多模态LLM
前言
为什么我们需要能够处理多种数据类型的AI模型呢?原因很简单:我们的世界是多模态的。我们交流和感知世界不仅仅通过语言,还包括视觉、听觉等多种方式。多模态模型能够更全面地理解和模拟人类的交流和感知方式,使得AI能够更自然地与人类互动。 多模态模型就像是我们的大脑,能够同时处理和理解来自眼睛(视觉信息)、耳朵(听觉信息)和其他感官的数据。作用主要体现在以下几个方面:
- 信息整合:能够将不同类型的信息整合在一起,提高理解和分析的准确性。
- 增强表现力:通过结合多种数据源,模型可以表现出更强的感知和认知能力。
- 提高鲁棒性:多模态模型可以在某种类型数据缺失或不完整的情况下,依靠其他数据类型来弥补,从而提高整体性能。
语言模型的发展历程与视觉模型有许多相似之处。
- 它们都考虑了生物行为的特点,找到了适合自身的神经网络结构——循环神经网络(RNN)和卷积神经网络(CNN)。
- 它们在模型规模不断扩大的过程中,也都遇到了梯度爆炸和梯度消失的问题,并基于各自模型结构的特点找到了应对方法,分别是 LSTM 和 ResNet。
- 都逐步走出了自己的预训练之路。CV的分层结构(底层网络正在构建基础的“边缘检测能力”、中层的网络则利用这些边缘信息,来组成更高层次目标的局部特征(比如五官信息)、最上层则会出现和我们的目标分类任务最相关的一些实体),非常适合用来做模型的领域微调,只需要使用较少的数据,更新最上层也就是负责分类功能部分的模型参数,就能够获得良好的效果。Transformer的出现让NLP走出自己的预训练模型之路。
大模型中,常见的模态包括:
- 文本模态:包括自然语言文本、语音识别文本等。
- 图像模态:指图像数据,如照片、绘画等。
- 视频模态:指视频数据,包括视频片段、电影等。
- 音频模态:指声音数据,如音乐、语音等。
- 其他模态:如传感器数据、生物特征数据等其他形式的信息。
多模态大模型技术点总结 未读。
多模态 LLM对齐的演进之路,从 CLIP到Qwen3-Omni 未读。
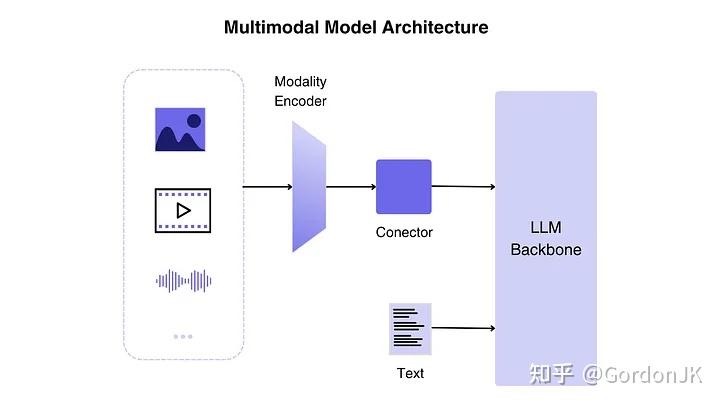
MLLM 的“三位一体”架构: PS:Vision Encoder -> MLP -> LLM
- 视觉编码器。输入的像素世界——无论是静态图片还是动态视频,转化为机器能够理解的、蕴含丰富语义的数学表达(即特征向量)。
- LLM,负责最后端的认知。它拥有强大的语言理解、逻辑推理和内容生成能力,是整个系统的“思考中枢”。
- 连接器,将“眼睛”看到的视觉信息,精准地翻译成“大脑”能够听懂的“语言”,实现两大模态的无缝对接。
Transformer与多模态
常见的文本 LLM 架构,这里简单分为两个部分:
- 分词部分: 负责将 Prompt 拆分为 Input Ids
