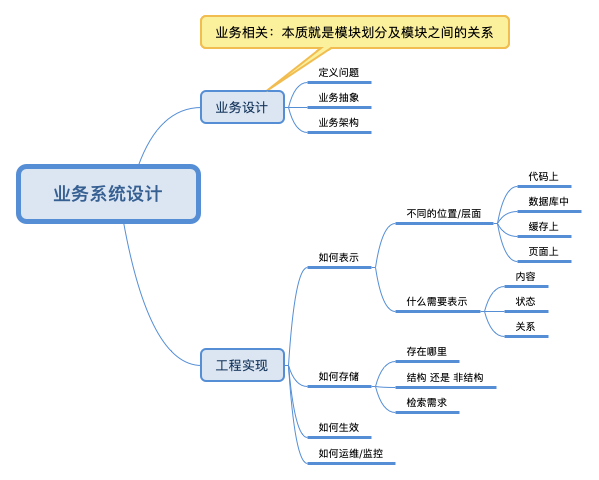
业务系统设计的一些体会
简介
笔者的历程
- 觉得代码实现是难点
- 觉得数据库设计是难点。因为数据库设计有了,代码也就定了。一个学生信息管理系统,数据库设计自然没啥。但对于一个权限管理系统、审批流系统,数据库设计就很有含量了。
- 觉得业务抽象是难点。比如一个配置中心系统、ABTest 系统有哪些基本抽象,如何入手。此时是不是用数据库存储都是一个问题,比如还可以存在zk上。
-
实现一个有闭环的平台类系统,比如风控系统等。
- 首先它的输入是各种各样,输出也是各种各样的。
- 各种技术的结合。java 业务处理、spark数据处理等
- 性能要求带来的复杂度
业务系统设计
- 定义项目解决的真正问题。很多时候,“有一个需求,我们做个系统吧”,然而系统做着做着,就会跑偏掉,要么自己想一堆伪需求,要么做出来的系统用处不大或只解决了部分问题。
- 解决有什么抽象,设定几个概念术语来描述系统、向别人解释系统
-
基本理念,比如推送系统,宁愿不推也不要打扰用户。基本理念很重要,要害就在于影响了很多决策
- 假设你的算法 有一点错误率,那错误率 让哪些用户来扛
- 有个新需求很紧急,你干不干,一个新feature 你接不接,风险点是否跟基本理念冲突
- 有很多事可以你的项目做,也可以别人的项目做,到底是你做还是别人做
-
画后台界面原型图(如果有的话),我发现这是一个很有含量的东西
- 充分反应了你对系统的认识,如果你认识不到位,这个界面根本画不出来,画出来用户也不知道所以。
- 逼着你思考:一共要做哪些事儿?用户入口是什么?哪些让用户看到(易变的部分),哪些不让(不变的、可以自动化的部分)?
