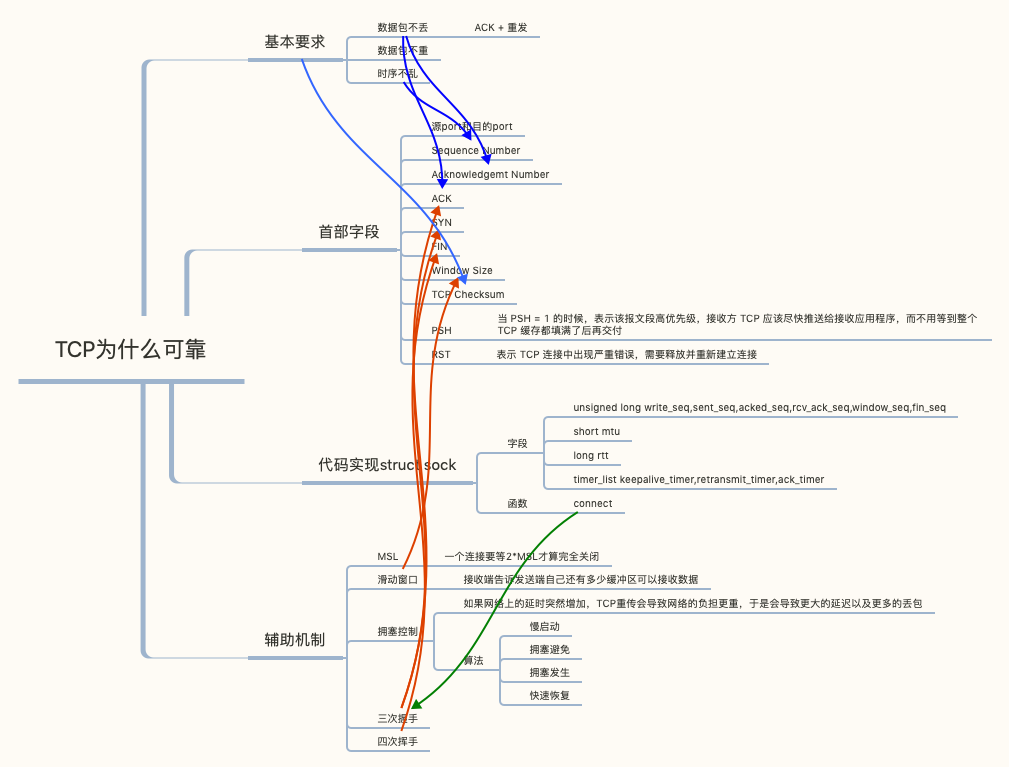
再看tcp
前言
1978 年在 TCP 协议迭代了 3 个版本后,才被 Jon Postel(IANA 创始人)提出违反了网络分层原则,网络层和传输层耦合在一起很难扩展。于是在 TCP 的第 4 个迭代版本中把协议一分为二,包括网络层 IP 协议和传输层 TCP 协议(这也是今天的 IP 协议被称为 IPv4 的原因,IP层专注于解决跨网络传输消息,TCP 解决任意长度消息的可靠传输)。TCP/IP协议族按照层次由上到下,层层包装。发送协议的主机从上自下将数据按照协议封装,而接收数据的主机则按照协议从得到的数据包解开,最后拿到需要的数据。这种结构非常有栈的味道,所以某些文章也把tcp/ip协议族称为tcp/ip协议栈。
TCP/IP不是一个协议,而是一个协议族的统称,里面包括了IP协议、IMCP协议、TCP协议以及我们更加熟悉的http、ftp、pop3协议等等。
程序员如何把控自己的职业把知识结构化。从一个技术关键点开始不断地关联和细化下去,比如:关于TCP协议,首先第一个要记住状态图,怎么建立连接,怎么断连接,状态怎么变迁。TCP没有连接,是靠状态维护连接的(http是无状态的,所以每一次通信 header 都要带上所有信息)。其次,要了解TCP怎么保证可靠性,就是丢包以后怎么重传,重传有哪些技术点。然后,重传会让你联想到拥塞控制,拥塞控制到滑动窗口……。这基本就是TCP的所有东西了,找到关键点,然后顺着这个脉络一点点往下想,通过知识图关联就可以进行顺藤摸瓜。赫拉克利特说: 人不能两次踏入同一条河流。网络连接也是如此,TCP看似保持连接,底层的物理路径、网络拓扑、中间节点状态都在不断变化。长连接不是“保持”连接,而是在不断变化的网络中持续重新建立连接。
从抓包看tcp
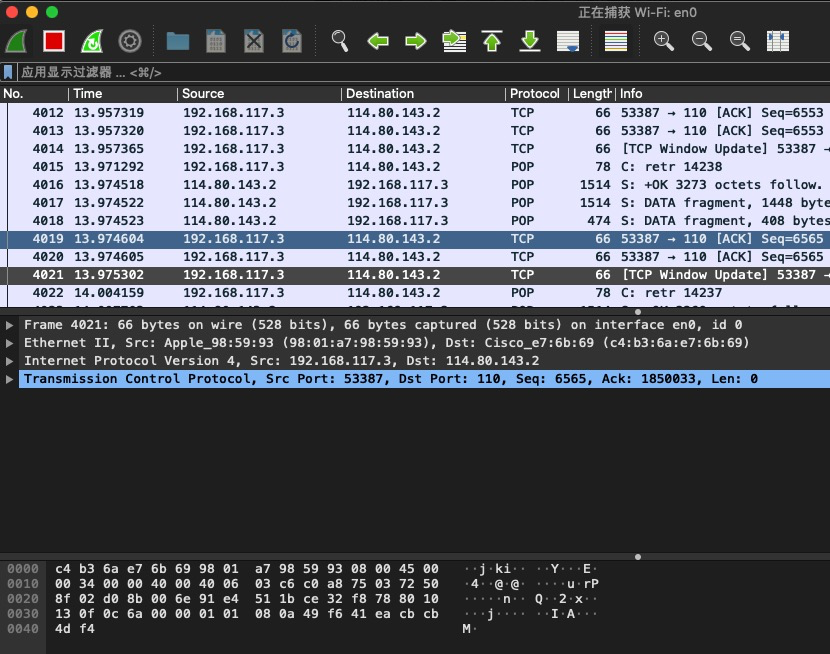
使用wireshark 抓包工具,从上到下是
- 抓到的数据包/报文列表
- 中间是 每个数据包的多层数据,从最外到最内是Frame ==> Ethernet II(可能是apple 的一个特殊协议) ==> Internet Protocol Version 4 ipv4 协议 ==> Transmission Control Protocol tcp 传输控制层协议 ==> 应用层协议(比如http)。
- 最底部是 数据包的 二进制数据,点击 中间每一个层 后每一层内的字段,底部会高亮对应的 数据。
一个协议由:字段 + 基于字段之上的策略 组成
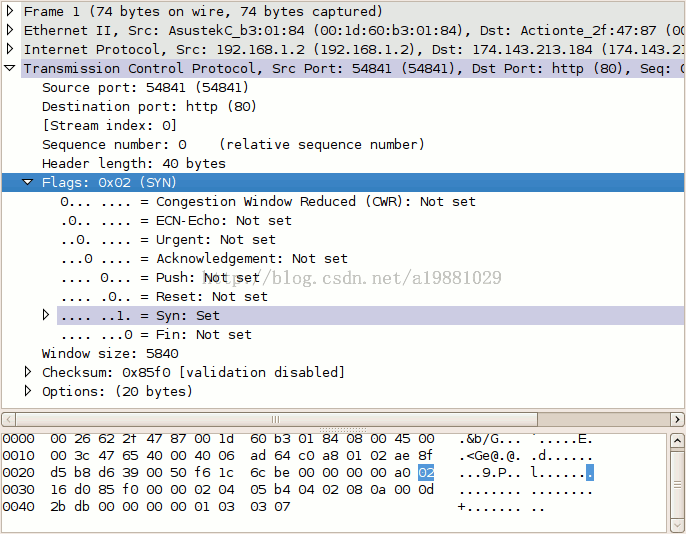
比如图中的“window size”,是不是看起来很耳熟。
TCP 报文可以分为两类:控制报文和普通数据报文。控制报文用于管理 TCP 连接的建立、维护和关闭,以及流量控制和错误处理。常见类型:SYN、ACK、FIN、RST、PSH、URG。TCP 报文的结构包括一个固定长度的头部(20-60 字节)和可选的数据部分。控制报文至少有一个控制标志(如 SYN、ACK、FIN、RST 等)被设置为 1,通常不携带应用层数据,或者数据部分非常少。普通数据报文通常只有 ACK 标志位被设置为 1(表示确认),其他控制标志位为 0。
如何定位到应用层的请求和返回的报文?我们只要选中请求报文,Wireshark 就会自动帮我们匹配到对应的响应报文,反过来也一样。从图上看,应用层请求(这里是 HTTP 请求)是一个向右的箭头,表示数据是进来的方向;应用层响应是一个向左的箭头,表示数据是出去的方向。此外,Wireshark 自己分析得到的信息,都会用方括号括起来。
在一些技术文档,特别是 Wireshark 相关的文档中,“TCP 流”是一个很常见的词汇。这里的 TCP 流,就是英文的 TCP Stream。TCP Stream 是指在 TCP 连接中两个端点(通常是客户端和服务器)之间交换的所有数据包的完整序列。Wireshark 提供了“Follow TCP Stream”功能,可以将这些数据包重新组装成一个连续的数据流,以便更清晰地查看数据交换的完整过程。Stream 这个词有“流”的意思,也有“连续的事件”这样一个含义,所以它是有前后、有顺序的,这也正对应了 TCP 的特性。跟 Stream 相对的一个词是 Datagram,它是指没有前后关系的数据单元,比如 UDP 和 IP 都属于 Datagram。在 Linux 网络编程里面,TCP 对应的 socket 类型是 SOCK_STREAM,而 UDP 对应的,就是 SOCK_DGRAM 了。显然,DGRAM 就是 Datagram 的简写。
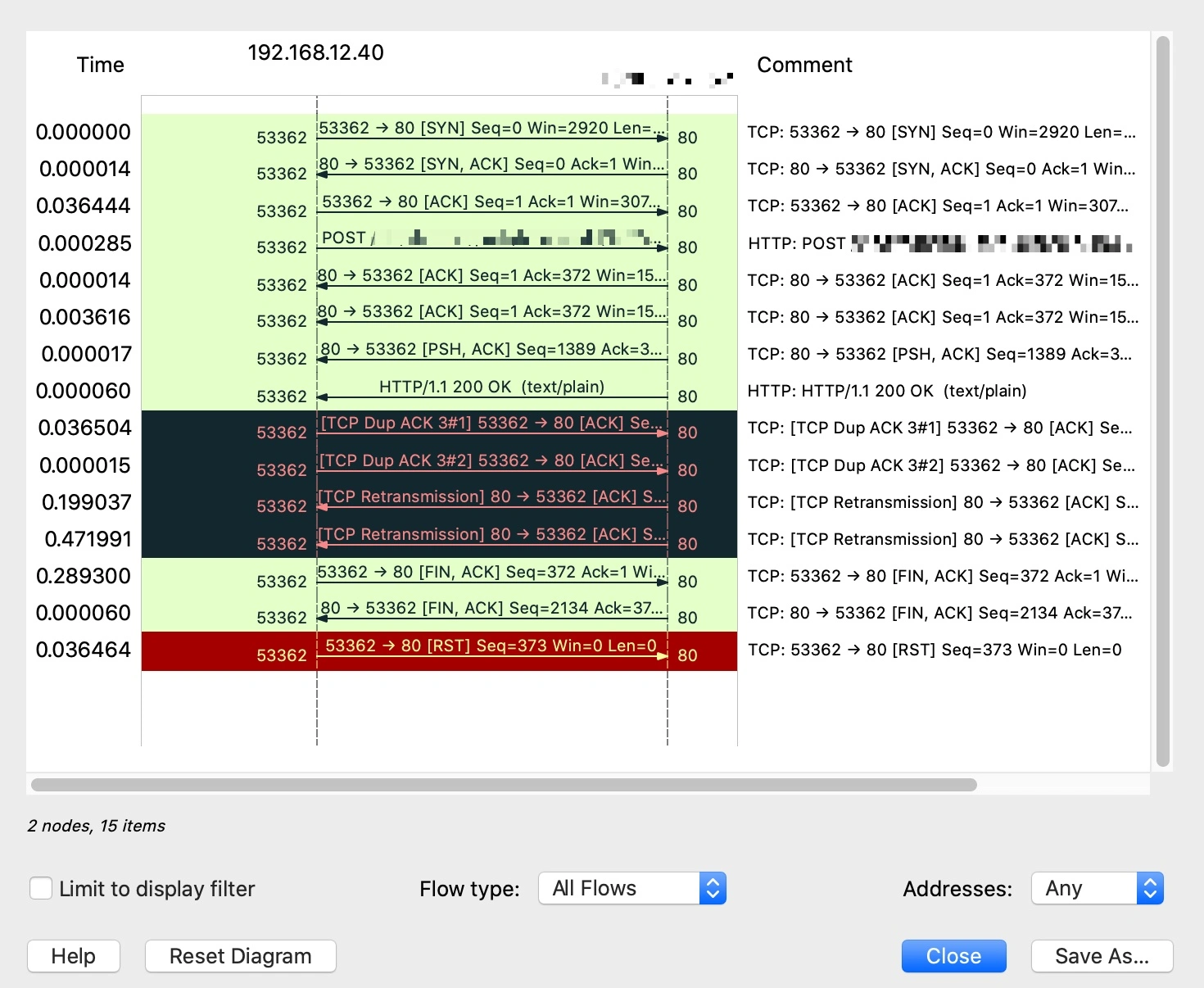
Wireshark 主窗口里展示的报文,确实有点类似“一维”,也就是从上到下依次排列,在解读通信双方的具体行为时,如果能添加上另外一个“维度”,比如增加向左和向右的箭头,是不是可以让我们更容易理解呢?Wireshark 里确实有一个小工具可以起到这个作用,它就是 Flow Graph。
tcp协议字段组成
就像一致性协议一样,可以尝试从容错角度看待 tcp的各项机制。
一说到TCP和UDP,就是
- TCP 是面向连接的(一对一的;四元组)
- UDP 是面向无连接的,UDP只是简单的在IP层协议上加了个传输层的端口封装,不用关心对端是否在线。每一个数据段的发送都是独立的一个数据个体,数据和数据之间没有关系,无需维护其之间的关系。典型的例子就是发短信。
- 需要维护seq序列号字段维护数据的顺序关系保证按序交付,和解决数据包重复的问题。
- 需要部分特殊的状态标记的包来专门创建、断开和维护一个连接:syn,ack,fin,rst
- TCP 提供可靠交付,无差错、不丢失、不重复、并且按序到达;UDP 不提供可靠交付,不保证不丢失,不保证按顺序到达。