- LLM 主干部分: 基于 Input Ids 生成的 Embedding 进行后续的推理,得到最终的 Hidden States 并取 argmax
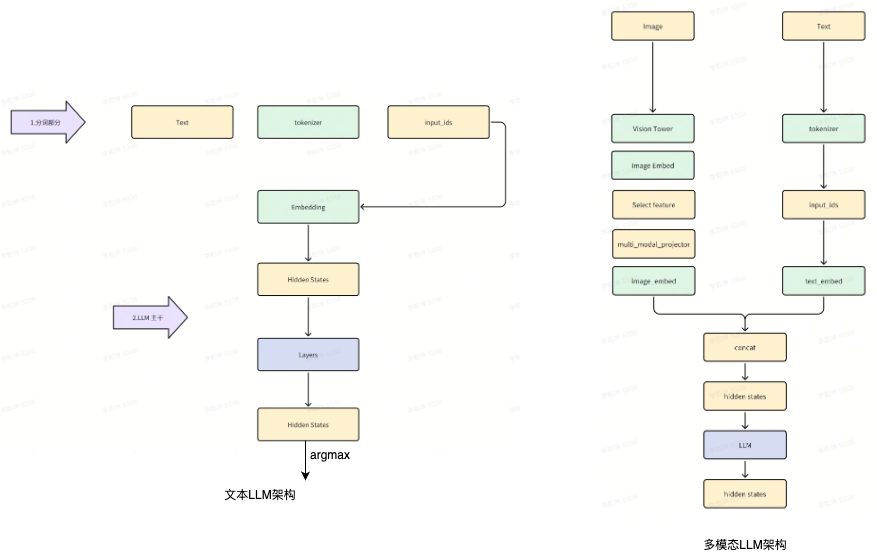
对于多模态场景,我们除了需要转换文本外,还需要将图像信息也转换为 Embedding,通过将文本 Embedding + 图像 Embedding concat 连接,再继续后面的部分。
- 其实不是“Transformer适合做多模态任务”,而是Transformer中的Attention适合做多模态任务,准确的说,应该是“Transformer中的Dot-product Attention适合做多模态任务”。PS: Transformer提出了深度学习领域既MLP、CNN、RNN后的第4大特征提取器。
- 之前的多模态任务是怎么做的? 在Transformer,特别是Vision Transformer出来打破CV和NLP的模型壁垒之前,CV的主要模型是CNN,NLP的主要模型是RNN,那个时代的多模态任务,主要就是通过CNN拿到图像的特征,RNN拿到文本的特征,然后做各种各样的Attention与concat过分类器。
- 为什么Transformer可以做图像也可以做文本,为什么它适合做一个跨模态的任务?说的直白一点,因为Transformer中的Self-Attetion机制很强大,使得Transformer是一个天然强力的一维长序列特征提取器,而所有模态的信息都可以合在一起变成一维长序列被Transformer处理。当你输入纯句子时,模型能学到这个it主要指animal,那么比如当你输入图片猫+这个句子的时候,模型可能就能学到你前面那张猫指的就是这个animal。
- attention本身就是很强大的,已经热了很多年了,而self-attention更是使得Transformer的大规模pretrain成为可能的重要原因self-attention的序列特征提取功能其实是非常强大的,如果你用CNN,那么一次提取的特征只有一个限定大小的矩阵,如果在句子里做TextCNN,那就是提取一小段文字的特征,最后汇聚到一起;如果做RNN,那么会产生长程依赖问题,当句子 太长最后RNN会把前面的东西都忘掉。self-attention的本质就是对每个token,计算这个token相对于这个句子其他所有token的特征再concat到一起,无视长度,输入有多长,特征就提多远。Transformer也可以认为是一个全连接图, 缓解了序列数据普遍存在的长距离依赖和梯度消失等缺陷 。
-
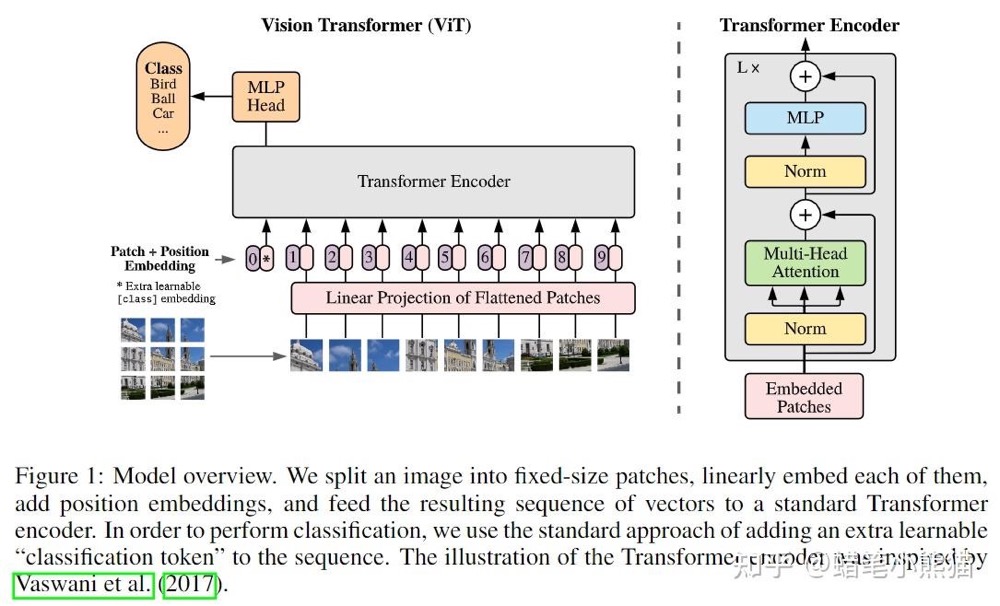
