Prometheus 告警学习
前言
本文主要来自《Prometheus 监控实战》
告警能力在Prometheus的架构中被划分成两个独立的部分。通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
alert rule
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
groups:
- name: node_alerts
rules:
- alert: HighNodeCPU
expr: instance:node_cpu:avg_rate5m > 80
for: 60m
labels:
severity: warning
annotations:
summary: High Node CPU for 1 hour
console: You might want to check the Node Dashboard at http://grafana.example.com/dashboard/db/node-dashboard
- for 控制在触发警报之前 测试表达式必须为true的时间长度
- label 和 annotations 用来装饰警报,
- 与metric类似,警报上的标签与警报的名称相结合,构成警报的标识
以上述 HighNodeCPU 为例,alert 的生命周期如下:
- node的cpu 不断变化,metric 每隔scrape_interval=15s 被Prometheus 抓取一次
- 根据每个evaluation_interval=15s的 metric来评估alert rule
- 当alert rule 为true时(即cpu超过80%),会创建一个alert 并转换到pending 状态,执行 for 子句
- 在下一个evaluation_interval中,如果alert rule=true,则检查for 的持续时间,如果超过则alert 转换为Firing,生成通知并将其推送到Alertmanager。在Prometheus web界面 可以看到这个alert 及其状态
- 如果alert rule 不再为true,则alert 状态转为Inactive
Prometheus 将为 Pending和 Firing状态中的每个警报创建metric, 这个metric 被称为ALERT ,比如ALERT{alertname="HighNodeCPU",alertstate="firing",severity="warning",instance="xx"} 每个alert metric都具有固定值1,并且在警报处于Pending或Firing状态期间存在。在此之后,它将不 接收任何更新,并且最终会过期。
Alertmanager
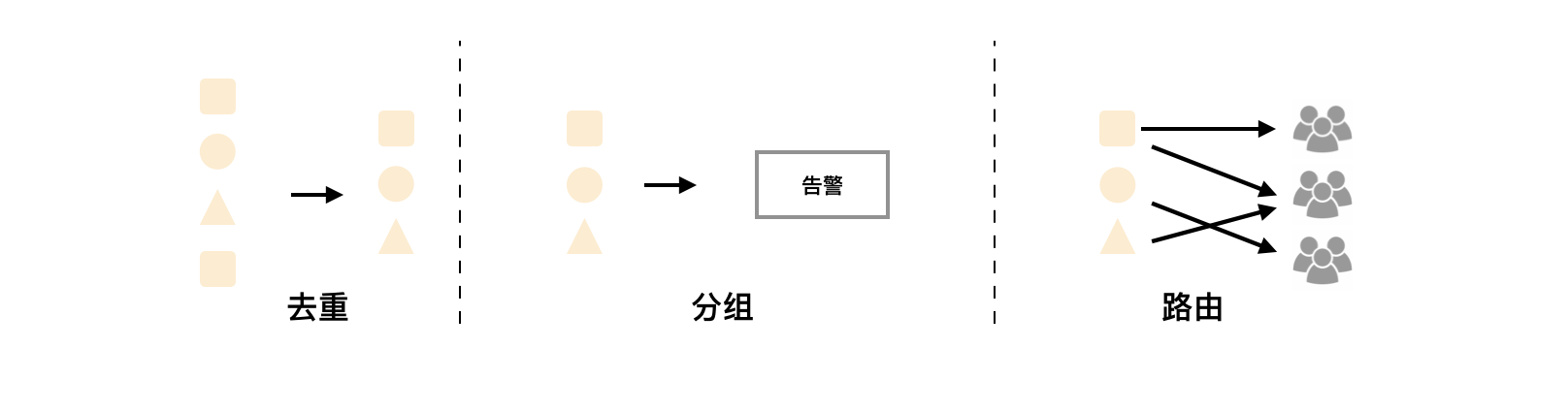
Alertmanager作为一个独立的组件,负责接收并处理(去重、分组、路由(基于alert携带的标签将告警发给不同的receiver)、抑制、静默)来自Prometheus Server(也可以是其它的客户端程序)的告警信息。 PS:Prometheus 有HA 的部署模式,使用 两个或多个配置相同的Prometheus服务器来收集时间序列数据,生成的报警自然会重复。
global:
smtp_smarthost: 'localhost:25'
smtp_from: 'alertmanager@example.com'
smtp_require_tls: false
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
receiver: email
receivers:
- name: 'email'
email_configs:
- to: 'alerts@example.com'
模板
模板(template)是一种在警报中使用时间序列数据的标签和值的方法,可用于注解和标签。模板 使用标准的Go模板语法,并暴露一些包含时间序列的标签和值的变量。标签以变量$labels形式表示, 指标的值则是变量$value。
groups:
- name: node_alerts
- alert: InstanceDown
expr: up{job="node"} == 0
for: 10m
labels:
severity: critical
annotations:
summary: Host of is down!
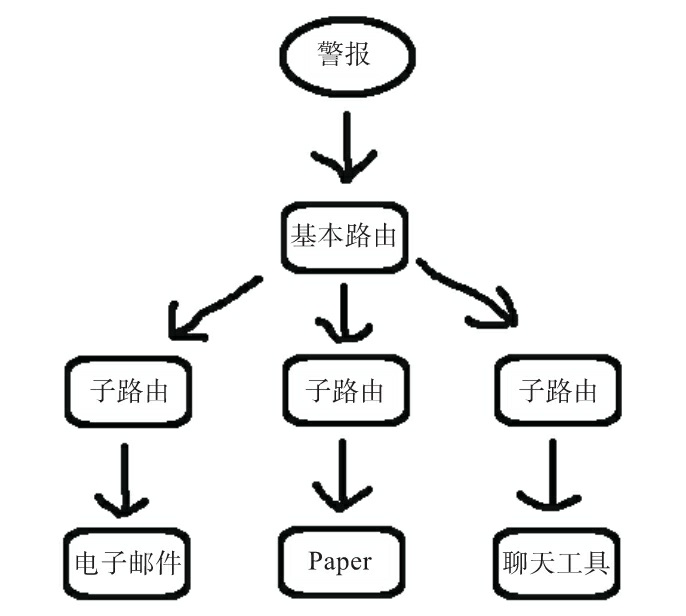
路由
路由是一棵树。顶部的默认路由总会被配置,并匹配任何子路由不匹配的内容。
route:
group_by: ['instance']
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receiver: email
routes:
- match:
severity: critical
receiver: pager
- match_re: # 表示正则表达式匹配
severity: ^(warning|critical)$
recevier: support_team
receivers:
- name: 'email'
email_configs:
- to 'alerts@example.com'
- name: 'support_team'
email_configs:
- to 'support@example.com'
- name: 'pager'
email_configs:
- to 'alert-pager@example.com'
- group_by 控制的是 Alertmanager 分组警报的方式。默认情况下,所有警报都组合在一起,但如果我们指定了group_by 和任何标签,则Alertmanager将按这些标签对警报进行分组 。
- 如果引发了新警报 , 那么Alertmanager将等待group_wait=30s,以便在触发警报之前查看是否收到该组中的其他警报。你可以将其视为 警报缓冲。
- 在发出警报后,如果收到来自该分组的下一次评估的新警报,那么Alertmanager将等 待group_interval=5m,然后再发送新警报。这可以防止警报分组的警报泛滥。
其它
prometheus 本身的报警机制基本能够满足各种报警需求,唯一的缺憾就是 配置变更要通过 修改配置文件 以及reload prometheus server,国内开源了Qihoo360/doraemon 来解决该问题。
留下评论