- 引入数据传输的确认机制,即数据发送之后等待对方确认。于是需要维护确认字段Acknowledgement和ack状态。即:停止等待协议。
- 引入数据确认机制(停止等待协议)之后,引发了带宽利用律不高的问题,如何解决?解决方案是引入窗口确认机制和滑动窗口,即不在以每个包发送之后进行确认,而是发送多个包之后一起确认。
- 引入窗口之后,如何在不同延时的网络上选择不同窗口大小?解决方法是引入窗口变量(发送方和接收方 维护窗口的左右边界,不同含义),和窗口监测通告:
- 引入滑动窗口之后,带宽可以充分被利用了,但是网络环境是复杂的,随时可能因为大量的数据传输导致网络上的拥塞。于是要引入拥塞控制机制:当出现拥塞的时候,tcp应该能保证带宽是被每条tcp连接公平分享的。所以在拥塞的情况下,要能将占用带宽较大的连接调整为占用带宽变小,占用小的调大。以达到公平占用资源的目的。拥塞控制对带宽占用的调整本质上就是调整滑动窗口的大小来实现的,所以需要在接受端引入一个新的变量叫做cwnd:拥塞窗口,来反应当前网络的传输能力,而之前的通告窗口可以表示为awnd。此时发送端实际可用的窗口为cwnd和awnd的较小者。深入理解Linux的TCP三次握手
- TCP 是面向字节流的,发送时发的是一个流,缺点是没头没尾,不维护应用报文的边界(要求上层协议比如HTTP/GRPC 自己维护报文的边界);优点是不强制应用必须离散的创建数据块,不限制数据块大小。UDP是面向数据报的,一个一个的发送。
- TCP 是可以提供流量控制和拥塞控制的,解决速度不匹配的问题,既防止对端被压垮,也防止网络被压垮。http2 将frame 分为控制frame和数据frame,tcp 没有区分,所以tcp 协议控制字段和通信字段混在一起。
这些特性=算法+数据结构,算法由端上的代码体现,数据结构由协议格式体现。
tcp连接建立与关闭
一般来说 TCP 连接是标准的 TCP 三次握手完成的:
- 客户端发送 SYN;
- 服务端收到 SYN 后,回复 SYN+ACK;
- 客户端收到 SYN+ACK 后,回复 ACK。 这里面 SYN 会在两端各发送一次,表示“我准备好了,可以开始连接了”。ACK 也是两端各发送了一次,表示“我知道你准备好了,我们开始通信吧”。服务端的 SYN 和 ACK 是合并在一起发送的,就节省了一次发送。这个在英文里叫 Piggybacking,就是背着走,搭顺风车的意思。
TCP会话的每一端都包含一个32位(bit)的序列号,该序列号被用来跟踪该端发送的数据量。每一个包中都包含确认号,接收端通过确认号用来通知发送端数据成功接收,TCP 序列号、Payload(载荷)、TCP 确认号一般情况下就是一个 A+B=C 的关系。从序列号和确认号的角度看,三次握手是这样的(握手握的就是ISN号):
- 客户端向服务器发送一个同步数据包SYN请求建立连接,该数据包中,初始序列号(ISN)是客户端随机产生的一个值。
- 服务器收到这个SYN后,会向客户端发送一个同步确认ACK(确认号是客户端的初始序列号+1 ),并发送SYN 携带服务端自己的ISN
- 客户端收到SYN后,再对服务器进行一个ACK。该数据包中,序列号是上一个同步请求数据包中的确认号值,确认号是服务器的ISN+1。
假设初始序列号是0(不管是客户端请求,还是服务端响应),那么序列号为当前端成功发送的数据位数,确认号为当前端成功接收的数据位数。握手过程中,尽管没有传输有效数据,确认号还是被加1,这是因为接收的包中包含SYN或FIN标志位(占1bit)。由此,我们就可以知道为什么一些linux命令可以统计流量,为什么说tcp是可靠地?序列号、确认号、checksum即可以保证交互双方正确传输了n字节的数据。序列号来保证所有传输的数据可以按照正常的顺序进行重组,从而保障数据传输的完整。 初始序列号(ISN)随时间而变化的,而且不同的操作系统也会有不同的实现方式,所以每个连接的初始序列号是不同的。TCP连接两端会在建立连接时,交互一些信息,如窗口大小、MSS等,以便为接着的数据传输做准备。
TCP的“假”连接/状态机
从本质上来讲,所谓的建立连接,其实是为了在客户端和服务端维护连接,而建立一定的数据结构来维护双方交互的状态,并用这样的数据结构来保证面向连接的特性。TCP 无法左右中间的任何通路,也没有什么虚拟的连接,中间的通路根本意识不到两端使用了 TCP 还是 UDP。
TCP使用了三种基础机制来实现面向连接的服务:
- 消息顺序编号:使用序列号进行标记,以便TCP接收服务在向目的应用传递数据之前修正错序的报文排序;
- 客户端重发
- 服务端顺序ACK。服务端虽然接收数据包是并发的(数据包到达的顺序性无法保证),但数据包的ack是按照编号从小到大逐一确认的。比如服务端已收到了数据包123,又收到了567,服务端会回复ack=3,并把123发给上层进程处理。567 暂存在tcp receive buffer中,直到客户端重发4567后收到了4,才回复ack=7。
- 这样只需一个变量,便表达了哪些数据包收到哪些未收到。顺序确认在一致性协议Raft中也有应用。
- 这导致了经典的tcp层队头阻塞问题,丢失的数据包4 队头阻塞(HOL blocking)数据包567!比如上层是http2,可能不需要等数据包4,浏览器可以直接处理567。
系统调用 与TCP 标志位的状态转换关系
![]()
- 对于建立连接来说,都是由客户端发起,所以client 是主动方,server 是被动方。 对于关闭连接来说, client 和 server 都可以发起(通常由客户端发起)
- 起初,client 和server 都处于closed状态,连接建立好后,双方都处于established状态,开始传输数据。最后连接关闭, 双方再次回到closed状态。closed/established/time_wait 因为持续时间较久,通过netstat 命令比较容易看到。
为什么一定要进行三次握手呢?
