消息/任务队列
简介
linux的消息队列
进程间通信的三大手段之一(共享内存、信号和消息队列),对于不同的通信手段,进程消费“通信数据”的方式不同。
- 共享内存 聊聊跨进程共享内存的内部工作原理
- 消息队列和管道的区别:
- 管道的中间介质是文件。
- 消息队列是消息缓冲区,在内存中以队列的形式组织,传输时以消息(一个数据结构)为单位。
本地队列
本地队列的几种应用场景
- 存储数据,单纯的利用下先进先出特性
-
缓存任务/消息,缓解生产者和消费者的速度差异,便于消费者批量处理,通常用于消费者需要进行文件io或网络io的场景
- log4j,调用线程将日志加入到队列中,由write线程批量写入日志
- kafka producer
一个功能完善的队列通常要解决以下问题:
- 有界队列还是无界队列
- 多生产者和消费者的并发生产和消费问题。有界队列的线程安全问题,核心无非是生产和消费两个操作,对于入队操作,最关键的要求是不能覆盖没有消费的元素;对于出队操作,最关键的要求是不能读取没有写入的元素。所以一定会维护类似出队索引和入队索引这样两个关键变量。
- 性能问题,一般涉及到对硬件机制的利用,比如缓存批量读取、伪共享、cas等
- ArrayBlockingQueue 使用数组作为底层的数据存储,Disruptor 是使用 RingBuffer 作为数据存储。RingBuffer 本质上也是数组,仅仅将数据存储从数组换成 RingBuffer 并不能提升性能。生产者线程向 ArrayBlockingQueue 增加一个元素,每次增加元素 E 之前,都需要创建一个对象 E,如下图所示,ArrayBlockingQueue 内部有 6 个元素,这 6 个元素都是由生产者线程创建的,由于创建这些元素的时间基本上是离散的,所以这些元素的内存地址大概率也不是连续的。RingBuffer 这个数组中的所有元素在初始化时是一次性全部创建的,所以这些元素的内存地址大概率是连续的。生产者线程通过
publishEvent()发布 Event 的时候,并不是创建一个新的 Event,而是通过event.set()方法修改 Event, 也就是说 RingBuffer 创建的 Event 是可以循环利用的,这样还能避免频繁创建、删除 Event 导致的频繁 GC 问题。 -
