Python虚拟机
简介
一个典型的编程语言虚拟机包括执行器、垃圾回收器和运行时支持等三大特性。执行器有两种基本的结构:解释器和 JIT(Just In Time,即时编译)执行器。垃圾回收器的主流算法也在不断地演进。Hotspot 从 CMS 走向 G1 回收器,然后向 ZGC 等无暂停垃圾回收算法演化,支持的堆越来越大,回收的效率也越来越高。在 Python 虚拟机中,运行时包括列表、字典等内建类型支持,也包括闭包、函数对象等维持运行时状态的对象。运行时与语言的语法特征有很强的关联性。很多语言仍然在不断地向前发展,所依赖的正是语言运行时提供的能力。
虚拟机执行
Python 虚拟机设计了一种基于栈的字节码,执行过程简洁高效。Python 语言既支持面向对象编程,也支持将函数做为语言的第一类公民,支持自动内存管理。支持语言的动态特性,例如运行时修改类定义、反射等。
编程语言虚拟机的一个重要能力就是屏蔽硬件差异。
- 以 Java 为例,Java 源代码文件会被 javac 先编译生成 class 文件,多个 class 文件可以集中在一起,生成一个 jar 文件。字节码的设计非常类似于 CPU 指令,它有自己定义的数值计算、位操作、比较操作、跳转操作等。所以人们把这种专门为某一类编程语言所开发的字节码以及其解释器合并称为编程语言虚拟机。
- 以 V8 为代表的 JavaScript 虚拟机。网页上的 JS 代码都是以源代码的形式由服务端发送到客户端,然后客户端来执行的。相比 Java 的执行过程,这一过程中缺少了编译生成字节码的步骤。它根本不需要生成字节码,而是直接将源代码翻译成树形结构,我们称之为抽象语法树。然后,V8 的执行器就通过后序遍历这棵树,在访问语法树上的不同结点时,执行与这个结点相对应的动作,最终完成代码的解释执行。这种做法是把源代码的编译和程序的执行直接绑定在一起。
- 以 Go 为代表的静态编译的类型。如果对 Go 语言的源代码进行编译的话,你会发现,即使是很小的一段代码,编译的可执行程序的体积也会很大,这是因为 Go 在编译的时候直接将虚拟机与用户代码链接在了一起。好处是,既能通过虚拟机实现对硬件平台和操作系统的屏蔽,又能提供很好的执行效率。
- Python 比较灵活,一方面它规定了自己的字节码,但它又不要求程序必须以字节码文件(.pyc)来发布。它完全支持甚至鼓励应用程序以源代码的方式发行。本质上,在 Python 虚拟机内部,源代码也是先编译成字节码然后再执行的,也就是说 Python 的编译器 Python 虚拟机的一部分,它不像 Java 虚拟机,javac 用于编译,和执行是分离的。你可以回忆一下 Python 中的 eval 功能,其实 eval 就是调用了 Python 内置的编译器,来编译字符串。CPython 虚拟机既可以执行 py 文件,也可以执行编译过的 pyc 文件,这是因为CPython 里包含了一个可以编译 py 文件的编译器,在执行 py 文件时,第一步就是要把 py 文件先翻译成字节码文件。当然 Python 虚拟机也有其他的开源实现,例如,Jython 是一种用 Java 实现的 Python 语言,它的原理与 CPython 大有不同,它放弃了 Python 的原生字节码,直接将 py 源代码文件翻译成了由 Java 字节码组成的 class 文件。而我们知道,class 文件是可以直接在 Java 虚拟机上执行的,这样一来,Python 代码就可以自由地使用各种强大的 Java 类库。通过编译,Jython 实现了 Python 与 Java 的无缝衔接。
Python 源文件编译之后会得到什么,它的结构是怎样的?和字节码又有什么联系?
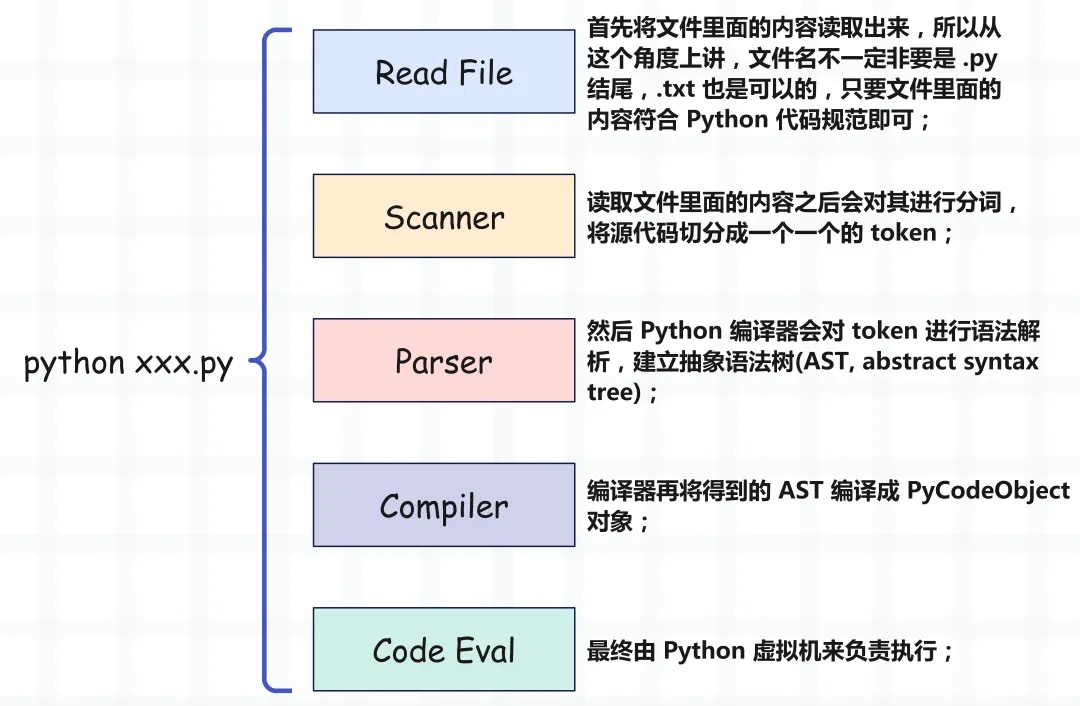 Python 解释器 = Python 编译器 + Python 虚拟机,Python 编译器负责将 Python 源代码编译成 PyCodeObject 对象(不是可执行文件),然后交给 Python 虚拟机来执行。
Python 解释器 = Python 编译器 + Python 虚拟机,Python 编译器负责将 Python 源代码编译成 PyCodeObject 对象(不是可执行文件),然后交给 Python 虚拟机来执行。
我们常听到 py 文件被编译成字节码,这句话其实不太严谨,因为字节码只是一个 PyBytesObject 对象、或者说一段字节序列。虚拟机的执行实际上就是对字节码不断解析的一个过程。然而除了字节码之外,还应该包含一些其它的信息,这些信息也是 Python 运行的时候所必需的,比如常量、变量名等等,这些静态信息也需要被收集起来,它们整体被称为 PyCodeObject。而 PyCodeObject 对象中有一个字段 co_code,它是一个指针,指向了这段字节序列(PyBytesObject?)。但是这个对象除了有 co_code 指向的字节码之外,还有很多其它字段,负责保存代码涉及到的常量、变量(名字、符号)等等。所以虽然编写的是 py 文件,但虚拟机执行的是编译后的 PyCodeObject 对象。但是问题来了,难道每一次执行都要将源文件编译一遍吗?pyc 文件负责保存编译之后的 PyCodeObject 对象。对于 Python 编译器来说,PyCodeObject 对象是对源代码编译之后的结果,可以认为是源码文件的另一种等价形式,而 pyc 文件则是这个对象在硬盘上的表现形式。
Python 编译器在对源代码进行编译的时候,针对每一个 code block(代码块),都会创建一个 PyCodeObject 与之对应。但多少代码才算得上是一个 block 呢?有一个简单而清晰的规则:当进入一个新的名字空间,或者说作用域时,就算是进入了一个新的 block 了。举个例子:
class A:
a = 123
def foo():
a = []
我们仔细观察一下上面这段代码,它在编译完之后会有三个 PyCodeObject 对象,一个是对应整个 py 文件(模块)的,一个是对应 class A 的,一个是对应 def foo 的。因为这是三个不同的作用域,所以会有三个 PyCodeObject 对象。所以一个 code block 对应一个作用域、同时也对应一个 PyCodeObject 对象。Python 的类、函数、模块都有自己独立的作用域,因此在编译时也都会有一个 PyCodeObject 对象与之对应。
深度解密 Python 虚拟机的执行环境:栈帧对象既然源代码在经过编译之后,字节码指令以及静态信息都存储在 PyCodeObject 当中,那么是不是意味着虚拟机就在 PyCodeObject 对象上进行所有的动作呢?很明显不是的,因为尽管 PyCodeObject 包含了关键的字节码指令以及静态信息,但有一个东西是没有包含、也不可能包含的,就是程序在运行时的执行环境,这个执行环境在 Python 里面就是栈帧。因此虚拟机并不是在 PyCodeObject 对象上执行操作的,而是在栈帧对象上。虚拟机在执行时,会根据 PyCodeObject 对象动态创建出栈帧对象,然后在栈帧里面执行字节码。所以栈帧是虚拟机执行的上下文,执行时依赖的所有信息都存储在栈帧中。
name = "古明地觉"
def some_func():
name = "八意永琳"
print(name)
some_func()
print(name)
上面的代码当中出现了两个 print(name),它们的字节码指令相同,但执行的效果却显然是不同的,这样的结果正是执行环境的不同所产生的。因为环境的不同,name 的值也不同。因此同一个符号在不同环境中可能指向不同的类型、不同的值,必须在运行时进行动态捕捉和维护,这些信息不可能在 PyCodeObject 对象中被静态存储。我们可以大致描述一下流程:
- 首先基于模块的 PyCodeObject 创建一个栈帧,假设叫 A,所有的字节码都会在栈帧中执行,虚拟机可以从栈帧里面获取变量的值,也可以修改;
