tensorflow原理——core层分析
简介
本文内容主要来自 《深入理解Tensorflow》 和 《Tensorflow内核剖析》
神经网络在视觉上是一层一层的,表达式上是张量计算,执行上是数据流图。当今的软件开发基本都是分层化和模块化的,应用层开发会基于框架层。比如开发Linux Driver会基于Linux kernel,开发Android app会基于Android Framework。深度学习也不例外,框架层为上层模型开发提供了强大的多语言接口、稳定的运行时、高效的算子,以及完备的通信层和设备层管理层。学习Tensorflow框架内核,可以理解前端接口语言的支持,session生命周期,graph的构建、分裂和执行,operation的注册和运行,模块间数据通信,本地运行和分布式运行模式,以及CPU GPU TPU等异构设备的封装支持等。学习这些,对于模型的压缩 加速 优化等都是大有裨益的。
| 视图层 | 可视化 | TensorBoard | |
| 工作流层 | 数据集准备、存储、加载 | Keras | |
| 计算图层 | Graph构造/操作/优化/执行/前向计算/后向传播 | TensorFlow Core | Graph中每个节点都是OpKernels类型 |
| 数值计算层 | opKernel实现/矩阵乘法/卷积计算 | Eigen/cuBLAS/cuDNN | OpKernels以Tensor为处理对象,依赖网络通信和设备内存分配,实现了各种Tensor操作或计算 |
| 网络层 | 组件间通信 | grpc/RDMA | |
| 设备层 | 硬件 | CPU/GPU/TPU/FPGA |
tensorflow
c
cc // c++ 前端接口
java // java 前端接口
python // python 前端接口
stream_executor // 运行时环境,对cuda和opencl进行统一封装,屏蔽他们的区别
compiler // 运行时优化,分析计算图,对op 进行融合,提升运行效率,XLA技术
contrib // 三方库,成熟后会移到core python中
core // tf的核心,基本都是c++,包括运行时、图操作、op定义、kernel实现等
common_runtime // 本地运行时
distributed_runtime // 分布式运行时
framework // 框架层
graph // 图,包括图的创建、分裂和执行等,tf的核心对象
kernels // 内核,包括op算子的实现
ops // op算子的定义
platform // 平台相关
protobuf // 数据格式定义,graph 就是通过这种格式在client 和master 间传递的
user_ops // 用户自定义算子
以Graph为中心的视角
深度学习分布式训练的现状及未来AI 模型训练任务流程:初始化模型参数 -> 逐条读取训练样本 -> 前向、反向、参数更新 -> 读取下一条样本 -> 前向、反向、参数更新 -> … 循环,直至收敛。在软件层面的体现就是计算机按顺序运行一个个 OP。
proto 定义
// tensorflow/core/framework/graph.proto
message GraphDef {
repeated NodeDef node = 1;
VersionDef versions = 4;
}
// tensorflow/core/protobuf/worker_service.proto
service WorkerService {
rpc RegisterGraph(RegisterGraphRequest) returns (RegisterGraphResponse);
rpc RunGraph(RunGraphRequest) returns (RunGraphResponse);
}
message OpDef{
string name = 1;
repeated ArgDef input_org = 2;
repeated ArgDef output_org = 3;
repeated AttrDef attr = 4; // 用于描述OP输入输出的类型,大小,默认值,约束,及其其他OP的特征
string summary = 5;
string description = 6;
//options
...
}
以下划线开头的OP被系统内部实现保留。例如,_Send, _Recv,它们用于设备间通信的OP;_Source, _Sink标识计算图的开始节点和结束节点。
C++定义
// 后端中的Graph主要成员也是节点node和边edge
class Graph {
private:
FunctionLibraryDefinition ops_; // 所有已知的op计算函数的注册表
const std::unique_ptr<VersionDef> versions_; // GraphDef版本号
std::vector<Node*> nodes_; // 节点node列表,通过id来访问
int64 num_nodes_ = 0; // node个数
std::vector<Edge*> edges_; // 边edge列表,通过id来访问
int num_edges_ = 0; // graph中非空edge的数目
// 已分配了内存,但还没使用的node和edge
