函数式编程
简介
- 简介
- 编程范式异同
- 基本特性
- 左耳听风
- 基本概念
- 函数式编程对java设计模式的影响——refactoring object-oriented design patterns with lambdas
- 一些代码技巧
- 实现
许式伟:函数式编程之所以小众,个人认为最重要的原因,是理论基础不广为人知。我们缺乏面向函数式编程的数据结构学。因为变量不可变,数据结构学需要用完全不同思维方式来表达。比如在传统命令式的编程方式中,数组是最简单的基础数据结构,但函数式编程中,数组这样的数据结构很难提供(修改数组的一个元素成本太高,Erlang 语言中数组这个数据结构很晚才引入,用 tree 来模拟数组)。
为什么开始热门了?不管是面向过程,还是面向对象,解决的都还是代码组织问题。我们知道,软件生命周期 最大的过程是维护,维护基本就是debug,debug过程中又会产生新的bug。那么换个思路,干脆在编程阶段,如何编写 易维护的代码?换句话说,哪些因素导致代码容易出bug?函数式编程 在某些层面规避了这些。
- runtime的能力变得更强:一个猜测是:比如并发执行for循环,那么如果还在语言中写for循环的话,jvm就不知道是否可以并发执行。
- 语言获得了更强大的抽象(比如异步future、缓存等下沉到语言层面),代码中只要填一个处理函数的场景越来越多了。大家想下,一个异步框架 给你的抽象 是不是实现一个callback 就行了。当语言将这个框架的能力 集成进来以后,可以将这个 callback 的接口做的更简洁。
函数式编程提倡不可变性、高阶函数和函数组合。这些特性合在一起就能使代码简洁、富有表现力、易于理解和修改。所以开发世界变得更加函数化,这使开发人员可以花费更多的时间来思考结果的影响,而不是思考如何生成结果。比如以前语言不支持、异步也不用框架的话,就难免异步代码 和 业务代码 混淆在一起。由于高阶函数等抽象出现在语言中,它们将成为高度优化的操作的自定义机制。PS:现成库越来越丰富了,业务无关的代码越来越多的依赖现成库,业务代码抽成函数 + 部分库依赖 就可以完成一个项目。
因此,函数式编程的流行,跟语言的发展有关系,以前不流行,不是不想,是语言暂时没办法提供那个抽象能力。函数式编程 函数式思维和函数式编程
编程范式异同
声明式与命令式
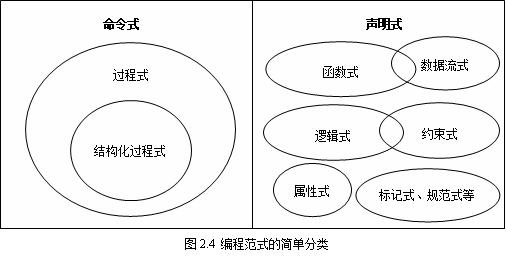
命令式编程是行动导向(Action-Oriented)的,因而算法是显性而目标是隐性的;声明式编程是目标驱动(Goal-Driven)的,因而目标是显性而算法是隐性的。声明式编程是人脑思维方式的抽象,即利用数理逻辑或既定规范对已知条件进行推理或运算。已知 ==> 未知。
命令式编程中的变量本质上是抽象化的内存,变量值是该内存的储存内容。声明式编程让我们重回数学思维:函数式编程类似代数中的表达式变换和计算,逻辑式编程则类似数理逻辑推理。其中的变量也如数学中的一样,是抽象符号而非内存地址,因此没有赋值运算,不会产生变量被改写的副作用(side-effect),也不存在内存分配和释放的问题。
声明式语言与命令式语言的相通之处
- 首先,所有高级语言都建立于低级语言之上,最终转化为机器语言,声明式语言也不例外。
- 其次,声明式语言与命令式语言并非泾渭分明,而是互相交叉渗透的。一些‘非纯粹’ 的声明式语言也提供变量赋值和流程控制,而一些命令式语言也在逐渐发展,通过利用其他程序或增加新的语言特征来实现声明式编程。
总的说来,在命令式语言中融入声明式的元素应当是一种趋势。尤其是函数式,它的一些特征已经在许多命令式语言中得到了支持。
既然声明式编程有这么多好处,为什么命令式语言不仅占大多数,而且流行程度也不减呢?编程语言的流行程度与其擅长的领域关系密切。声明式语言——尤其是函数式语言和逻辑式语言——擅长基于数理逻辑的应用,如人工智能、符号处理、数据库、编译器等,对基于业务逻辑的、尤其是交互式或事件驱动型的应用就不那么得心应手了。而大多数软件是面向用户的,交互性强、多为事件驱动、业务逻辑千差万别,显然命令式语言在此更有用武之地。
