RAG向量检索与微调
简介
Foundation Model有两个代表,一个是Large Language Model,另一个是Embedding Model。前者聚焦文本空间,其形式化功能为text -> text;后者聚焦向量空间,其功能为text -> embedding。转为向量能做些什么呢?比较常见的使用场景包括retrieval(如检索知识库、检索Tool)、clustering(聚类)、classification(分类,通常需再接一层分类layer)等。
没有思考过 Embedding,不足以谈 AI计算的基础是数,而自然语言是文字,因此很容易想到要做的第一步是让文字数字化,为行文方便,我们将这个过程叫做编码。要设计编码的方法,自然需要思考的问题是:哪些性质是编码规则必须要满足的?
- 每一个词具有唯一量化值,不同词需要具有不同的量化值
- 词义相近词需要有”相近”的量化值;词义不相近的词量化值需要尽量“远离”。当性质二得到满足时,同义的句子在序列特征上会更加接近,这将有利于计算机而言更高效地理解共性、区分特性;反之则会给计算机制造非常多的困难。难以捕捉同质内容之间的共性,就意味着模型需要更多的参数才能描述同等的信息量,学习的过程显然困难也会更大。OpenAI 的 Jack Rae 在 Standford 的分享 中提到了一个很深刻的理解语言模型的视角:语言模型就是一个压缩器。所有的压缩,大抵都能被概括在以下框架内:提取共性,保留个性,过滤噪声。带着这个视角去看,就更加容易认识到性质二的必要性。不同词所编码的数值,是否基于词义本身的相似性形成高区分度的聚类,会直接影响到语言模型对于输入数据的压缩效率。因为词是离散分布的,而计算模型的输出 —— 除非只使用非常简单的运算并且约束参数的权重 —— 很难恰好落在定义好的量化值中。对于神经网络模型,每一个节点、每一层都必须是连续的,否则便无法计算梯度从而无法应用反向传播算法。这两个事实放在一起可能会出现的情况是:词的量化值可以全部是整数,但是语言模型的输出不一定。例如当模型输出 1.5,词表只定义了 1 和 2,这时该如何处理呢?我们会希望 1 和 2 都可以,甚至 3 可能也不会太离谱,因此 1 和 2 所代表的词在词义上最好有某种共性。当相近的词聚集到一起,推断出有效输出的概率就会更高。
- 词义的多维性。对于每一个词,我们可以表达为一组数,而非一个数;这样一来,就可以在不同的维度上定义远近,词与词之间复杂的关系便能在这一高维的空间中得到表达。
图像可以有embedding,句子和段落也可以有 embedding —— 本质都是通过一组数来表达意义。段落的 embedding 可以作为基于语义搜索的高效索引,AI 绘画技术的背后,有着这两种 embedding 的互动 —— 未来如果有一个大一统的多模态模型,embedding 必然是其中的基石和桥梁 。
On The Role of Pretrained Language Models in General-Purpose Text Embeddings: A Survey 论文综述。
embedding 渊源
词嵌入的新时代为了让机器可以学习到文本的特征属性,我们需要一些将文本数值化的表示的方式。
- Word2vec算法通过使用一组固定维度的向量来表示单词,计算其方式可以捕获到单词的语义及单词与单词之间的关系。使用Word2vec的向量化表示方式可以用于判断单词是否相似,对立,或者说判断“男人‘与’女人”的关系就如同“国王”与“王后”。(这些话是不是听腻了〜 emmm水文必备)。另外还能捕获到一些语法的关系,这个在英语中很实用。例如“had”与“has”的关系如同“was”与“is”的关系。
- 上面介绍的词嵌入方式有一个很明显的问题,因为使用预训练好的词向量模型,那么无论上下文的语境关系如何,每个单词都只有一个唯一的且已经固定保存的向量化形式。这和中文的同音字其实也类似,用这个举一个例子吧, ‘长’ 这个字,在 ‘长度’ 这个词中表示度量,在 ‘长高’ 这个词中表示增加。那么为什么我们不通过”长’周围是度或者是高来判断它的读音或者它的语义呢?这个问题就派生出语境化的词嵌入模型。EMLo改变Word2vec类的将单词固定为指定长度的向量的处理方式,它是在为每个单词分配词向量之前先查看整个句子,然后使用bi-LSTM来训练它对应的词向量。
- Transformer论文和代码的发布,以及其在机器翻译等任务上取得的优异成果,让一些研究人员认为它是LSTM的替代品,事实上却是Transformer比LSTM更好的处理long-term dependancies(长程依赖)问题。从LSTM到Transformer的过渡中,我们发现少了些东西。ELMo的语言模型是双向的,但是OpenAI的transformer是前向训练的语言模型。我们能否让我们的Transformer模型也具有Bi-Lstm的特性呢?Bert = transformer encoder + 双向 + Masked learning。 bert base 有12层encoder,最后一层的第一个输出向量(对应
[cls])可以作为整个输入的向量表示。PS:其实其它层输出向量、最后一层的非第一个输出向量 单个、或几个contact一下也都可以作为输入的表示,也有平均模型产生的所有 token embeddings 的值来作为输出向量的。)
word embedding ==> Sentence Embeddings ==> Document Embeddings/Image Embeddings.