std::vector<Node*> free_nodes_;
std::vector<Edge*> free_edges_;
}
// Edge既可以承载tensor数据,提供给节点Operation进行运算,也可以用来表示节点之间有依赖关系
class Edge {
private:
Edge() {}
friend class EdgeSetTest;
friend class Graph;
Node* src_; // 源节点, 边的数据就来源于源节点的计算。源节点是边的生产者
Node* dst_; // 目标节点,边的数据提供给目标节点进行计算。目标节点是边的消费者
int id_; // 边id,也就是边的标识符
int src_output_; // 表示当前边为源节点的第src_output_条边。源节点可能会有多条输出边
int dst_input_; // 表示当前边为目标节点的第dst_input_条边。目标节点可能会有多条输入边。
};
class Node {
public:
const NodeDef def() const; // NodeDef,节点算子Operation的信息,比如op分配到哪个设备上了,op的名字等,运行时有可能变化。
const OpDef op_def() const; // OpDef, 节点算子Operation的元数据,不会变的。比如Operation的入参列表,出参列表等
private:
EdgeSet in_edges_; // 输入边,传递数据给节点。可能有多条
EdgeSet out_edges_; // 输出边,节点计算后得到的数据。可能有多条
}
系统中存在默认的Graph,初始化Graph时,会添加一个Source节点和Sink节点。Source表示Graph的起始节点,Sink为终止节点。Source的id为0,Sink的id为1,其他节点id均大于1。
数据流图的整体执行
阿里巴巴开源大规模稀疏模型训练/预测引擎DeepRecTensorFlow是一个基于Graph的静态图训练引擎,在其架构上有相应的分层,比如最上层的API层、中间的图优化层和最下层的算子层。TensorFlow通过这三层的设计去支撑上层不同Workload的业务需求和性能优化需求。
符号式编程将计算过程抽象为计算图(所有函数操作都是在构造GraphDef)。TensorFlow 使用数据流图表达计算过程和共享状态,使用节点表示抽象计算,使用边 表示数据流。如下图,展示了 MNIST 手写识别应用的数据流图。在该模型 中,前向子图使用了 2 层全连接网络,分别为 ReLU 层和 Softmax 层。随后,使用 SGD 的 优化算法,构建了与前向子图对应的反向子图,用于计算训练参数的梯度。最后,根据参数 更新法则,构造训练参数的更新子图,完成训练参数的迭代更新。
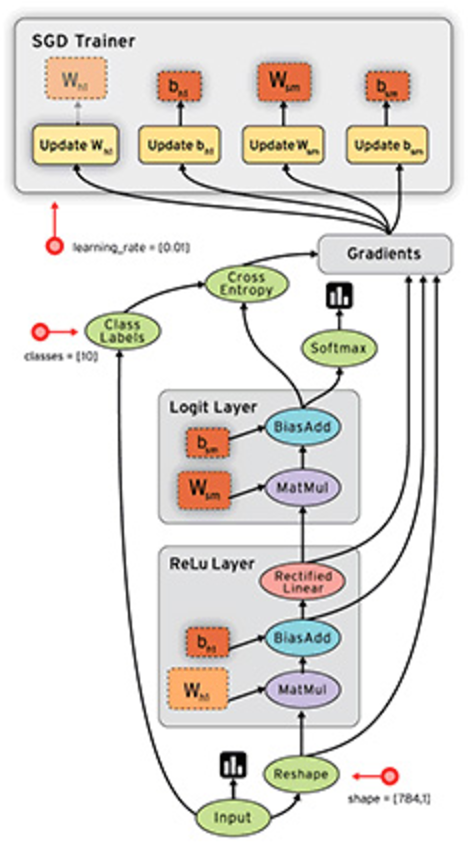
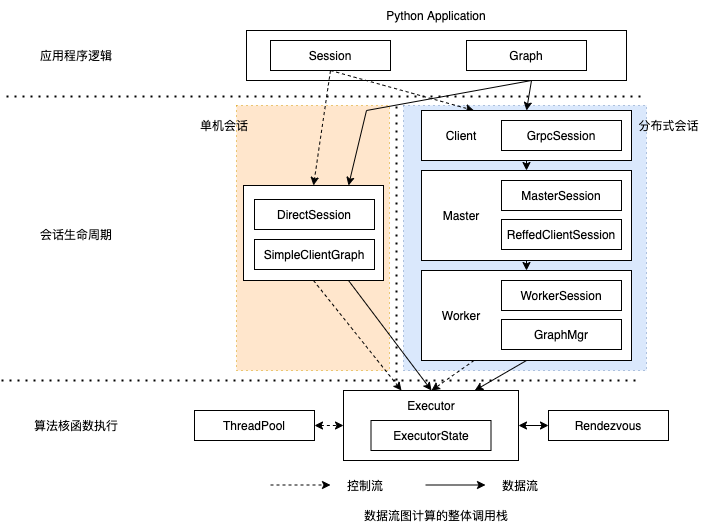
《深入理解Tensorflow》数据流图计算粗略的分为 应用程序逻辑、 会话生命周期和算法核函数执行 这3个层次
- 在应用程序逻辑中,用户使用Python 等应用层API 及高层抽象编写算法 模型,无需关心图切分、进程间通信等底层实现逻辑。算法涉及的计算逻辑和输入数据绑定到图抽象中,计算迭代控制语义体现在会话运行前后(即session.run)的控制代码上。
- 在会话生命周期层次,单机会话与分布式会话具有不同的设计。
- 单机会话采用相对简单的会话层次和图封装结构,它将图切分、优化之后,把操作节点和张量数据提交给底层执行器
- 分布式会话分为 client、master和worker 三层组件,它们对计算任务进行分解和分发,并通过添加通信操作 来确保计算逻辑的完整性。
- 在算法核函数执行层次, 执行器抽象将会话传入的核函数加载到各个计算设备上有序执行。为充分利用多核硬件的并发计算能力,这一层次提供线程池调度机制;为实现众多并发操作的异步执行和分布式协同, 这一层次引入了通信会合点机制。
模型构造和执行流程
- 图构建(Client):用户在client中基于TensorFlow的多语言编程接口,添加算子,完成计算图的构造。
- 图传递(Client->Master):client开启session,通过它建立和master之间的连接。执行session.run()时,将构造好的graph序列化为graphDef后,以protobuf的格式传递给master。
- 图剪枝(Master,Master->Worker):master根据session.run()传递的fetches和feeds列表,反向遍历全图full graph,实施剪枝,得到最小依赖子图 图分裂:master将最小子图分裂为多个Graph Partition,并注册到多个worker上。一个worker对应一个Graph Partition。
- (Worker)图二次分裂:worker根据当前可用硬件资源,如CPU GPU,将Graph Partition按照op算子设备约束规范(例如tf.device(‘/cpu:0’),二次分裂到不同设备上。每个计算设备对应一个Graph Partition。
- 图运行(Worker):对于每一个计算设备,worker依照op在kernel中的实现,完成op的运算。设备间数据通信可以使用send/recv节点,而worker间通信,则使用GRPC或RDMA协议。
