换个角度看待设计模式
前言
世事纷扰,但总有几个线头。兵法多样,就那几个套路。
| 设计模式 | 军事 | |
|---|---|---|
| 战术 | 二十三个设计模式 | 三十六计 |
| 战略 | 4个原则 | 以正合以奇胜 |
以正合,以奇胜。以奇胜,被人们误读为奇袭得胜,还是贪巧求速的心理作怪。以奇胜的奇,不念qi,念ji,是个数学词汇,奇数、偶数的奇,古人又称为“余奇”,多余的部分,正兵安排好了,余下来的就是奇兵,关键的时候用。 简单地说,奇(ji)兵,不是出奇制胜的部队,是预备队。孙子的意思是:不要一下子把所有的牌都打完了,留一张在手上,关键时候打出去。 “奇正之变,不可胜穷也。奇正相生,如环之无端。” 奇正之间怎么相互转化呢?其实很简单,已经投入战斗的,是正兵;预备队,是奇兵。预备队投上去,就变为正兵了。正在打的部队撤下来,又变成奇兵。
因为每个人自身的能力、所在的层次、看问题的角度都不同,仅凭直觉“对现实建模”,很有可能会生成一些大小不均、职责不清、关系混乱的对象,最后搭建出一个虽然可以运行,但却难以理解、难以维护的系统。所以,设计模式就是为此而生的。它系统地描述了一些软件开发中的常见问题、应用场景和对应的解决方案,给出了专家级别的设计思路和指导原则。不能说绝对是“最优解”,但至少是“次优解”。
分类方式
《Pattern Oriented Software Architecture》中提到,将模式分为三种类型:
- 体系结构模式,比如mvc
- 设计模式
- 惯用法,比如引用计数法
Design patterns were originally grouped into the categories: creational patterns, structural patterns, and behavioral patterns, and described using the concepts of delegation, aggregation, and consultation
Design patterns are composed of several sections . Of particular interest are the Structure, Participants, and Collaboration sections. These sections describe a design motif:
- a prototypical micro-architecture that developers copy and adapt to their particular designs to solve the recurrent problem described by the design pattern.
- A micro-architecture is a set of program constituents (e.g., classes, methods…) and their relationships.
- Developers use the design pattern by introducing in their designs this prototypical micro-architecture, which means that micro-architectures in their designs will have structure and organization similar to the chosen design motif.
http://design-patterns.readthedocs.io/zh_CN/latest/ 传统分类方式分别对应了开发面向对象系统的三个关键问题:如何创建对象、如何组合对象,以及如何处理对象之间的动态通信和职责分配。
- 创建型模式,创建型模式(Creational Pattern)对类的实例化过程进行了抽象,能够将软件模块中对象的创建和对象的使用分离单一职责原则,仅一个对象的创建独立出来,催生了spring的ioc,减少了代码中的创建类代码)。在创建什么(What),由谁创建(Who),何时创建(When)等方面都为软件设计者提供了尽可能大的灵活性。
-
结构型模式(Structural Pattern)描述如何将类或者对 象结合在一起形成更大的结构,它关注的是对象的静态联系,以灵活、可拆卸、可装配的方式组合出新的对象。虽然它会有多个参与者,但最后必定得到且使用的是“一个”对象,而不是“多个”对象。结构型模式可以分为类结构型模式和对象结构型模式
- 类结构型模式关心类的组合,一般只存在继承关系和实现关系.