解决伪共享。对于 ArrayBlockingQueue,当 CPU 从内存中加载 takeIndex 的时候,会同时将 putIndex 以及 count 都加载进 Cache。假设线程 A 运行在 CPU-1 上,执行入队操作,入队操作会修改 putIndex,而修改 putIndex 会导致其所在的所有核上的缓存行均失效;此时假设运行在 CPU-2 上的线程执行出队操作,出队操作需要读取 takeIndex,由于 takeIndex 所在的缓存行已经失效,所以 CPU-2 必须从内存中重新读取。入队操作本不会修改 takeIndex,但是由于 takeIndex 和 putIndex 共享的是一个缓存行,就导致出队操作不能很好地利用 Cache,这其实就是伪共享。简单来讲,伪共享指的是由于共享缓存行导致缓存无效的场景。如何避免伪共享呢?缓存行填充。每个变量独占一个缓存行、不共享缓存行就可以了。
// ArrayBlockingQueue final Object[] items; /** 队列数组 */ int takeIndex; /** 出队索引 */ int putIndex; /** 入队索引 */ int count; /** 队列中元素总数 */ -
java内置队列 都采用加锁方式实现线程安全,Disruptor采用cas实现线程安全。Disruptor 中的 RingBuffer 维护了入队索引,但是并没有维护出队索引,这是因为在 Disruptor 中多个消费者可以同时消费,每个消费者都会有一个出队索引,所以 RingBuffer 的出队索引是所有消费者里面最小的那一个。
do { //生产者获取n个写入位置 current = cursor.get(); //cursor类似于入队索引,指的是上次生产到这里 next = current + n; //目标是在生产n个 long wrapPoint = next - bufferSize; //减掉一个循环 long cachedGatingSequence = gatingSequenceCache.get(); //获取上一次的最小消费位置 if (wrapPoint>cachedGatingSequence || cachedGatingSequence>current){ //没有足够的空余位置 ... } else if (cursor.compareAndSet(current, next)){ //获取写入位置成功,跳出循环 break; } } while (true); -