《大规模数据处理实战》不少人在理解 PCollection 的时候都觉得这不那么符合他们的直觉。许多人都会自然地觉得 PCollection 才应该是节点,而 Transform 是边。因为数据给人的感觉是一个实体,应该用一个方框表达;而边是有方向的,更像是一种转换操作。其实,区分节点和边的关键是看一个 Transform 是不是会有多于一个的输入和输出。每个 Transform 都可能有大于一个的输入 PCollection,它也可能输出大于一个的输出 PCollection。所以,我们只能把 Transform 放在节点的位置。因为一个节点可以连接多条边,而同一条边却只能有头和尾两端。
结合分布式环境
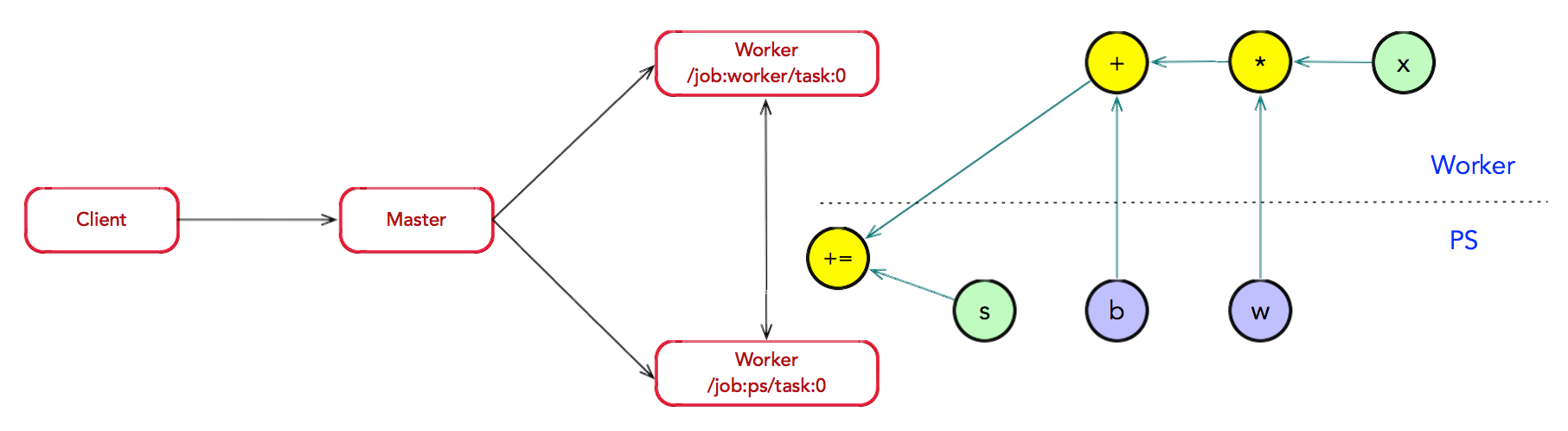
假如存在一个简单的分布式环境:1 PS + 1 Worker
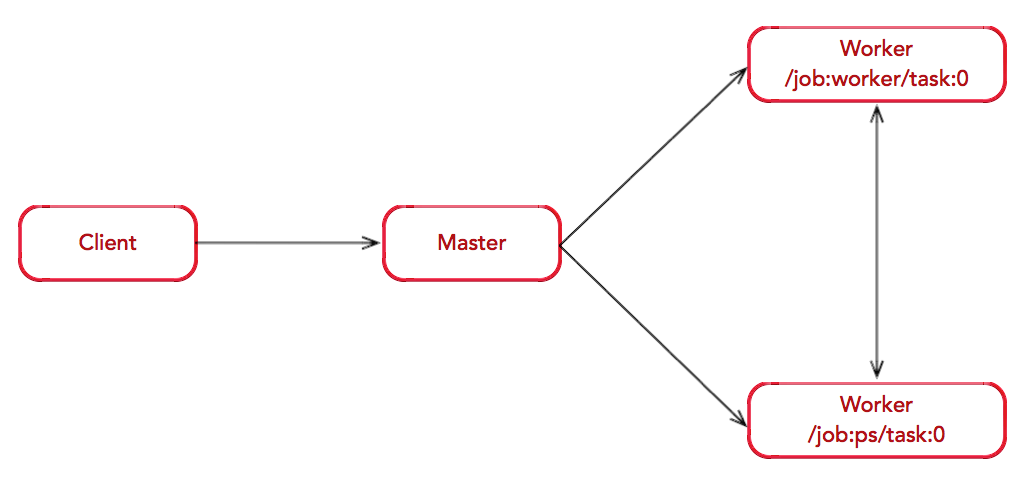
图构造:Client 构建了一个简单计算图;首先,将 w 与 x 进行矩阵相 乘,再与截距 b 按位相加,最后更新至 s 中。
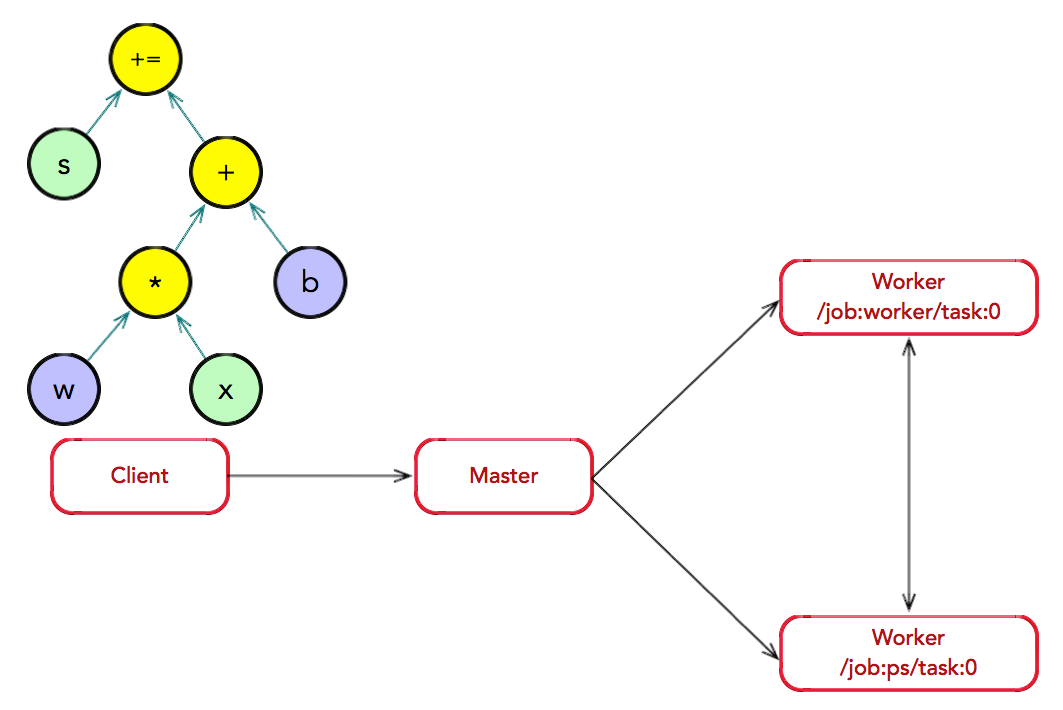
图执行:Client 创建一个 Session 实例,建立与 Master 之间的 通道;接着,Client 通过调用 Session.run 将计算图传递给 Master。Master 会实施一系列优化技术,例如公共表达式消除,常量折叠等。最后,Master 负责任务之间的协同,执 行优化后的计算图。
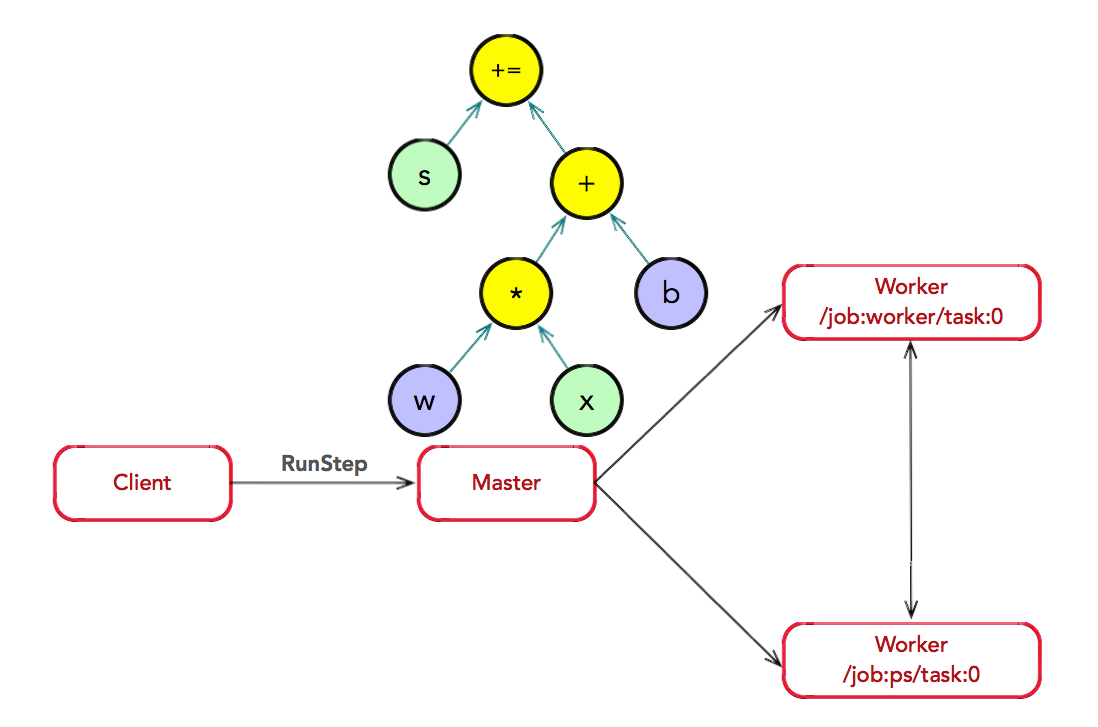
图分裂:存在一种合理的图划分算法。Master 将模型参数相关的 OP 划 分为一组,并放置在 ps0 任务上;其他 OP 划分为另外一组,放置在 worker0 任务上执行。
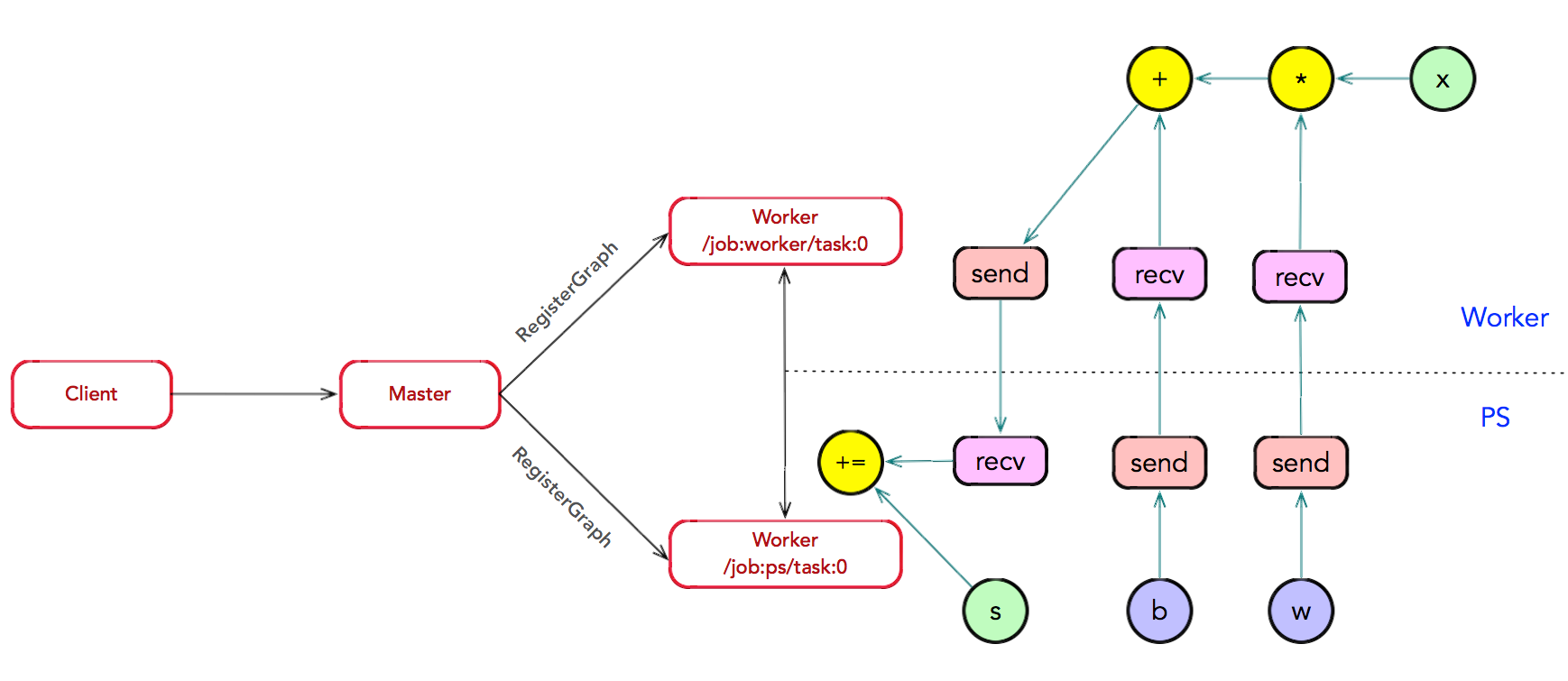
子图注册:在图分裂过程中,如果计算图的边跨越节点或设备,Master 将 该边实施分裂,在两个节点或设备之间插入 Send 和 Recv 节点,实现数据的传递。其中,Send 和 Recv 节点也是 OP,只不过它们是两个特殊的 OP,由内部运行时管理和控制,对用户不可见;并且,它们仅用于数据的通信,并没有任何数据计算的逻辑。最后,Master 通过调用 RegisterGraph 接口,将子图注册给相应的 Worker 上,并由相 应的 Worker 负责执行运算。
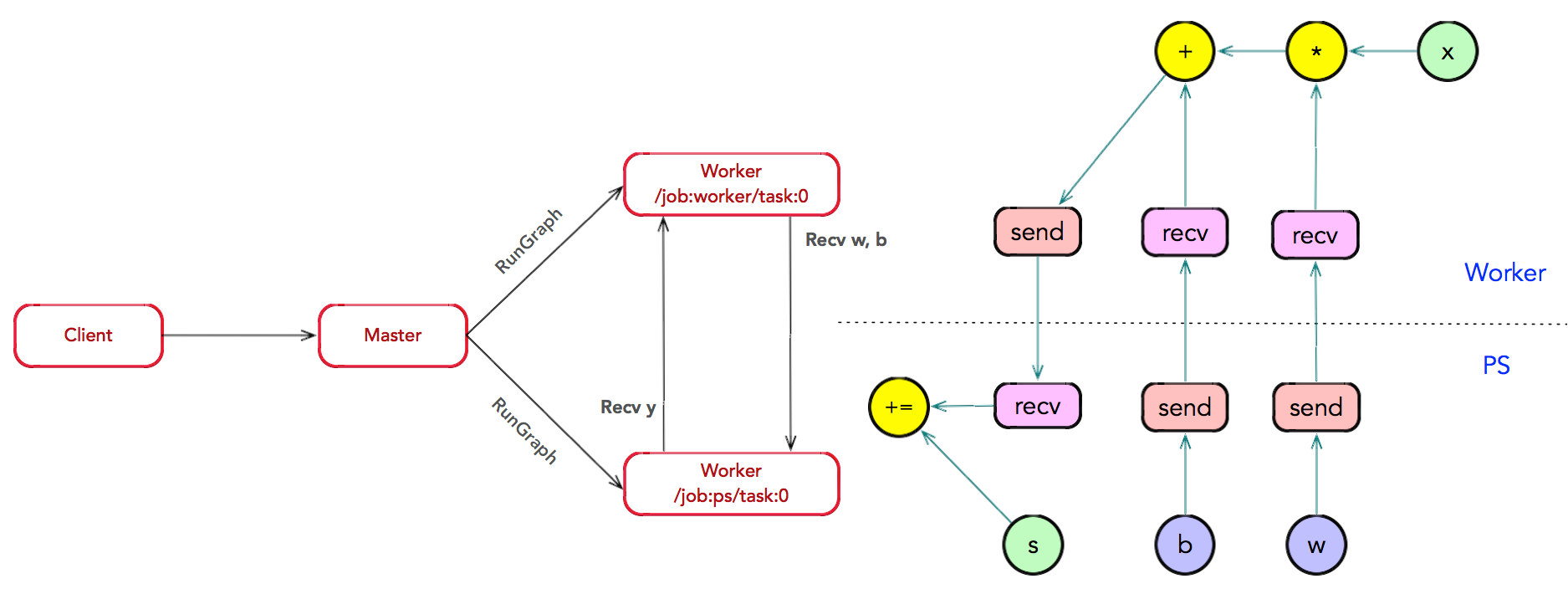
子图运算:Master 通过调用 RunGraph 接口,通知所有 Worker 执行子图 运算。其中,Worker 之间可以通过调用 RecvTensor 接口,完成数据的交换。
client-master-worker
Master-Worker 架构是分布式系统之中非常常见的一种架构组织形式,此架构下,Master 通常维护集群元信息,调度任务,Workers 则负责具体计算或者维护具体数据分片。Client 利用这个分布式环境进行计算。
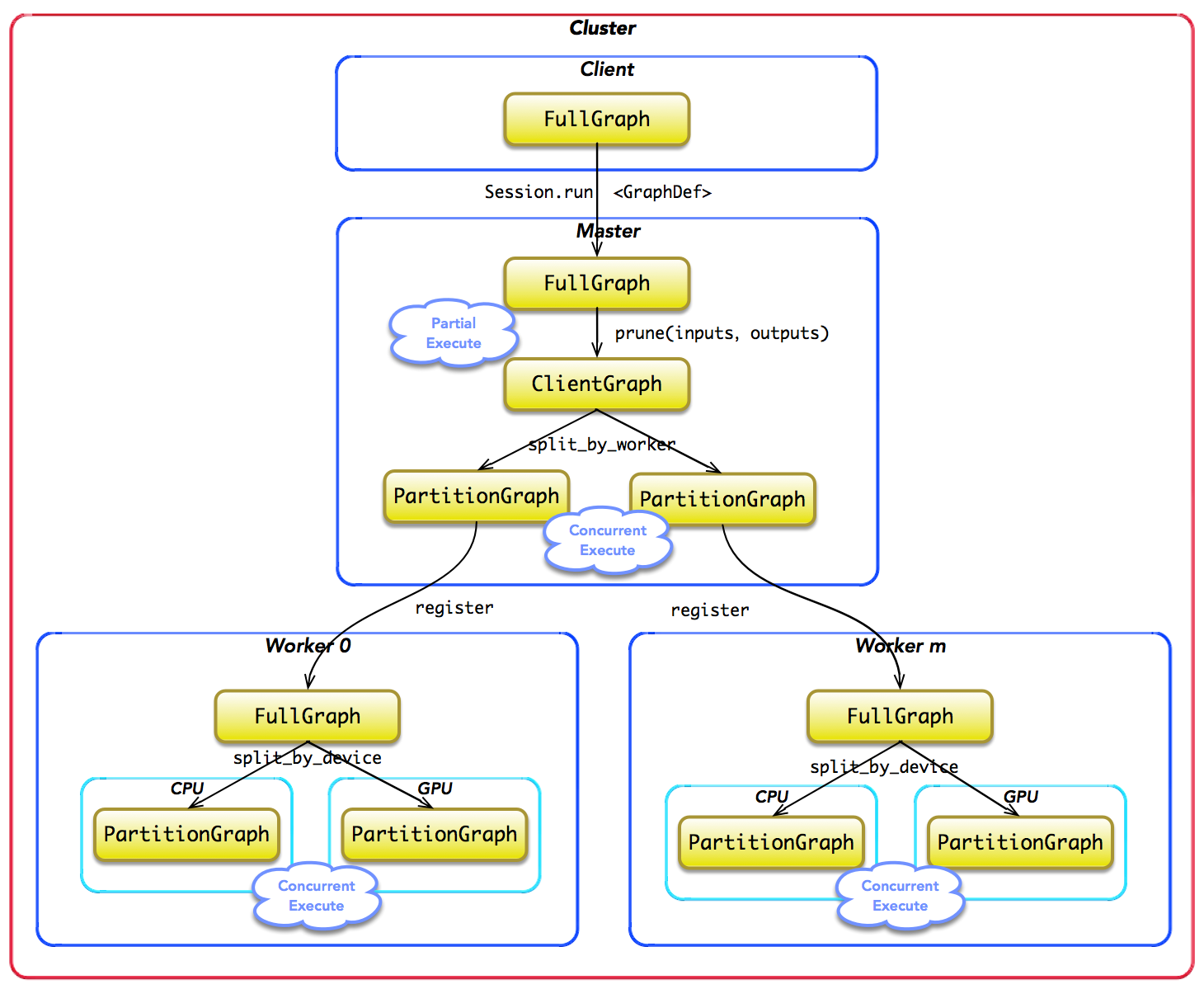
应用层数据流图 表示为Python API 中的tensoflow.Graph 类,通信时表示为 基于Protocol Buffers 文件定义的GraphDef (以 Session 为桥梁,建立 Client 与 Master 之间的通道,并将 Protobuf 格式的 GraphDef 序列 化后传递给 Master),运行时的数据流图 表示为C++ 代码中的Graph 类及其成员类型。GraphDef是描述计算图的知识模型,整个TensorFlow的计算过程都是围绕GraphDef所展开的。
在分布式的运行时环境中,Client 执行 Session.run 时,传递整个计算图给后端的 Master。此时,计算图是完整的,常称为 Full Graph。随后,Master 根据 Session.run 传 递给它的 fetches, feeds 参数列表,反向遍历 Full Graph,并按照依赖关系,对其实施剪 枝,最终计算得到最小的依赖子图,常称为 Client Graph。 接着,Master 负责将 Client Graph 按照任务的名称分裂 (SplitByTask) 为多个 Graph Partition;其中,每个 Worker 对应一个 Graph Partition。随后,Master 将 Graph Partition 分别注册到相应的 Worker 上,以便在不同的 Worker 上并发执行这些 Graph Partition。最 后,Master 将通知所有 Work 启动相应 Graph Partition 的执行过程。 其中,Work 之间可能存在数据依赖关系,Master 并不参与两者之间的数据交换,它们 两两之间互相通信,独立地完成交换数据,直至完成所有计算。
对于每一个任务,TensorFlow 都将启动一个 Worker 实例。Worker 主要负责如下 3 个 方面的职责:
- 处理来自 Master 的请求;