- 对象结构型模式关心类与对象的组合,通过关联关系使得在一 个类中定义另一个类的实例对象(也就是成员变量),然后通过该对象调用其方法。
-
行为型模式(Behavioral Pattern)是对在不同的对象之间划分责任和算法的抽象化(所以一般先定义好高层接口,定义好交互关系)。行为型模式不仅仅关注类和对象的结构(涉及到结构设计,但不是重点),而且重点关注它们之间的相互作用。它描述了对象之间动态的消息传递,也就是对象的“行为”、工作的方式。行为型模式分为类行为型模式和对象行为型模式两种:
- 类行为型模式:类的行为型模式使用继承关系在几个类之间分配行为,类行为型模式主要通过多态等方式来分配父类与子类的职责。
- 对象行为型模式:对象的行为型模式则使用对象的聚合关联关系来分配行为,对象行为型模式主要是通过对象关联等方式来分配两个或多个类的职责。
根据“合成复用原则”,系统中要尽量使用关联关系来取代继承关系,因此大部分结构/行为型设计模式都属于对象结构/行为型设计模式。
如何写好单元测试?设计模式最重要的点还是在于解耦和复用,创建型模式将创建代码与使用代码解耦,结构型模式是将功能代码解耦,行为型模式将行为代码解耦,最终达到高内聚,松耦合的目标,设计模式体现了设计原则。我们经常说的“高内聚 松耦合”究竟什么是高内聚,什么是松耦合?
- 高内聚:相近功能放在同一类中,相近功能往往会被同时修改,放到同一个类中在修改时,代码更易维护(指导类本身的设计)。PS:比如将两个字段拼成一个字符串来作为map的key,“将两个字段拼成字符串”和“将字符串解析为两个字段”的方法就一定要放在一起,这样可以改一个,就知道需要改另一个。
- 松耦合:类与类之间的依赖关系简单清晰,一个类的代码改动不会或者很少导致依赖类的代码修改(指导类间依赖关系设计)。PS:假设一个A类里有List成员,不要在B类里
a.getList().add(element)这样操作,A类尽量写成充血模型,否则List 换成Map了,B类恨不能也要重写。
成为通用术语
从技术演变的角度看互联网后台架构20多年前的经典著作DesignPatterns中讲过学习设计模式的意义:学习设计模式并不是要你学习一种新的技术或者编程语言,而是建立一种交流的共同语言和词汇,在方案设计时方便沟通,同时也帮助人们从更抽象的层次去分析问题本质,而不被一些实现的细枝末节所困扰。同时,当我们能把很多问题抽象出来之后,也能帮我们更深入更好地去了解现有系统。
圣杯与银弹——没用的设计模式设计模式作为通用的术语确实可以增加不同工程师之间的沟通效率,但是降低沟通成本的前提是双方对同术语有着相同的并且正确的认识,如果双方的理解有差异,反而会制造更多的困惑。我们可以将 23 种不同的设计模式分成两部分来分析,其中一部分是单例模式、抽象工厂模式这些被广泛接受并理解的模式,另一部分是迭代子模型、命令模式和解释器模式等不容易被理解的复杂模式。从单例模式以及观察者模式的命名,我们就能猜到它们想要解决的问题,使用类似的术语也很难造成歧义,确实能够起到提高沟通效率的作用;不过,对于复杂的设计模式想要正确理解就非常困难,更不用说用来沟通了。
软件设计之美
如果用数学来比喻的话,设计原则就像公理,它们是我们讨论各种问题的基础,而设计模式则是定理,它们是在特定场景下,对于经常发生的问题给出的一个可复用的解决方案。设计模式之所以能成为一个特定的解决方案,很大程度上是因为它是一种好的做法,符合软件设计原则,所以,设计原则其实是这些模式背后的东西。
学习设计模式,我们应该有一个更开阔的视角:要看到语言的局限,虽然设计模式本身并不局限于语言,但很多模式之所以出现,就是受到了语言本身的限制。比如,Visitor 模式主要是因为 C++、Java 之类的语言只支持单分发,也就是只能根据一个对象来决定调用哪个方法。而对于支持多分发的语言,Visitor 模式存在的意义就不大了。PS:比如golang有了channel,则观察者订阅者模式的意义就不大了。
Annotation 可以说是消灭设计模式的一个利器。语言本身的局限造成了一些设计模式的出现,这一点在 Java 上表现得尤其明显。随着 Java 自身的发展,随着 Java 世界的发展,有一些设计模式就越来越少的用到了。比如,Builder 模式通过 Lombok 这个库的一个 Annotation 就可以做到:
@Builder
class Student {
private String name;
private int age;
...