tcp握手的目标:确认对端在线,同步初始sequence序列号;交换tcp 通讯参数(比如MSS、窗口比例因子、指定校验和算法等)。两次握手至少让一端无法确定对端是否了解了你的起始序列号。
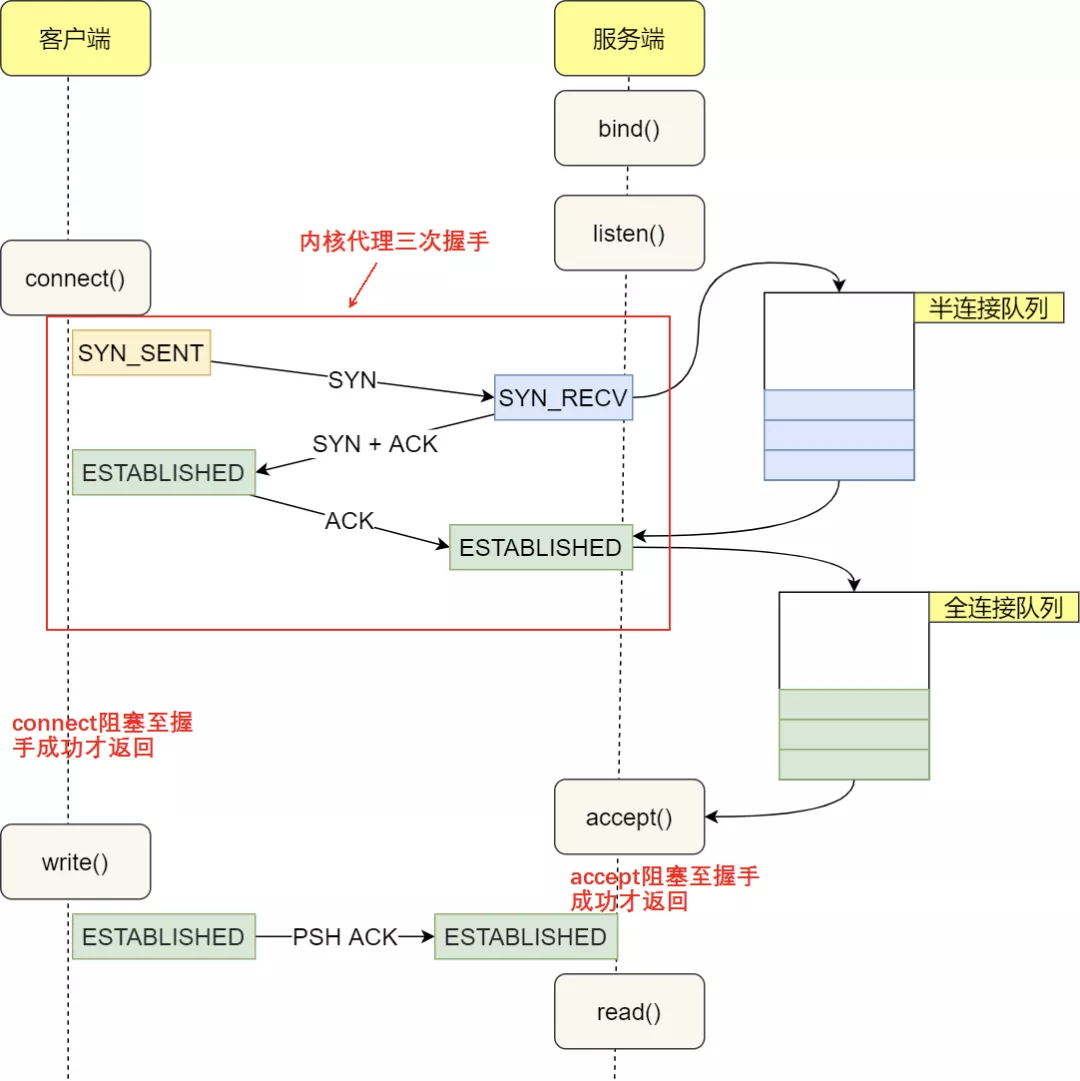
三次握手和函数调用结合起来理解:
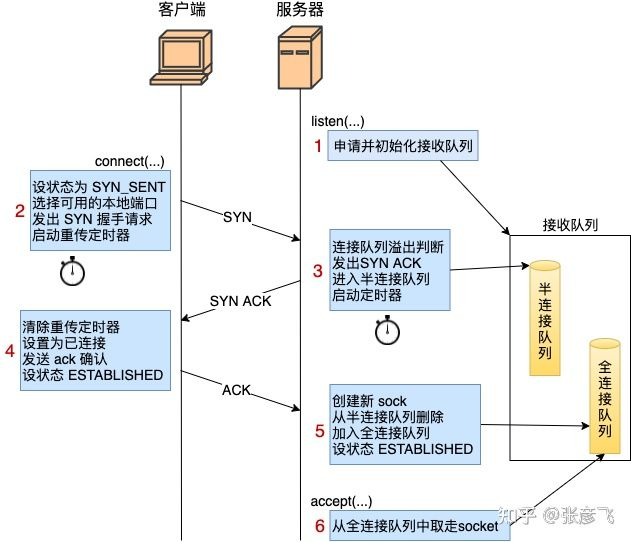
- 客户端调用connect 的时候,把本地socket状态设置成了TCP_SYN_SENT,选了一个可用端口,接着发出SYN握手请求并启动重传定时器。它会把这个SYN包放入重发队列中,如果收到了关于这个包的确认信息,便将此数据包从队列中删除,如果在计时器超时的时候仍然没有收到确认信息,则需要重新发送该数据包。Linux下,默认重试次数为5次,重试的间隔时间从1s开始每次都翻售,5次的重试时间间隔为1s, 2s, 4s, 8s, 16s。客户端和服务端有多种类型的报文段,对于特定报文段,超时重发机制会带来意想不到的后果。
- 服务端响应 syn 请求的主要工作是 判断接收队列是否满了,满的话可能直接丢弃该请求,否则发出syn+ack,申请request_sock 添加到半连接队列中,同时启动定时器。
- 客户端收到服务端的syn+ack 时清除connect 时设置的重传定时器,把当前socket 状态设置为established,开启保活计时器后发出第三次握手的ack 确认。
- 服务端响应第三次握手ack 所做的工作是:判断全连接队列是否满了,如果满了修改一下计数器就丢弃了。如果队列不满,把当前半连接对象删除,创建了新sock 后加入全连接队列(所以加入之前要判断是否满),最后将新连接状态设置为 established。
- 服务端accept 的工作:从已经建立好的全连接队列中取出 一个返回给用户进程。
《软件架构设计》:无论两次、三次、四次,永远都不知道最后发出去的数据包对方是否收到了,问题无解。那为什么是三次呢?因为三次握手恰好可以保证client 和server 对自己的发送、接收能力做了一次确认
- client 发送seq=x,收到了回复的seq=y,ack=x+1 则客户端知道自己的发送、接收没问题
- 服务端发送 seq=y,收到了第三次的ack = y+1,可以确认自己的发送、接收也没问题
三次握手的过程即是通信双方相互告知序列号起始值,并确认对方已经收到了序列号起始值的必经步骤(服务端SYN伴随ACK 一起发了);如果只是两次握手,至多只有连接发起方的起始序列号能被确认,另一方选择的序列号则得不到确认。
服务端连接队列满主动丢包
- 第一次握手丢包(服务端因半/全连接队列满,丢弃来自客户端的syn包),从客户端视角看跟网络断了没有区别,就是发出去的syn包没有任何反馈,触发客户端重试(继续发syn,会重试net.ipv4.tcp_syn_retries次,间隔时间逐步翻倍,即指数退避),连接耗时增加。
- 第三次握手丢包(服务端因全连接队列满,丢弃来自客户端的ack包),服务端等到半连接定时器到时后,向客户端重启发起synack,客户端收到后再重新回复第三次握手ack。如果这期间服务端全连接队列一直是满的,那么服务端重试5次就放弃了。所以 尽快在握手成功后通过accept 把新连接取走,不要忙于处理业务逻辑而导致全连接队列满了。
网络“失而复得”
前两次的握手很显然是必须的,主要是最后一次,即客户端收到服务端发来的确认后为什么还要向服务端再发送一次确认呢?这主要是为了防止已失效的请求报文段突然又传送到了服务端而产生连接的误判。考虑如下的情况:客户端发送了一个连接请求报文段/SYN到服务端,但是在某些网络节点上长时间滞留了(可以滞留一个MSL=1分钟),而后客户端又超时重发了一个连接请求报文段该服务端(connect超时配置一般不超过10s),而后正常建立连接,数据传输完毕,并释放了连接。如果这时候第一次发送的请求报文段延迟了一段时间后,又到了服务端,很显然,这本是一个早已失效的报文段。
| 处理失效SYN | 三次握手 | 两次握手 |
|---|---|---|
| 失效SYN到达服务端 | 服务端返回ACK | 服务端返回ACK,连接建立 |
| 服务端ACK到达客户端 | 客户端不理会 | 客户端不理会 |
| 服务端 | 超过时间未收到ACK认为连接未建立 | 等待客户端发送数据,直到超出保活计数器的设定值 而将客户端判定为出了问题,才会关闭这个连接 |
上述偏表象,更实质的原因是:
- TCP 需要 seq 序列号来做可靠重传或接收,而避免连接复用时无法分辨出 seq 是延迟或者是旧链接的 seq,因此需要三次握手来约定确定双方的 ISN(初始 seq 序列号)。
- TCP 协议是不限制一个特定的连接(两端 socket 一样)被重复使用的。所以这样就有一个问题:这条连接突然断开重连后,TCP 怎么样识别之前旧连接重发的包?——这就需要独一无二的 ISN(初始序列号)机制。当一个新连接建立时,初始序列号( initial sequence number ISN)生成器会生成一个新的32位的 ISN。这个生成器会用一个32位长的时钟,差不多4µs 增长一次,因此 ISN 会在大约 4.55 小时循环一次。而一个段在网络中并不会比最大分段寿命(Maximum Segment Lifetime (MSL) ,默认使用2分钟)长,MSL 比4.55小时要短,所以我们可以认为 ISN 会是唯一的。发送方与接收方都会有自己的 ISN 来做双方互发通信。