# 命令式
def findMax(temperatures:List[Int]) = {
var highTemperature = Integer.MIN_VALUE
for (temperature <- temperatures){
highTemperature = Math.max(highTemperature,temperature)
}
highTemperature
}
# 函数式
def findMax(temperatures:List[Int]) = {
# 集合的foldLeft()方法在集合的每一个元素上应用函数Math.max(),java.lang.Math类的max()方法接受两个参数,并算出两者中的较大者。这两个参数在前面的代码中被隐式传递。max()方法的第一个隐式参数是前一次计算出的最高值,而第二个参数是集合在被foldLeft()方法遍历时的当前元素。
temperatures.foldLeft(Integer.MIN_VALUE){ Math.max }
}
与其它编程范式对比
Java如何支持函数式编程?每个编程范式都有自己独特的地方,这就是它们会被抽象出来作为一种范式的原因。面向对象编程最大的特点是:以类、对象作为组织代码的单元以及它的四大特性。面向过程编程最大的特点是:以函数作为组织代码的单元,数据与方法相分离。那函数式编程最独特的地方又在哪里呢?实际上,函数式编程最独特的地方在于它的编程思想。函数式编程认为程序可以用一系列数学函数或表达式的组合来表示。函数式编程是程序面向数学的更底层的抽象,将计算过程描述为表达式。不过,这样说你肯定会有疑问,真的可以把任何程序都表示成一组数学表达式吗?理论上讲是可以的。但是,并不是所有的程序都适合这么做。函数式编程有它自己适合的应用场景,比如科学计算、数据处理、统计分析等。对于强业务相关的大型业务系统开发来说,费劲吧啦地将它抽象成数学表达式,硬要用函数式编程来实现,显然是自讨苦吃。相反,在这种应用场景下,面向对象编程更加合适,写出来的代码更加可读、可维护。
具体到编程实现,函数式编程跟面向过程编程一样,也是以函数作为组织代码的单元。不过,它跟面向过程编程的区别在于,它的函数是无状态的。何为无状态?简单点讲就是,函数内部涉及的变量都是局部变量,不会像面向对象编程那样,共享类成员变量,也不会像面向过程编程那样,共享全局变量。函数的执行结果只与入参有关,跟其他任何外部变量无关。同样的入参,不管怎么执行,得到的结果都是一样的。这实际上就是数学函数或数学表达式的基本要求。在FP中有一个严格的要求和规范,就是不能变更入参,要保证多次执行之后的结果是一致的(框架实现中的基于context传递的面向过程的编程方式不在此列)。
不同的编程范式之间并不是截然不同的,总是有一些相同的编程规则。比如不管是面向过程、面向对象还是函数式编程,它们都有变量、函数的概念,最顶层都要有main函数执行入口,来组装编程单元(类、函数等)。只不过,面向对象的编程单元是类或对象,面向过程的编程单元是函数,函数式编程的编程单元是无状态函数。
基本特性
2019.3.24补充
在1995年到2008年的这段时期,可谓是函数式编程的”中世纪“,C++/Java等编程语言的使用率不断增加,而命令式的、面向对象的编程风格成为编写应用程序和解决问题最流行的方式。终于,多核心cpu的到来为并行化开辟了新机会, 在这样的环境中,具有副作用的命令式编程结构可能难以为继。这引领函数式编程进入了”文艺复兴“时期,许多编程语言都包含来自函数式编程中的结构成分,因为这些成分可以更好地帮助分析推导并发和并行应用程序中的问题。
函数式编程的本质:洞察到程序实际上可以按照纯粹的数学函数来编写;也就是说,每次给这些函数传递相同的输入时,它们将总是返回相同的值,并且不会产生副作用。在函数式编程中编写代码类似于在数学中组合函数。