}
Decorator 模式也可以通过 Annotation 实现,比如,一种使用 Decorator 模式 的典型场景,是实现事务,很多 Java 程序员熟悉的一种做法就是使用 Spring 的 Transactional
class Handler {
@Transactional
public void execute() {
...
}
}
所以,我们学习设计模式除了学习标准写法的样子,还要知道,随着语言的不断发展,新的写法变成了什么样子。
底层逻辑
可能你在学习设计模式的时候还是有些困惑,设计模式是专家经验的总结不假,但专家们是如何察觉、发现、探索出这些模式的呢?有没有什么更一般的思想来指导我们呢?换句话说,有没有“设计‘设计模式’的模式”呢?其实,这些更高层次的指导思想你可能也听说过,它们被通称为“设计原则”。最常用有 5 个原则,也就是常说的“SOLID”。
- SRP,单一职责(Single ResponsibilityPrinciple);简单来说就是“不要做多余的事”,更常见的说法就是“高内聚低耦合”。在设计类的时候,要尽量缩小“粒度”,功能明确单一,不要设计出“大而全”的类。使用单一职责原则,经常会得到很多“短小精悍”的对象,这时候,就需要应用设计模式来组合、复用它们了,比如,使用工厂来分类创建对象、使用适配器、装饰、代理来组合对象、使用外观来封装批量的对象。
- OCP,开闭(Open Closed Principle);LSP,通常的表述是“对扩展开放,对修改关闭”,你可以反过来理解这个原则,在设计类的时候问一下自己,这个类封装得是否足够好,是否可以不改变源码就能够增加新功能。如果答案是否定的(要改源码),那就说明违反了开闭原则。应用开闭原则的关键是做好封装,隐藏内部的具体实现细节,然后开放足够的接口,这样外部的客户代码就可以只通过接口去扩展功能,而不必侵入类的内部。
- 里氏替换(Liskov Substitution Principle);意思是子类必须能够完全替代父类。就是说子类不能改变、违反父类定义的行为。
- ISP,接口隔离(Interface-Segregation Principle);目标是尽量简化、归并给外界调用的接口,避免写出大而不当的“面条类”。
- DIP,依赖反转,有的时候也叫依赖倒置(Dependency Inversion Principle)。上层要避免依赖下层的实现细节,下层要反过来依赖上层的抽象定义。模板方法模式可以算是比较明显的依赖反转的例子,父类定义主要的操作步骤,子类必须遵照这些步骤去实现具体的功能。如果单从“解耦”的角度来理解的话,存在上下级调用关系的设计模式都可以算成是依赖反转,比如抽象工厂、桥接、适配器。
从DDD战略设计划分边界的视角来审视SOLID
| 原则 | 对应的划分视角 | 架构层面的关键解释 |
|---|---|---|