bert embedding
大模型 RAG 基础:信息检索、文本向量化及 BGE-M3 embedding 实践信息检索的技术发展大致可分为三个阶段:
- 基于统计信息的关键字匹配(statistical keyword matching)
- 是一种 sparse embedding —— embedding 向量的大部分字段都是 0;
- 基于深度学习模型的上下文和语义理解,
- 属于 dense embedding —— embedding 向量的大部分字段都非零;基于 dense vector,用最近邻算法就能对给定的 query 进行检索,强大且语义准确。
- 所谓的“学习型”表示,组合上面两种的优点,称为 learned sparse embedding。
- 既有深度学习模型的上下文和语义理解能力;又具备稀疏表示的可解释性(interpretability of sparse representations)和低计算复杂度。
- 先通过 BERT 等深度学习模型生成 dense embedding;再引入额外的步骤对以上 dense embedding 进行稀疏化,得到一个 sparse embedding;代表算法:BGE-M3。
以输入 “Milvus is a vector database built for scalable similarity search” 为例,BERT dense embedding 工作过程:
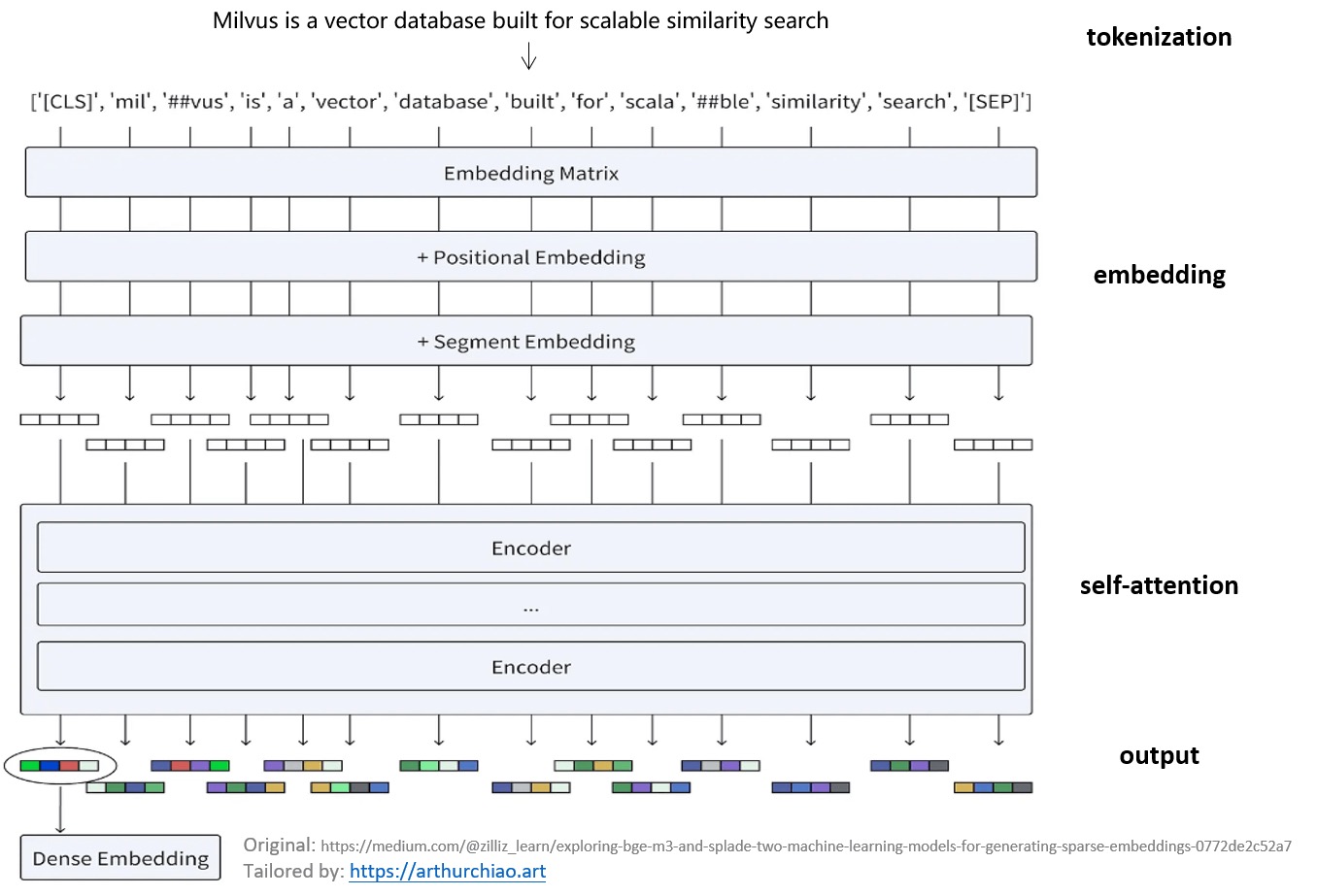
- Tokenization
- 将输入文本转成 token 序列
- BERT 还会插入两个特殊的 token:[CLS] token 表示开始,[SEP] token 表示一个句子的结束。
- Embedding:使用 embedding matrix 将每个 token 转换为一个向量,详见 BERT 论文;
- tokenizer的下一步就是将token的one-hot编码转换成更dense的embedding编码。在ELMo(Embeddings from Language Model)之前的模型中,embedding模型很多是单独训练的,而ELMo之后则爆发了直接将embedding层和上面的语言模型层共同训练的浪潮。每个单词会定位这个表中的某一行,而这一行就是这个单词学习到的在嵌入空间的语义。
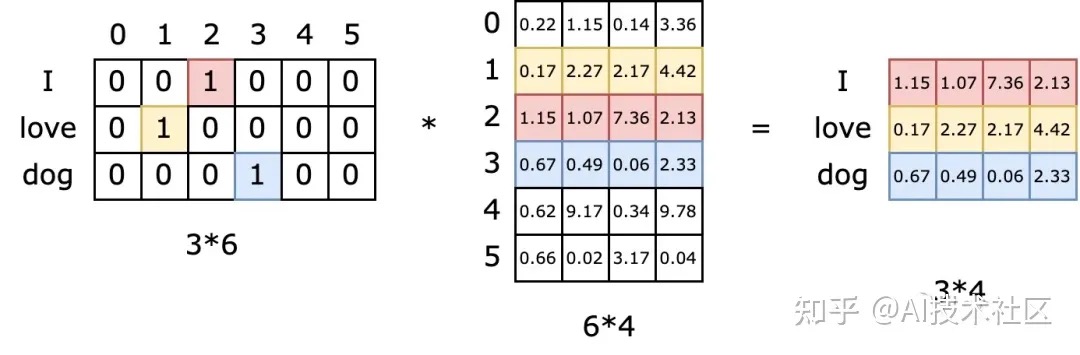
- Encoding:这些向量通过多层 encoder,每层由 self-attention 和 feed-forward 神经网络组成
- 会根据所有其他 token 提供的上下文细化每个 token 的表示。
- Output:输出一系列最终的 embedding vectors。 最终生成的 dense embedding 能够捕捉单个单词的含义及其在句子中的相互关系。
BGE 是一系列 embedding 模型,扩展了 BERT 的能力。BGE-M3 是目前最新的一个,3 个 M 是强调的多个 multi- 能力:Multi-Functionality/Multi-Linguisticity/Multi-Granularity。BGE-M3 生成 learned sparse embedding 的过程

- 先走 BERT dense embedding 的流程,
- 最后加一个 linear 层,得到 learned sparse embedding。
in M3-Embedding, the [CLS] embedding is used for dense retrieval, while embeddings from other tokens are used for sparse retrieval and multi-vector retrieval. PS:既生成了spare embedding,又生成了 dense embedding。我说呢,只用一个[CLS] 对应的emebedding 其它的不用太浪费了。