- 当发生函数调用的时候,这里是 some_func,那么虚拟机会在栈帧 A 之上,为 some_func 创建一个新的栈帧,假设叫 B,然后在栈帧 B 里面执行函数 some_func 的字节码指令;
- 在栈帧 B 里面也有一个名字为 name 的变量,但由于执行环境、或者说栈帧的不同,name 指向的对象也不同;
- 一旦函数 some_func 的字节码指令全部执行完毕,那么会将当前的栈帧 B 销毁(也可以保留),再回到调用者的栈帧中来。每当调用函数时,就会在当前栈帧之上创建一个新的栈帧,一层一层创建,一层一层返回;
| 操作系统 | 虚拟机 | |
|---|---|---|
| 程序加载 | 加载可执行文件到内存,设置程序计数器。 | 加载 .pyc 文件中的 PyCodeObject 对象,初始化字节码指令指针。 |
| 内存管理 | 为进程分配内存空间,管理堆和栈。 | 创建和管理 Python 对象,处理内存分配和垃圾回收。 |
| 指令执行 | CPU 逐条执行机器指令。 | 虚拟机逐条执行字节码指令。 |
| 资源管理 | 管理文件句柄、网络连接等系统资源。 | 管理文件对象、套接字等 Python 级别的资源。 |
| 异常处理 | 处理硬件中断和软件异常。 | 捕获和处理 Python 异常。 |
变量、函数、 容器(list/dict)
编程语言的发展为虚拟机技术提供了源动力,而虚拟机技术的发展则为编程语言的发展提供了根本保障。虚拟机中的很多技术是为了支持对应的语言特性才被发明出来的,同样有很多好用的语言特性也是因为虚拟机技术的长足发展才得以实现。所以说,编程语言和虚拟机技术是相互依赖和对立统一的。
- 编译器是如何把源代码翻译成字节码的?词法分析 ==> 语法分析 ==> 生成抽象语法树 ==> 生成字节码。
- 虚拟机是如何执行字节码的?
- 虚拟机的代码里不使用任何的 STL 内建库,这是因为虚拟机中的字符串、整数、列表、字典等结构未来都应该由垃圾回收器自动管理。所以虚拟机必须对数据结构中的每一个字节的分配位置和生命周期有完全的掌控权,这就必然要求所有的数据结构都自主实现,而不能使用第三方类库。
- 对于一个简单的运算,如果使用 C 语言,经过 GCC 等编译器的优化,只需要三四条机器指令就可以完成了。而使用解释执行,最少也要几百条指令才能完成。所以采用解释执行的 Python、Lua 等脚本语言相比 C 语言等静态编译语言,性能表现上往往有数量级的差距。
- 不过可以用即时编译(Just In Time,JIT)来弥补,JIT两大核心机制:可写可执行的内存区域,确保在运行期可以生成可执行的机器码(把我们手写的机器码复制进去,然后使用一个函数指针指向这块内存,并且调用它,就可以执行这一段手写的机器码了);基于性能采样的编译优化(Profiling Guided Optimization, PGO),可以使 JIT 编译器获得超过静态编译器的运行性能。
Interpreter核心逻辑:逐条取出字节码,然后依次执行,一个巨型的 switch 语句,一个 case 分支,对应一个字节码指令的实现。循环遍历 op_code 得到字节码指令,然后交给内部的 switch 语句、执行匹配到的 case 分支,如此周而复始,最终完成了对整个 Python 程序的执行。将自己当成一个 CPU,在栈帧中执行一条条指令,而执行过程中所依赖的常量、变量等,则由栈帧的其它字段来维护。因此在虚拟机的执行流程进入了那个巨大的 for 循环,并取出第一条字节码指令交给里面的 switch 语句之后,第一张多米诺骨牌就已经被推倒,命运不可阻挡的降临了。一条接一条的指令如同潮水般涌来,浩浩荡荡,横无际涯。PS: 复杂东西的源头都很简单,比如k8s controller 的reconcile
void Interpreter::run(HiString* codes) {
int pc = 0;
int code_length = codes->length();
_stack = new int[16]; // 创建一个运行时栈
int top = 0;
// 使用一个大的循环不断地从字节码数组中取出指令
while (pc < code_length) {
unsigned char op_code = codes->value()[pc++];
bool has_argument = (op_code & 0xFF) >= ByteCode::HAVE_ARGUMENT;
int op_arg = -1;
if (has_argument) {
op_arg = (codes->value()[pc++] & 0xFF);
}
int v, w;
// 分别对不同的指令进行处理
switch (op_code) {
case ByteCode::LOAD_CONST:
_stack[top++] = op_arg;
break;
case ByteCode::BINARY_ADD:
v = _stack[--top];
w = _stack[--top];
_stack[top++] = v + w;
break;
case ByteCode::BINARY_MULTIPLY:
v = _stack[--top];
w = _stack[--top];
_stack[top++] = v * w;
break;
default:
printf("Error: Unrecognized byte code %d\n", op_code);
}
}
printf("%d\n", _stack[0]);
delete[] _stack;
}
pc 是一个程序计数器,代表虚拟机当前执行到哪条指令了。当控制流因为分支选择而发生跳转的时候,本质上就是改变这个程序计数器,让它不再顺序向下取指,而是跳转到另外一个目标地址,去把那里的指令取出来执行。所以,所有的跳转指令本质上就是对程序计数器的干预,使它指向我们期望的地址。
(下图是python vm 运行时相关的数据结构,for switch case的运行就是在不停的更新PyFrameObject/PyCodeObject及相关的数据结构)

编程语言虚拟机中Klass-Oop 二元结构。Klass 代表一种具体的类型,它是“类”这个概念的实际体现。例如,Integer 类在虚拟机里就有一个 IntegerKlass 与之对应,所有的整数都是 IntegerKlass 的实例。Oop 是 Ordinary object pointer 的缩写,代表一个普通的对象。每一个对象都有自己的 Klass ,同一类对象是由同一个 Klass 实例化出来的。类与类之间有继承关系,类里还会封装其他的属性和方法。这些信息都会保存在 Klass 结构中。使用这种二元结构,还有一个原因是,我们不希望在普通对象里引入虚函数机制,因为虚函数会在对象的开头引入虚表指针,而虚表指针会影响对象的属性在对象中的偏移。
class Klass {
private:
HiString* _name; // 类的名称
public:
Klass() {};
void set_name(HiString* x) { _name = x; }
HiString* name() { return _name; }
virtual void print(HiObject* obj) {};
virtual HiObject* greater (HiObject* x, HiObject* y) { return 0; }
virtual HiObject* less (HiObject* x, HiObject* y) { return 0; }
virtual HiObject* equal (HiObject* x, HiObject* y) { return 0; }
virtual HiObject* not_equal(HiObject* x, HiObject* y) { return 0; }
virtual HiObject* ge (HiObject* x, HiObject* y) { return 0; }
virtual HiObject* le (HiObject* x, HiObject* y) { return 0; }