| SRP单一职责 | 边界按什么原则拆 | 边界按变化源而不是功能名称来划;降低耦合 |
| OCP开闭原则 | 边界能否承受迭代(稳定性) | 判断边界是否能承受未来演化;稳定区和变化区分离 |
| LSP里氏替换 | 边界靠什么协作(抽象) | 边界靠抽象协作;抽象的语义必须清晰稳定 |
| ISP接口隔离 | 边界对下游暴露到什么粒度 | 面向不同下游提供最小必要契约,而非大而全接口 |
| DIP依赖倒置 | 边界之间依赖的方向 | 指定模块间依赖流向,使边界站得住 |
除了 SOLID 这五个之外,我觉得还有两个比较有用:DRY(Don’t Repeate Yourself)和 KISS(Keep It Simple Stupid)。它们的含义都是要让代码尽量保持简单、简洁,避免重复的代码。
- 过程式就是过分强调了how,一开始就思考怎么去做,过程式思维是以自己为中心,导演了整个功能流程,自己承担了太多自己不应该承担的职责,整个设计就显得不灵活。面向对象是从对象的角度去看问题,解决问题是由各个对象协作完成,设计模式的基石就是面向对象,脱离了面向对象去谈设计模式那是耍流氓。
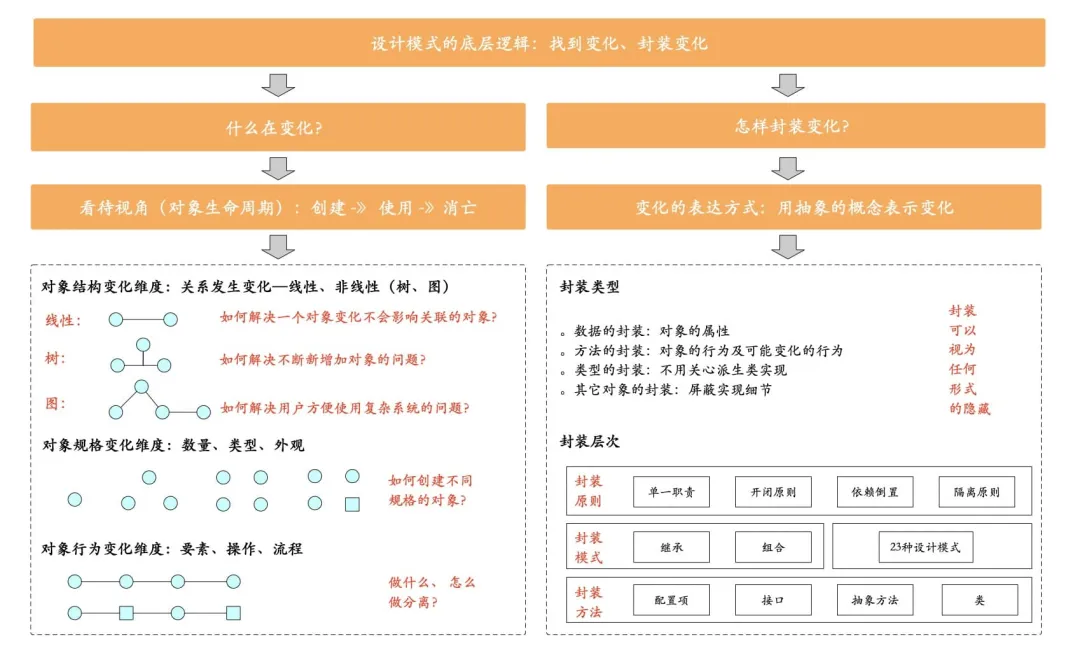
- “找到变化,封装变化”,这才是设计模式的底层逻辑
- 过程式编码的优点就是 “简单,好理解,易于修改”:在过程式编码中,代码片段是拥有上下文的全部信息的,设计模式则 通常上下文信息有限。 设计模式一般都会应用比较高级的语言特性,而过程式编码只需要会基本语法就可以写了。
- 业务逻辑不会因为过程式编码而变得更加简单,“过程式代码更加好理解”往往只是针对某个代码片段的,当我们将范围扩大到一个模块,甚至整个系统时,其中会包含大量的代码片段,如果这些代码片段全部是无模式的过程代码,理解成本会成倍增加,相似的模式则能大大降低理解成本,越大的代码库从中的收益也就越大。过程式编码只是短期比较好理解,因为没有设计模式的学习成本,但是长期来看,因为它没有固定的模式,理解成本是更高的;
- “设计模式” 作为对抗 “软件复杂度” 恶龙的少年,可能业务发展,缺乏演进等原因,最终自己腐坏成了新的 “恶龙”。
- 在互联网野蛮发展时期,大量的人才和热钱涌入,软件快速上线比一切都重要,开发效率的问题,只要招聘更多的人就能解决,哪怕在一个公司开发好几套功能一样的系统。但是随着互联网人口红利的消失,不再有充足的资源去承接业务,我们就不得不做好精耕细作的准备,扎实地累积自己的产品和技术优势,继续创造下一个十年的辉煌。
其它
许式伟:我个人不太喜欢常规意义上的 “设计模式”。或者说,我们对设计模式常规的打开方式是有问题的。理解每一个设计模式,都应该放到它想要解决的问题域来看。所以,我个人更喜欢的架构范式更多的是 “设计场景” 的总结。“设计场景” 和设计模式的区别在于它有自己清晰的问题域定义,是一个实实在在的通用子系统。是的,这些 “通用的设计场景”,才是架构师真正的武器库。如果我们架构师总能把自己所要解决的业务场景分解为多个 “通用的设计场景” 的组合,这就代表架构师有了极强的架构范式的抽象能力。而这一点,正是架构师成熟度的核心标志。