向量匹配的几个问题
BERT 严重依赖预训练数据集的领域知识(domain-specific knowledge), 预训练过程使 BERT 偏向于预训练数据的特征, 因此在领域外(Out-Of-Domain),例如没有见过的文本片段,表现就不行了。另一方面,尽管传统 sparse embedding 在词汇不匹配问题时虽然也存在挑战, 但在领域外信息检索中,它们的表现却优于 BERT。 这是因为在这类算法中,未识别的术语不是靠“学习”,而是单纯靠“匹配”。
- 问题在语义上与其答案并不相同。因此直接将问题与原始知识库进行比较不会有成果。假设一位律师需要搜索数千份文件以寻找投资者欺诈的证据。问题“什么证据表明鲍勃犯了金融欺诈行为? ”与“鲍勃于 3 月 14 日购买了 XYZ 股票”在语义上基本上没有任何重叠(其中隐含 XYZ 是竞争对手,3 月 14 日是收益公告发布前一周)。PS:构建数据以进行同类比较。与问题→支持文档相比,问题→问题比较将显著提高性能。从实用角度来说,您可以要求 ChatGPT 为每个支持文档生成示例问题,并让人类专家对其进行整理。本质上,您将预先填充自己的 Stack Overflow。此外,用户反馈的问答对也可以用于问题重写或检索。
- 向量嵌入和余弦相似度是模糊的。向量在完全捕捉任何给定语句的语义内容方面存在固有缺陷。另一个微妙的缺陷是,余弦相似度不一定能产生精确的排名,因为它隐含地假设每个维度都是平等的。在实践中,使用余弦相似度的语义搜索往往在方向上是正确的,但本质上是模糊的。它可以很好地预测前 20 个结果,但通常要求它单独可靠地将最佳答案排在第一位是过分的要求。
-
在互联网上训练的嵌入模型不了解你的业务和领域。在专业的垂直领域,待检索的文档往往都是非常专业的表述,而用户的问题往往是非常不专业的白话表达。所以直接拿用户的query去检索,召回的效果就会比较差。Keyword LLM就是解决这其中GAP的。例如在ChatDoctor中会先让大模型基于用户的query生成一系列的关键词,然后再用关键词去知识库中做检索。ChatDoctor是直接用In-Context Learning的方式进行关键词的生成。我们也可以对大模型在这个任务上进行微调,训练一个专门根据用户问题生成关键词的大模型。这就是ChatLaw中的方案。
微调emebedding
在专业数据领域上,嵌入模型的表现不如 BM25,但是微调可以大大提升效果。embedding 模型 可能从未见过你文档的内容,也许你的文档的相似词也没有经过训练。在一些专业领域,通用的向量模型可能无法很好的理解一些专有词汇,所以不能保证召回的内容就非常准确,不准确则导致LLM回答容易产生幻觉(简而言之就是胡说八道)。可以通过 Prompt 暗示 LLM 可能没有相关信息,则会大大减少 LLM 幻觉的问题,实现更好的拒答。
- 大模型应用中大部分人真正需要去关心的核心——Embedding
- 分享Embedding 模型微调的实现 ,此外,原则上:embedding 所得向量长度越长越好,过长的向量也会造成 embedding 模型在训练中越难收敛。 手工微调embedding模型,让RAG应用检索能力更强 未细读
- embedding训练过程本质上偏向于训练数据的特点,这使得它在为数据集中(训练时)未见过的文本片段生成有意义的 embeddings 时表现不佳,特别是在含有丰富特定领域术语的数据集中,这一限制尤为突出。微调有时行不通或者成本较高。微调需要访问一个中到大型的标注数据集,包括与目标领域相关的查询、正面和负面文档。此外,创建这样的数据集需要领域专家的专业知识,以确保数据质量,这一过程十分耗时且成本高昂。而bm25等往往是精确匹配的,信息检索时面临词汇不匹配问题(查询与相关文档之间通常缺乏术语重叠)。幸运的是,出现了新的解决方法:学习得到的稀疏 embedding。通过优先处理关键文本元素,同时舍弃不必要的细节,学习得到的稀疏 embedding 完美平衡了捕获相关信息与避免过拟合两个方面,从而增强了它们在各种检索任务中的应用价值。支持稀疏向量后,一个chunk 在vdb中最少包含: id、text、稠密向量、稀疏向量等4个字段。