- 三次握手(A three way handshake)是必须的, 因为 sequence numbers(序列号)没有绑定到整个网络的全局时钟(全部统一使用一个时钟,就可以确定这个包是不是延迟到的)以及 TCPs 可能有不同的机制来选择 ISN(初始序列号)。接收方接收到第一个 SYN 时,没有办法知道这个 SYN 是否延迟了很久了,除非他有办法记住在这条连接中,最后接收到的那个sequence numbers(然而这不总是可行的)。所以,接收方一定需要跟发送方确认 SYN。PS:防止虚假连接有很多办法,三次握手也可以说是防止服务端资源泄漏(总不能客户端SYN一下,服务端就创建一个socket放到全连接队列),可以认为针对某个具体的问题都有解决办法,综合起来三次握手比较好,就用了三次握手这个方法。
四次分手
TCP 的连接断开,无非跟两种报文有关:FIN 和 RST。
关闭连接的操作其实是告诉通信的另一方自己没有需要发送的数据(TCP 的挥手是任意一端都可以主动发起的,由close 系统调用触发),但是它仍然保持了接收对方数据的能力(半关闭)。 所以拉手3次即可(服务端SYN伴随ACK 一起发了),分手需要4次(服务端ACK 与FIN分开发送)。
为什么 TCP 协议有 TIME_WAIT 状态TIME_WAIT 状态是 TCP 与不确定的网络延迟斗争的结果,而不确定性是 TCP 协议在保证可靠这条路的最大阻碍。
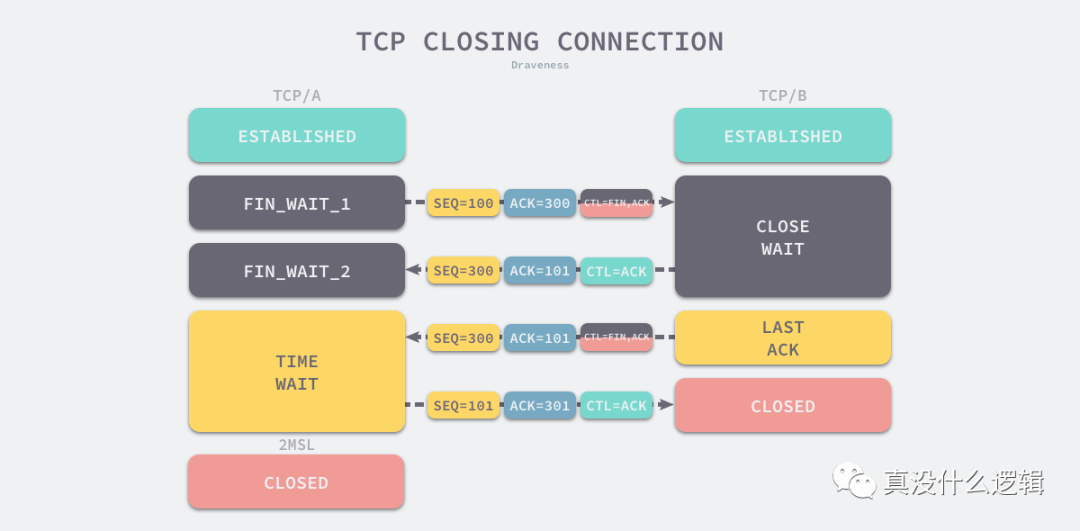
PS:如果是服务端发起的关闭连接,服务端有可能会把应用层的应答数据,跟操作系统对 TCP 连接关闭的控制报文(这个 FIN),合并在同一个报文里面,也就是Piggybacking/搭顺风车。
MSL及 配合措施
- 进入 TIME_WAIT 的客户端(主动关闭方)需要等待 2 MSL 才可以真正关闭连接。PS: 半关闭 ==> 关闭。
- 任何一个IP数据包在网络上逗留的最长时间是MSL,默认120s(Linux 60s),超过这个时间,中间的路由节点会将数据包丢弃。
关闭时为什么要TIME_WAIT 2MSL?换个表述,主动方为什么要等待2MSL 不能直接进入 CLOSED 状态?TIME_WAIT 仅在主动断开连接的一方出现(另一方是CLOSE_WAIT),被动断开连接的一方发完FIN后会直接进入 CLOSED 状态。PS:连接是由状态体现的,是两个人的事儿,特定的数据包和计时器都可以更改通信两端的状态。
- 等待足够长的时间以确定被动关闭连接的一方收到 FIN 对应的 ACK 消息。以客户端主动关闭为例,只要客户端等待 2 MSL 的时间,有两种可能
- 服务端正常收到了 ACK 消息并关闭当前 TCP 连接;
- 服务端自发送FIN后等了2ML没有收到 ACK 消息,会重新发送 FIN 关闭连接并等待新的 ACK 消息,客户端自发送ACK 2MSL 内会收到 服务端重发的FIN,继而回复服务端ACK。==> 客户端2MSL 内又收到了FIN 即表示自己发送的ACK 未送达,没收到即表示ACK送达了
- 如果客户端等待的时间不够长,当服务端还没有收到 ACK 消息时,客户端就重新与服务端建立 TCP 连接就会造成以下问题 — 服务端因为没有收到 ACK 消息,所以仍然认为当前连接是合法的,客户端重新发送 SYN 消息请求握手时会收到服务端的 RST 消息,连接建立的过程就会被终止。假如不回复RST 拒绝 连接,可能连接关闭之后客户端再重开一个新的连接,新老连接的四元组
<源地址,源端口,目的地址,目的端口>是一样的。老连接关闭后,仍可能有数据包在网络上“闲逛”,但是序列号是老的,这个过期的消息却可能被服务端正常接收,这就会带来比较严重的问题。
等待2*MSL造成一个问题:在2MSL时间内,该地址上的连接(客户端地址,端口和服务器的端口地址)不能被使用。在 Linux 上,客户端的可以使用端口号 32,768 ~ 61,000,总共 28,232 个端口号与远程服务器建立连接,但是如果主机在MSL时间内创建的 TCP 连接数超过 28,232,那么再创建新的 TCP 连接就会发生错误。这也是为什么client要建连接池的原因之一。
左耳朵耗子:有些时候网络连接会闪断。从 a 节点到 b 节点,中间经过了很多设备,你怎么排查故障?如果你懂原理,那就会容易些。第一,你先看看 TCP 的状态,如果是 time wait 的话,那就是我主动断开连接;如果是 close wait 的话,那就是对方主动断开连接。你看状态就能有一个基本的判断。 如果没有看到连接建立的话,你需要使用抓包的方式,像什么 tcpdump、wireshark 之类,用这些工具,就能很快定位问题。懂基础和不懂基础的人,他们的思考完全是在两个层面。不懂基础知识的人,他就在那瞎搞,这里试一下,那里试一下。运气好,碰巧解决了,但也不知道怎么回事。而懂基础的人,他可以很快理解大概是怎么回事。
连接保活
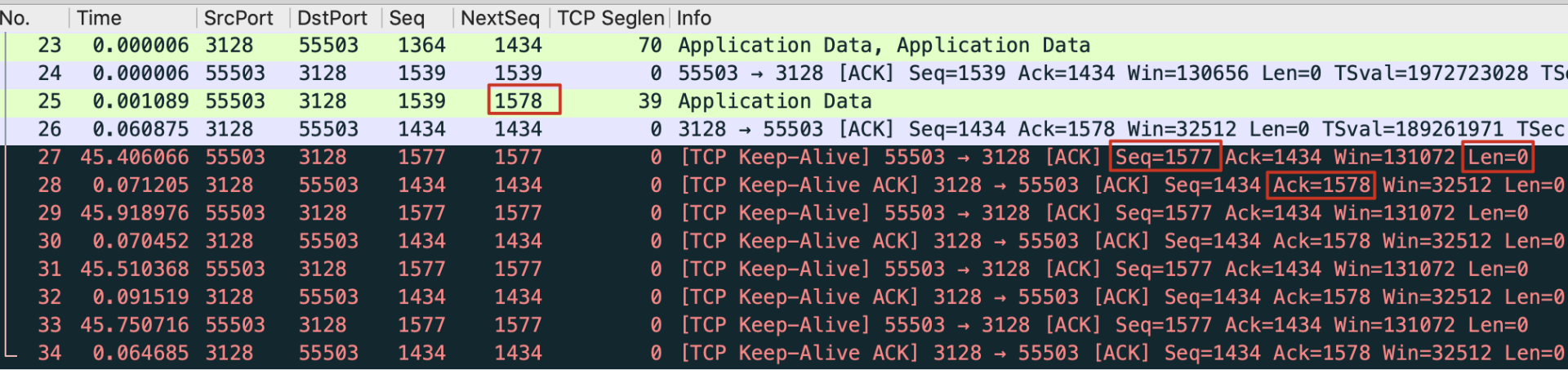
在一个空闲的 TCP 连接中并不会发送任何数据。前文在完成三次握手的连接后,多次添加了 iptables 规则去拦截数据包,这并不影响已经建立的连接。因为 TCP 的“连接”本身就是双方建立的一个逻辑上的通信状态机而已。甚至连接建立好后不发送数据,让中间的网络设备重启后再发送也不影响连接的有效性(特定情况下,假定没有使用 NAT 机制等)。特别地,默认情况下通信一方直接宕机或者拔掉网线,另一端一直没有数据交换的话会一直处于“连接”状态到永远。TCP 的保活机制(Keep-alive)就是为了解决上述机制设计的,但这并不是标准 TCP 规范的一部分(大部分的实现都支持,比如 Linux 内核)。这是一个争议很多的特性,TCP 层的保活很多时候无法取代应用层自己的保活设计,所以很多时候并不会有意识的在应用代码里开启这个选项。
默认 TCP 连接并不启用 Keep-alive,打开这个 TCP Keep-alive 特性,你需要使用 setsockopt() 系统调用,对已经创建的 Socket 进行配置,启用 Keep-alive。在 Linux 操作系统层级,有三个跟 Keep-alive 有关的全局配置项。