那么如果传入的不是句子,而是普通一维序列(也就是一个数组)呢?那就是对序列的每个点(数组的每个值),计算这个点与序列里其他点的所有特征,这也是Vision Transformer (ViT)成功的原因,既然是对序列建模,我就把一张图片做成序列不就完了?如果 Transformer 能够通过理解单词序列来读懂一篇文章,那它为什么不能通过理解图像块序列来“读懂”一张图片呢?一整张图片的像素矩阵直接平铺变成序列复杂度太大,那就切大块(一个块称为Patch)一点呗(反正CNN也是这种思想,卷积核获得的是局部特征,换个角度来说也是特定patch的特征),ViT就把一张图片做成了16个patch, 通过一个标准的可学习线性投影层(本质上是一个全连接神经网络层),被映射到模型预设的、更具语义意义的隐藏维度(Embedding Dimension)中(Patch Embedding),然后加上对应的position embedding(就是割成小方块变成token向量塞进去加上patch对应图片原始位置的标号)
步骤 (Step) 数据格式 (Data Format) 示例矩阵形状 (Example Matrix Shape) 详细说明 (Detailed Explanation) 1. 原始图像输入 像素矩阵 [1, 3, 224, 224] 一张 224x224 的 3 通道(RGB)彩色图像。 2. ViT 分块 Patch 序列 [1, 196, 768] 图像被切分为 196 个 16x16 的图块,并展平为向量。 3. ViT 输出 视觉特征序列 [1, 196, 768] 经过 ViT 编码器处理后,得到蕴含全局信息的特征序列。 4. Connector 投影 对齐后的视觉特征 [1, 196, 4096] 视觉特征被投影到与 LLM 词向量一致的 4096 维空间。 5. 文本嵌入 分词后的文本特征 [1, 5, 4096] 问题“What is in the image?”被分词并嵌入为 5 个 4096 维向量。 6. 多模态拼接输入 视觉+文本联合特征 [1, 201, 4096] 将 196 个视觉词元和 5 个文本词元沿序列维度拼接。 7. LLM 生成输出 生成的 Token ID 序列 [1, 7] LLM 基于联合特征生成了 7 个词元的答案。 - 如上图表格的第 3 步和第 4 步所示,连接器接收了 ViT 输出的 [1, 196, 768] 维特征,并将其转换为了 [1, 196, 4096] 维的“对齐后视觉特征”。这不仅仅是维度的改变,更是一次深刻的语义空间映射。在 MLLM 的世界里,连接器的设计主要分为两大流派:
- 线性投影层 (Linear Projection),以LLaVA为代表,它奉行“大道至简”的哲学,通常是一个非常简单的多层感知机 (MLP),甚至可以只是一个单层的全连接网络。它的核心任务就是进行一次线性的维度变换,将输入的视觉特征向量(如 768 维)映射到 LLM 的隐藏空间维度(如 4096 维)。这种方法并不试图对视觉信息进行复杂的预处理或提炼,而是相信在海量的图文数据对的训练下,这个简单的线性层足以学习到两个模态空间之间的映射关系。PS:传声筒。