cas玩了一些花活儿:
- 环形数组(ring buffer),这里环形不是首位相顾,数组通过下标访问,Disruptor的“下标”会一直递增,通过“下标%数组长度”得到实际的数组index。数组长度2^n
- 假设ring buffer长度为length,则还有一个length bit的数组available buffer,用于标记ring buffer 对应下标的元素是否被生产者占用。意图就是,java内置队列加锁,同一时刻数组只能被一个线程访问。而ring buffer允许多个线程同时访问,通过检查 available buffer是否被其他线程捷足先登(通过新增数据结构,来感知竞争激烈程度),然后重试。将加锁 改为 探测-重试
消息队列中间件
基于内存或磁盘的队列,为分布式应用提供通信手段。
消息模型
消息模型可以分为两种, 队列和发布-订阅式。
- 队列,此时队列单纯的是一个”削峰”的作用
-
发布-订阅模型,在producer 和 consumer 之间提取一个独立的第三方。可以看到,相对于“生产消费者”的生产消费,有一个订阅的过程来描述消费者的兴趣,不是producer发的所有消息消费者都会接

体现在实现上,一个rabbitmq为例
1. rabbitmq producer和 consumer 都明确绑定exchange 2. rabbitmq producer发消息时,除了消息本身,要通过routingkey描述消息的“特征”。
rabbitmq的发布订阅模式
- Exchange、Queue与Routing Key三个概念是理解RabbitMQ消息投递的关键。
- RabbitMQ中一个核心的原则是,消息不能直接投递到Queue中。
- Producer只能将自己的消息投递到Exchange中,由Exchange按照routing_key投递到对应的Queue中
- 在Consumer Worker中,声明自己对哪个Exchange感兴趣,并将自己的Queue绑定到自己感兴趣的一组routing_key上,建立相应的映射关系;
- 在Producer中,将消息投递一个Exchange中,并指明它的routing_key。
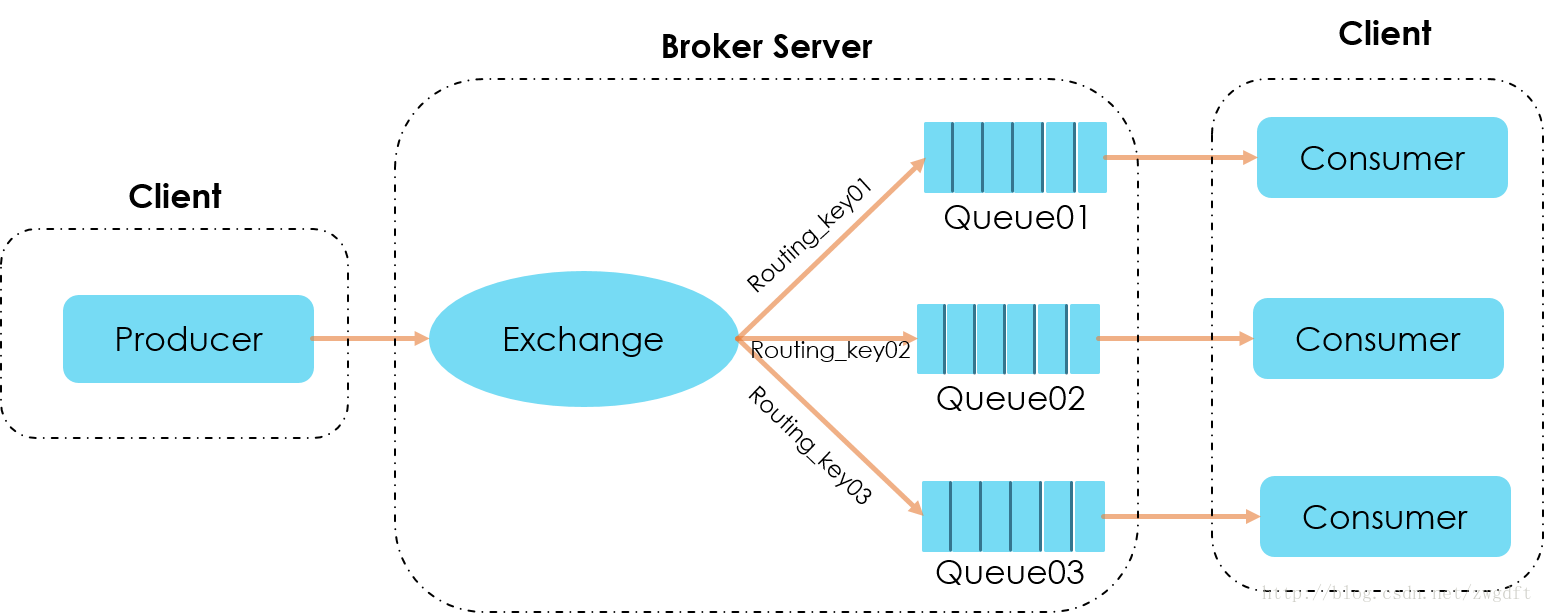
Queue这个概念只是对Consumer可见,Producer并不关心消息被投递到哪个Queue中