virtual HiObject* add(HiObject* x, HiObject* y) { return 0; }
virtual HiObject* sub(HiObject* x, HiObject* y) { return 0; }
virtual HiObject* mul(HiObject* x, HiObject* y) { return 0; }
virtual HiObject* div(HiObject* x, HiObject* y) { return 0; }
virtual HiObject* mod(HiObject* x, HiObject* y) { return 0; }
};
// object/hiObject.hpp
class HiObject {
private:
Klass* _klass; // 指向 Klass 的指针,用于表示这个对象的类型。
public:
Klass* klass() { assert(_klass != NULL); return _klass; }
void set_klass(Klass* x) { _klass = x; }
void print();
HiObject* add(HiObject* x);
HiObject* sub(HiObject* x);
HiObject* mul(HiObject* x);
HiObject* div(HiObject* x);
HiObject* mod(HiObject* x);
HiObject* greater (HiObject* x);
HiObject* less (HiObject* x);
HiObject* equal (HiObject* x);
HiObject* not_equal(HiObject* x);
HiObject* ge (HiObject* x);
HiObject* le (HiObject* x);
};
// 把 HiObject 中的函数都实现为转向调用自己所对应的 Klass 中的函数。
// object/hiObject.cpp
void HiObject::print() {
klass()->print(this);
}
HiObject* HiObject::greater(HiObject * rhs) {
return klass()->greater(this, rhs);
}
// other comparision methods.
// ...
HiObject* HiObject::add(HiObject * rhs) {
return klass()->add(this, rhs);
}
// other arithmatic methods.
// ...
有了HiObject和Klass,虚拟机就有了对象系统,可以实现内建或自定义 class,比如HiInteger ==> HiObject, IntegerKlass => Klass。
函数(FunctionObject)与栈帧(FrameObject)。FunctionObject/CodeObject 包含了关键的字节码指令以及静态信息,但有一个东西是没有包含、也不可能包含的,就是程序在运行时的执行环境,这个执行环境在 Python 里面叫做栈帧。在虚拟机执行器里,要实现一种数据结构,来记录函数的调用过程,这个数据结构就是 FrameObject。每一次调用一个函数,就有一个这次调用的活动记录,也就是说每次函数调用,都会创建一个 FrameObject。每次函数执行结束,相应的 FrameObject 也会被销毁。PS:基于一个函数构建栈帧时,基于PyCodeObject vm 已经知道了这个函数的所有局部变量,因此栈帧的大小(包含哪些变量)就已经知道了。
class FrameObject {
public:
FrameObject(CodeObject* codes);
~FrameObject();
ArrayList<HiObject*>* _stack;
ArrayList<Block*>* _loop_stack;
ArrayList<HiObject*>* _consts;
ArrayList<HiObject*>* _names;
Map<HiObject*, HiObject*>* _locals; // 记录了局部变量的值。有一个LOAD_NAME zh
Map<HiObject*, HiObject*>* _globals; // 全局变量
CodeObject* _codes;
int _pc; // 记录了程序当前执行到的位置
_sender = NULL; // 记录调用者的栈帧,当函数执行结束的时候,就会通过这个域返回到调用者的栈帧里。
public:
void set_pc(int x) { _pc = x; }
int get_pc() { return _pc; }
ArrayList<HiObject*>* stack() { return _stack; }
ArrayList<Block*>* loop_stack() { return _loop_stack; }
ArrayList<HiObject*>* consts() { return _consts; }
ArrayList<HiObject*>* names() { return _names; }
Map<HiObject*, HiObject*>* locals() { return _locals; }
bool has_more_codes();
unsigned char get_op_code();
int get_op_arg();
};
unsigned char FrameObject::get_op_code() {
return _codes->_bytecodes->value()[_pc++];
}
bool FrameObject::has_more_codes() {
return _pc < _codes->_bytecodes->length();
}
int FrameObject::get_op_arg() {
int byte1 = _codes->_bytecodes->value()[_pc++] & 0xff;
int byte2 = _codes->_bytecodes->value()[_pc++] & 0xff;
return byte2 << 8 | byte1;
}
和它相应的,Interpreter 的 run 方法也发生了很多变化。
void Interpreter::run(CodeObject* codes) {
_frame = new FrameObject(codes);
eval_frame();
destroy_frame();
}
void Interpreter::eval_frame() {
...
while (_frame->has_more_codes()) {
unsigned char op_code = _frame->get_op_code();
...
FunctionObject* fo;
...
switch (op_code) {
...
case ByteCode::CALL_FUNCTION:
// 将 FrameObject 切换到新函数后,,返回到 run 方法里继续执行。_frame变量已经发生了变化。_frame 里的程序计数器已经指向要调用的目标方法里了。
build_frame(POP());
break;
case ByteCode::RETURN_VALUE:
_ret_value = POP();
if (_frame->is_first_frame()) // 如果某个 FrameObject 的 sender 为 NULL,就代表它是第一个栈帧,是程序开始的地方,或者说是“主程序”,因为它没有调用者。直接结束 run 的逻辑即可
return;
leave_frame();
break;
...