- 对注册的 Graph Partition 按照本地计算设备集实施二次分裂 (SplitByDevice),并通知各个计算设备并发执行各个 Graph Partition;
- 按照拓扑排序算法在某个计算设备上执行本地子图,并调度 OP 的 Kernel 实现;
- 协同任务之间的数据通信。Worker 要负责将 OP 运算的结果发送到其他的 Worker 上去,或者接受来自 其他 Worker 发送给它的运算结果,以便实现 Worker 之间的数据交互。TensorFlow 特化实 现了源设备和目标设备间的 Send/Recv。
- 本地 CPU 与 GPU 之间,使用 cudaMemcpyAsync 实现异步拷贝;
- 本地 GPU 之间,使用端到端的 DMA 操作,避免主机端 CPU 的拷贝。
- 对于任务间的通信,TensorFlow 支持多种通信协议。1. gRPC over TCP;2. RDMA over Converged Ethernet。并支持 cuNCCL 库,用于改善多 GPU 间的通信。
Kernel 是 OP 在某种硬件设备的特定实现,它负责执行 OP 的具体运算。目前, TensorFlow 系统中包含 200 多个标准的 OP,包括数值计算,多维数组操作,控制流,状 态管理等。
会话管理
Session是TensorFlow的client和master连接的桥梁(Client 是tf.Session,Master 是Session),client任何运算(create run close和del)均由Python前端开始,最终调用到C层后端实现。在client端,The default session/graph is a property of the current thread. 有点像java threadlocal的意思,以便client 的各个操作都可以方便获取session/graph。
会话生命周期与图控制
《Tensorflow内核剖析》 调用一次 run 是执行一遍数据流图
- 创建会话:Client 首次执行 tf.Session.run 时,会将整个图序列化后,通过 gRPC 发送CreateSessionRequest 消息,将图传递给 Master。随后,Master 创建一个 MasterSession 实例,并用全局唯一的 handle 标识,最终通过 CreateSessionResponse 返回给 Client。
- 迭代运行:随后,Client 会启动迭代执行的过程,并称每次迭代为一次 Step。此时,Client 发送 RunStepRequest 消息给 Master,消息携带 handle 标识,用于 Master 索引相应的 MasterSession 实例。
- 注册子图:Master 收到 RunStepRequest 消息后,将执行图剪枝,分裂,优化等操作。最终按照任 务 (Task),将图划分为多个子图片段 (Graph Partition)。随后,Master 向各个 Worker 发送 RegisterGraphRequest 消息,将子图片段依次注册到各个 Worker 节点上。当 Worker 收到 RegisterGraphRequest 消息后,再次实施分裂操作,最终按照设备 (Device),将图划分为多个子图片段 (Graph Partition)。当 Worker 完成子图注册后,通过返回 RegisterGraphReponse 消息,并携带 graph_handle 标识。这是因为 Worker 可以并发注册并运行多个子图,每个子图使用 graph_handle 唯一 标识。
- 运行子图:
Master 完成子图注册后,将广播所有 Worker 并发执行所有子图。这个过程是通过 Master 发送 RunGraphRequest 消息给 Worker 完成的。其中,消息中携带 (session_handle, graph_handle, step_id) 三元组的标识信息,用于 Worker 索引相应的子图。
Worker 收到消息 RunGraphRequest 消息后,Worker 根据 graph_handle 索引相应的子 图。最终,Worker 启动本地所有计算设备并发执行所有子图。其中,每个子图放置在单独 的 Executor 中执行,Executor 将按照拓扑排序算法完成子图片段的计算。上述算法可以形 式化地描述为如下代码。
def run_partitions(rendezvous, executors_and_partitions, inputs, outputs): rendezvous.send(inputs) for (executor, partition) in executors_and_partitions: executor.run(partition) rendezvous.recv(outputs) - 关闭会话:当计算完成后,Client 向 Master 发送 CloseSessionReq 消息。Master 收到消息后,开 始释放 MasterSession 所持有的所有资源。

PS:tf 运行时 很像一个c++ 写的grpc server 程序。
单机会话运行 DirectSession.run