- 间隔时间:net.ipv4.tcp_keepalive_time,其值默认为 7200(秒),也就是 2 个小时。
- 最大探测次数:net.ipv4.tcp_keepalive_probes,在探测无响应的情况下,可以发送的最多连续探测次数,其默认值为 9(次)。
- 最长间隔:net.ipv4.tcp_keepalive_intvl,在探测无响应的情况下,连续探测之间的最长间隔,其值默认为 75(秒)。 如果我们连接启用了 Keep-alive,但没有设定自定义的数值,那么就会使用上面这些默认值,即:当连接闲置(没有数据交互)达到 7200 秒(2 小时)时发送心跳包,每次心跳包超时时间为 75 秒,最多重试 9 次。这样的话,对于一个已经失效的 TCP 连接,最大需要 7200+75*9=7875 秒(约等于 2 小时 11 分钟)才能探测到。毫无疑问,这个时间是相当长的。不过结合时代背景,这个其实也可以理解:TCP Keep-alive 被设计的时候是八十年代,当时因特网还很初级,所以设计者们并不想让心跳包占据太多的网络资源。从而,就有了这么一个感知时间很长的心跳机制。
backlog
tcp 连接机制 的缺陷 常见Dos攻击原理及防护(死亡之Ping、Smurf、Teardown、LandAttack、SYN Flood) 故意让服务端 维持一堆半连接,直到超过 backlog
再聊 TCP backlogbacklog 参数跟 listen 函数有关,listen 函数的定义如下:int listen(int sockfd, int backlog); 。listen 最主要的工作就是申请和初始化接收队列,包括全连接队列和半连接队列。其中全连接队列是一个链表,而半连接队列由于需要快速的查找,所以使用的是一个哈希表。全/半两个队列是三次握手中很重要的两个数据结构,有了它们服务器才能正常响应来自客户端的三次握手。所以服务器端都需要 listen 一下才行。为什么服务端程序都需要先 listen 一下?
To understand the backlog argument, we must realize that for a given listening socket, the kernel maintains two queues :
- An incomplete connection queue, which contains an entry for each SYN that has arrived from a client for which the server is awaiting completion of the TCP three-way handshake. These sockets are in the SYN_RCVD state .
- A completed connection queue, which contains an entry for each client with whom the TCP three-way handshake has completed. These sockets are in the ESTABLISHED state. 「全连接队列」包含了服务端所有完成了三次握手,但是还未被应用调用 accept 取走的连接队列。此时的 socket 处于 ESTABLISHED 状态。每次应用调用 accept() 函数会移除队列头的连接。如果队列为空,accept() 通常会阻塞。全连接队列也被称为 Accept 队列。
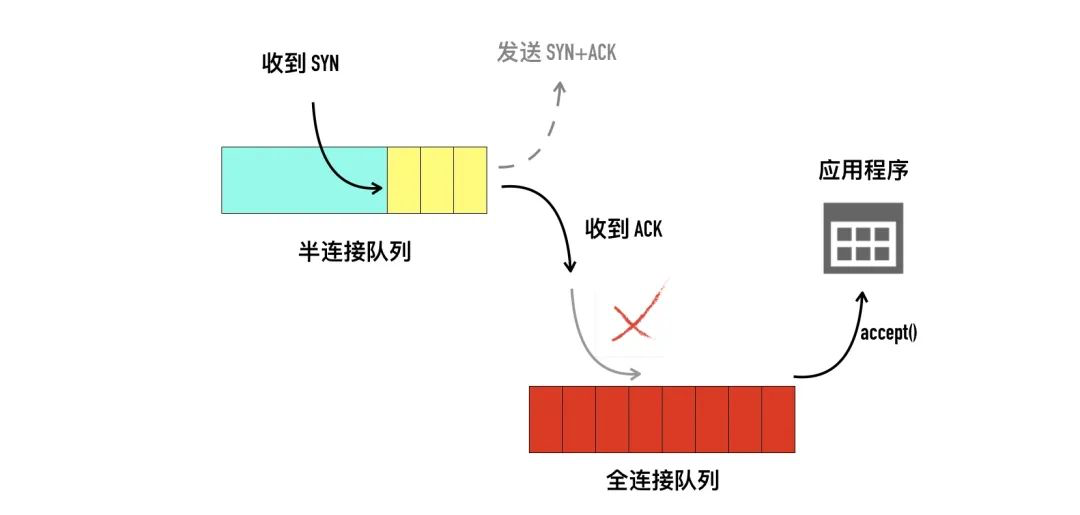
你可以把这个过程想象生产者、消费者模型。内核是一个负责三次握手的生产者,握手完的连接会放入一个队列。我们的应用程序是一个消费者,取走队列中的连接进行下一步的处理。这种生产者消费者的模式,在生产过快、消费过慢的情况下就会出现队列积压。
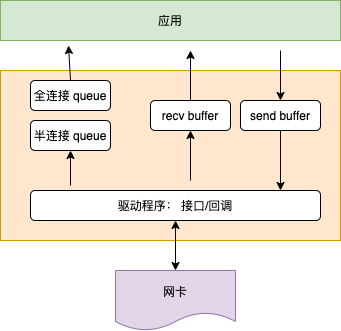
如果某服务挂了,那么内核会帮忙收尾,根据情况或走 RST 或走 FIN,访问者就知道连接关了。但如果主机挂了,或者中间网络设备挂了,客户端没有超时配置,就只能 tcp keepalive 来判断死链接,按照默认内核配置语言两个多小时。
(建连后数据传输)为什么可靠
通过实验深入了解 TCP 数据的发送和接收 经典。 协议就是一系列约定,屏蔽底层各种错乱,得到一个完整有序的数据包序列:
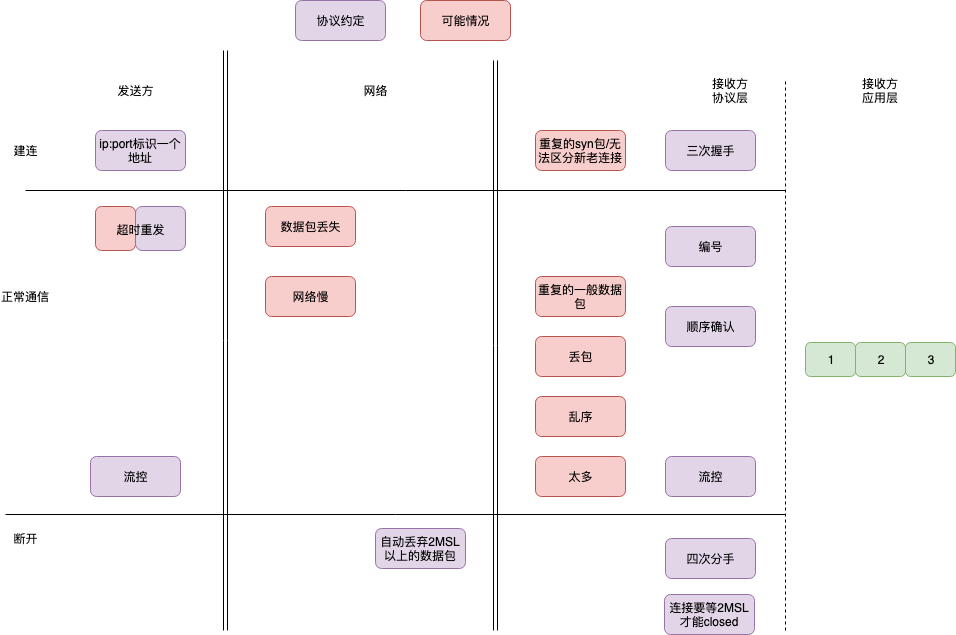
如何看待谷歌 Google 打算用 QUIC 协议替代 TCP/UDP?
超时重传:序列号和确认号
TCP 最核心的价值,如果说只有一个的话,那就是对可靠传输的保证。而要实现可靠的传输,可能需要这样做:如果我的报文丢了,应该在一定次数内持续尝试,直到传输完成;而如果这些重传都失败了,那就及时放弃传输,避免陷入死循环。PS:超时重传和快速重传
TCP 是基于自动重复请求的机制(Automnatic Repeat Request, ARQ)来设计的。简单说就是对待发送的数据(Payload)进行字节级别的编号(Sequence Number)(序列号和确认号针对的是字节而不是报文)。在 TCP 完成三次握手建立了连接后(在不携带数据的包里,握手的 SYN 包和挥手的 FIN 也要占用编号),发送的数据均带有相应的位置序号。接收端可以根据序号对数据进行重排序来解决传输过载中存在的乱序送达的情况,并回复 ACK 包给发送端以告知数据送达(不需要请求回复一对一,只需要 ACK 最大的位置即可)。基于这个朴素的数据编号的想法,TCP 完成了发送和接收数据的基本逻辑。
tcp的传输过程是可靠的,那为什么许多较大的下载最终还要校验文件完整性?