- 和用户最佳的沟通工具
- 迭代优于一步到位
如何分析一个业务
先功能后性能
- 找到所有相关人,摸清需求,罗列123
- 梳理需求,摸清楚需求背后的需求,汇总需求,将需求归类,总结为一两个核心点
- 列出所有可能的方案,针对每一个方案,先深度优先遍历,即搞清楚其所有优缺点,优点是否是痛点,缺点是否可以接受。根据需求、已有资源、未来规划等对方案进行“剪枝”,最终得到一个看起来可行的方案
- 群策群力,将方案抛出来,接受各方的challenge。很多时候技术并非只有一条道能达成结果,但是如果多个研发有不同的思路,大部分情况下都会想法设法去证明基于思路的方案才是对的,同时陷入对其它方法的批判中,事实上双方的方案可能只是取舍方式不一,并无绝对对错。
这要求:
- 工作所需的组件会用,会基本的排查,最好读过源码
- 实现过 相当复杂度的组件
- 形成一种常识与判断。比如开车,你左右转向要提前观察左右后视镜、超车时要关注对向来车、前面的车什么行为什么意图。
技术攻关:从零到精通当为一个新系统编写代码的时候,代码应该从接口设计开始。先用代码定义出各层的接口(包括回调接口)(第一次看到将回调接口 提升到接口设计的范畴),没有实现,只是能够编译通过。有了这些接口,就可以拿它们与同事进行非常细节的讨论了。应该先把接口讨论得足够清楚,再进行下一步的具体实现。这也是一个比较痛苦的过程,我们需要反复抉择,而通常「选择」就意味着痛苦。
阅读技术文章来「循证」的做法。很多个人博主和团队博客会在网上发表他们自己系统的实现过程,以及系统前后版本的演进过程。如果我们恰好找到相关的类似这样的文章,那么它们就有很大的参考价值。我们从别人分享的技术方案中获得一个印证,确保自己的想法没有走向极端,或者漏掉了什么重要的东西。
业务架构
业务架构其实是为了“塑造一面镜子”,让企业看清自己。知道在做哪些事情,有哪些能力。如果企业都不知道自身的能力和发展情况,那么管理层就容易“纸上谈兵”、“朝令夕改”,或选择“无为而治”。因为不了解一线情况,就会提出不合时宜、不够长期的个人主张。说白了,我们需要一个能够承上启下的模型,能够让企业外的人或者上层的管理者,在比较抽象的角度理解经营活动;同时让具体的干活的执行者能够知道“我在做什么”、“能够产生怎么价值”,“应该往什么方向演进”。也就是把一件事抽象地讲清楚。PS:所以一般从下到上,有哪些基础设施,原子能力,一直到上层的业务能力(核心、非核心)、价值。 做事情之前,要把事情想清楚,想清楚之前,首先得能够有渠道和视角看到东西。看不到,看不明白,也就无法思考,更没法做出有效决策,那么只能随波逐流,听天由命。
到底什么才是业务架构? 文章讲的比较虚,但把“业务架构” 这个词给体现出来了。在产品方案和最终的技术方案(或者是代码)之间是有很深的鸿沟的,人月神话里面也说了,整个研发编码实现,只能是软件工程中的次要问题,业务架构,主要在解决业务需求和我们技术方案之间的鸿沟。如果产品方案非常nb,是不需要业务架构师的。
结合笔者的个人体验,以一个音乐app为例,其主干架构如下
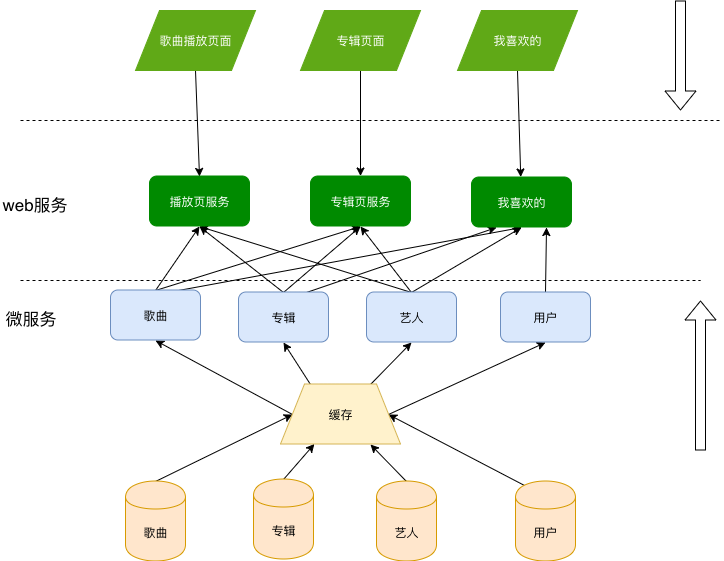
- 包括基本的服务 歌曲、专辑、艺人、用户
- 从业务上说,这是一个读多写少的业务,你需要有一个框架无缝的处理cache、db和业务的关系
- 存储是按照领域进行的,但用户的需求不是,两者在web 服务这一层发生碰撞,最复杂的就是web 服务层。
- 那么web 服务层如何简化,能减少业务程序猿的负担?
