LRU实现
前言
近日面试有一个算法题,设计一个数据结构实现LRU cache。当时发挥的并不好,现在来仔细讲讲这个问题。写这篇文章虽然是马后炮,但整理和推理的过程还是很有乐趣的。
问题
Design and implement a data structure for Least Recently Used (LRU) cache. It should support the following operations: get and set.
-
get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1
-
set(key, value) - Set or insert the value if the key is not already present. When the cache reached its capacity, it should invalidate the least recently used item before inserting a new item.
解决思路
首先要分析都有哪些操作,针对我们提供的数据结构,分析每个操作花费的时间。先提出一个最笨的方法,然后不断优化。说实话,算法方面我不是特别擅长,逐渐逼近最优值,是个不错的办法。首先做一个初步的判断:
get(key)时,有两个操作:
- 我们要记录数据被访问的优先次序,有两个方法:
- 为每个数据记录一个对应的值(最后一次访问时间,或者某个整数值)
-
通过调整数据的位置来维护数据被访问的次序。
很明显,第一个方法并不可取,因为如果cache较大时,我们确定谁最长时间没有被访问,需要比较整个数据结构,耗费较大。如果采用第二个数据结构,则要求该数据结构能够非常方便的移动元素,很自然的,可以想到链表。
- 在使用链表的前提下,我们要尽快判断key是否在数据结构中,很自然地,我们可以使用哈希表,负责维护key和存放key节点位置的映射,复杂度为O(1)。
单链表+哈希表
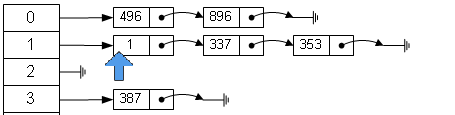
好,我们先用一个简单的单链表,同时限制每个链表的长度,链表当前长度记录在头结点中,分析每个操作的耗费:
get(key)时流程如下:
- 判断key是否在哈希表中,使用hashtable,复杂度为O(1)
- 获取相应位置链表的头指针head,并设定其指向key值对应节点(确保最新访问的放在链表头部)
- 如果key不在链表中,则将key插入到链表头部,此处调用set(key)
- 如果key在链表中,则将key节点移动到链表头部。此处问题出现:我们虽然可以知道key节点的next,但无法直接得到key节点前一个节点的next指针。
为获取key节点前一个节点的next指针有两个办法:
- 根据head遍历链表时,使用两个指针p、q,分别指向当前节点和下一个节点。
- 使用双链表
但针对单链表,set(key)时
- 根据哈希函数早到某个链表head指针,如果该链表长度不超过设定值,则直接插入到头部。
- 如果链表长度超过设定值,则删除最后一个元素,再插入key到链表头结点。
其中,删除尾部操作需要遍历链表直到最后一个节点,较为费时(当然,可以为每个链表维护一个指针用来存储最后一个节点的地址)。而双链表没有这样的问题。
双链表+哈希表
分析每个操作的耗费:
get(key)时
- 判断key是否在哈希表中,使用hashtable,复杂度为O(1)
- 获取相应位置链表的头指针head,并设定其指向key值对应节点(确保最新访问的放在链表头部)
- 如果key不在链表中,则将key插入到链表头部,此处调用set(key)
- 如果key在链表中,则将key节点移动到链表头部,复杂度为O(1)
set(key)时
- 如果该链表长度不超过设定值,则直接插入到头部。
- 如果链表长度超过设定值,则删除最后一个元素,再插入key到链表第一个节点。
其它方法
在搜集该类资料的过程中,还有提到双队列等其它方法的。说实话,这就是算法工程师研究的问题了,按以上的推理过程,实在是不好直接串联起来,应该是对这个算法有长期思索的人提出来的。
2018.11.12 极客时间《数据结构与算法之美》提到一个方法
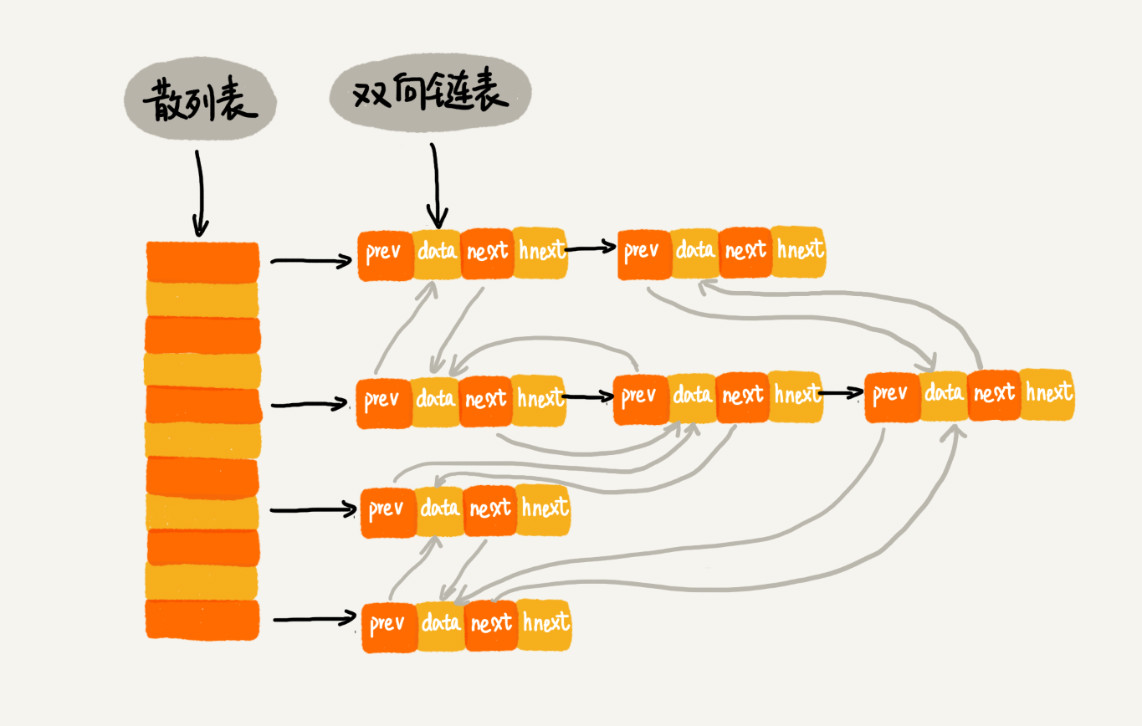
与我们的方法不同处是:它基于散列表改造
- 将散列表的 拉链 用 hnext 串起来
- 将所有的拉链 用 prev/next 双向链表串起来
java 中的 LinkedHashMap 便采用如图所示的结构,支持通过插入/访问顺序来遍历LinkedHashMap。
小结
如果说数组和单链表的优缺点,我们都会背:数组方便随机访问,链表方便插入和删除(现在看来,也包括移动了)。
但如何将它们应用到实际,解决一些问题,“经世致用”的能力还是有所欠缺的。
留下评论