通常,Embedding模型是通过对比学习来训练的,而负样本的质量对模型性能至关重要。Language Embedding模型训练通常采用多阶段方案,分为弱监督的预训练以及有监督的精调训练。
- 微调样本构建
- 微调脚本
- 训练过程监控:W&B监控
- 模型效果评估
PS:文搜图时,CLIP模型的核心思想是通过对比学习(contrastive learning)来训练模型,使得相似的图像和文本在向量空间中的距离更近,而不相似的图像和文本距离更远。
微调样本构建
微调样本的构建过程,其实就是找出跟一个query相似的句子——正样本,以及不相似的句子——负样本,Embedding在微调时,会使用对比学习loss来让模型提高辨别正负样本的能力。,query自然是用户问题(下面“-”前面的Q),根据正负样本的来源(下面“-”后面的部分),通常可以分为如下几种:
- Q-Q(question-question):这种方式适合已经积累了比较多FAQ的企业,希望对用户问题检索FAQ库中的Q,这种情况下,使用Q-Q方式构建的样本,优化的模型检索效果会比较好
- Q-A(question-answer):这种方式比较有误导性,看起来感觉最应该用这种方式构建,但实际上线后,要检索的,是一堆documents,而不是answer,如果你真的用这个方式构建过样本,看一些case就会发现,answer跟实际的文档相差非常远,导致模型微调后,性能反而出现下降
- Q-D(question-document):这种方式,在几个项目中实践下来,基本上是最适合的构建方式,因为实际检索时,就是拿问题去检索文档,确保训练、推理时任务的一致性,也是减少模型性能损失最主要的一个方法。
将数据格式化为文本对(例如查询与相关文档)或三元组(anchor, positive, negative),便于使用对比损失进行训练。
- 样本数据格式示例,微调目的是让正样本和负样本的分数差变大。
{"query": str, "pos": List[str], "neg":List[str]}
训练过程
探索更强中文Embedding模型:Conan-Embedding 不是特别直白。
预训练
- 通过文档提取和语言识别进行格式化处理;
- 在基于规则的阶段,文本会经过规范化和启发式过滤;
- 在安全过滤阶段,执行域名阻止、毒性分类和色情内容分类;
- 在质量过滤阶段,文本会经过广告分类和流畅度分类,以确保输出文本的高质量。
- 通过MinHash方法进行去重
在预训练阶段,为了高效且充分地利用数据,我们使用InfoNCE Loss with In-Batch Negative:
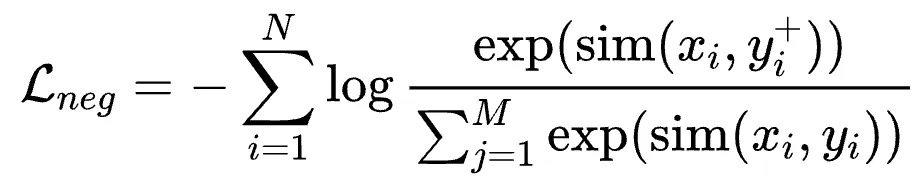
其中是title,input,question,prompt等,$y_i^{+}$是对应的 content,output,answer,response等,认为是正样本;$y_i$是同 batch 其他样本的content,output,answer,response,认为是负样本。In-Batch Negative InfoNCE Loss 是一种用于对比学习的损失函数,它利用了 mini-batch 中的其他样本作为负样本来优化模型。具体来说,在每个 mini-batch 中,除了目标样本的正样本对外,其余样本都被视为负样本。通过最大化正样本对的相似度并最小化负样本对的相似度,In-Batch Negative InfoNCE Loss 能够有效地提高模型的判别能力和表征学习效果。这种方法通过充分利用 mini-batch 中的样本,提升了训练效率并减少了对额外负样本生成的需求。
有监督精调,我们针对不同的下游任务进行特定任务的微调。
- 检索(Retrieval)。检索任务包括查询、正样本和负样本,经典的损失函数是InfoNCE Loss。
- 语义文本相似性(STS)。STS任务涉及区分两段文本之间的相似性,经典的损失函数是交叉熵损失。