- 以 BLIP-2 为代表Q-Former,能够主动思考、提炼关键信息。例如,一张 224x224 的图片会被转换成 196 个“视觉词元”。这 196 个词元是“未经加工的原始素材”。它们包含了图像中的一切——重要的物体(比如一只猫)、物体的细节(猫的胡须)、次要的背景(一片草地),以及大量冗余和无用的信息(比如 100 个几乎一模一样的草地块)。LLaVA把这 196 个词元全部“翻译”一下,然后原封不动地丢给LLM。Q-Former 基于Learnable Queries + Cross Attention机制提炼出32(超参数)个“浓缩”后的词元。
- 所以如果你用Transformer来当backbone的时候,你需要做的就只是把图片,文本,甚至表格信息等其他的所有模态信息全部flatten再concat或者相加成一维数组送进Transformer,然后期待强大的Self-Attention开始work就可以了。
面向统一的AI神经网络架构和预训练方法近几年,自然语言处理(NLP)和图形图像领域(CV)在神经网络架构和预训练上正在经历一个趋向统一的融合趋势。Transformer 的神经网络架构率先在自然语言处理(NLP)领域取得了很好的效果,并成为该领域的主流神经架构。从 2020 年下半年开始,计算机视觉领域也开始将 Transformer 应用到各种视觉问题中,并取代此前的卷积神经网络,成为新的主流神经架构。关于统一的好处,这里列举三点:
- 技术和知识共享:技术和知识共享能让不同领域都有更快的进步,对于 NLP 和 CV 领域来说,深度学习革命的早期主要是 CV 技术在影响 NLP 领域,而最近两年 NLP 领域进展迅速,很多很好的技术被 CV 领域所借鉴。
- 促进多模态应用:技术的统一也在催生全新的多模态研究和应用,例如实现零样本物体识别能力的 CLIP 模型、能给定任意文本生成图片的 DALL-E 模型等等。
- 实现降本增效:我们举芯片的例子,以前设计芯片时需要优化不同的算子,例如卷积、Transformer 等,而现在芯片设计只需要优化 Transformer 就可以解决 90% 以上问题。Nvidia 最新的 H100 GPU 的一个主要宣传点,就是可以将 Transformer 的训练性能提升 6 倍。
谷歌的 ViT 模型就是把图像切块切成不重叠的块,将每个块当作一个 token,于是就可以将 NLP 里的 Transformer 直接应用于图像分类。这种建模相比 CNN 有两个明显的好处:
- 相比 CNN 这种基于静态模板的网络,Transformer 的滤波模板是随位置动态的,可以更高效地建模关系。
- 可以建模长程关系(Long-term relationship),可以建模远距离的 token 之间的关联。