}
}
}
void Interpreter::build_frame(HiObject* callable) {
FrameObject* frame = new FrameObject((FunctionObject*) callable);
frame->set_sender(_frame);
_frame = frame;
}
void Interpreter::leave_frame() {
destroy_frame(); // 将被调用者的 FrameObject 销毁
PUSH(_ret_value); // 将返回值 push 到调用者的栈帧中去
}
void Interpreter::destroy_frame() {
FrameObject* temp = _frame;
_frame = _frame->sender(); // 将 _frame 变量切换为自己的调用者的栈帧
delete temp; // FrameObject 的生命周期是确定的,所以使用 delete 来销毁和释放,其它虚拟机的内部对象都会使用垃圾回收器进行自动管理
}
修饰器不过是类似函数调用add = call_cnt(add)的一种语法上的简写、语法糖。在vm实现,如果一个方法被装饰器修饰,则函数调用的字节码会从CALL_FUNCTION改为CALL_FUNCTION_EX,解释器会帮忙将add 调用改为 add=call_cnt(add) 后的add。PS:所以是不是可以认为,语法糖的实现都有解释器帮忙?
总结:字节码可以视为一个dsl文件,然后用c++写了一个程序/引擎去执行这个文件 ==> 这个c++程序有一些基本设计 Klass-Oop(包括内建class 与自定义class)来支持一个基本流程Interpreter.run,每一个字节码都对应一段c++代码的执行,用户数据(变量或对象)是一堆Klass-Oop,Interpreter.run 就是在不停的新增、删除、执行Klass-Oop的方法。
面向对象
从实现上讲,面向对象编程这一部分包括自定义类型、运行时判断对象类型、继承、函数和操作符重载等特性。
- 在vm里,类型是使用 Klass 表示的,对象则都是继承自 HiObject,虚拟机执行的计算、运行时栈、全局变量表、局部变量表等等,所有的机制都是建立在 HiObject 的基础上。
- 每一个 Klass 都有一个对应的 TypeObject。Python 中一切皆是对象,就连类型也是对象。如果用于判断一个对象的类型时(type(xx)),就会使用 Klass.TypeObject 来完成相应的功能。
class TypeKlass : public Klass { private: ... public: static TypeKlass* get_instance(); }; class HiTypeObject : public HiObject { private: Klass* _own_klass; } class Klass { private: Klass* _super; HiTypeObject* _type_object; ... public: ... void set_type_object(HiTypeObject* x) { _type_object = x; } HiTypeObject* type_object() { return _type_object; } ... }; - 在 Python 中,所有的类都是 object 的子类,无论整数、字符串、列表还是其他的用户自定义的类,无一例外。Python 中的继承关系是通过 Klass 的 super 指针串联起来的,所有类型的 Klass 沿着它的 super 指针向上查找,最终都会停留在 ObjectKlass 里。
- 将类型作为函数调用来创建对象是类型系统中最重要的一个功能。创建对象使用的语法和函数调用的语法是相同的,它们最后生成的字节码也是相同的,都是 CALL_FUNCTION,在函数调用的执行部分添加了类型判断。如果被调用者是一个类型对象时,就代表这个时候应该创建一个新的对象。
PS:是不是可以认为
- 从c++视角出发实现一个“编程语言(解释器)”的业务,该如何抽象?一般面向对象,所有对象都有一个公共父类(比如叫object),因为在python使用方看来,即便一个python对象没有数据和方法,但是c++解释执行的时候,对应的c++对象要有一些解释执行时会用到的数据(比如_mark_word)、方法。
- 如果编程语言只支持int/str/list/dict等基本类型,则使用Kclass/HiObject抽象就够用了,代码里声明一个int,解释器就对应创建一个HiInteger 就行了。只支持基本类型肯定不够,得允许用户扩展,但也不可能让用户直接定义Kclass/HiObject,于是放开给用户定义TypeKlass,再支持根据TypeKlass 生成HiTypeObject(将类型作为函数调用来创建对象),HiTypeObject再作为 Klass 的成员。
- 综上,比如定义了一个python student 对象,vm不会对应有一个 c++ 的student存在,vm会对应一个new HiObject 对象(持有HiTypeObject等引用),HiObject 有一些公共方法便于vm 对它的管理,student.func 的执行也会转为 HiObject.call(?)执行,最终转到HiTypeObject 上去。
内存管理
由编程语言虚拟机管理起来的内存统称为虚拟机堆,在 Python 这个场景中,人们就会简称为 Python 堆,便于和进程堆进行区分。进程堆是指进程中可以使用 malloc 和 free 进行分配和释放的一块用户态内存区域。而 Python 堆则专指创建普通 Python 对象的地方,这一段内存是由虚拟机所管理的。
垃圾回收可以分为引用计数和 Tracing GC 两大类,其中引用计数的代表就是 CPython,也就是我们平常最常使用的社区版 Python。而大多数编程语言虚拟机基本上都使用 Tracing GC。
Python 中一切皆对象。因此,你所看到的一切变量,本质上都是对象的一个指针。那么,怎么知道一个对象,是否永远都不能被调用了呢?引用计数(sys.getrefcount(a),getrefcount 本身也会引入一次计数;在函数调用发生的时候,会产生额外的两次引用,一次来自函数栈,另一个是函数参数。)。
相比 C 语言里,你需要使用 free 去手动释放内存,Python 的垃圾回收在这里可以说是省心省力了。不过,如果我偏偏想手动释放内存,应该怎么做呢?方法同样很简单。你只需要先调用 del a 来删除对象的引用;然后强制调用 gc.collect(),清除没有引用的对象,即可手动启动垃圾回收。
引用计数实现
- Mutator 在运行中会不断地修改对象之间的引用关系,这种引用关系的变化都是发生在赋值的时候。以 Python 为例,赋值语句最终会被翻译成 STORE_XX 指令,那么我们就可以在执行 STORE 指令的时候,做一些手脚了。如果使用伪代码表示出来,就是这样的:
void do_oop_store(Value * obj, Value value) { inc_ref(&value); dec_ref(obj); obj = &value; } void inc_ref(Value * ptr) { ptr->ref_cnt++; } void dec_ref(Value * ptr) { ptr->ref_cnt--; if (ptr->ref_cnt == 0) { // 如果某个对象的引用计数为 0,就把这个对象回收掉 collect(ptr); // 然后把这个对象所引用的所有对象的引用计数减 1。 for (Value * ref = ptr->first_ref; ref != null; ref=ref->next) dec_ref(ref); } } - 我们在写一个对象的域的时候做了一些工作,就好比在更新对象域的时候,对这个动作进行了拦截。所以,GC 中对这种特殊的操作起了一个比较形象的名字叫 write barrier。那在 do_oop_store 里,可不可以先做减,后做加呢?就是说第 2 行和第 3 行的先后顺序换过来有没有影响呢?答案是不行。因为当 obj 和 value 是同一个对象的时候,如果先减后加的话,这个对象就会被回收,内存有可能会被破坏。那么,这个对象就有可能发生数据错误。
- 从算法描述中容易推断出来,引用计数可以立即回收垃圾。因为每个对象在被引用次数为 0 的时候,是立即就可以知道的,所以一旦一个对象成为垃圾,它将立即被释放。此外,引用计数没有暂停时间。对象的回收根本不需要另外的 GC 线程专门去做,业务线程自己就搞定了,所以引用计数算法不需要停顿时间。同时,引用计数也存在一些缺点。
- 比如在每次赋值操作的时候都要做额外的计算。