争用是在多核心cpu上运行的代码最大的性能杀手
不可变性
函数式编程,限制使用赋值语句,它是对程序中的赋值施加了约束。
函数式编程的不变性主要体现在值和纯函数上。
- 值,你可以将它理解为一个初始化之后就不再改变的量,换句话说,当你使用一个值的时候,值是不会变的。
- 纯函数,是符合下面两点的函数:
- 对于相同的输入,给出相同的输出;
- 没有副作用。
编写纯函数的重点是,不修改任何字段,也不调用修改字段内容的方法。绝大多数涉及到可变或者副作用的代码,应该都是与外部系统打交道的。
当一个变量可在不同时刻指向不同的值时,它就被称为具有可变的状态。对不可变的数据执行任何操作都将创建一个新的数据结构,其保存了更改后的结果。
最好使用编译器而不是约定来强制不可变性,这也就意味着将值传递给构造函数,而不是调用setter,并使用编程语言的特性,如Java中的final 以及Scala 中的val。java 并不会让一切都默认不可变,(所以通常要动点手脚),Scala的case class 则默认提供了不可变性,Rust 中变量默认是不可变的(可变变量要特别声明)。类似的还有 领域驱动的值对象(Value Object)
如果将一个表达式替换为其求值后的结果,对程序(其它部分)的执行不产生影响,这个表达式便可称为引用透明。例如在不可变列表中添加、删除或者更新一个值的行为,将会产生一个具有修改后的值的新列表,程序中任何仍然使用该原始列表的部分都不会看到对该列表的更改。PS:从中可以看到,不可变/引用透明有助于提高 可以并行执行的代码比例。
《Scala实用指南》编程中采用不可变性有明显的好处,但是复制对象而不是改变它们难道不会导致性能糟糕并增加内存使用吗?如果不小心,确实会这样。但是Scala依赖于一些特殊的数据结构来提供良好的性能和高效的内存使用。例如,Scala列表是不可变的,因此复制一个列表以在列表的头部增加一个额外的元素将复用已经存在的列表。因此,复制一个列表以将元素插入到列表的开头,在时间复杂度和空间复杂度上都是O(1)。同样,Scala的Vector用一种名为Tries的特殊不可变数据结构实现。在设计上,它就能够高效复制集合,以常数级的时间复杂度和空间复杂度来改变集合中的任意元素。
函数作为第一公民
函数作为第一公民 目的是当让代码根据组合性。
《软件设计之美》:在函数式编程中,有一类比较特殊的函数,它们可以接收函数作为输入,或者返回一个函数作为输出。这种函数叫做高阶函数。它的一个重要作用在于,我们可以用它去做行为的组合。高阶函数的出现,让程序的编写方式出现了质变。按照传统的方式,程序库的提供者要提供一个又一个的完整功能,就像 findByNameAndBySno 这样,但按照函数式编程的理念,它接收了一个函数作为参数,由此,一些处理逻辑就可以外置出去。提供者提供的就变成了一个又一个的构造块,像 find、byName、bySno 这样。然后,使用者可以根据自己的需要进行组合。
早期的函数式编程探索是从 LISP 语言开始的。LISP 这个名字源自“List Processing”,这个名字指明了这个语言中的一个核心概念:List,也就是列表。LISP 的一个洞见就是,大部分操作最后都可以归结成列表转换,也就是说,数据经过一系列的列表转换会得到一个结果。最基础的列表转换有三种典型模式,分别是 map、filter 和 reduce,更多的转换操作都可以基于这三个转换完成。
同样是一组数据的处理,我更鼓励使用函数式的列表转换,而不是传统的 for 循环。因为它是一种更有表达性的写法,它几乎和我们想做的事是一一对应的。 很多 Java 程序员适应不了这种写法,一个重要的原因在于,他们缺少对于列表转换的理解。缺少了一个重要的中间环节,必然会出现不适。在讲 DSL 的时候就谈到过代码的表达性,其中一个重要的观点就是,有一个描述了做什么的接口之后,具体怎么做就可以在背后不断地进行优化。比如,如果一个列表的数据特别多,我们可以考虑采用并发的方式进行处理,而这种优化在使用端完全可以做到不可见。