- 最常见的负担是什么?根据歌曲找专辑、根据专辑找艺人,根据专辑找声音等,也就是按照需求构建各个domain的关系,笔者曾经试想过:提供一个统一的关系服务,比如根据歌曲id,即可一次性直接找到专辑id、艺人id、相关歌曲id 等。
说到业务架构,wiki上各种高大上,按笔者在实际开发过程的中的理解,就是:
- 尽量发现小伙伴们写代码的重复的、臃肿的地方,提高效率
- 什么是团队代码中容易出bug的部分,规范它们(通常通过框架约束),减少个人易出错的概率。
- 可能是讲分布式系统最到位的一篇文章 提到中间件的作用:中间件为了在软件系统的迭代过程中,避免将精力过多地花费在某个子功能下众多差异不大的选项中。在现实中,这点更多时候出现在技术层面的中间件里,因为与业务相比,技术层面“稳定”多了,所以做标准化更有价值,更能获得长期收益。但“稳定”是相对的,哪怕单纯在业务层面也存在相对稳定的部分。
误区
过多过早的以技术实现来干扰设计
混淆领域模型和数据模型
一文教你认清领域模型和数据模型领域模型是面向领域对象的,要尽量具体,尽量语明确,显性化的表达业务语义是其首要任务,扩展性是其次。而数据模型是面向数据存储的,要尽量可扩展。PS:领域模型跟技术毫无关系,而是为了更有结构化的拆解和表达业务逻辑。
任何系统和业务的运作,不管是面向过程设计也好,面向对象设计也好,领域模型设计也好,其核心都是数据模型的设计。单个数据模型自身的设计,比如:包含哪些属性、每个属性的含义是什么、这个模型本身代表什么等;同时也有数据模型之间关系的设计,比如:商品和SKU是1:n的关系,榜单和商品、商家等等模型是1:n的关系等。我们在梳理数据模型的过程中,可以尝试画ER图或者其他图来把这些关系都表示出来,这样即使后边忘记了,会过来翻一下之前的图例,就可以快速的回忆起来。
api 设计原则
高层API以操作意图为基础设计。如何能够设计好API,跟如何能用面向对象的方法设计好应用系统有相通的地方,高层设计一定是从业务出发,而不是过早的从技术实现出发。低层API根据高层API的控制需要设计。设计实现低层API的目的,是为了被高层API使用,考虑减少冗余、提高重用性的目的,低层API的设计也要以需求为基础,要尽量抵抗受技术实现影响的诱惑。
api 包括
- http api
- rpc api
- rabbitmq,consumer 向 producer 提供一个api,这个api 在producer 可以提供的数据 中选择consumer 需要的数据,producer 无需了解 consumer的细节
大到架构设计,小到接口设计,若是换个编程语言、存储,设计、代码感觉、接口就变了,一定说明设计有问题。api 设计用来隔离关注点(业务功能、系统功能),业务功能彼此划分就不提了。对于系统功能,比如监控,有的设计为了加监控把代码改的鸡飞狗跳 ==> 代码漏出几个callback记日志 ==> Prometheus 对系统的监控侵入性就很低。
函数最小参数原则,比如一个函数要根据用户名查询用户其它信息,此时函数的参数一定要是userName,不能图省事(IDE自动生成的方法通常会这样)直接使用包含userName的Person/User等上层对象。
-
API 的设计本身最关键的难题并不是让客户端与服务端软件之间如何交互,而是设计者、维护者、API使用者这几个程序员群体之间在 API 生命周期内的互动。一个 API 如何被使用,以及API本身如何被维护,依赖于设计者提供了一个清晰易于理解的模型。
-
如果一个 API 自身可以有多个完全不同的实现,一般来说这个API已经有了足够好的抽象,那么一般也不会出现和外部系统耦合过紧的问题。这个比松耦合原则更有可核实性。举个例子,比如我们已经有一个简单的 API
