kubevela中cue的应用
简介
BCL 全名 Borg Configuration Language,是 Google 内部基于 GCL (Generic Configuration Language) 在 Borg 场景的实践。用户通过 BCL 描述对 Borg 的使用需求,通过基于 BCL 的抽象省去对 Borg 复杂配置细节的感知提高单位效率,通过工程化手段满足可抽象、可复用、可测试的协作方式提高团队效率和稳定性,并在其上建立了相应的生态平台,作为 Borg 生态的重要抽象层在 Google 内部服务了超过 10 年,帮助 Google 内部数万开发者更好的使用 Infra。CUE 是一种服务于云化配置的强类型配置语言,由 Go team 成员 Marcel van Lohiuzen 结合 BCL 及多种其他语言研发并开源,可以说是 BCL 思路的开源版实现。PS:大家都对直接使用yaml 的方式不满意。
基本使用
数据类型
cue 的基本数据类型
// first.cue
a: 1.5
a: float
b: 1
b: int
d: [1, 2, 3]
g: {
h: "abc"
}
e: "abc"
如何自定义 CUE 类型?使用 # 符号来指定一些表示 CUE 类型的变量
#abc: {
x: int
y: string
z: {
a: float
b: bool
}
}
开放性和封闭性 未读。
渲染
$ cue eval first.cue
a: 1.5
b: 1
d: [1, 2, 3]
g: {
h: "abc"
}
e: "abc"
默认情况下, 渲染结果会被格式化为 JSON 格式。
$ cue export first.cue
{
"a": 1.5,
"b": 1,
"d": [
1,
2,
3
],
"g": {
"h": "abc"
},
"e": "abc"
}
渲染为yaml 格式
$ cue export first.cue --out yaml
a: 1.5
b: 1
d:
- 1
- 2
- 3
g:
h: abc
e: abc
与k8s结合
CUE 用于模板化 Kubernetes 资源:在 KubeVela 中,抽象层由 CUE 支持,这是一种新颖的配置编程语言,可以描述复杂的渲染逻辑,它在使用层面与 JSON 一致,是 JSON 的超集。抽象层简化了 Kubernetes 中资源的配置,隐藏了实现的细节,并仅向业务开发人员暴露有限参数。使用 KubeVela 应用程序,开发人员可以轻松地专注于应用程序的中心逻辑,例如应该使用哪个容器镜像以及如何访问服务。为了实现这一目标,使用 Kubernetes 原生资源的最佳实践被总结到 KubeVela X-Definitions 中,并使用 CUE 提供资源的渲染模板。PS: 开发一个paas平台,一个核心工作就是将项目、应用(包括使用xxcpu、xx内存)保存到db中,在发布时将这些信息 转换为Deployment 发给k8s apiserver,这个转换过程可以 代码手动一个字段一个字段转换为apps.Deployment,也可以是 apps.Deployment = 参数 + apps.Deployment模版 渲染得到。
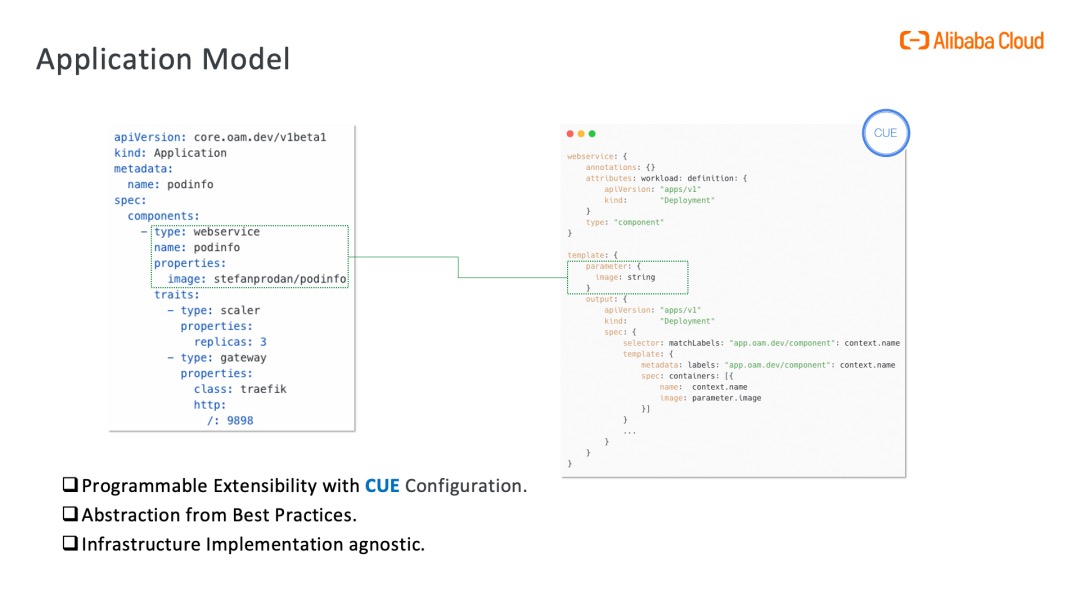
// deployment.cue
parameter:{
name: "mytest"
image: "nginx:v1"
}
template: {
apiVersion: "apps/v1"
kind: "Deployment"
spec: {
selector: matchLabels: {
"app.oam.dev/component": parameter.name
}
template: {
metadata: labels: {
"app.oam.dev/component": parameter.name
}
spec: {
containers: [{
name: parameter.name
image: parameter.image
}]
}}}
}
cue export deployment.cue -e template --out yaml 导出指定template变量的结果。
导入包
可以在 CUE 模版中通过 kube/<apiVersion> 导入 kubernetes 的包,就像使用 CUE 内部包一样。
import (
apps "kube/apps/v1"
)
parameter: {
name: string
}
output: apps.#Deployment ## output 的类型是 deployment
output: {
metadata: name: parameter.name ## 给output 的metadata.name 字段赋值
}
kubevela 中使用
kubevela
/pkg
/appfile
/parser.go
/cue
/definition
/model
/process
/task
utils.go
/workflow # 工作流相关
/operation
/providers
/step
/template
/workflow.go
/stdlib
/op.cue
kubevela 可扩展的的核心是复用,主要复用两方面的能力
- component/trait 主要复用 crd 的能力,由ComponentDefinition/TraitDefinition 使用cue 来定义crd 模版,Application controller 负责渲染出 真实crd
- workflow 复用http/email/k8s(apply等) 等能力,由 WorkflowStepDefinition 使用cue 来定义对底层provider 能力/函数的调用(provider 函数被封装为taskRunner),executor 从 WorkflowStepDefinition 拿到 provider+op(底层能力标识) “渲染”为taskRunner 并调用执行。