- 在多线程的情况下,为了正确地维护引用计数,需要同步和互斥操作,这往往需要通过锁来实现,这会给多线程程序性能带来比较大的损失。
- 其次,会有链式回收的情况。比如多个对象对链表形式串在一起,它们的引用计数都为 1,当链表头被回收时,整个链表都会回收,这可能会导致一次回收所使用的时间过长。
- 另外,引用计数还容易引起循环引用的问题。如果 objA 引用了 objB,objB 也引用了 objA,但是除此之外,再没有其他的地方引用这两个对象了,这两个对象的引用计数就都是 1。这种情况下,这两个对象是不能被回收的。Python 在引用计数之外,另外引入了三色标记算法,保证了在出现循环引用的情况下,垃圾对象也能被正常回收。
基于引用追踪的垃圾回收算法
Python 使用标记清除(mark-sweep)算法和分代收集(generational),来启用针对循环引用的自动垃圾回收。先来看标记清除算法。我们先用图论来理解不可达的概念。对于一个有向图,如果从一个节点出发进行遍历,并标记其经过的所有节点;那么,在遍历结束后,所有没有被标记的节点,我们就称之为不可达节点。显而易见,这些节点的存在是没有任何意义的,自然的,我们就需要对它们进行垃圾回收。当然,每次都遍历全图,对于 Python 而言是一种巨大的性能浪费。所以,在 Python 的垃圾回收实现中,mark-sweep 使用双向链表维护了一个数据结构,并且只考虑容器类的对象(只有容器类对象才有可能产生循环引用)。而分代收集算法,则是另一个优化手段。Python 将所有对象分为三代。刚刚创立的对象是第 0 代;经过一次垃圾回收后,依然存在的对象,便会依次从上一代挪到下一代。而每一代启动自动垃圾回收的阈值,则是可以单独指定的。当垃圾回收器中新增对象减去删除对象达到相应的阈值时,就会对这一代对象启动垃圾回收。
- 标记(Mark)核心在于对象图的遍历。标记就是从根集合出发,根据对象之间的引用关系在整个图中进行搜索,能访问到的对象就标记为活跃的。基于此,我们就为每个对象添加一个额外的域来记录这个对象是否存活。搜索的过程可以是深度优先遍历,也可以是广度优先遍历。等到遍历结束的时候,所有存活的对象就都被标记过了,而所有的不可达对象,也就是变成垃圾的对象都没有被标记。
- 清除(Sweep)。我们从头开始逐个访问对象,如果一个对象被标记了,那就什么也不做(当然,要把标记信息清除一下,以备下一次 GC 时可用)。如果一个对象未被标记,那就把它们的起始地址和大小记录到一个链表中去就可以了。由于这个链表记录了未使用的空间,所以它有一个专门的名字叫 freelist。
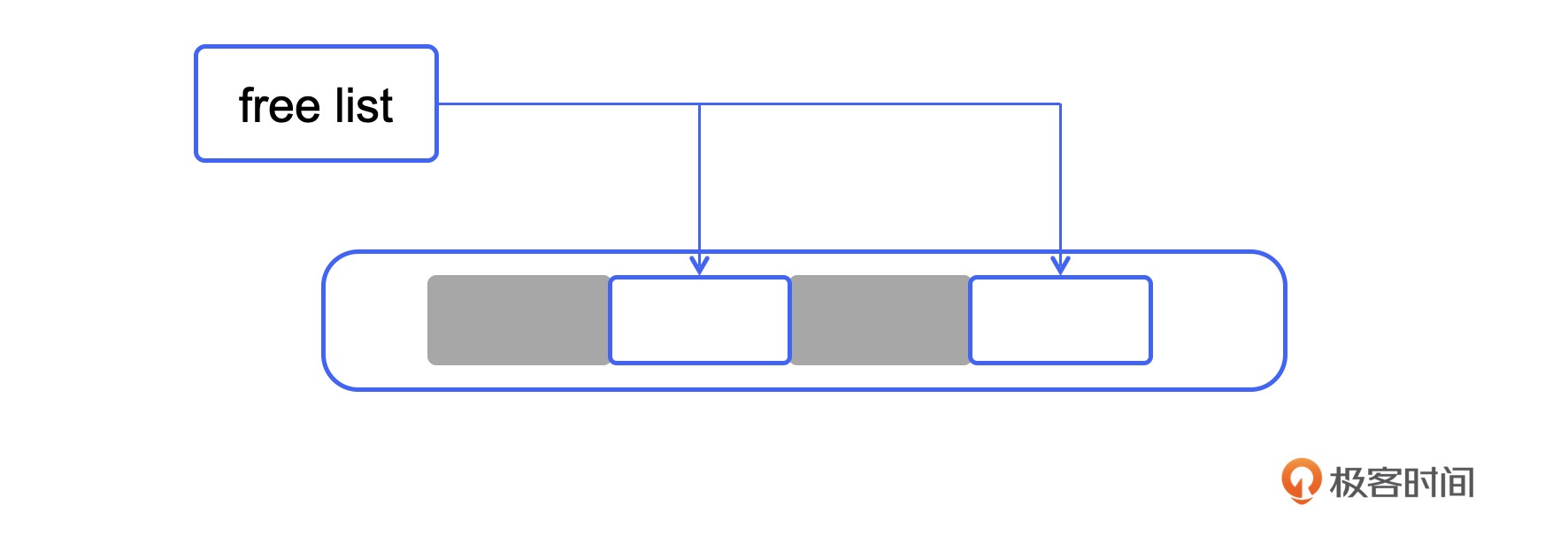
sweep() {
p = heap_start;
while (p < heap_end) {
if (p.is_mark())
p.clear_mark();
else
collect(p);
p += p.size();
}
}
// collect 函数会把一块不使用的内存放到链表里
collect(obj) {
last_free_chunk = free_list.last_chunk();
if (last_free_chunk.end() == obj)
last_free_chunk.inc_size(obj.size());
else
free_list.add_chunk(new chunk(obj, obj.size()));
}
由于堆里未使用的空间都使用 freelist 管理起来了。在创建对象的时候去堆里分配内存,就需要去空闲链表中找一块可用的空间,分配给这个新的对象。在找可用空间的时候,又有几种常见的策略。
- 遍历链表,找到第一块 size 大于或等于所需空间的,就立即返回这块 chunk。这种方式叫做 first-fit。
- 从链表中找到符合条件的所有 chunk,并从中挑选最小的那个。这种方式叫做 best-fit。
- 从链表中找到符合条件的所有 chunk,并从中挑选最大的那个。这种方式叫做 worst-fit。 Mark-Sweep 算法的内存分配相对复杂。另外,Mark-Sweep 还有一个比较大的缺点,就是内存的碎片化。
基于 Copy 的 GC 算法
CPython 的垃圾回收主要靠引用计数,这样方便实现,但是遇到引用循环容易导致内存泄露,因此CPython 2.0实现了分代垃圾回收程序,它能把引用循环中不可达的对象销毁。
最基础的 Copy 算法,就是把程序运行的堆分成大小相同的两半,一半是 From 空间,一半是 To 空间。当创建新对象的时候,都是在 From 空间里进行内存的分配。等 From 空间满了以后,垃圾回收器就会把活跃对象复制到 To 空间,把原来的 From 空间全部清空。然后再把这两个空间交换,也就是说 To 空间变成下一轮的 From 空间,现在的 From 空间变成 To 空间。
void copy_gc() {
# 从 roots 的遍历开始的
for (obj in roots) {
*obj = copy(obj); # 对每一个 roots 中的对象都执行 copy 方法
}
}
obj * copy(obj) {
new_obj = to_space.allocate(obj.size); # 在 To 空间中申请一块新的内存
copy_data(new_obj, obj, size); # 将对象拷贝到 To 空间
for (child in obj) { # 对这个对象所引用到的对象进行递归的拷贝
*child = copy(child);
}
return new_obj; # 返回新空间的地址
}
实现 GC 的第一步是创建虚拟机的堆,以后所有对象的内存分配就都在这个堆里进行。Heap 类代表了虚拟机堆,它包含了三个空间,分别是 survivor 空间、eden 空间和 meta 空间(把 Klass 放到 meta 空间里,meta 空间中的信息相对稳定,不需要频繁回收)。
class Heap {
private:
Space* mem_1;
Space* mem_2;
Space* eden;
Space* survivor;
Space* metaspace;
Heap(size_t size);
public:
static size_t MAX_CAP;
static Heap* instance;
static Heap* get_instance();
~Heap();
void* allocate(size_t size);
void* allocate_meta(size_t size);
void copy_live_objects();
double rate() { return eden->rate(); }
void gc();
};
Space 代表了一个独立的空间,一个空间的基本属性包括它的起始起址 _base、尾地址 _end、总的容量 _size、当前可用内存的开始地址 _top,以及当前可用内存的总量 _capacity。
class Space {
friend class Heap;
private:
char* _base;
char* _top;
char* _end;
size_t _size;
size_t _capacity;
double _rate;
Space(size_t size);
~Space();
public:
void* allocate(size_t size);
void clear();
bool can_alloc(size_t size);
bool has_obj(char* obj);
double rate() { return _rate; }
};
Heap* Heap::instance = nullptr;
size_t Heap::MAX_CAP = 2 * 1024 * 1024;
Heap* Heap::get_instance() {
if (instance == nullptr)
instance = new Heap(MAX_CAP);
return instance;
}
// 指定堆中每个 space 的容量大小
Heap::Heap(size_t size) {
mem_1 = new Space(size);
mem_2 = new Space(size);
metaspace = new Space(size / 16);
mem_1->clear();
mem_2->clear();
metaspace->clear();
eden = mem_1;
survivor = mem_2;
}
Heap::~Heap() {
if (mem_1) {
delete mem_1;
mem_1 = nullptr;
}
if (mem_2) {
delete mem_2;
mem_2 = nullptr;
}
if (metaspace) {
delete metaspace;
metaspace = nullptr;
}