Tensorflow源码解析6 – TensorFlow本地运行时本地运行时,client master和worker都在本地机器的同一进程内,均通过DirectSession类来描述(由 DirectSession 同时扮演这三个角色)。由于在同一进程内,三者间可以共享内存,通过DirectSession的相关函数实现调用。client前端直接面向用户,负责session的创建,计算图Graph的构造。并通过session.run()将Graph序列化后传递给master。master收到后,先反序列化得到Graph,然后根据反向依赖关系,得到几个最小依赖子图,这一步称为剪枝。之后master根据可运行的设备情况,将子图分裂到不同设备上,从而可以并发执行,这一步称为分裂。最后,由每个设备上的worker并行执行分裂后的子图,得到计算结果后返回。最终完成子图上定义的所有计算语义,将输出结果以张量形式返回给创建会话的应用程序。ps:跟一个dag 流程编排软件的执行逻辑差不多。
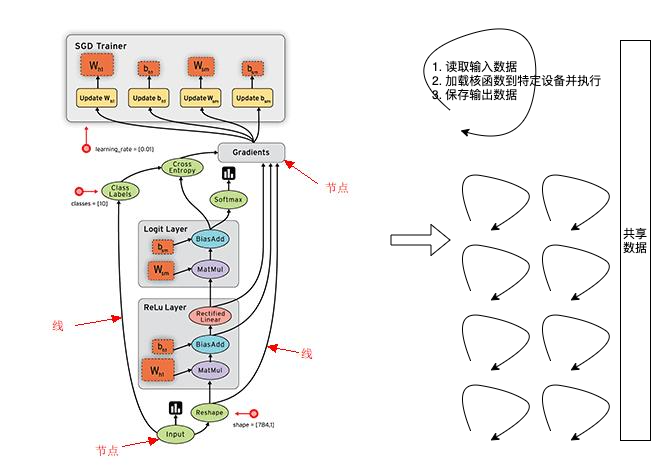
Graph经过master剪枝和分裂后,就可以在本地的各CPU GPU设备上执行了(这个过程的管理者叫worker)。各CPU GPU设备间可能需要数据通信,通过创建send/recv节点来解决。数据发送方创建send节点,将数据放在send节点内,不阻塞。数据接收方创建recv节点,从recv节点中取出数据,recv节点中如果没有数据则阻塞。这是一个典型的生产者-消费者关系。
运行时是围绕计算图Graph来进行的:图从GraphDef 反序列化为Graph,剪枝和分裂,将分裂后的子图发送给多个worker。Tensorflow 的关键路径为 run_step,用python 简化描述一下
def run_step(devices, full_graph, inputs, outputs):
client_graph = prune(full_graph, inputs, outputs)
executors_and_partitions = split(client_graph, devices)
run_partitions(executors_and_partitions, inputs, outputs)
def run_partitions(executors_and_partitions, inputs, outputs):
frame = FunctionCallFrame()
frame.set_args(inputs)
do_run_partitions(executors_and_partitions)
frame.get_ret_vals(outputs)
def do_run_partitions(executors_and_partitions):
barrier = ExecutorBarrier(executors_and_partitions.size())
for (executor, partition) in executors_and_partitions:
executor.run(partition, barrier)
barrier.wait()
在每个计算设备上,启动一个 Executor 执行分配给它的 PartitionGraph(即executor.run)。当某 一个计算设备执行完所分配的 PartitionGraph 之后,ExecutorBarrier 的计数器加 1,直至 所有设备完成 PartitionGraph 列表的执行,barrier.wait() 阻塞操作退出。
分布式会话运行
在分布式模式中,可能存在多个 Client 同时接入一个 Master, Master 为其每个接入的 Client 创建一个 MasterSession 实例。Worker 也可能同时为多个 Master 提供计算服务,Worker 为其每个请求计算的 Master 创建一个 WorkerSession 实例。 为了区分不同的 Client 的计算服务,使用不同的 session_handle 区分。PS: client-master-worker 属于不同的角色、实现不同的功能,执行还是要由进程驱动。
tf.train.ClusterSpec({
"worker": [
"worker0:2222", # /job:worker/task:0
"worker1:2222", # /job:worker/task:1
"worker2:2222" # /job:worker/task:2
],
"ps": [
"ps0:2222", # /job:ps/task:0
"ps1:2222" # /job:ps/task:0
]})
一般地,在分布式运行时中,Task (比如 /job:worker/task:0) 运行在独立的进程中(cluster/job/task 都是对进程的一种划分),并在其上运行一个 tf.train.Server 实例。Server 表示 Task 的服务进程,它对外提供 MasterService 和 WorkerService 服务(grpc)。也 就是说,Server 可以同时扮演 Master 和 Worker 两种角色。
service MasterService {
rpc CreateSession(CreateSessionRequest)
returns (CreateSessionResponse);
rpc ExtendSession(ExtendSessionRequest)