你可以通过 在StepDefinition 中引用cue 官方以及KubeVela内置的包,来使用HTTP 请求、crud 资源、配置日志来源、条件等待、使当前步骤失败等函数,从而通过配置的方式来覆盖你的业务场景,极大提升 Step的可扩展性。
描述 Component/Trait/Policy等Definition
webservice ComponetDefinition 内容
import (
"strconv"
)
webservice: {...}
template: {
mountsArray: {...} # 根据 parameter.volumeMounts 计算mount 相关的内容,最终会被output 使用
volumesList: {...}
...
output: { # deployment yaml的核心部分
apiVersion: "apps/v1"
kind: "Deployment"
spec: {...}
}
exposePorts: {}
outputs: {
if len(exposePorts) != 0 {
webserviceExpose: {
apiVersion: "v1"
kind: "Service"
metadata: name: context.name
spec: {
selector: "app.oam.dev/component": context.name
ports: exposePorts
type: parameter.exposeType
}
}
}
}
parameter: {...} # template的参数部分
}
// kubevela/pkg/appfile/parser.go
func generateComponentFromCUEModule(c client.Client, wl *Workload, appName, revision, ns string) (*v1alpha2.Component, ..., error) {
pCtx, err := PrepareProcessContext(c, wl, appName, revision, ns)
for _, tr := range wl.Traits {
tr.EvalContext(pCtx)
}
comp, acComp, err = evalWorkloadWithContext(pCtx, wl, appName, wl.Name)
for _, sc := range wl.Scopes {
acComp.Scopes = append(acComp.Scopes, v1alpha2.ComponentScope{...})
}
return comp, acComp, nil
}
从Application 中拿到 component/trait name,找到对应的Definition 拿到cue 模版,加上Application 提供的参数,转成Component ,并将trait 挂在 ApplicationConfigurationComponent 对象里。
PrepareProcessContext
Workload.EvalContext
workloadDef.Complete(ctx process.Context, abstractTemplate string, params interface{})
bi := build.NewContext().NewInstance("", nil)
bi.AddFile("-", abstractTemplate)
var paramFile = "parameter: {}"
bt, err := json.Marshal(params)
paramFile = fmt.Sprintf("%s: %s", mycue.ParameterTag, string(bt))
bi.AddFile("parameter", paramFile)
bi.AddFile("-", ctx.ExtendedContextFile())
var r cue.Runtime
inst, err := r.Build(bi)
output := inst.Lookup("output") # 返回cue文件中 output 字段的值
base, err := model.NewBase(output)
ctx.SetBase(base)
Trait.EvalContext
traitDef.Complete(ctx, trait.Template, trait.Params)
bi := build.NewContext().NewInstance("", nil)
bi.AddFile("-", abstractTemplate)
var paramFile = "parameter: {}"
bt, err := json.Marshal(params)
paramFile = fmt.Sprintf("%s: %s", mycue.ParameterTag, string(bt))
bi.AddFile("parameter", paramFile)
bi.AddFile("context", ctx.ExtendedContextFile())
instances := cue.Build([]*build.Instance{bi})
for _, inst := range instances {
patcher := inst.Lookup("patch") # 返回cue文件中 patch 字段的值
base, _ := ctx.Output()
p, err := model.NewOther(patcher)
base.Unify(p)
}
evalWorkloadWithContext
base, assists := pCtx.Output()