微调脚本
- llamaindex 有相关实践
- torchrun FlagEmbedding
- sentence-transformers
FlagEmbedding 微调
此处原始参考文档来自BGE官方仓库: https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune
准备微调样本
- 切分文档 得到chunk
- 使用llm依据chunk来生成对应query正样本,prompt 借鉴了 llama_index的generate_qa_embedding_pairs
DEFAULT_QA_GENERATE_PROMPT_TMPL = """\ Given the context below, your task is to create a set of {num_questions_per_chunk} diverse questions that a human might ask, each within 20 words. \ Restrict the questions to the provided context.\ --------------------- {context_str} --------------------- Try to cover various aspects and perspectives in your questions. \ Be concise and make sure the questions are relevant to the context. \ Generate questions based on the provided information directly, nothing else. \ """ - 如何从一个questions set里挑出最合适的一个,这里考虑做二次生成,把之前生成的作为examples放在prompt里面。思路类似于COT,先生成几个,再基于这几个再生成一个。
""" # Context: {context} # Generate a relevant and coherent question based on the information provided. # Example: {questions} # Generate a question directly. # Question: """ - 生成数据清洗
- 生成负例,主要逻辑就是针对每一个正样例,将所有的chunk按照embedding相似度排序,10-100的chunk中随机7条作为负样例(如果每次embedding匹配取top10的话)。PS: 比如一共有100个chunk,每个chunk 生成了xx个query,选用一个query,再根据query和100个chunk的embedding相似度排序,取10名开外的7条作为负例。
微调emebedding
构造好微调样本后,就可以开始微调模型了。代码仓库中包含了4个版本的微调脚本,总体大同小异,此处以finetune_bge_embedding_v4.sh为例
#!/bin/bash
SCRIP_DIR=$(echo `cd $(dirname $0); pwd`)
export PATH=/work/cache/env/miniconda3/bin:$PATH
# 此处替换为“微调样本构建”步骤产出文件的路径,代码仓库中也有此文件
export TRAIN_DATASET=outputs/v1_20240713/emb_samples_qd_v2.jsonl
# model_name_or_path替换为自己的本机路径,或者BAAI/bge-large-zh-v1.5
torchrun --nproc_per_node ${N_NODES} \
-m FlagEmbedding.baai_general_embedding.finetune.run \
--output_dir ${OUTPUT_DIR} \