returns (ExtendSessionResponse);
rpc PartialRunSetup(PartialRunSetupRequest)
returns (PartialRunSetupResponse);
rpc RunStep(RunStepRequest)
returns (RunStepResponse);
rpc CloseSession(CloseSessionRequest)
returns (CloseSessionResponse);
rpc ListDevices(ListDevicesRequest)
returns (ListDevicesResponse);
rpc Reset(ResetRequest)
returns (ResetResponse);
service WorkerService {
rpc GetStatus(GetStatusRequest)
returns (GetStatusResponse);
rpc CreateWorkerSession(CreateWorkerSessionRequest)
returns (CreateWorkerSessionResponse);
rpc RegisterGraph(RegisterGraphRequest)
returns (RegisterGraphResponse);
rpc DeregisterGraph(DeregisterGraphRequest)
returns (DeregisterGraphResponse);
rpc RunGraph(RunGraphRequest)
returns (RunGraphResponse);
rpc CleanupGraph(CleanupGraphRequest)
returns (CleanupGraphResponse);
rpc CleanupAll(CleanupAllRequest)
returns (CleanupAllResponse);
rpc RecvTensor(RecvTensorRequest)
returns (RecvTensorResponse)
rpc Logging(LoggingRequest)
returns (LoggingResponse);
rpc Tracing(TracingRequest)
returns (TracingResponse);
在分布式模式中,Client 负责计算图的构造,然后通过调用 Session.run,启动计算图的执行过程。
- Master 进程收到计算图执行的消息后,启动计算图的剪枝,分裂,优化等操作;最终将子图分发注册到各个 Worker 进程上,然后触发各个 Worker 进程并发执行子图。
- Worker 进程收到子图注册的消息后,根据本地计算设备资源,再将计算子图实施二 次分裂,将子图分配在各个计算设备上,最后启动各个计算设备并发地执行子图;如果 Worker 之间存在数据交换,可以通过进程间通信完成交互。
其中,在分布式运行时,图分裂经历了两级分裂过程。
- 一级分裂:由 MasterSession 完成,按照 SplitByWorker 或 SplitByTask 完成图 分裂过程;
- 二级分裂:由 WorkerSession 完成,按照 SplitByDevice 完成图分裂过程。
def run_step(devices, full_graph, inputs, outputs):
executors_and_partitions = split(full_graph, devices)
run_partitions(executors_and_partitions, inputs, outputs)
def run_partitions(executors_and_partitions, inputs, outputs):
remote_rendezvous = RpcRemoteRendezvous()
send_inputs(remote_rendezvous, inputs)
do_run_partitions(executors_and_partitions)
recv_outputs(remote_rendezvous, outputs)
def send_inputs(remote_rendezvous, inputs):
for (key, tensor) in inputs:
remote_rendezvous.send(key, tensor)
def do_run_partitions(executors_and_partitions):
barrier = ExecutorBarrier(executors_and_partitions.size())
for (executor, partition) in executors_and_partitions:
executor.run(partition, barrier.on_done())
barrier.wait()
def recv_outputs(remote_rendezvous, outputs):
for (key, tensor) in outputs:
remote_rendezvous.recv(key, tensor)
汇合点机制 / 设备间通信