componentWorkload, err := base.Unstructured()
component := &v1alpha2.Component{}
// we need to marshal the workload to byte array before sending them to the k8s
component.Spec.Workload = util.Object2RawExtension(componentWorkload)
acComponent := &v1alpha2.ApplicationConfigurationComponent{}
for _, assist := range assists {
tr, err := assist.Ins.Unstructured()
acComponent.Traits = append(acComponent.Traits, v1alpha2.ComponentTrait{
Trait: util.Object2RawExtension(tr),
})
}
k8s patch语法参考 Update API Objects in Place Using kubectl patch
描述WorkflowStepDefinition
自定义工作流比如以下场景:使用 Helm 部署一个 Tomcat,并在部署完成后自动向 Slack 发送消息通知。
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: first-vela-workflow
namespace: default
spec:
components:
- name: tomcat
type: helm
workflow:
steps:
- name: tomcat
type: my-helm # 指定步骤类型
outputs:
- name: msg
# 将 my-helm 中读取到的 deployment status 作为信息导出
valueFrom: resource.value.status.conditions[0].message
- name: send-message
type: webhook-notification
我们可以使用 vela def 通过编写 Cue template 来定义工作流步骤。 KubeVela 提供了一些 CUE 操作类型用于编写工作流步骤。这些操作均由 vela/op 包提供。比如以下 3 个 CUE 操作:
| 操作名 | 说明 | 参数 |
|---|---|---|
| ApplyApplication | 部署应用中的所有资源 | - |
| Read | 读取 Kubernetes 集群中的资源。 | value: 描述需要被读取资源的元数据,比如 kind、name 等,操作完成后,集群中资源的数据会被填充到 value 上。 |
err: 如果读取操作发生错误,这里会以字符串的方式指示错误信息。 |
||
| ConditionalWait | 会让 Workflow Step 处于等待状态,直到条件被满足。 | continue: 当该字段为 true 时,Workflow Step 才会恢复继续执行。 |
部署 Tomcat 步骤 my-helm WorkflowStepDefinition 实现步骤
- 通过 vela def init 来生成一个 WorkflowStepDefinition 模板:
$ vela def init my-helm -t workflow-step --desc "Apply helm charts and wait till it's running." -o my-helm.cue # 得到以下结果 $ cat my-helm.cue "my-helm": { annotations: {} attributes: {} description: "Apply helm charts and wait till it's running." labels: {} type: "workflow-step" } template: { } - 引用 vela/op 包,并将 Cue 代码补充到 template 中:
import ( "vela/op" ) "my-helm": { annotations: {} attributes: {} description: "Apply helm charts and wait till it's running." labels: {} type: "workflow-step" } template: { // 部署应用中的所有资源 apply: op.#ApplyApplication & {} resource: op.#Read & { value: { kind: "Deployment" apiVersion: "apps/v1" metadata: { name: "tomcat" // 可以使用 context 来获取该 Application 的任意元信息 namespace: context.namespace } } } workload: resource.value // 等待 helm 的 deployment 可用 wait: op.#ConditionalWait & { continue: workload.status.readyReplicas == workload.status.replicas && workload.status.observedGeneration == workload.metadata.generation } } - 部署到集群中:
$ vela def apply my-helm.cue WorkflowStepDefinition my-helm in namespace vela-system updated.