QueryOrderResponse queryOrder(string orderQuery),但是有场景需求希望总是读取到最新更新数据,不接受缓存,于是QueryOrderResponse queryOrder(string orderQuery, boolean useCache)这样的改法看上去合理,但实际上泄漏了后端实现的细节(后端采用了缓存)
File API 为什么是经典的好 API 设计。抽象的过程是去除细节的过程。在我们做设计时,如果现实世界的流程或者操作对象是具体化的,抽象的 Object 的选择可能不那么困难,但是对于哪些细节应该包括,是需要很多思考的。例如对于文件的API,可以看出,文件 File 这个 Resource(资源)的抽象,是“可以由一个字符串唯一标识的数据记录”。这个定义去除了文件是如何标识的(这个问题留给了各个文件系统的具体实现),也去除了关于如何存储的组织结构(again,留给了存储系统)细节。
一般来说,域模型中的概念抽象,如果能和现实中的人们的体验接近,会有利于人们理解该模型。
定义对象时需要选择合适的 Level of abstraction。当设计一个 API 用于与数据访问的客户端交互时,“文件 File “是更合适的抽象,而设计一个 API 用于文件系统内部或者设备驱动时,数据块或者数据块设备可能是合适的抽象
有什么、会怎么就怎么做 ==> 理论上应该怎么做,就怎么做
透过表象看本质,抓住本质找规律,运用规律改变世界。
我们先要想,这个系统应该是什么样子,而不是怎么样做写代码最简单。
很多时候,发现问题、描述问题,比解决问题更重要。一个很重要的要求是你要对烂的代码、设计容忍度比较低,不能一边抱怨一边让代码更复杂。
对一些原则的误解
- KISS(Keep It Simple, Stupid) 。怎样才算是“Simple and Stupid”︖这是这个原则中最让⼈迷惑的地⽅。只有通过对⽤户的业务⽣命周期、访问⽣命周期进⾏分析,根据流量的压⼒不同,进⾏合理的树状拆分,也因此形成不同的系统,那么这些所形成的系统⼀定是内聚的,边界⼀定是清晰的,也⼀定是“Simple and Stupid”。也就是说,只有从业务上去分析、去拆分,才能够得到⼀个“Simple and Stupid”的结构,这是⼀个副产品,⽽不是⽬标。
- Single responsibility principle,这句话很对,但没没什么用。This principle was described in the work of Tom DeMarco and Meilir Page-Jones . They called it cohesion(内聚)。什么是内聚?A class should have only one reason to change。为什么要单一?”Because each responsibility is an axis of change”,意思是“因为每个职责是⼀个变化的维度”。“单一职责” 远不如 “A class should have only one reason to change” 更能指导人的实践。
- 原本现实⽣活中打保龄球,可以⾃⼰算分,也可以让别⼈帮忙算。为什么可以拆分开来,这是因为打保龄球的核⼼⽣命周期是打球,算分只是⼀个游戏规则,没有这个规则,保龄球也可以打的,因此这个分数计算规则可以拆分出来。并且保龄球游戏产⽣的结果是计算分数的输入,这两个步骤是打保龄球游戏的两个连续的⽣命周期活动,因此非核⼼⽣命周期可以拆分出去,形成树状结构。Game 的原本功能没变,只不过其中⼀个步骤的实现分离出去,通过⽅法调⽤的⽅式回归了⽽已。这样 Game 的职责更专注,分数计算也更专注,修改时可以互不影响,确实叫“内聚”比较好。
- 保持权责对等是成本最低的