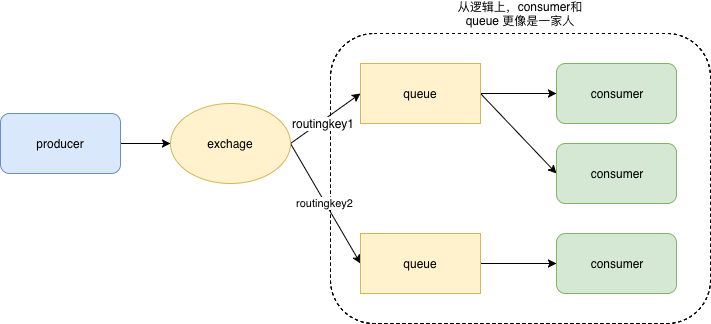
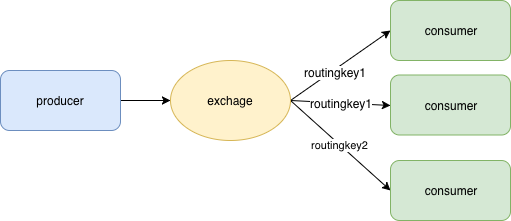
只保留逻辑概念的话
kafka的发布订阅模型
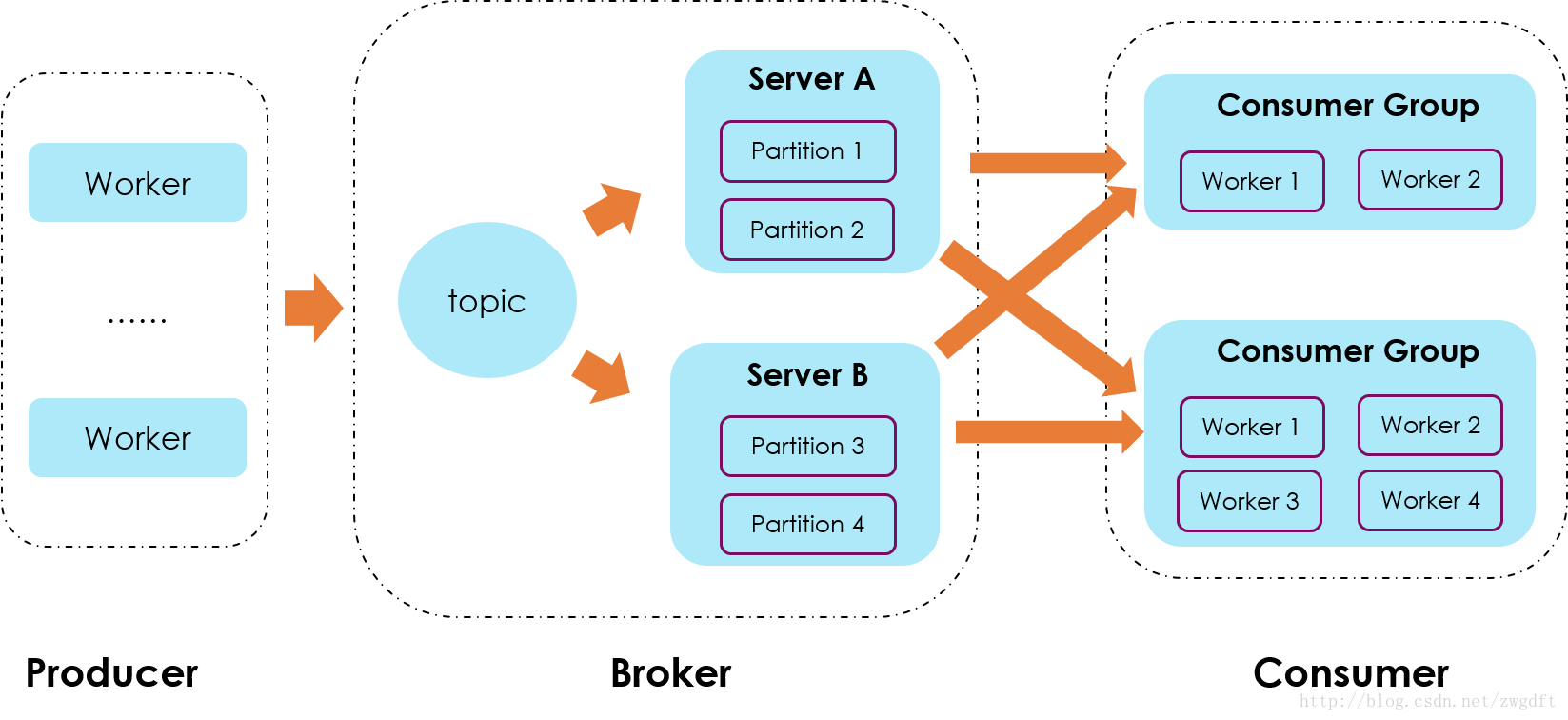
kafka 中partition 是物理上的概念,仅从逻辑概念上看
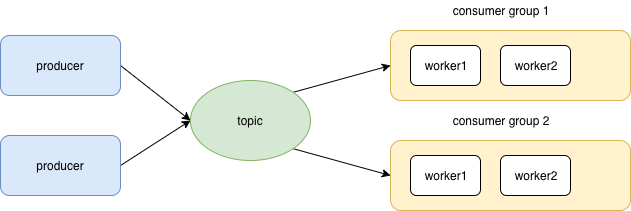
所有接入topic 的consumer group 都会收到消息,producer 没有类似routingkey 可以进行topic 内部 consumer group的指定,因此Kafka只提供了广播和单播(一对一广播)的消息模型,不支持组播(消息只发给topic 内的特定n个consumer group)。因此对于复杂场景,一般rabbitmq 项目只需要一个exchange即可,而kafka 通常要多个topic,所以kafka topic 其实跟 rabbitmq的 routingkey 逻辑上作用更像。
发布订阅模型小结
- 两者都包含 物理概念和逻辑概念
- producer 只负责向逻辑概念发布数据
- consumer 一般与物理概念紧密关联,并绑定相关的逻辑概念(exchange + routingkey/topic,也就是订阅自己感兴趣的“事件”)
消息中间件的选型
笔者一度很迷kafka,并打算用其替换项目中的rabbitmq,但实际上kafka 不是银弹,比如其不支持优先级队列,而这个feature 在某些业务场景下很重要。
选型消息中间件 应该注意哪些问题 可以参见消息中间件选型分析——从Kafka与RabbitMQ的对比来看全局
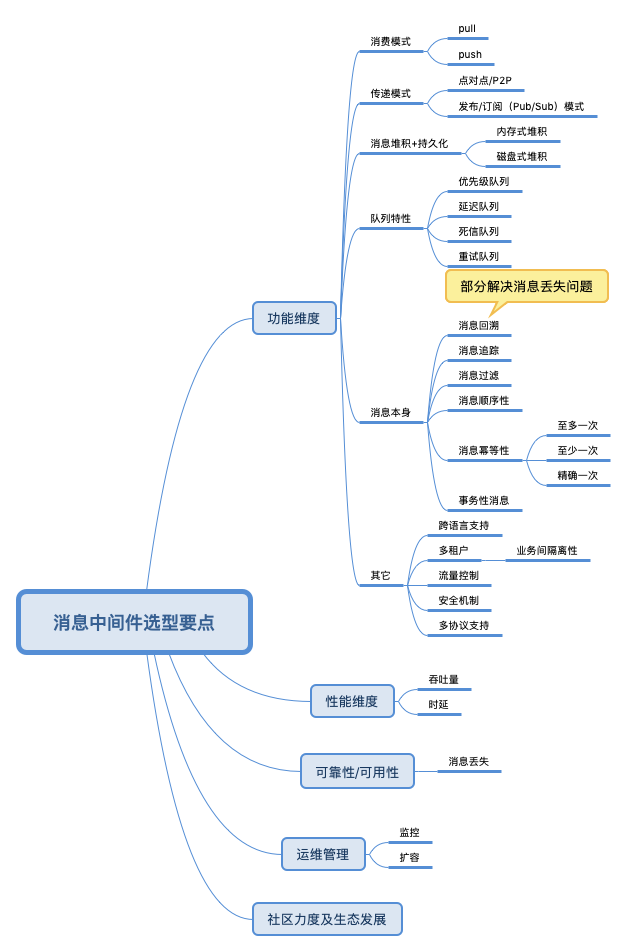
消息中间件犹如小马过河,选择合适的才最重要,这需要贴合自身的业务需求,技术服务于业务。RabbitMQ在于routing,而Kafka在于streaming,了解其根本对于自己能够对症下药选择到合适的消息中间件尤为重要。从功能维度上来说,RabbitMQ的优势要大于Kafka,但是Kafka的吞吐量要比RabbitMQ高出1至2个数量级,一般RabbitMQ的单机QPS在万级别之内,而Kafka的单机QPS可以维持在十万级别,甚至可以达到百万级。