eden = nullptr;
survivor = nullptr;
}
// 定义了从堆中申请内存的逻辑。如果当前的 eden 区足够分配,那就直接分配,如果不够分配,就调用一次 gc 方法,进行内存回收,然后再分配。
void* Heap::allocate(size_t size) {
if (!eden->can_alloc(size)) {
gc();
}
return eden->allocate(size);
}
// 从 meta 空间中申请内存
void* Heap::allocate_meta(size_t size) {
if (!metaspace->can_alloc(size)) {
// 由于我们的垃圾回收算法在回收时不会回收 meta 空间内的对象,所以如果 meta 空间不够用的时候,就只能报错退出。
return nullptr;
}
return metaspace->allocate(size);
}
void Heap::copy_live_objects() {
ScavengeOopClosure(eden, survivor, metaspace).scavenge();
}
void Heap::gc() {
// 调用 copy_live_objects 将存活对象复制到 survivor 空间中去
// 交换 eden 和 survivor 指针
}
建立好堆空间以后,全部统一在堆中分配对象。原本python new一个student,底层要new 一个HiObject,此时用的是c++的内存,这块内存不归vm管理。把 HiObject.new 重载掉,所有 HiObject 的子类在实例化的时候,都会通过虚拟机的堆分配内存。由于 HiObjet 类是所有 Python 对象的超类,这就意味着所有的 Python 对象全部都已经被管理起来了。 代码层面new Python对象 ==> 虚拟机层面new HiObject ==> heap->allocate(size) ==> eden->allocate(size) 链式分配。
// [runtime/universe]
class Universe {
public:
...
static Heap* heap;
static void genesis();
};
Heap* Universe::heap = nullptr;
void Universe::genesis() {
heap = Heap::get_instance();
...
}
// [object/hiObject]
class HiObject {
...
public:
...
void* operator new(size_t size);
};
void* HiObject::operator new(size_t size) {
return Universe::heap->allocate(size);
}
按照同样的思路,我们再把 Klass 也管理起来。Klass 存储python 类信息,new Klass的时候实际分配的内存在heap meta空间。 heap->allocate_meta(size)。
// [runtime/universe]
class Universe {
public:
...
static ArrayList<Klass*>* klasses;
};
// 在 Universe 里新增了一个元素类型为 Klass 指针的 ArrayList,名字为 klasses,用于记录整个虚拟机中所有的 Klass。通过这种方式可以知道虚拟机创建了哪些 Klass,方便我们快速遍历。
ArrayList<Klass*>* Universe::klasses = NULL;
void Universe::genesis() {
heap = Heap::get_instance();
klasses = new ArrayList<Klass*>();
...
}
// [object/klass]
class Klass {
public:
...
void* operator new(size_t size);
};
void* Klass::operator new(size_t size) {
return Universe::heap->allocate_meta(size);
}
Klass::Klass() {
Universe::klasses->add(this);
_klass_dict = NULL;
_name = NULL;
_super = NULL;
_mro = NULL;
}
PS:新增一个python student类对应新增一个klass,new 一个student 对应vm new 一个HiObject。之前vm new klass/HiObject的时候用的c++ 进程内存,有了基于一套分配回收理念的heap之后,new的klass/HiObject 使用了heap空间,第一次将klass-oop、python对象、vm c++对象、heap空间管理都呼应上了。极简版类似于,自己申请了一个byte[],然后new 一个对象初始化放在byte[] 上。这是为何有了堆内堆外的区别。
搬移对象:最适合完成搬移对象功能的结构就是访问者模式。我们定义一个 ScavengeOopClosure 类,它在访问每一个堆内的对象时,就可以完成对象的搬移和指针修改。OopClosure 是访问者的接口类,所以里面定义的方法都是纯虚方法。ScavengeOopClosure 是访问者的具体实现类,针对不同的被访问者提供了具体的访问方法。如果对象是 HiObject,就使用 do_oop 进行访问,如果对象是 Map,就使用 do_map 进行访问。当然,具体实现类不仅仅是 ScavengeOopClosure 这一种,我们也可以通过继承 OopClosure 实现其他的 GC 算法,例如标记清除和标记压缩等。
// [memory/heap.cpp]
void Heap::copy_live_objects() {
ScavengeOopClosure(eden, survivor, metaspace).scavenge();
}
// [memory/oopClosure.hpp] 访问者的接口类
class OopClosure {
public:
virtual void do_oop(HiObject** obj) = 0;
virtual void do_array_list(ArrayList<Klass*>** alist) = 0;
virtual void do_array_list(ArrayList<HiObject*>** alist) = 0;
virtual void do_array_list(ArrayList<HiString*>** alist) = 0;
virtual void do_map(Map<HiObject*, HiObject*>** amap) = 0;
virtual void do_raw_mem(char** mem, int length) = 0;
virtual void do_klass(Klass** k) = 0;
};
// 访问者的具体实现类,针对不同的被访问者提供了具体的访问方法。
class ScavengeOopClosure : public OopClosure {
private:
Space* _from;
Space* _to;
Space* _meta;
Stack<HiObject*>* _oop_stack;
HiObject* copy_and_push(HiObject* obj);
public:
ScavengeOopClosure(Space* from, Space* to, Space* meta);
virtual ~ScavengeOopClosure();
virtual void do_oop(HiObject** oop);
virtual void do_array_list(ArrayList<Klass*>** alist);
virtual void do_array_list(ArrayList<HiObject*>** alist);
virtual void do_array_list(ArrayList<HiString*>** alist);
template <typename T>
void do_array_list_nv(ArrayList<T>** alist);
virtual void do_map(Map<HiObject*, HiObject*>** amap);
virtual void do_raw_mem(char** mem, int length);
// CAUTION : we do not move Klass, because they locate at MetaSpace.