在实际工作中,如何将面向对象和函数式编程两种不同的编程范式组合运用呢?我们可以用面向对象编程的方式对系统的结构进行搭建,然后,用函数式编程的理念对函数接口进行设计。
左耳听风
2018.9.29 补充:来自《左耳听风》课程
在编程这个世界中,更多的编程工作是解决业务上的问题,而不是计算机的问题。所以内存操作 等这些事情 尽量不要反应到 业务代码上来。
代码 = 控制 + 逻辑,代码在描述 你要干什么,而不是怎么干。map/reduce 是控制,toUpper/sum 是业务逻辑。函数式编程固化/隐藏了“控制”代码,使得“逻辑” 代码的编写显式化了。
在皓哥文章末的评论中,有用户提到:面向对象编程和函数式编程 他们的关注点不一样,面向对象编程 帮助你设计更复杂的应用程序,函数式编程帮助你简化更复杂的计算。所以,我们学东西不是为了腾笼换鸟,而是胸有谋划,师夷长技。
柯里化
def inc(x):
def incx(y):
return x+y
return incx
incc = inc(2)
inc5 = inc(5)
print inc2(5) // output 7
print inc5(5) // output 10
大牛 从参数分解的角度 对柯里化 的描述是:将一个函数的多个参数 分解成多个函数,然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这样可以简化函数的多个参数。
装饰器
皓哥用专门一章讲了装饰器, 从全文看,比较好玩的是皓哥如何将装饰器模式、linux 管道、代码层面的编排、pipeline 联系到一起的。
shell 命令
ps auwwx | awk '{print $2}' | sort -n | xargs echo
抽象成函数式的样子(函数嵌套)
xargs(echo,sort(n,awk('print $2',ps(auwwx))))
也可以将函数放进数组里,此处可能需要对三个方法进行修饰(Decorator), 以便将普通函数管道化
pids = for_each(result,[ps_auwwx,awk_p2,sort_n,xargs_echo])
如果我们将这些函数当做微服务,那么管道其实在做服务的编排(再往下有类的编排、方法的编排)。
对于pipeline 式的代码,体现在java中便需要定义pipeline、Step/Stage等接口,然后自定义逻辑实现Step/Stage接口(如果逻辑是已经写好的,还需Decorator 修一下),最后由pipeline 驱动执行。而函数作为“第一公民”后,设计模式的三大类创建、行为、结构中的行为型模式 都可以由函数嵌套、函数参数、函数返回值等直接实现(函数层面),无需上升java的类/接口层面了。换句话说,设计模式由类/接口层面(java 提到设计模式都会有一个复杂的类图) 下沉到 函数层面了,将一些功能或逻辑代码 通过函数的拼装(因此才有了柯里化 和 高阶函数等)来组织。这也可说是 函数式编程的一个体现了吧。
我们弄个小节专门讲下
基本概念
| 函数的概念 | 其它 | ||
|---|---|---|---|
| 函数式编程 | 一种东西和另一种东西之间的对应关系。 | 至于什么柯里化、什么数据不可变,都只是外延体现而已。 | |
| 命令式编程 | 面向过程、面向对象等 | 一个步骤 |
object HelloWorld {
def main(args: Array[String]): unit = {
args.filter( (arg:String) => arg.startsWith("G") )
.foreach( (arg:String) => Console.println("Found " + arg) )
}
}
函数式的代码是“对映射的描述”,查看scala中filter函数的源码,或许更能体会对映射的描述的感觉。
class Array[A]{
// ...
