙,重且脏;而且你想把 sandbox 网络完全封死时,控制通道也跟着断了。于是 microVM 普遍另开一条专用通道:vsock。
vsock 是一个专给 host↔guest 用的 socket 协议族 AF_VSOCK,用法跟 TCP 一样,只是寻址不用 IP 而用 (CID, port):host 永远是 CID 2,每个 guest 分一个 CID(≥3)。它落地为第 4 个 virtio 设备 virtio-vsock,机制和上面 virtio 一模一样(virtqueue + 门铃 + 中断),只是搬运的是 socket 字节流。host 侧怎么接?以 Firecracker 为例,host 开一个 Unix domain socket 做多路复用,写 CONNECT <port> 就接到 guest 里 listen 该 port 的进程——全程不碰网络。
host (控制面) guest (microVM)
控制进程 agent (PID 1,即 initramfs 的 /init)
│ 普通 Unix socket │ listen vsock:<port>,跑 ttrpc
└────── virtio-vsock(队列+门铃+中断)────────┘
收到 exec → 在 guest 里 fork+exec → stdout 回流 vsock
业务流量另走 virtio-net
落到实现:guest 里那个 agent 是 PID 1(就是直引导那节 initramfs 里的 /init),listen 一个 vsock 端口、上面常跑 ttrpc(containerd 那套轻量 RPC,kata-agent 等也用);host 控制面经 vsock 给它发 exec/文件/生命周期请求。两个平面分开:控制面走 vsock,业务面走 virtio-net(容器里业务服务的端口)。
这正好和容器的 kubectl exec 形成对照:容器共享内核,host 用 runc exec(setns)直接钻进去执行,不需要 pod 内有 agent;microVM 是独立内核,host 跨不进 guest 边界、setns 没用,必须在里面预先放一个 agent,经 vsock 喊它替你 fork+exec。一个“从外面伸手进去”,一个“在里面安插内应”。
启动快 + 省内存:snapshot + CoW
冷启压到 ~125ms 之后还能更快:干脆不 boot。一台 VM 的完整状态就两块——vCPU 寄存器(KVM_GET_REGS/SREGS/...,KB 级)+ guest 内存(就是那块 host mmap,dump 成文件)+ 一点设备状态。存下来就是 snapshot;新实例直接 KVM_SET_* 灌回寄存器、把内存文件映射回来、KVM_RUN,就恢复到拍快照那一刻、跳过整个 boot。(其实就是前面 sum 函数里 KVM_GET_REGS 取返回值的放大版:那次读 1 个寄存器,snapshot 读全部状态。)
光这样 restore 还是慢(拷整份内存)又费(每实例一份)。两个机制把它做到又快又省:
- CoW:把快照内存文件用
mmap(..., MAP_PRIVATE)映射成 guest 内存。所有实例共享同一份基底页,某实例写某页时内核才复制那一页(copy-on-write)。→ N 个实例 = 一份共享基底 + 各自脏页增量,内存只占一份,restore 也不用拷整份。 - UFFD(userfaultfd):注册 guest 内存后 VM 立即 resume,页按需 fault-in——guest 摸到未加载的页才从快照文件读进来。→ restore 几 ms 返回,没摸到的页永不加载(“申请 2G、实际用几百 M”的画像正合适)。
- 拍快照本身用脏页追踪(
KVM dirty log/ soft-dirty)做增量,只 dump 变化的页。CRIU、Firecracker diff snapshot 都靠它。
于是一个“热模板”玩法:boot 一次模板 VM 到就绪 → 拍快照 → 每个新实例从快照 fork(restore + CoW + UFFD),几 ms 起、共享基底内存;空闲实例还能 pause-to-disk(拍快照 + 释放 RAM)。
为什么能同时压启动和省内存?因为是同一件事——不在运行时构建状态,而是预烤成快照、再 CoW 共享、按需懒加载:
| 看时间轴(快) | 看空间轴(省) |
|---|---|
| restore 代替 boot(跳过 kernel boot / init / 应用 warmup) | 一份基底被多实例共享 |
| CoW 立即返回,不等整份内存拷完 | 实例只付脏页增量 |
| UFFD 页按需 fault,不阻塞 resume | 没摸的页不占 RAM |
所以“几 ms 热启”和“MB 级边际开销”本是同一个 CoW 引擎的两面。代价是冷页长尾(首访从快照 fault,微小延迟)和内存超卖的赌注(实例同时摸满工作集就 CoW 塌缩、可能 OOM),收益高低取决于真实工作集和空闲比。
小结:进程 / 容器 / 虚拟机 三方对比