virtual void do_klass(Klass** k);
void scavenge();
void process_roots();
void ScavengeOopClosure::scavenge() {
// step 1, mark roots
process_roots();
// step2, process all objects;
while (!_oop_stack->empty()) {
_oop_stack->pop()->oops_do(this);
}
}
// 有哪些引用是 roots 里的呢?Universe 中的 HiTrue、HiFalse 等全局对象指针肯定属于 roots,同理,StringTable 中定义的字符串也可以看做是全局对象,它们也是 roots 集合中的。最重要根引用位于程序栈上,也就是 Interpreter 中使用的 Frame 对象,其中记录的局部变量表、全局变量表、操作数栈等,都有可能是一个普通的 HiObject 对象的引用,这些都属于 roots 集合。
void ScavengeOopClosure::process_roots() {
Universe::oops_do(this);
Interpreter::get_instance()->oops_do(this);
StringTable::get_instance()->oops_do(this);
}
};
void Interpreter::oops_do(OopClosure* f) {
f->do_oop((HiObject**)&_builtins);
f->do_oop((HiObject**)&_ret_value);
if (_frame)
_frame->oops_do(f);
}
Heap.copy_live_objects ==> OopClosure.scavenge roots 依次处理 ==> HiObject.oops_do,在不同的类型中,分别执行不同的逻辑。我们以字符串类型为例看一看。
void HiObject::oops_do(OopClosure* closure) {
// object does not know who to visit, klass knows
closure->do_oop((HiObject**)&_obj_dict);
klass()->oops_do(closure, this);
}
class HiString : public HiObject {
private:
char* _value;
int _length;
public:
...
char** value_address() { return &_value; }
};
void StringKlass::oops_do(OopClosure* closure, HiObject* obj) {
HiString* str_obj = obj->as<HiString>();
// do_raw_mem在 to 空间中分配一块内存,然后把 from 空间中的内容复制到 to 空间中。再修改引用的内容,让它指向 to 空间中的地址。
closure->do_raw_mem(str_obj->value_address(), str_obj->length());
}
其它
import
Python 的 import 语句和 Java 的大不相同,Java 的 import 只是用于编译时引入符号,而 Python 中却会执行要加载的模块。被加载的模块中用于定义类、函数、变量的语句都会被执行。执行的结果就是创建了一个新的命名空间 ModuleObject。
void Interpreter::eval_frame() {
...
while (_frame->has_more_codes()) {
unsigned char op_code = _frame->get_op_code();
...
switch (op_code) {
...
case ByteCode::IMPORT_NAME:
v = _frame->names()->get(op_arg);
w = _modules->get(v);
if (w != Universe::HiNone) {
PUSH(w);
break;
}
w = ModuleObject::import_module(v);
_modules->put(v, w);
PUSH(w);
break;
...
}
}
}
import 语句 ==> IMPORT_NAME字节码 ==> ModuleObject.import_module 通过模块的名字加载模块。加载成功以后,就把它放到 _modules 存储起来,下一次再遇到 import 同一个模块的时候,就从缓存中查找,如果缓存中已经有了,就可以直接得到,这就避免了重复加载模块。
使用 import 语句加载一个模块,使用它们命名空间中的变量时,要加上模块名字。例如 test.func1(假设test.py 定义了func1 方法),这时候,我们也可以使用 from 子句来进行化简。
import test
print(test.func1(5))
# 使用 from 子句
from test import import func1
print(func1(5))
func1 这个符号就被加载到当前的局部变量表里了。
generator
def foo():
i = 0
while i < 10:
yield i
i += 1
return
for i in foo():
print(i)
- 一个函数中如果出现了 yield 语句,那么它的函数标志 CO_GENERATOR(0x20) 就会被置位,当虚拟机在执行一个函数/CALL_FUNCTION的时候,发现函数的这个标志位被置位了,那就应该创建一个 Generator,而不是直接执行。PS:以为 foo() 返回的是一个或多个 数字,实际返回的是一个Generator,foo 成了Generator 的一部分,在Generator.__next__ 执行时被触发。类似调用async 函数 实际返回的是一个coroutine
- Generator 依然是一个普通的 Python 内建类型,所以它还是经典的 Klass-Oop 结构。GeneratorKlass 采用单例实现,里面要实现的最重要的两个虚函数是 iter 和 next,分别用来实现 GET_ITER 字节码和 FOR_ITER 字节码。
- Generator 对象的迭代器就是它自身,所以 Generator 既支持 iter 方法也支持 next 方法。每次调用 next 方法都会像处理普通函数那样创建栈帧,逐条字节码执行,直到遇到 YIELD_VALUE 指令就从 eval 函数中退出,但是栈帧却并不销毁。这意味着,当前栈帧里的状态都被保留在这个帧里了。当下一次再调用 next 方法的时候,就从上一次的那条 YIELD 语句之后继续执行。直到 next 方法产生 StopIteration 为止。
class GeneratorKlass : public Klass {
private:
static GeneratorKlass* instance;
GeneratorKlass();
public:
static GeneratorKlass* get_instance();
virtual HiObject* next(HiObject* obj); // 实现 FOR_ITER 字节码
virtual HiObject* iter(HiObject* obj); // 实现 GET_ITER 字节码
};
HiObject* GeneratorKlass::iter(HiObject* obj) { return obj;} // generator 对象的迭代器就是它自己
HiObject* GeneratorKlass::next(HiObject* obj) {
assert(obj->klass() == (Klass*) this);
Generator* g = (Generator*) obj;
return Interpreter::get_instance()->eval_generator(g);
}
class Generator : public HiObject {
friend class Interpreter;
friend class FrameObject;
friend class GeneratorKlass;
private:
FrameObject* _frame; // 当迭代结束以后,保存局部变量的值
public:
Generator(FunctionObject* func, ArrayList<HiObject*>* args, int arg_cnt);
FrameObject* frame() { return _frame; }
void set_frame(FrameObject* x) { _frame = x; }
};
// CALL_FUNCTION 指令中,如果碰到generator,函数对应的FunctionObject 成了Generator._frame 的一部分。