--model_name_or_path /DataScience/HuggingFace/Models/BAAI/bge-large-zh-v1.5 \
...
另外,如果你使用的是开源嵌入模型,对其进行微调是提高检索准确性的有效方法。LlamaIndex 提供了 一份详尽的指南,指导如何一步步微调开源嵌入模型,并证明了微调可以在各项评估指标上持续改进性能。(https://docs.llamaindex.ai/en/stable/examples/finetuning/embeddings/finetune_embedding.html ) 下面是一个示例代码片段,展示了如何创建微调引擎、执行微调以及获取微调后的模型:
finetune_engine = SentenceTransformersFinetuneEngine(
train_dataset,
model_id="BAAI/bge-small-en",
model_output_path="test_model",
val_dataset=val_dataset,
)
finetune_engine.finetune()
embed_model = finetune_engine.get_finetuned_model()
import torch
from torch.optim import Adam
from torch.nn import TripletMarginLoss
optimizer = Adam(model.parameters(), lr=2e-5)
criterion = TripletMarginLoss(margin=1.0)
for epoch in range(num_epochs):
for anchor, positive, negative in data_loader:
# 前向传播:计算嵌入向量
emb_anchor = model.encode(anchor, convert_to_tensor=True)
emb_positive = model.encode(positive, convert_to_tensor=True)
emb_negative = model.encode(negative, convert_to_tensor=True)
# 计算损失
loss = criterion(emb_anchor, emb_positive, emb_negative)
# 反向传播与参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch {epoch} - Loss: {loss.item()}")
模型使用
模型的使用方式,与使用RAG技术构建企业级文档问答系统之基础流程中介绍的完全一致,只是替换模型路径model_path即可
from langchain.embeddings import HuggingFaceBgeEmbeddings
import torch
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_path = 'stevenluo/bge-large-zh-v1.5-ft-v4'
embeddings = HuggingFaceBgeEmbeddings(
model_name=model_path,
model_kwargs={'device': device},
encode_kwargs={'normalize_embeddings': True},
query_instruction='为这个句子生成表示以用于检索相关文章:'
)
模型评估(未完成)
https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune
其它embedding 优化