def filter (p : (A) => Boolean) : Array[A] = ... // not shown
}
当我在说函数也是一个对象时,我在说什么:函数作为参数进行传递、把它们存贮在变量中、或者当作另一个函数的返回值
函数不是方法,方法指的是类或对象中定义的函数,方法中的this引用会隐性的指向某一对象。比如(s:String) => s.toUpperCase()便是一个函数,它是独立的,没有通过this与一个对象相关联。函数不是方法,但在某些时候,会将方法归入函数。
scala函数中,有偏函数一说,限定了函数的输入。还有柯里化函数,A way to write functions with multiple parameter lists. For instance
def f(x: Int)(y: Int) is a curried function with two parameter
lists. A curried function is applied by passing several arguments
lists, as in: f(3)(4). However, it is also possible to write a partial
application of a curried function, such as f(3).
比如"hello world"可以称为String字面量,那么(s:String) => s.toUpperCase可以称为函数字面量。
函数没有副作用,比如没有全局对象被修改。当一个函数采用其它函数作为变量或返回值时,它被称为高阶函数。
函数可以内嵌。
一个方法的极简定义def id = Match.random,完整形式def def():Unit = Match.random
定一个函数类型的值(注意是函数不是方法)var greetVar:String => String = (name) => "Hello" + name, 分为三个部分
- var greetVar
- 类型 String => String
- “Hello” + name
一个方法可以赋给一个函数类型的变量val gr = greet _,此处greet是一个方法名。
在该小节中,笔者因为水平和对scala的认识有限,还未能精确描述函数式编程的精髓
- 从基本组成和相互关系的角度来描述,面向对象的基本组成是类和对象,基本组成的相互关系是继承、聚合等。函数式编程基本组成是函数、偏函数等,函数与函数关系可以是调用、内嵌、返回等。当然,面向对象和函数编程是两个维度的东西,对比不太合适。
- 笔者学习spark的时候,了解到,你对data set的一系列函数式调用,并不会被立即执行。比如对一个数据集,你先过滤男性、又将值翻番。从执行角度看,不会是把数据拿出来,先for循环一把过滤,再for循环一把每个值乘以2。一系列的函数调用更像是一个执行计划,spark会优化这些计划的执行,最终可能一次for循环就好了。
函数式编程对java设计模式的影响——refactoring object-oriented design patterns with lambdas
以前分析java 项目,通常会有一个复杂的类图 描述基本抽象及依赖关系。那么通过高阶函数,可以减少类的数量,依赖关系直接成了参数。因此,高阶函数 有利于 简化复杂项目类图的 层次 及 一些边缘抽象。
函数式编程 对传统设计模式的影响(这是个大话题)
- 很多角色 不需要专门的类,比如jib 中Observer 就使用jdk8 自带的Consumer 替代了。
- 高阶函数:一个类本来可以有很多方法,现在都一个主要方法(执行主流程),然后传入Function、Consumer(表示策略) 代替了,模板模式、策略模式基本都消亡了。
- 逻辑聚合越来越普遍了,以前只是数据聚合(比如一个配置类聚合其它配置类,形成一个更大的配置类)。jib-core 很多地方拿Runnable 当成员到处传着玩。反过来说,逻辑更容易被拆分,参见
Consumer.andThen@FunctionalInterface public interface Consumer<T> { void accept(T t); default Consumer<T> andThen(Consumer<? super T> after) { Objects.requireNonNull(after); return (T t) -> { accept(t); after.accept(t); }; } }
此外,从jib-core event 设计中还可以看到一点,用更多Functional interface 对象 替代 if else 逻辑,比如 Jib 中的Handler 只会处理一个特定类型的事件。代码中会有更多的对象、funciton,但每个对象和function 都更简单。
How Functional Programming will (Finally) do Away With the GoF Patterns
- A lot of the GoF design patterns stem from a time when EVERYTHING needed to be an object. Object orientation was the new holy grail, and people even wanted to push objects down into databases. Object databases were invented (luckily, they’re all dead) and the SQL standard was enhanced with ORDBMS features. 面向对象领域,“一切皆对象”是最高准则,人们甚至想把对象存到数据库里去。
- Since Java 8, finally, we’re starting to recover from the damage that was made in early days of object orientation in the 90s, and we can move back to a more data-centric, functional, immutable programming model where data processing languages like SQL are appreciated rather than avoided, and Java will see more and more of these patterns, hopefully.