- 随着现代开发理念的发展,越来越多的⼈看到了抽象、继承的坏处,越来越多的⼈采⽤组合的⽅式来协作,其实抽象类可以看成是组合的⼀种特殊情况。⽽且随着代码的变化越来越频繁,拥抱变化反⽽成为了⼀个风⽓。只要代码中的类做到了“内聚”,只要业务代码能够做到内聚、访问通道做到不重⽤(不重用也是内聚),那么要重⽤的只会是业务代码,这样修改的范围会⼩很多,同时依靠版本与依赖管理,完全可以避免修改所产⽣的影响。因此这个“开 / 闭原则”,也需要重新再看待,理性使⽤。
- 有了多态这个代换的办法,结果⼤家倒是不⽤来遵守开闭原则了,⽽是⽤来尽可能的抽象,结果把本来应该内聚在⼀个类中的⽅法和属性,分散到许多不同的⽗类中去了,这是很⼤的⼀个弊病。何必要花⼒⽓去抽象呢︖直接引⽤实际的类就好了。除非能够做到⼀次抽象能够适应以后所有的变化,否则还是⽼⽼实实的⾯对实际情况吧。
- Interface segregation principle ,即“接口隔离原则”。这个原则相当于是预设了调⽤者与被调⽤者两⽅的前提,对于调⽤者来讲,被调⽤者的接⼜数量应该最⼩化。这个原则其实就是通道访问的隔离。在访问通道上,不同的客户端,不可以使⽤同样的访问通道,因为会导致它们之间的访问互相影响,这是很简单的道理。比如⼀个居民⼩区的车道和⼈⾏道必须要分离。
很多⼈也会提到“⾼内聚、低耦合”的原则。这个“⾼、低”的说法不够严谨。只要某个业务的⽣命周期活动不在⼀个类中确定,那么这个类就没有形成内聚,反之就是做到了内聚(这也是ddd为什么提倡“充血类”)。只要做到内聚,就没耦合了,就只有依赖关系,⽽且这个依赖是⼀个树状的结构;只要没做到内聚,肯定耦合了,没有⾼低之分,最后都会带来麻烦,区别在于带来麻烦的多少⽽已。所以⼀个应⽤要么没有内聚,只有耦合,要么只有内聚,没有耦合,只有其中⼀个情况。
架构设计的的核⼼原则就是“内聚”,任何架构原则都不能违反此原则。这个“内聚”包括两部分:“业务内聚”,“业务访问通道内聚”。所以,对于我们遇到的任何⼀个架构原则都可以这样去判断:如果发现它违反了“业务内聚”原则,我们都要三思,因为会导致业务分散、无法重⽤︔如果它违反“业务访问通道内聚”原则,也就是“业务访问通道不重⽤”原则,我们也要三思,不要去追求访问通道重⽤。
如果做好了业务的内聚,并隔离不同类型客户端对业务的访问通道,形成访问通道的内聚,基本上程序就不会太差,代码就会很稳定。有了这个基础,再根据运营过程中所产⽣的瓶颈点,有针对性的做业务架构拆分或访问通道架构拆分就很容易了。作为⼀个架构设计师或者程序员,如果不把“内聚”放在最重要的位置,最终⼀定会被需求给淹没的。
访问通道内聚的例子,以controller-service-dao 为例,假设有一个订单服务OrderService,OrderService 可以只提供crud 四个方法。但创建、支付、退款、到货等都会引起Order 状态的改变,大家都去调用update 方法 就引起了访问通道的重用,实际上应该屏蔽update 方法,对外提供createOrder/payOrder/refundOrder/completeOrder。A class should have only one reason to change ,一个接口也应该只有一个原因被访问。
教训
-
面向故障编程
- 要给可靠性设计多一点关注,而不只是业务逻辑本身
- 因为需要协作,要一定程度上优先简单、易兜底的方案
- 合适的方案:最优方案一旦某个环节有问题,往往成了最差方案
- 可观测性、可回退性要融入到系统/代码的设计中
- 一个事情必须至少两个人知情,团队内部要有自纠错意识和能力
- 一人一系统 ==> 一人一项目 ==> 两人一项目
- 自身逻辑漏洞 ==> 测试、编程习惯、设计简单性等
- 协作导致逻辑漏洞 ==> 代码走读,code review 结构 + 逻辑
- 简单,设计简单;代码简单;测试简单;复现简单;兜底简单
- 一个事情如果是复杂的,那一定是因为没有想清楚
- 复杂就意味着易出错,尤其是要多人协作的系统
- 先稳定,再迭代
- 全局开关,一键清客户端数据开关,可以随时关闭
- 要确保兜底可以生效
留下评论