WorkflowStepDefinition 深入理解
实现 Operator 效果
开源工作流引擎如何支撑企业级 Serverless 架构?比如 工作流中新增一个镜像预热的节点,以往多集群中下发 ImagePullJob 工作负载为例,你不仅需要管理多集群的配置,还需要 Watch 工作负载(CRD)的状态,直到工作负载的状态变成 Ready,才继续下一步。而这个流程其实对应了一个简单的 Kubernetes Operator 的 Reconcile 逻辑:先是创建或者更新一个资源,如果这个资源的状态符合了预期,则结束此次 Reconcile,如果不符合,则继续等待。难道我们运维操作中每新增一种资源的管理,就需要实现一个 Operator 吗?
template: {
// 第一步:从指定集群中读取资源
read: op.#Read & {
value: {
apiVersion: parameter.apiVersion
kind: parameter.kind
metadata: {
name: parameter.name
namespace: parameter.namespace
}
}
cluster: parameter.cluster
}
// 第二步:直到资源状态 Ready,才结束等待,否则步骤会一直等待
wait: op.#ConditionalWait & {
continue: read.value.status != _|_ && read.value.status.phase == "Ready"
}
// 第三步(可选):如果资源 Ready 了,那么...
// 其他逻辑...
// 定义好的参数,用户在使用该步骤类型时需要传入
parameter: {
apiVersion: string
kind: string
name: string
namespace: *context.namespace | string
cluster: *"" | string
}
}
对应到当前这个场景就是:
- 读取指定集群(如:上海集群)中的 ImagePullJob 状态。
- 如果 ImagePullJob Ready,镜像已经预热完毕,则当前步骤成功,执行下一个步骤。
- 当 ImagePullJob Ready 后,清理集群中的 ImagePullJob。
通过这样自定义的方式,不过后续在运维场景下新增了多少 Region 的集群或是新类型的资源,都可以先将集群的 KubeConfig 纳管到 KubeVela Workflow 的管控中后,再使用已经定义好的步骤类型,通过传入不同的集群名或者资源类型,来达到一个简便版的 Kubernetes Operator Reconcile 的过程,从而极大地降低开发成本。
官方 deploy step 示例
import (
"vela/op"
)
deploy: {
alias: ""
annotations: {}
attributes: {}
description: "A powerful and unified deploy step for components multi-cluster delivery with policies."
labels: {}
type: "workflow-step"
}
template: {
deploy: op.#Deploy & {
policies: parameter.policies
parallelism: parameter.parallelism
ignoreTerraformComponent: parameter.ignoreTerraformComponent
}
parameter: {
//+usage=If set to false, the workflow will suspend automatically before this step, default to be true.
auto: *true | bool
//+usage=Declare the policies that used for this deployment. If not specified, the components will be deployed to the hub cluster.
policies?: [...string]
//+usage=Maximum number of concurrent delivered components.
parallelism: *5 | int
//+usage=If set false, this step will apply the components with the terraform workload.
ignoreTerraformComponent: *true | bool
}
}
kubevela/pkg/providers 设计了一套机制,当workflow executor 执行deploy step时,executor.doSteps 首先从 template.deploy 的 #provider 和 #do 中拿到 provider和 do,接着执行exec.Handle(…,provider,do) ==> handler := providers.GetHandler(provider,do);handler()。
// kubevela/pkg/stdlib/op.cue
#Deploy: multicluster.#Deploy
// kubevela/pkg/stdlib/pkgs/multicluster.cue
#Deploy: {
#provider: "multicluster"
#do: "deploy"
policies: [...string]
parallelism: int
ignoreTerraformComponent: bool
}
// kubevela/pkg/workflow/providers/multicluster/multicluster.go
// Install register handlers to provider discover.
func Install(p wfTypes.Providers, c client.Client, app *v1beta1.Application, af *appfile.Appfile,...) {
prd := &provider{Client: c, app: app, af: af, apply: apply, healthCheck: healthCheck, renderer: renderer}
p.Register(ProviderName, map[string]wfTypes.Handler{
"read-placement-decisions": prd.ReadPlacementDecisions,
"make-placement-decisions": prd.MakePlacementDecisions,
"patch-application": prd.PatchApplication,
"list-clusters": prd.ListClusters,
"get-placements-from-topology-policies": prd.GetPlacementsFromTopologyPolicies,
"deploy": prd.Deploy,
})
}
从效果看,根据 op.Deploy ==> multicluster.#Deploy 可以找到 kubevela/pkg/workflow/providers/multicluster/multicluster.go 的Deploy 方法。换句话说,workflow/provider 实现了一些通用的能力函数,加上stdlib 等机制,我们在workflowStep cue 模版中可以直接使用这些函数。
suspend step 示例
suspend: {
alias: ""
annotations: {}
attributes: {}
description: "Suspend the current workflow, it can be resumed by 'vela workflow resume' command."
labels: {}
type: "workflow-step"
}
template: parameter: {
// +usage=Specify the wait duration time to resume workflow such as "30s", "1min" or "2m15s"
duration?: string
}
留下评论