告别传统的文档切块!JinaAI提出Late Chunking技巧对于传统的分块,类似于固定长度的分块。带来的一个比较大的问题是,上下文缺失。比如一个句子的主语在段落开头,后面的段落/句子中,有一些代词比如 It’s, The city等等来表示主语。这种情况下确实主语的句子基本上就变得比较断章取义了~与先分块后向量化不同,JinaAI最新提出的“Late Chunking”方法是一个相反的步骤,首先将整个文本或尽可能多的文本输入到嵌入模型中。在输出层会为每个token生成一个向量表示,其中包含整个文本的文本信息。然后我们可以按照需要的块大小对对向量进行聚合得到每个chunk的embedding。这样的优势是,充分利用长上下文模型的优势,同时又不会让每个块的信息过多,干扰向量表征。
其它
稀疏向量
稀疏向量 也是对chunk 算一个稀疏向量存起来,对query 算一个稀疏向量,然后对稀疏向量计算一个向量距离来评价相似度。
-
关键词检索。BM25是产生稀疏向量的一种方式。其稀疏性体现在,假设使用 jieba(中文分词库)分词,每个词用一个浮点数来表示其统计意义,那么,对于一份文档,就可以用 349047 长度的向量来表示。这个长度是词典的大小,对于某文档,该向量绝大部分位置是0,因此是稀疏向量。基于统计的BM25检索有用,但其对上下文不关心,这也阻碍了其检索准确性。假设有份文档,介绍的是 阿司匹林 的作用,但这篇文档仅标题用了 阿司匹林 这个词,但后续都用 A药 来代指 阿司匹林,这样的表述会导致 阿司匹林 这个词在该文档中的重要程度降低。
\(\text{score}(D, Q) = \sum_{n=1}^{N} \text{IDF}(q_n) \cdot \left(\frac{f(q_n, D)}{k_1 + 1} + \frac{k_1 (1 - b + b \cdot \frac{\text{length}(D)}{\text{avgDL}})}{f(q_n, D) + k_1}\right)\) 其中,f函数则是词在文档中的频率。
- 稠密检索。核心思想是通过神经网络获得一段语料的、语意化的、潜层向量表示。不同模型产生的向量有长有短,进行相似度检索时,必须由相同的模型产生相同长度的向量进行检索。
- BM25可以产生稀疏向量用于检索,另一种方式便是使用神经网络。与BM25不同的是
- 神经网络赋予单词权重时,参考了更多上下文信息。
- 另一个不同点是分词的方式。神经网络不同的模型有不同分词器,但总体上,神经网络的词比传统检索系统分的更小。比如,清华大学 在神经网络中可能被分为4个令牌,而使用jieba之类的,会分为1个词。神经网络的词典大约在几万到十几万不等,但文本检索中的词典大小通常几十万。分词方式不同,使得神经网络产生的稀疏向量,比BM25的向量更稠密,检索执行效率更高。这类的代表有:splade、colbert、cocondenser当使用这类模型编码文档时,其输出一般是:
{ "indices": [19400,724,12,243687,17799,6,1635,71073,89595,32,97079,33731,35645,55088,38], "values": [0.2203369140625,0.259765625,0.0587158203125,0.24072265625,0.287841796875,0.039581298828125,0.085693359375,0.19970703125,0.30029296875,0.0345458984375,0.29638671875,0.1082763671875,0.2442626953125,0.1480712890625,0.04840087890625] }该向量编码的内容是 RAG:”稠密 或 稀疏?混合才是版本答案!”,由 BGE-M3 模型产生。这个稀疏向量中,indices是令牌的ID,values是该令牌的权重。若文档存在重复令牌,则取最大的权重。产生稀疏向量后,无需将所有的都存入数据库中,可以只存权重较高的前几百个即可。具体数值可以根据自身的业务特性实验。
PS: 也就是稀疏向量 可以用一个词表长度的[]来表示,也有其对应的稀疏表示形式。但是计算的时候,还是用[] 去计算的。
留下评论