把前面两件事——“VM 是一个进程、vCPU 是线程”和“VMM 不是 dockerd”——并起来,横向对比“直接跑在 host 的进程 / 容器 / 虚拟机”三种执行模型:
| 维度 | 进程(直接跑 host) | 容器(docker) | 虚拟机(VM) |
|---|---|---|---|
| 隔离机制 | 无 | namespace + cgroup(共享 host 内核) | KVM / VT-x(独立 guest 内核) |
| 在 host 上是什么 | 一个 host 进程 | runc 拉起的 host 进程(套 namespace) | 一个 VMM 进程,guest 跑在它内部(vCPU=线程、guest 内存=它 mmap 的一段) |
| host 看得到内部进程吗 | —(它本身就是) | 看得到,容器进程就是 host 进程 | 看不到,只见 1 个 VMM 进程 + vCPU 线程 |
| 怎么“进去”执行命令 | 直接 fork/exec | host setns 钻进 namespace(docker / k8s exec) |
跨不进,需 guest 内 agent 经 vsock |
| guest 做 I/O | 直接 syscall | 直接 syscall(共享内核) | VM Exit 后由 VMM 进程做 host syscall |
| 管理 / 编排守护进程 | init / systemd | dockerd / containerd(一个 daemon 管很多容器) | libvirtd / 外部编排(每个 VM fork 一个 VMM 进程) |
| 隔离强度 / 边际开销 | 无 / 最低 | 中(可逃逸)/ 低 | 强 / 较高,snapshot + CoW 可压到 ms 级 |
一句话:容器把工作负载直接摊在 host 上(共享内核、host 直接可见、可 setns 进去);虚拟机把工作负载塞进一个 VMM 进程内部(自带内核、host 穿不透)。 所以 VMM 对应的是“runc + 容器进程”这个运行体,而不是 dockerd——dockerd 那个管家角色,在 VM 世界对应的是 libvirtd / 外部编排器。
命令行方式创建一个传统虚拟机
qemu 创建传统虚拟机流程(virtualbox是一个图形化的壳儿)
# 创建一个虚拟机镜像,大小为 8G,其中 qcow2 格式为动态分配,raw 格式为固定大小
qemu-img create -f qcow2 ubuntutest.img 8G
# 创建虚拟机(可能与下面的启动虚拟机操作重复)
qemu-system-x86_64 -enable-kvm -name ubuntutest -m 2048 -hda ubuntutest.img -cdrom ubuntu-14.04-server-amd64.iso -boot d -vnc :19
# 在 Host 机器上创建 bridge br0
brctl addbr br0
# 将 br0 设为 up
ip link set br0 up
# 创建 tap device
tunctl -b
# 将 tap0 设为 up
ip link set tap0 up
# 将 tap0 加入到 br0 上
brctl addif br0 tap0
# 启动虚拟机, 虚拟机连接 tap0、tap0 连接 br0
qemu-system-x86_64 -enable-kvm -name ubuntutest -m 2048 -hda ubuntutest.qcow2 -vnc :19 -net nic,model=virtio -nettap,ifname=tap0,script=no,downscript=no
# ifconfig br0 192.168.57.1/24
ifconfig br0 192.168.57.1/24
# VNC 连上虚拟机,给网卡设置地址,重启虚拟机,可 ping 通 br0
# 要想访问外网,在 Host 上设置 NAT,并且 enable ip forwarding,可以 ping 通外网网关。
# sysctl -p
net.ipv4.ip_forward = 1
sudo iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
# 如果 DNS 没配错,可以进行 apt-get update
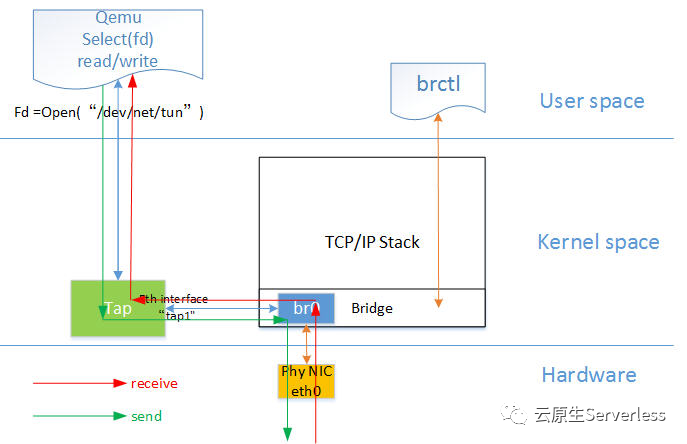
可以看到至少在网络配置这个部分,传统虚拟机跟容器区别并不大
其它
QEMU尽管非常的强大,但也正是应为它的强大导致其对初学者非常的不友好。这里推荐大家刚开始学习KVM时可以先学习kvm tool,这是一个基于C语言开发的KVM虚拟化工具,其代码非常精简易懂,同时也可以支持完整的linux虚拟化,非常适合初学者入门使用。其项目地址为https://github.com/kvmtool/kvmtool。
- 神龙架构从CPU手头接过虚拟化的重任,一路带飞存储、网络、安全等关键性能。
- 到今天为止,最适合做DPU的还是可编程可升级的FPGA。 从 VMWare 到阿里神龙,虚拟化技术 40 年演进史
留下评论