- 如果 TCP 包出现了丢失,发送端如何知晓?自然是接收端回复的 ACK 序号小于已发送的序号。那么这就要求发送端在发送数据之后启动一个定时器(对于每条连接都维护了一个超时计时器),在指定的时间未收到接收端的 ACK 时就要主动的重传尚未被确认的数据。那么这个超时时间设置多大合适?这里需要引入 RTT 和 RTO 的概念:RTT(Round Trip Time) 指一个数据包从发出去到回来的时间,RTO(Retransmission TimeOut) 指的是重传超时的时间。很显然,只有比较精确地评估出来对端接收到数据包并 ACK 回包的时间,才能准确地评估 RTO 的初始值。RTO 评估的过大会导致通信效率降低,RTO 评估的过小会导致没有必要的重发加剧拥塞。PS:有兴趣可以去研究下算法。
- TCP 的可靠传输就是保证在传送丢失或者是包校验和出错的时候重传,但 crc 校验只能大概判断一下,并不能保证数据 100% 正确。
- 传输层协议只保证传输过程的校验。假如发送方进程在部分数据还没有发送的时候,进程崩溃了,或者断点续传的时候断点计算漏了。这时候数据还没有进入到传输层,整体上也就无法保证了。
- 传输过程中我们的包要经过很多复杂的环境,在 HTTP 时代,中间的某个环节的运营商出于利益驱使完全是有能力修改传输的数据的(运营商劫持),当然现在 HTTPS 的广泛应用使得这种情况已经好多了。
- tcp 接收方传输层的 ack 确认其实只是确认的接收方的内核正确地收到了。这时候用户进程有没有收到其实不一定。假如用户进程还没来得及接收,进程崩溃了。或者读取内核中的数据时候发生了极低概率的内存翻转等错误,或者是说接收正确,但是写硬盘的时候出错了。以上这些这些错误都是所谓可靠的 tcp 所无法照顾到的场景。
滑动窗口
客户端维护了一个 待发送的数据包的缓冲区,对于缓冲区的数据包,“发送一个数据包,等待该数据包的ack,再发送下一个” 的方式太低效了,所以客户端一次发送多个数据包(批量发送)
- client 不等第一个数据包收到ack就发送第二个,那么收到ack包时,如何确定这个ack包是对第一个还是第二个包的确认呢?序列号确认号
- 这个“多个”是多少呢? 就是滑动窗口的长度。主机 A 一直向主机 B 发送数据,不考虑主机 B 的接收能力,则可能导致主机 B 的接收缓冲区满了而无法再接收数据,从而导致大量的数据丢包,引发重传机制。而在重传的过程中,若主机 B 的接收缓冲区情况仍未好转,则会将大量的时间浪费在重传数据上,降低传送数据的效率。所以引入了流量控制机制,主机 B 通过告诉主机 A 自己接收缓冲区的剩余大小,来使主机 A 控制发送的数据量。总结来说:所谓流量控制就是控制发送方发送速率,保证接收方来得及接收。
发送窗口
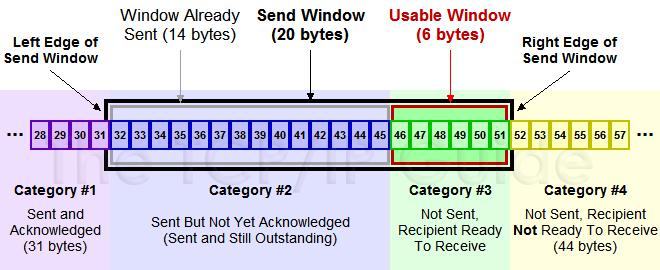
TCP 以字节为单位维护其窗口结构。这里 #1 是发送了且对端已经 ACK 确认过的,#2 是已经发送了但是尚未 ACK 过的,#3 是尚未发送的(接收方有空间可以发送),#4 是窗口大小以外的(接收方没空间了)。当接收方 ACK 了 32 后面的数据,这个窗口就可以往右边“滑动”了。所以又称之为滑动窗口(Sliding Window)算法。
接收窗口
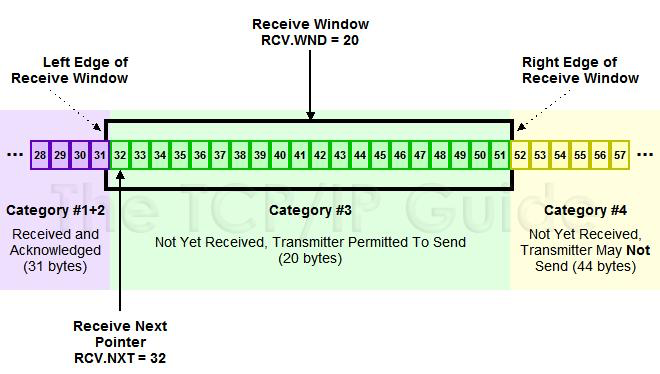
在此之后,基于跟接收方的沟通,可以调整滑动窗口的大小。滑动窗口在支持批量发送之外(类似于redis pipeline),又承载了 流控机制/拥塞控制的实现。
拥塞控制
TCP 协议通过调整接收窗口的大小对发送端进行限流。这个设计解决了接收端和发送端速率不匹配的问题。但是仅仅这样是不够的。在 TCP 传输过程中,要经过很多的处理节点(分组交换的存储-转发模型)。任意一条通信线路的繁忙都会造成网络的拥塞从而影响通信。TCP 不是一个自私的协议,当 TCP 感觉到网络时延突然增加的时候、如果拥塞突然发生的时候,每个进行中的 TCP 通信都会觉得是自己的问题,然后尝试把路让出来。这就依赖 TCP 里另外一个重要的部分——拥塞控制。这一块可以说是 TCP 里最复杂的一部分内容,涉及到的 RFC 和讨论多如牛毛。而且直到今天,新的拥塞控制算法还在不断的被提出和应用,以适应不断提速网络信道和场景不断变化的现实世界。
流量控制和拥塞控制其实就是根据收到的对端的网络包,调整两端数据结构的状态。TCP 协议的设计理论上认为,这样调整了数据结构的状态,就能进行流量控制和拥塞控制了,其实在通路上是不是真堵了,谁也管不着。总的来说,拥塞控制主要是通信两端自己需要实现的功能,而途中的网络设备,比如交换机、路由器等等,除了可能会发出拥塞通知报文以外,其他时候它们只管转发报文,都是不会担负更多的拥塞控制的责任的。
