资源调度泛谈
简介

Kubernetes架构为什么是这样的?在 Google 的一篇关于内部 Omega 调度系统的论文中,将调度系统分成三类:单体、二层调度和共享状态三种,按照它的分类方法,通常Google的 Borg被分到单体这一类,Mesos被当做二层调度,而Google自己的Omega被当做第三类“共享状态”。我认为 Kubernetes 的调度模型也完全是二层调度的,和 Mesos 一样,任务调度和资源的调度是完全分离的,Controller Manager承担任务调度的职责,而Scheduler则承担资源调度的职责。
| 资源调度 | 任务调度 | 任务调度对资源调度模块的请求方式 | |
|---|---|---|---|
| Mesos | Mesos Master Framework |
Framework | push |
| YARN | Resource Manager | Application Master Application Manager |
pull |
| K8S | Scheduler | Controller Manager | pull |
Kubernetes和Mesos调度的最大区别在于资源调度请求的方式
- 主动 Push 方式。是 Mesos 采用的方式,就是 Mesos 的资源调度组件(Mesos Master)主动推送资源 Offer 给 Framework,Framework 不能主动请求资源,只能根据 Offer 的信息来决定接受或者拒绝。
- 被动 Pull 方式。是 Kubernetes/YARN 的方式,资源调度组件 Scheduler 被动的响应 Controller Manager的资源请求。
为什么不支持横向扩展?
几乎所有的集群调度系统都无法横向扩展(Scale Out),集群调度系统的架构看起来都是这个样子的
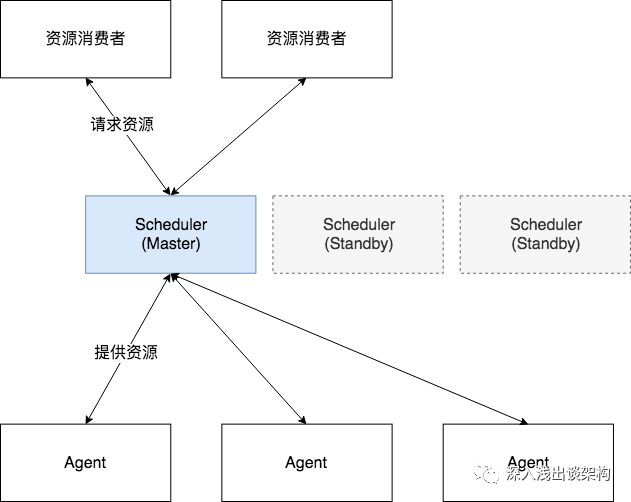
中间的 Scheduler(资源调度器)是最核心的组件,虽然通常是由多个(通常是3个)实例组成,但是都是单活的,也就是说只有一个节点工作,其他节点都处于 Standby 的状态。
每一台服务器节点都是一个资源,每当资源消费者请求资源的时候,调度系统的职责就是要在全局内找到最优的资源匹配:拿到全局某个时刻的全局资源数据,找到最优节点——这是一个独占操作。
一篇文章搞定大规模容器平台生产落地十大实践对于大的资源池的调度是一个很大的问题,因为同样一个资源只能被一个任务使用,如果串行调度,可能会调度比较慢。如果并行调度,则存在两个并行的调度器同时认为某个资源空闲,于是同时将两个任务调度到同一台机器,结果出现竞争的情况。Kubernetes有这样一个参数percentageOfNodesToScore,也即每次选择节点的时候,只从一部分节点中选择,这样可以改进调度效率。
调度分类
资源全局最优 vs 业务稳定性最优
在线调度最常见的调度能力
- 应用基本诉求:如规格、OS等
- 容灾与打散
- 高级策略:应用对物理资源、网络、容器的一些定制要求。
- 应用编排:比如应用对宿主机的独占要求,以确保绝对的防干扰;多个应用部署在同一台宿主机上的互斥要求
- cpu 精细编排:最大化使用宿主机物理核资源;应用之间最小cpu干扰隐患
- 重调度:应用重调度;cpu重调度