多模态的三条路:
- 用多模态数据端到端预训练的模型:Fuyu-8B,Gemini,LVM
- 使用“胶水层”粘接已经训练好的文本模型和各模态编码/解码器,使用多模态数据训练胶水层(projection layer) GPT-4V, MiniGPT-4/v2, LLaVA
- 使用文本粘接文本模型和多模态识别/生成模型,无需训练,例如语音:whisper语音识别+LLM文本模型+VITS语音合成
多模态大模型MLLM的架构发展及思考 mllm的综述。
数据
Qwen3-VL技术报告解析 如何弄数据集还是非常有含量的。
Tokenizer
我们一般怎么用多模态模型,是用一句话让模型生成张图片,或者给一张图片输出图片的总结。那么就需要将图片和文本等多种模态一起喂给大模型,让其一起理解。比如可以用vit 将图片转成 embedding,用 hubert 表征语音,然后将这些 embedding 用MLP 投射到同一空间。然后将统一后的 embedding 输入到一个文本大模型中,这个大模型输出的是 tokens。如果是文本就直接输出了。如果是图片等模态的就再经过一层 MLP 做输出投射,然后就可以借助如 stable diffusion 生成图片,利用 zeroscope 生成视频。很多模型都是现成的,核心工作在两次 MLP 的模态对齐,训练阶段主要用文本+各种模态的数据对,比如文本-图片,来训练。模型的架构也被分成了理解和生成两个大的模块。
Tokenizer 是一种将原始数据(如文字、图像或视频)转化为模型可以处理的基础单位(即 Token)的工具。Token是否能够代表原始数据的含义,直接影响模型的输入质量和后续处理效率。文字大模型和视频、图像大模型的 Tokenizer 的核心区别在于它们处理的输入数据具有不同的性质:文字是离散的符号序列,而视频和图像是连续的高维信号。因此,两者的 Tokenizer 的设计思路和实现上区别较大:
- 文字由于其离散性,主要以基于词表的方法构建Tokenizer,因此变体较少,其优化目标主要为如何更合理的分割最优子词,从而在能够满足语义表达的同时,尽量减少序列长度和词表大小。
- 图像或者视频没有类似文字的“离散语义单位”,需要通过人工设计或模型提取来划分为 token 表示。
所有的分歧都出现在模态对齐的过程中
- 如果以文本为基准,所有模态都向文本对齐,这种就叫做“文本霸权”,如果以视觉为基准,所有模态都向视觉对齐,这种就叫做“视觉霸权”。CLIP以及后续的大语言模型走的就是典型的文本霸权路线,用文本模态融合其他模态,而杨立昆的JEPA就是视觉霸权路线,用视觉模态来融合其他模态。杨立昆搞图像出身的,始终认为,真正的物理世界是无法用文本表示的,所以文本霸权根本不可取,而他所说的大模型只是海量拟合,只不过是这段话的一种阐述形式。他心里清楚,CNN也并非懂了图像的意义,都是抓特征值,谁也不会比谁高级。