圣杯与银弹——没用的设计模式软件系统中处处都是设计,学习设计模式无法让我们成为优秀的工程师,如果我们错误的理解了这本书的目的,以为自己学到了软件设计或者面向对象设计的精髓,那就大错特错了。软件设计的能力并不是一朝一夕就能培养出来的,它需要我们不断对代码进行思考,理解可能存在的扩展点并设计合理的抽象。PS:面向扩展点设计。圣杯与银弹——没用的设计模式 对设计模式做了一定的批评,对“单元测试”推崇有加,提升项目单元测试覆盖率的过程会让我们思考如何写出更利于测试的代码,虽然软件工程中没有银弹,但是单元测试不是银弹可能也所差无几了。
圣杯与银弹——没用的设计模式抽象的设计模式是从不同具体项目中总结出来的通用经验,从具体到抽象的过程相对容易,然而从抽象的模式套用到具体场景却很困难,如果没有足够的经验或者思考只会做出拙劣的设计。而且并不是居高临下的架构设计才是系统设计,每个包、方法甚至代码中的空行中都体现了作者的设计思路,抽象的理论和模式能够起到指导的作用,但是真正让设计融入系统的还是工程师的丰富经验和深入思考。
21 世纪诞生的一些编程语言与过去的编程语言有着很大的不同,不仅新的编程语言开始接收函数式编程中的一些思想和设计,上个世纪诞生的编程语言也在吸纳不同的编程范式,函数和方法成为了语言中的一等公民,我们可以直接向函数中传递函数来简化过去复杂的类关系。比如观察者模式函数式编程的设计模式
object.OnUpdate(func(u *updates) {
...
})
- 转移复杂度是徒劳的。Kent Beck 在《实现模式》一书中提到的 Local Consequence:希望一个改动能够局部化影响。这包括你要做这个修改,需要阅读的代码,或者需要获得的知识边界,能够局限在一个局部。同时也包括你的源代码改动本身,不是一个散落到各个代码仓库,这一点那一点的片段。然而这个愿望是永远不可能达成的。如果目标是任何改动都能实现 Local Consequence ,这是绝无可能实现的。你总是要决定什么和什么放在一起的。不可能一个东西和所有其他东西都放在一起。当代码组织成方便了一类改动的时候,必然会让另外一类改动像是意大利面条似的。正因为无法让所有改动都实现 Local Consequence,所以得依赖经验去判断发生变化的频率。尽量让高频的改动变成是容易的。但是又怎么能未卜先知,提前知道什么是会高频变化的呢?如果你相信这种花大力气整一个架构,搞出一个笨拙的家伙去预测不靠谱的未来是徒劳的。那么是不是所谓的 Simple Design,堆一堆毕业生按直觉本能,996 堆砌代码逻辑其是更好的策略呢。简单,直接,有效。
留下评论