中心调度器做到了一次性最优调度;但与最终想要的集群维度全局调度最优,是两个完全不一样的概念。重调度也包括全局中心重调度和单机重调度。为什么一定需要中心重调度作为一次性调度的补偿呢?我们举几个例子:
- 集群内存在众多长生命周期的 POD 实例;随着时间的积累,集群维度必将产生众多资源碎片、CPU 利用率不均等问题。
- 大核 POD 的分配需要动态的腾挪式调度能力(实时驱逐某些小核 POD 并空闲出资源)、或基于提前规划的全局重调度,在众多节点上预空闲一些大核。
- 资源供给总是紧张的。对某个 POD 做一次性调度时,可能存在一定“将就”,这意味着某种瑕疵和不完美;但集群资源又是动态变化的,我们可以在其后的某个时刻,对该 POD 发起动态迁移,即重调度,这将带来业务更佳的运行时体验。
业界系统的调度架构主要分为四类:单体调度、两层调度、共享调度和混合调度。这些调度架构的本质区别其实只有两点:调度时调度器是否拥有全局的资源视图;不同的应用是否拥有多个资源调度器。
- 单体调度顾名思义,即只有一个调度器,调度器拥有全局资源视图的架构,Google Borg 和 K8s 都采用这个架构。单体架构的好处是,所有的任务都由唯一的调度器处理,调度器可以充分的考虑全局的资源使用情况,能方便的做出最优调度。但由于调度架构的限制,集群性能受限于单体的性能,无法支撑过大的集群。
- 两层调度拥有多个调度器,Apache Mesos 和 Hadoop YARN 都采用这个架构。两层调度中,每个应用的调度器首先向中心节点获取资源,再将其分配给应用中的各个任务。两层调度解决了单体调度的性能问题,但是调度器仅拥有局部资源视图,无法做出最优调度。
- 共享调度拥有多个调度器,每个调度器拥有全局资源视图,Omega 采用了这个架构。共享调度方案中,每个调度器都可以并发地从整个资源池中申请资源,解决了性能问题和最优调度问题,且可以支持较大集群。调度器间资源申请冲突可通过悲观锁或乐观锁来解决。
资源调度的复杂性
没有银弹,只有取舍 - Serverless Kubernetes 的思考与征程(一)
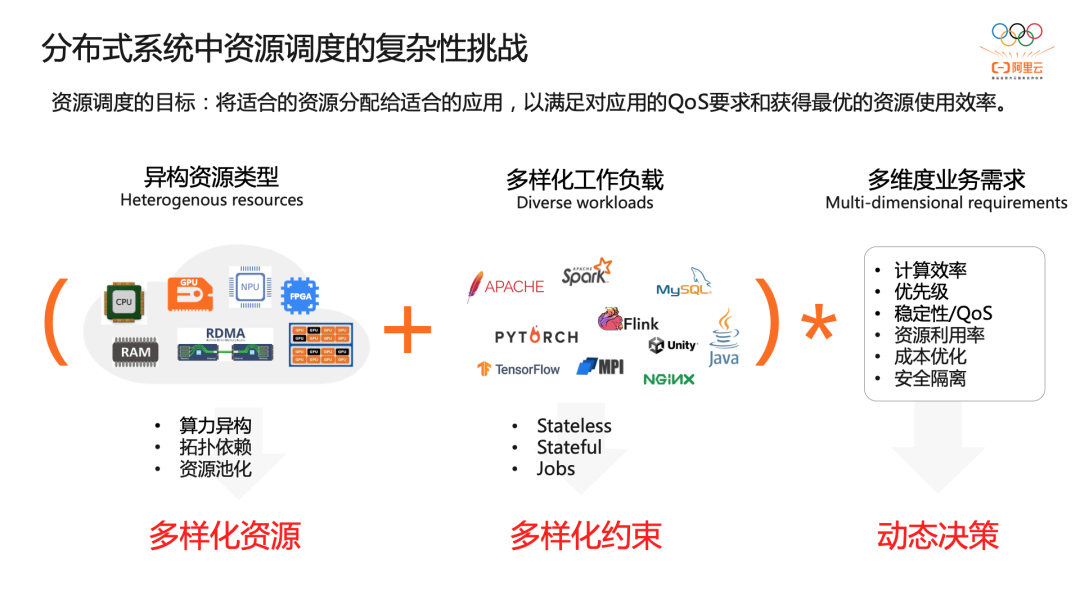
有一个非常现实的问题,如何衡量调度效果的好坏或者收益。通常情况下大家直接使用使用率去衡量,但是使用率并不适合单独使用,还要结合业务 SLO 的指标。举个例子,即使在什么都不做的情况下,如果业务萧条,那使用率自然会低,如果业务增长,使用率自然会高。Borg 提供了一个用来衡量调度效果的方法:集群压缩比,即以业务实际历史运行来模拟,逐步挑选集群中的机器下线,直到找不到任何一台可以下线的机器停止,可以用总的机器数 / 最终机器数计算一个压缩比,这个值越大,说明浪费越严重。在生产环境中,一般会刻意保留相当大的余地,以应对工作负载的增长、偶发的“黑天鹅”事件、负载峰值、机器故障、硬件升级以及大规模的部分故障(例如电源总线故障)。
服务调用延迟降低 10%-70%,字节跳动做了什么?与直接将微服务合并为更大的服务相比,亲和性部署方案仍保留了微服务架构中服务的独立性、敏捷性和易扩展性等优势。
- 通过策略性地重新部署服务的 Pod,尽量将频繁通信的服务 Pod 部署在同一台机器上(Collocation);
- 通过调整网络通信协议,采用本地通信方式(IPC)替代网络通信,显著降低网络开销,减少请求延迟,增强系统的稳定性。
留下评论