消息中间件选型切忌一味的追求性能或者功能,性能可以优化,功能可以二次开发。如果要在功能和性能方面做一个抉择的话,那么首选性能,因为总体上来说性能优化的空间没有功能扩展的空间大。然而对于长期发展而言,生态又比性能以及功能都要重要。
消息队列监控
rabbitmq
channel 接口本身 也提供
// 队列未消费的消息数
long messageCount(String queue) throws IOException;
// 队列消费者个数
long consumerCount(String queue) throws IOException;
RabbitMQ 有灵活的插件机制,启用 rabbitmq-management 就可以对服务进行监控和管理。http://rabbitmq_host:15672/api/ 展示了rabbitmq 的http api 列表,基本具备所有 Rabbitmq java client 功能。http api的优势在于,可以在队列的消费实例之外构建专门的监控系统。
- 所有的请求需要授权,请求的返回数据都是json
- 很多请求返回的都是一个列表,你可以在请求中 加入sort 和 sort_reverse 为返回数据排序
- 默认vhost 使用%2f 代替
curl -i -u guest:guest http://ip:port/api/queues/%2f/queue_name 返回值 json
{
...
"consumers":xx
"state":xx,
"vhost":xx,
"durable":xx,
"auto_delete":xx
"messages_unacknowledged":xx,
"messages_unacknowledged_details":{
"rate":xx
},
"messages_ready":xx,
"messages_ready_details":{
"rate":xx
},
"messages":xx,
"messages_details":{
"rate":xx
}
...
}
据此,就可以对队列拥堵,consumer 实例是否正常 来做出预警。
其它
消息队列系统有很多,主要有以下不同:
- 消息队列存在哪?内存、磁盘?
- 是否支持分布式
- 消息的格式是什么?
- 系统是否能够确保:消息一定会被接收,消息未被正确处理时通知发送方。
至于kafka、flume和rabbitmq等系统,网上资料很多,此处不再赘述。
留下评论