TCP 拥塞控制主要有四个重要阶段:慢启动;拥塞避免;快速重传;快速恢复。
- 慢启动/Slow Start,是指 TCP 传输的开始阶段是从一个相对低的速度(“慢”一词的由来)开始的。具体来说,在这个阶段,每次 TCP 收到一个确认了数据的 ACK,拥塞窗口(Congestion Window/CW)就增加一个 MSS。那么,这个过程什么时候终止呢?是下面两件事中有一件发生时:
- 遇到了拥塞;即检测到丢包,丢包对于发送端来说就是“拥塞
- 超时重传:如果发送端在超时时间内没有收到某个数据包的确认(ACK),则认为该数据包丢失;
- 重复 ACK:当接收端收到乱序的数据包时,会发送重复的 ACK 报文。如果发送端收到三个或更多重复的 ACK,也会认为某个数据包丢失
- 拥塞窗口增长到慢启动阈值/ssthresh。PS:网络延迟的90%不是距离是「协议开销」。
- 遇到了拥塞;即检测到丢包,丢包对于发送端来说就是“拥塞
- 拥塞避免,传输过了慢启动阈值(ssthresh)之后,就进入了拥塞避免阶段。拥塞窗口的增长速度立刻就放缓了,变成了每过一个 RTT,拥塞窗口就只增长一个 MSS(此前是每个确认数据的 ACK,增长一个 MSS)。直到探测到拥塞,然后拥塞窗口就要往下降。这个下降是直接减半的,所以叫乘性降低。PS:窗口一般比 MSS 大,而且大很多,相当于就是 MSS 的某个倍数,比如 2 倍、10 倍、50 倍等等。MSS 是有确定上限的,一般为 1460。
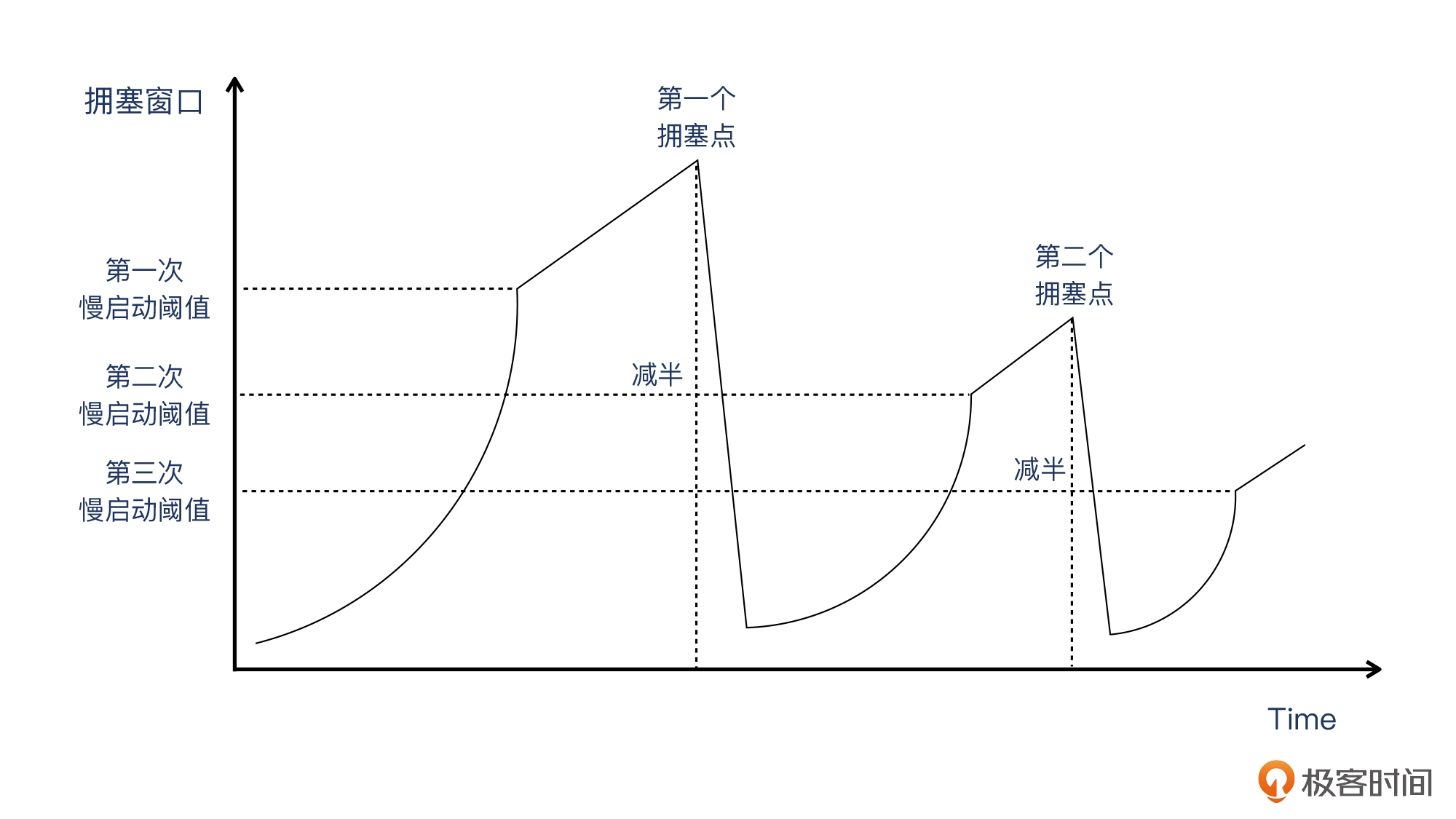 当然,图中的第二个拥塞点比第一个低只是一种可能的情况,现实场景里什么情况都可能有,因为网络状况本身就是动态变化的。
当然,图中的第二个拥塞点比第一个低只是一种可能的情况,现实场景里什么情况都可能有,因为网络状况本身就是动态变化的。 - 快速重传。TCP 每发送一个报文,就启动一个超时计时器。如果在限定时间内没收到这个报文的确认,那么发送方就会认为,这个报文已经在网络上丢失了,于是需要重传这个报文,这种形式叫做超时重传。一般来说,TCP 的最小超时重传时间为 200ms。这样的超时重传的机制虽然解决了丢包的问题,但也带来了一个新的问题:如果每次丢包都要等 200ms 或者更长时间,那应用不是就不能及时处理了吗?特别是对于有些时间敏感型的应用来说,影响更为严重。所以,TCP 会用另外一种方式来解决超时重传带来的时间空耗的问题,就是用快速重传。在这个机制里,一旦发送方收到 3 次重复确认(加上第一次确认就一共是 4 次),就不用等超时计时器了,直接重传这个报文。
- 快速恢复。它是跟随快速重传一起工作的。跟之前的“慢启动 -> 拥塞避免 -> 慢启动 -> 拥塞避免”这种做法不同的是,在遇到拥塞点之后,通过快速重传,就不再进入慢启动,而是从这个减半的拥塞窗口开始,保持跟拥塞避免一样的线性增长,直到遇到下一个拥塞点。
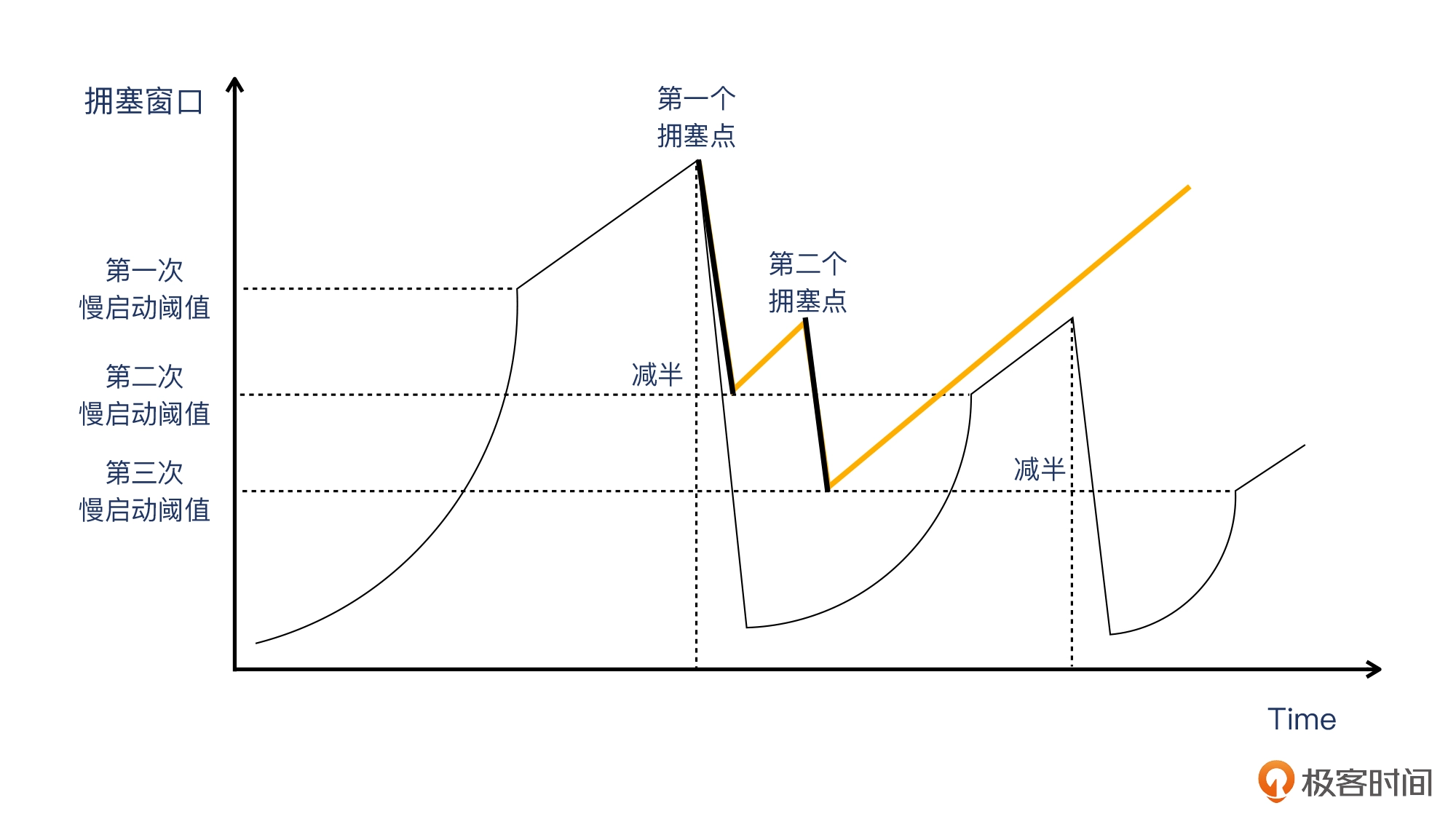 橙色线就是快速恢复阶段。
橙色线就是快速恢复阶段。
拥塞窗口是每个连接分开维护的,比如同一个主机有两个 TCP 连接在传输数据的话,那么这两个连接就各自维护自己的拥塞窗口,比如一个很大而一个很小,都没有关系。在 Linux 内核 3.0 以前,初始拥塞窗口(ICW)的大小比较小,在 2 到 4 个 MSS。2010 年,谷歌提出,为了充分利用现代互联网的传输能力,Linux(对应内核 3.0) 应该把 ICW 从 2~4 个 MSS 提升到 10 个 MSS。
用 Wireshark Statistics 菜单下的 TCP Stream Graphs -> Time Sequence (Stevens) 来观察慢启动和拥塞避免等现象。
所谓的可靠,也是两端的数据结构做的事情。不丢失其实是数据结构在“点名”,顺序到达其实是数据结构在“排序”,面向数据流其实是数据结构将零散的包,按照顺序捏成一个流发给应用层。总而言之,“连接”两个字让人误以为功夫在通路,其实功夫在两端。
假如带宽足够,网络也稳定,那又是什么决定了 TCP 传输的速度?
速度 = 距离 / 时间。看上去极为简单的公式,奥妙的地方在于:什么是距离,什么又是时间?假设你在开车,开出去 100 公里,耗时 1 小时。这是因为你眼观四路、耳听八方,在确保安全的前提下用比较快的速度行驶。如果你蒙上眼睛,那是 1 米都不敢开的,是不是?对于网络传输来说,报文发送出去后,发送端本身就“失去视力”了,也就是看不到报文在错综复杂的网络中行走时,到底遇到了什么样的“路况”。那它是继续发送更多数据好呢,还是先等对方确认这部分数据,然后再发送下一份数据好呢?如果确认了,那下一份数据又该发多少呢?