本地/分布式运行时存在跨设备的数据依赖。对于跨设备的数据边,将其分裂,在发送方插入send节点,接收方插入recv节点。如果二者跨进程通信(比如两台不同的服务器),则通过GrpcRemoteRendezvous进行数据交换。如果二者是进程内通信(比如同一台服务器的CPU0和CPU1),则通过IntraProcessRendezvous进行数据交换。
使用
在具体实现上,Tensorflow实现了Recv-Driven的数据交换模式,如上图所示,位于DeviceA和DeviceB的两张计算图会异步并发的执行,位于DeviceB的Recv执行时会发起一条RPC请求发往DeviceA,DeviceA收到请求后,会将请求路由到Rendezvous中,如果在当中发现所需要的数据已经生产好,并被Send算子注册了进来,那么就地获取数据,返回给DeviceB;如果此时数据还没有生产好,则将来自于DeviceB的Recv请求注册在Rendezvous中,等待后续DeviceA生产好后,由Send算子发送过来,找到注册的Recv,触发回调,返回数据给DeviceB。
跨设备的 PartitionGraph 之间可能存在数据依赖关系,它们之间通过插入 Send/Recv 节点完成交互。事实上,在本地模式中,Send/Recv 通过 Rendezvous 完成数据交换的。Send 将数据放在 Rendezvous 上,而 Recv 则根据标识从 Rendezvous 取走。其中,Send 不阻塞, 而 Recv 是阻塞的。也可以使用基于 FunctionCallFrame 函数调用替代之,使用 Arg/RetVal 分别替代 Send/Recv 节点,从而实现了函 数调用交换数据的方式。
SendOp/RecvOp 通过 Rendezvous 交换数据的;它实现了消息发送/接受,与具体消息传 递相解耦。例如,在单进程内,SendOp/RecvOp 基于 IntraProcessRendezvous 传递数据的; 而在多进程环境中,SendOp/RecvOp 则可以基于 GrpcRendezvous 传递数据。
// sendOp ==> Rendezvous.Send
struct SendOp : OpKernel {
void Compute(OpKernelContext* ctx) override {
Rendezvous::Args args;
args.device_context = ctx->op_device_context();
args.alloc_attrs = ctx->input_alloc_attr(0);
ctx->rendezvous()->Send(
CreateParsedkey(ctx), args, ctx->input(0),
ctx->is_input_dead());
}
}
// recvOp ==> Rendezvous.RecvAsync
struct RecvOp : AsyncOpKernel {
void ComputeAsync(OpKernelContext* ctx, DoneCallback done) override {
Rendezvous::Args args;
args.device_context = ctx->op_device_context();
args.alloc_attrs = ctx->output_alloc_attr(0);
ctx->rendezvous()->RecvAsync(
CreateParsedKey(ctx), args, CreateDoneCallback(ctx));
}
}
实现
TensorFlow中的通信机制——Rendezvous(一)本地传输最基本的Rendezvous类被定义在了tensorflow/core/framework/rendezvous.h文件中,它对外提供了最基本的Send、Recv和RecvAsync接口和实现。
// 每次分布式通信都需要有一个全局唯一的标识符
// ParsedKey 消息传输的唯一标识符,用于建立 send 和 recv的对应关系
// ParsedKey 的关键就是 src_device , dst_device 和 edge_name
struct ParsedKey {
StringPiece src_device;
DeviceNameUtils::ParsedName src;
uint64 src_incarnation = 0;
StringPiece dst_device;
DeviceNameUtils::ParsedName dst;
StringPiece edge_name; // 可以灵活指定为任何字符串,实现不同Key的区分。比如它可以是Tensor的名字,也可以是具有某种特殊意义的固定字符串
}
class RendezvousInterface {
public:
// Send() never blocks.
virtual Status Send(const ParsedKey& key, const Args& args, const Tensor& val, const bool is_dead) = 0;
virtual void RecvAsync(const ParsedKey& key, const Args& args, DoneCallback done) = 0;
// Synchronous wrapper for RecvAsync.