这部分内容非常重要,在函数式编程的设计模式 有专门阐述。
一些代码技巧
在java8 的List 接口中,存在一个default method void sort(Comparator<? super E> c)
对应java.util.Collections 中的sort 方法
public static <T> void sort(List<T> list, Comparator<? super T> c) {
list.sort(c);
}
从编程的本质 中 可以知道 程序 = 控制 + 逻辑(这与函数式编程理念是非常契合的)。在这里的sort方法中,排序是用冒泡还是插入是控制 ,与业务无关。而Comparator 描述的是逻辑,与业务紧密相关。
在 异步编程——Promise 中作者提了三个接口
interface Callback<R, V> {}
// 对输入采取一定的动作,没有返回
public interface Action<V> extends Callback<Void, V> {
void call(V value) throws Throwable;
}
// 将输入转换为输出
public interface Func<R, V> extends Callback<R, V> {
R call(V value) throws Throwable;
}
// 将输入转换为输出,异步
public interface AsyncFunc<R, V> extends Callback<R, V> {
Promise<R> call(V value) throws Throwable;
}
实现一个完全符合函数式编程理念的项目很难,通常也很少有这样的机会。但在我们日常的代码中,多用用Action、Func、AsyncFunc 这类接口,却可以做到,可以在很大程度上提高代码的可读性。
实现
编译器前端的工作
- 当声明一个函数时,要把它加入到符号表。而当程序中用到某个函数的时候,要找到该函数的声明。
- 既然函数可以被当做一个值使用,那么它一定也是有类型的,也要进行类型检查和推导。
- 举例来说,假设一个函数有两个参数,分别是类型 A 和 B,而返回值的类型是 C,那么这个函数的类型可以计为
(A, B)->C。这就是对函数的类型的形式化的表达。 函数的内部实现,在编译完毕以后,函数在runtime中是怎么表示的呢? - 在 Python 中,一切都是对象,所以函数也是一种对象;在 Scala 和 Java 这种基于 JVM 的语言中,函数在 JVM 这个层次没有获得原生支持,因此函数被编译完毕以后,其实会变成 JVM 中的类。在 Julia、Swift、Go、Rust 这样编译成机器码的语言中,函数基本上就是内存中代码段(或文本段)的一个地址。
- 编译成机器码的函数有什么特点呢?在被调用者的函数体内,通常会分为三个部分。头尾两个部分叫做序曲(prelude)和尾声(epilogue),分别做一些初始化工作和收尾工作。在序曲里会保存原来的栈指针,以及把自己应该保护的寄存器存到栈里、设置新的栈指针等,接着执行函数的主体逻辑。最后,到尾声部分,要根据调用约定把返回值设置到寄存器或栈,恢复所保护的寄存器的值和栈顶指针,接着跳转到返回地址。
留下评论