- 首先,一个报文被视为成功发送,基于以下的路径:(开始)发送端 » 数据报文 » 接收端 » ACK 报文 » 发送端(结束)。这样一来一回的时间,就是报文被成功传送的耗时。你可能会有疑问:数据报文到了接收端不就是已经完成传输了吗?其实,这个时候发送端还不知道接收端是否已经完成接收了,因为还没收到确认。从操作系统的角度来看:“完成”的标志,是这部分数据可以从发送缓存中删除;从缓存中删除这部分数据的前提,就是收到 ACK 报文。来回的时间,在英文里叫 Round Trip Time(RTT),即往返时间,也叫时延。报文大部分时候就像飞机在空中航行,跟两端的哪一端都碰不着,除了起飞和降落。在“空中”的时间,就取决于 RTT。RTT 越长,报文在“空中”的时间就越长。这个时候,这些报文就有了一个新的身份,叫做“在途数据”,它的大小,叫做在途字节数。英文是 Bytes in flight(Wireshark可以看)。
- 道路上最多可以容纳多少辆车呢?显然,是车道数×道路长度。那么类似地,带宽跟往返时间(RTT)相乘,就是在空中飞行的报文的最大数量,即带宽时延积。在英文里叫 Bandwidth Delay Product,缩写是 BDP(Delay 就是 RTT)。你可能还会有疑问,在途数据不是应该 RTT 的一半(即单程时间)再乘以带宽吗?从飞机的比喻来看,也许是的。但是你要考虑下图这种情况。如果回程时间只是用来传输 ACK,没有被用来传输实际的数据,效率就打了对折了。发送端并不知道什么时候报文到了接收端,它唯一知道的是什么时候自己收到了 ACK 报文,只有一半的时间在真正传输数据,另外一半时间没有在发送数据。假设时延是 134ms,带宽是 10Gbps,那么带宽时延积就是 0.134×10Gb。转换为 Byte 需要再除以 8,得到约 168MB。这个数值的意思是,假设这条链路完全被一次的文件传输连接所占满,那么最多可以有 168MB 的在途数据。假设文件95MB,如果按这个速度,那一个来回就传完了,也就是只需要 134ms!当然,TCP 有慢启动机制,不可能一开始就把一百多 MB 这么大的数字作为初始拥塞窗口,所以也不会真的一个来回就传完了。
TCP 有 3 个窗口:接收窗口、拥塞窗口,还有发送窗口。
- 接收窗口:它代表的是接收端当前最多能接收的字节数。通过 TCP 报文头部的 Window 字段,通信双方能互相了解到对方的接收窗口。在抓包文件里就能看到。一般说到 TCP Window,如果没有特别指明,就是指接收窗口。
- 拥塞窗口(Congestion Window):发送端根据实际传输的拥塞情况计算出来的可发送字节数,但不公开在报文中。各自暗地里各维护各的,互相不知道,也不需要知道。
- 发送窗口:对方的接收窗口和自身的拥塞窗口两者中,值较小者。实际发送的在途字节数不会大于这个值。
一般来说,接收窗口、拥塞窗口、发送窗口,这些都不是一上来就是一个很大的值的,这就产生了一个很有意思的话题:这些窗口之间都是怎么协调的呢?无论哪个更快了,另外两个就要受影响。假设起始值相同,如果接收窗口增长的速度小于拥塞窗口的增长速度,那么接收窗口就成了瓶颈(wireshark出现TCP Window Full现象);反过来说,拥塞窗口增速更小(一般wireshark会出现Out-of-Order、或者 retransmission),那么它就成了瓶颈。
速度 = 距离 / 时间 ==> 传输速度的上限就是 window/RTT。限制速度的最大因素,既不是带宽,也不是丢包,而是窗口。传输速度的问题,可以说就是窗口和往返时间这两个大玩家在起作用。你只要抓住这两个主要矛盾,就能解决大部分传输速度的问题了。其他因素也可能有它的作用,但一般不是核心矛盾。处理 TCP 传输速度问题的时候,先获取时延,再定位发送窗口,最后用这个公式去得到速度的上限值。
TCP 发展与上下游
TCP 与操作系统的关系
tcp/ip 只是一系列的协议,tcp真正的实现靠的是操作系统,进而抽象到语言层 有一个socket api作为入口,进行字节流交互。除linux 实现外,lwIP 是由瑞典计算机科学研究院(SICS)的 Adam Dunkels 开发的小型开源 TCP/IP 协议栈,它是一个用 C 语言实现的软件组件。
//golang
(c *conn) Read(b []byte) (int, error)
// c
int recv(int sockfd, void *buf, int len, int flags);
// java
InputStream in = socket.getInputStream();
int InputStream.read(byte b[], int off, int len);
编程接口
从基于 IP 协议的网络视角来看,数据并不是源源不断的流(stream),而是一个个大小有明确限制的 IP 数据包。
package net
type IPAddr struct {
IP IP
Zone string // IPv6 scoped addressing zone
}
func DialIP(network string, laddr, raddr *IPAddr) (*IPConn, error)
func ListenIP(network string, laddr *IPAddr) (*IPConn, error)
func (c *IPConn) Read(b []byte) (int, error)
func (c *IPConn) ReadFrom(b []byte) (int, Addr, error)
func (c *IPConn) ReadFromIP(b []byte) (int, *IPAddr, error)
func (c *IPConn) Write(b []byte) (int, error)
func (c *IPConn) WriteTo(b []byte, addr Addr) (int, error)
func (c *IPConn) WriteToIP(b []byte, addr *IPAddr) (int, error)
func (c *IPConn) Close() error
为什么需要有多套传输层的协议(TCP 和 UDP)呢?还是因为应用需求是多样的。底层的 IP 协议不保证数据是否到达目标,也不保证数据到达的次序。出于编程便捷性的考虑,TCP 协议就产生了。但是 TCP 协议对传输协议的可靠性保证,对某些应用场景来说并不是一个好特性。最典型的就是音视频的传输。在网络比较差的情况下,我们往往希望丢掉一些帧,但是由于 TCP 重传机制的存在,可能会反而加剧了网络拥塞的情况。这种情况下,UDP 协议就比较理想,它在 IP 协议基础上的额外开销非常小,基本上可以认为除了引入端口(port)外并没有额外做什么,非常适合音视频的传输需求。
package net
type TCPAddr struct {
IP IP
Port int
Zone string // IPv6 scoped addressing zone
}
func DialTCP(network string, laddr, raddr *TCPAddr) (*TCPConn, error)
func ListenTCP(network string, laddr *TCPAddr) (*TCPListener, error)
func (c *TCPConn) Read(b []byte) (int, error)
func (c *TCPConn) Write(b []byte) (int, error)
func (c *TCPConn) Close() error
func (l *TCPListener) Accept() (Conn, error)
func (l *TCPListener) AcceptTCP() (*TCPConn, error)
func (l *TCPListener) Close() error
监控
应用响应时延背后深藏的网络时延TCP 协议是面向连接的传输层通信协议,对其详细的通信过程分析,时延可分为三大类: • 建连时产生的时延 • [1] 完整的建连时延包含客户端发出 SYN 包到收到服务端回复的 SYN+ACK 包,并再次回复 ACK 包的整个时间。建连时延拆解开又可分为客户端建连时延与服务端建连时延 • [2] 客户端建连时延为客户端收到 SYN+ACK 包后,回复 ACK 包的时间 • [3] 服务端建连时延为服务端收到 SYN 包后,回复 SYN+ACK 包的时间 • 数据通信时产生的时延,可拆解为客户端等待时延+数据传输时延 • [4] 客户端等待时延为建连成功后,客户端首次发送请求的时间;为收到服务端的数据包后,客户端再发起数据包的时间 • [5] 数据传输时延为客户端发送数据包到收到服务端回复数据包的时间 • [6] 在数据传输时延中还会产生系统协议栈的处理时延,称为系统时延 • 断连时产生的时延:因为断连的时延并不影响到应用的响应时延,因此并不会单独统计此部分使用
度量的网络时延的指标已经拆解好了,接下来讨论在哪里采集指标,网络的报文将在客户端,各种虚拟和物理网络与服务端之间穿梭,因此可报文穿梭的位置点来采集,后续统称为统计位置。当然统计位置越多,定位网络的瓶颈路径越快,但是统计位置多则随之带来的计算量也是成倍增加,企业在有成本压力时,建议在重要节点进行采集即可,比如 K8s Pod 虚拟网卡、K8s Node 网卡、云服务器网卡、网关(如 LVS/Nginx 等)网卡、硬件防火墙/负载均衡器前后……
如何查看网络时延对请求响应时间的影响,基本可以分两种情况讨论
- 应用发起请求为短连接:此时分析网络时延需要查看 DNS 时延 + 建连时延 + 客户端等待时延 + 数据传输时延 + 系统时延,则可快速定位时延发生的具体原因了。
- DNS 时延高,结合统计位置,则可回答是网络传输时延高还是DNS 服务响应慢
- 建连时延高,结合客户端建连时延 + 服务端建连时延 + 统计位置,则可回答是网络传输时延高还是客户端系统回复慢还是服务端处理建连响应慢
- 客户端等待时延高,结合统计位置,则可回答是网络传输时延高还是客户端请求发送延迟
- 数据传输时延高,结合统计位置,则可回答是网络传输时延高还是服务端响应慢
- 系统时延高,结合统计位置,则可回答网络传输时延高还是服务端协议栈处理慢
- 应用发起请求为长连接:因为长连接是保持长期活动的 HTTP 连接,不需要考虑 DNS 查询与建连的时延消耗,只需要关注客户端等待时延 + 数据传输时延 + 系统时延即可
引用
TCP/IP 的七个设计理念
- internet communication must continue despite loss of networks or gateways. 要能容错。
- the network must support multiple types of communications service. 支持不同类型的通讯设备。
- the internet architecture must accommodate a variety of networks. 支持连接不同种类的网络比如wifi、光纤等
- the internet architecture must permit distributed management of its resources.
- the internet architecture must be cost effective.
- the internet architecture must permit host attachment with a low level of effort.
- the resources used in the internet architecture must be accountable.
- TCP中并不是所有的RST都有效
- Linux内核究竟有多少TCP端口可用。其中 ip_local_port_range 范围内的可以被系统随机分配,其他需要指定绑定使用,同一个端口只要TCP连接四元组不完全相同可以无限复用。

留下评论