Status Recv(const ParsedKey& key, const Args& args, Tensor* val, bool* is_dead, int64 timeout_ms);
Status Recv(const ParsedKey& key, const Args& args, Tensor* val, bool* is_dead);
}
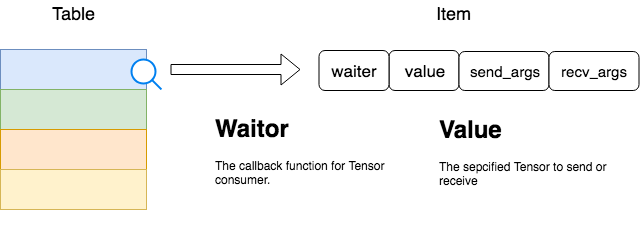
在TensorFlow中,几乎每个Rendezvous实现类都有自己的消息队列缓存,而几乎每种消息队列缓存都是依靠Table实现的。Rendezvous的发送(Send)和接收(Recv)都将通过Table完成。Table 的 Item 有两个重要字段
- Value:这就是参与通信Tensor本体
- Waitor:这是在确认Tensor被接收端完成接收后的处理函数,也就是consumer处理该Tensor的函数过程
- LocalRendezvous,Send端和Recv端使用的是同一个Rendezvous对象,所以他们共享同一个Table。无论是Send过程还是Recv过程,它们都将借助Table完成Tensor的转发。Send过程作为Tensor的生产者,它负责将待发送的Tensor送入Table中,并将ParsedKey作为该Item的键。而Recv过程作为消费者,它也会根据自己所需拼出相同的ParsedKey,然后从Table中查看是否已经存在该项。
- 若生产者先到达,由RecvAsync函数取出自己所需要的Item,然后执行waiter函数
- 若消费者先到达,由RecvAsync将所需的Item插入到Table中,并连同waiter函数一起发送到该表里。Send端到达后,Send函数将从表中取出该Item,并执行waiter函数,
- 跨进程通信过程/RemoteRendezvous TensorFlow中的通信机制——Rendezvous(二)gRPC传输
- Send 和本地传输场景下的Send过程相同,本地Tensor处于Ready状态后就被放挂了本地Worker的Table中,至此Send过程就全部完成了。所以Send过程完全没有涉及到任何跨网络传输的内容,并且Send过程是非阻塞的。
- Recv方是Tensor的接收方,它的处理过程是:将所需要的Tensor对应的ParsedKey拼出后,主动向Send方主动发出Request,Send方在接收到Request后立即在本地Table中查找方所需要的Tensor,找到后,拷贝到CPU上,将Tensor封装成Response发送回Recv方(grpc)。在这个过程中,Recv方可以认为是Client,Send方可以认为是Server,通过发送Request和Response来完成Tensor的传输。
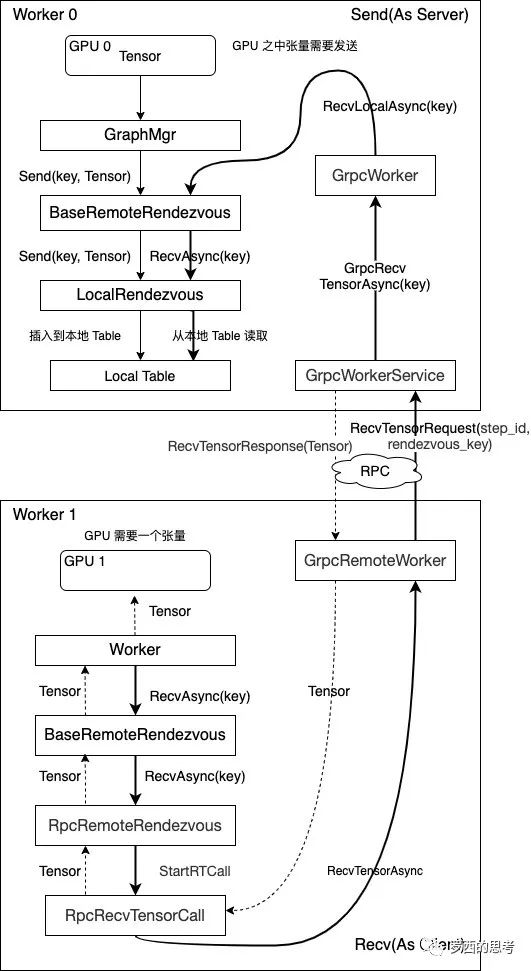
RemoteRendezvous需要支持不同的通信协议,因此派生了各种各样的实现类(主要扩展Recv);从设计哲学上说,gRPC本身设计并不适合深度学习训练场景,如果你使用NCCL或者MPI,那么你会得到不一样的性能。
- gRPC发送Tensor前,接收Tensor后必须要做序列化,在Tensor很大的时候这是一个非常讨厌的overhead,发送接收延迟过大;
- 序列化根本没有对数据做任何压缩,这是因为Tensor都是稠密的,所以序列化没有意义;
- 不能支持RDMA和GPU Direct。虽然这依赖于硬件,但是gRPC在软件层面也并没有做这些适配。
Worker的执行
在某个设备上,PartitionGraph 的起始节点为 Arg 节点,结束节点为 RetVal 节点。整 个过程可以看成函数调用过程,Arg 用于传递函数参数,RetVal 用于返回函数值。 更确切地说,Arg 完成 PartitionGraph 的输入,RetVal 完成 PartitionGraph 的输出。 对于 Arg 节点,其调用时序为:set_arg -> get_arg。其中,前者由 DirectSession 在启动 Executor 列表之前,通过调用 FunctionCallFrame.SetArgs(feeds),传递输入参数列表的 值;后者由 Arg 的 Kernel 实现调用。
每个 Executor 将执行 PartitionGraph 的拓扑排序算法,将入度为 0 的 OP 追加到 ready_queue 之中,并将其关联的 OP 的入度减 1。调度器调度 ready_queue 之中 OP ,并 将其放入 ThreadPool 中执行对应的 Kernel 实现。 在所有 Partition 开始并发执行之前,需要外部将其输入传递给相应的 Arg 节点;当 所有 Partition 完成计算后,外部再从 RetVal 节点中取走数据。其中,Arg/RetVal 节点之 间的数据时通过 FunctionCallFrame 完成交互的。
// tensorflow/tensorflow/core/common_runtime/direct_session.cc
Status DirectSession::Run(const RunOptions& run_options,...){
...
for (const auto& item : executors_and_keys->items) {
item.executor->RunAsync(args, barrier->Get());
}
}
// tensorflow/tensorflow/core/common_runtime/executor.cc
void ExecutorState::RunAsync(Executor::DoneCallback done) {
const Graph* graph = impl_->graph_;
TaggedNodeSeq ready;
// Initialize the ready queue.
for (const Node* n : impl_->root_nodes_) {
DCHECK_EQ(n->in_edges().size(), 0);
ready.push_back(TaggedNode{n, root_frame_, 0, false});
}
if (ready.empty()) {
done(Status::OK());
} else {
num_outstanding_ops_ = ready.size();
root_frame_->iterations[0]->outstanding_ops = ready.size();
done_cb_ = std::move(done);
// Schedule to run all the ready ops in thread pool.
ScheduleReady(ready, nullptr);
}
}
void ExecutorState::Process(TaggedNode tagged_node, int64 scheduled_usec) {
// Parameters passed to OpKernel::Compute.
TensorValueVec inputs;
OpKernelContext::Params params;
params.step_id = step_id_;
Device* device = impl_->params_.device;
params.device = device;
params.inputs = &inputs;
// Prepares inputs.
// Set up compute params.
OpKernel* op_kernel = item.kernel;
params.op_kernel = op_kernel;
params.frame_iter = FrameAndIter(input_frame->frame_id, input_iter);
params.is_input_dead = is_input_dead;
params.output_attr_array = item.output_attrs();
if (item.kernel_is_async) {
// Asynchronous computes.
AsyncOpKernel* async = item.kernel->AsAsync();
...
device->ComputeAsync(async, &state->ctx, done);
} else {
// Synchronous computes.
OpKernelContext ctx(¶ms, item.num_outputs);
if (stats) nodestats::SetOpStart(stats);
device->Compute(CHECK_NOTNULL(op_kernel), &ctx);
if (stats) nodestats::SetOpEnd(stats);
s = ProcessOutputs(item, &ctx, &outputs, stats);
}
// This thread of computation is done if completed = true.
if (completed) Finish();
}
操作节点执行 过程本质是 节点对应的核函数的执行过程。会话运行时,ExecutorImpl::Initialize 会对数据流图上每个操作节点 调用create_kernel 函数,这时创建的 核函数对象 是对应 操作在特定设备上的特化版本。
留下评论