Generator::Generator(FunctionObject* func, ArrayList* args, int arg_cnt) {
_frame = new FrameObject(func, args, arg_cnt);
set_klass(GeneratorKlass::get_instance());
}
Generator 对象里,有一个成员变量是 FrameObject 的指针,它的作用是当迭代结束以后,还是可以保存局部变量的值。
HiObject* Interpreter::eval_generator(Generator* g) {
Handle handle(g);
enter_frame(g->frame()); // 设置好与 generator 相对应的 frame
g->frame()->set_entry_frame(true);
eval_frame(); // 执行里面 CodeObject 中的逻辑
if (_int_status != IS_YIELD) {
_int_status = IS_OK;
leave_frame();
((Generator*)handle())->set_frame(NULL);
return NULL;
}
_int_status = IS_OK;
_frame = _frame->sender();
return _ret_value;
}
对于 generator 每次进来都不用新建一个 frame 对象,而是从 generator 里去获取。执行结束以后,也不用销毁这个 frame,这样局部变量就保存在这个 frame 中了。下一次迭代的时候,也就是 next 方法被调用的时候,就可以继续使用同一个 frame。这个 frame 的特殊的地方是它有两种类型的出口,一种是执行 yield 语句,另一种是 return 或者遇到异常。这两种出口的区别是,yield 语句退出时,不会销毁 frame,另一种就像其他普通函数一样,需要销毁这个 frame。PS:执行Generator.next 使用的是 Generator自己的frame,执行结束也不销毁。
python vm
函数
一个 PyCodeObject 是对一段代码的静态表示,Python 编译器将源代码编译之后,针对里面的每一个代码块(code block)都会生成相应的 PyCodeObject 对象,该对象包含了这个代码块的一些静态信息,也就是可以从源代码中看到的信息。比如某个函数对应的代码块里面有一个 a = 1 这样的表达式,那么符号 a 和整数 1、以及它们之间的联系就是静态信息。这些信息会被静态存储起来,符号 a 被存在符号表 co_varnames 中,整数 1 被存在常量池 co_consts 中。然后 a = 1 是一条赋值语句,因此会有两条指令 LOAD_CONST 和 STORE_FAST 存在字节码指令序列 co_code 中。这些信息是在编译的时候就可以得到的,因此 PyCodeObject 对象是编译之后的结果。
当虚拟机发现了 def 语句,那么就代表发现了新的 PyCodeObject 对象,然后虚拟机会根据这个 PyCodeObject 对象创建对应的 PyFunctionObject 对象,并将变量名和 PyFunctionObject 对象(函数体)组成键值对放在当前的 local 空间中。而在 PyFunctionObject 对象中,也需要拿到相关的静态信息,因此会有一个 func_code 字段指向 PyCodeObject。除此之外,PyFunctionObject 对象还包含了一些函数在执行时所必需的动态信息,即上下文信息。比如 func_globals,就是函数在执行时关联的 global 名字空间,如果没有这个空间的话,函数就无法访问全局变量了。由于 global 作用域中的符号和值必须在运行时才能确定,所以这部分必须在运行时动态创建,无法静态存储在 PyCodeObject 中。因此要基于 PyCodeObject 对象和 global 名字空间来创建 PyFunctionObject 对象,相当于一个封装。总之一切的目的,都是为了更好地执行字节码。
typedef struct {
PyObject_HEAD
PyObject *func_globals; // 指向执行时关联的 global 名字空间;动态信息
PyObject *func_builtins;
PyObject *func_name;
PyObject *func_qualname;
PyObject *func_code; // 指向 PyCodeObject;静态信息
PyObject *func_defaults;
PyObject *func_kwdefaults;
PyObject *func_closure;
PyObject *func_doc;
PyObject *func_dict;
PyObject *func_weakreflist;
PyObject *func_module;
PyObject *func_annotations;
PyObject *func_typeparams;
vectorcallfunc vectorcall;
uint32_t func_version;
} PyFunctionObject;
def foo():
pass
函数是怎么创建的,背后经历了哪些过程?def 在语法上这是函数的声明语句,但从虚拟机的角度来看,这其实是函数对象的创建语句,即执行 MAKE_FUNCTION 指令。该指令执行完毕后,一个函数对象就被压入了运行时栈。等到 STORE_NAME 执行时,再将它从栈中弹出,然后和变量(函数名)绑定起来。PS:将一个 PyCodeObject 对象变成一个 PyFunctionObject 对象。
出现了 def,虚拟机就知道源代码进入了一个新的作用域了,也就是遇到一个新的 PyCodeObject 对象了,而通过 def 关键字知道这是一个函数,于是会进行封装,将 PyCodeObject 封装成 PyFunctionObject,同时包含了全局名字空间,所以当执行完 def 语句之后,一个函数就被创建了,然后将变量名 foo 和函数体(PyFunctionObject)组成键值对存放在当前的 local 空间中,当然对于模块而言,local 空间也是 global 空间(模块对应的 PyCodeObject)。通过函数名()进行调用的时候,会从 local 空间中取出符号 foo 对应的 PyFunctionObject 对象(函数对象)。然后根据函数对象创建栈帧对象,也就是为函数创建一个栈帧,随后将执行权交给新创建的栈帧,并在新创建的栈帧中执行字节码。PS:vm的运行会创建PyXXObject,vm的运行底座就是一群PyXXObject(包含里面的数据成员,堆栈等数据结构)
异常处理
异常是怎么实现的?虚拟机是如何将异常抛出去的?当 Python 程序中使用raise关键字引发异常时,Python 虚拟机按如下流程处理:
- 异常设置与初步处理。当执行到raise语句或程序运行过程中出现错误触发异常时,虚拟机确定异常类型并设置相关错误信息。如除法运算中除数为 0,会通过相应函数(如PyErr_SetString)设置特定类型的异常(如ZeroDivisionError)及错误信息,并返回NULL。
- 跳转到错误处理标签。由于返回NULL,根据字节码指令执行逻辑,虚拟机跳转到对应的错误处理标签(如pop_2_error等),这些标签会进行栈清理操作(弹出相应数量栈元素),之后进入error标签。
- error标签中的关键操作。在error标签内,若栈帧不是入口栈帧且是完整的,会调用PyTraceBack_Here函数。此函数先获取当前异常对象,获取其已有的 traceback(可能为空),接着以当前栈帧为参数创建新的 traceback 对象,将新对象与已有 traceback 通过tb_next关联起来,然后将新的 traceback 对象设置为当前异常的 traceback 并重新设置异常。也就是异常信息的更新和传递依赖于线程状态对象。
- 异常传播与栈帧回退。创建 traceback 对象后,虚拟机会进入exception_unwind标签(此处假设未找到捕获逻辑),进而到达exit_unwind标签。在exit_unwind标签中,将当前线程状态对象中的活动栈帧设置为上一个栈帧,完成栈帧回退动作。此时,异常沿着栈帧链向上传播,若上一个栈帧中的函数因异常返回NULL,则重复上述从error标签开始的过程,不断更新 traceback 链表,继续寻找异常捕获逻辑。
- 异常表(Exception table 由 PyCodeObject 对象的 co_exceptiontable 字段负责维护)记录的代码块范围和异常类型信息,指导虚拟机决定是在当前栈帧继续查找其他try-except结构,还是沿着栈帧链向上继续传播异常,直到找到合适的异常处理代码块或者到达最顶层栈帧
- 最终处理(未捕获异常)。如果异常一直传播到最顶层(如模块对应的栈帧)都未被捕获,虚拟机从线程状态对象中取出维护的 traceback 链表,遍历并输出其中信息到stderr中,展示详细异常信息(包含函数调用栈追溯、异常类型和错误信息等),然后解释器结束运行。
参考

留下评论