- 如果做模态对齐?CLIP 搬来了两台巨大的“几何液压机”,从数学上就是两个投影矩阵。通过和两个投影矩阵相乘,他们(文本和图像)两个的维度变一致了。当我们统一了维度之后,CLIP做向量长度上的削减,这个步骤叫做L2归一化。此时CLIP 启动了它的终极引擎:对比损失函数。这个损失函数的工作相当于,用OpenAI 从互联网上爬取的 4 亿对“图片+文字说明”,强迫模型去学习:哪张图和哪句话是匹配的?至此,人类世界里所有的信息——无论是视网膜上的光子、耳膜上的震动、皮肤上的温度、还是前庭里的惯性——在经过神经网络的极端压缩和 L2 归一化之后,都可以在一个高维的几何空间里找到一个绝对唯一且互通的坐标点。
多模态理解
对于多模态数据理解任务来说,目前最主流的Tokenization方式,那应该就是Patch Tokenization了。主要代表模型:VIT。
- 基本原理:如果图片切成小块,然后变成一个序列,这个序列是不是就类似于一段文本了,因为 transformer 处理的是 embedding,其实它并不 care我们输入的是文本还是图片。知识需要前置做一些工作,将图片切分成 patch,例如 16x16 像素,然后压缩成 embedding,就可以输入到 transformer 中了。
- 将图像划分为固定大小的小块,比如1616,3232
- 每个图像块的像素展平为向量,通过一个线性变换,映射为固定的token表示。
- 好处展开来说就是:非常简单高效;直接处理的是原始像素,直接将图像转换为了序列。
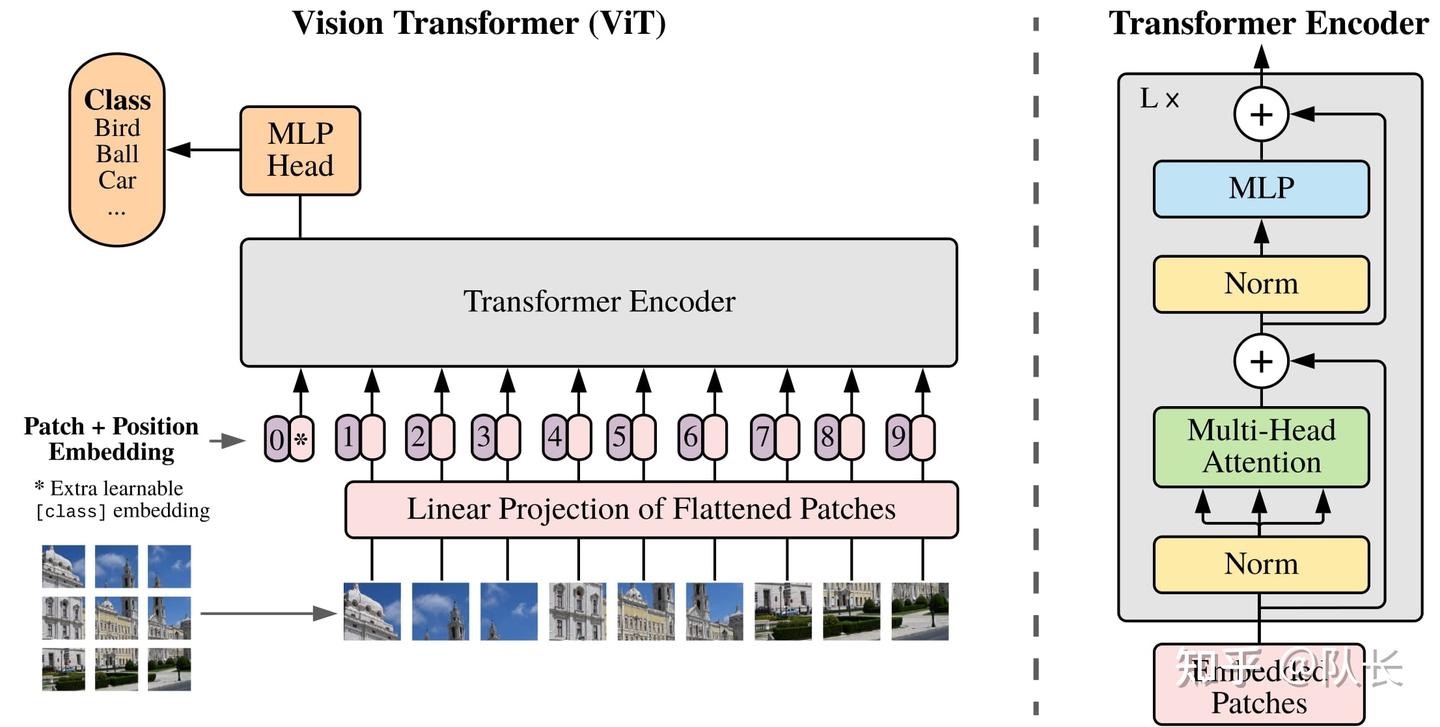
上面这个图是VIT模型的结构,我们只关注下面输入的处理部分:
- 将图像划分为 P×P 的小块。
- 使用线性变换操作对每个 patch 进行操作,将其映射到固定维度(hidden_size)。代码中使用的是卷积操作。
- 它起到的作用不仅仅是让图片输入满足了Transformer架构的输入要求,同时线性操作也尽可能地提取了图片每个patch的特征。
- 如果是处理视频的话,其实就是把线性变换由Conv2d换成Conv3d,比如qwen2_vl的实现:
- 添加一个 [CLS] token(用于分类任务),并为每个 token 添加位置编码以保留空间信息。
- 形成 token 序列,输入到 Transformer 模型进行后续计算。
多模态生成
PS: 生成的token 怎么变成图像的像素?
目前多模态生成任务有两种实现方式:
- Diffusion
- 自回归。需要考虑一些比较重要的问题,文字是离散化的数据,也就是说文字可以穷举,自回归生成的每一步,是在有限集中采样一个当前条件概率较高的元素出来。而图像、视频这种连续型的数据又该怎么用自回归方式生成呢?拿PixelCNN举例,它的核心思想是,将图像的生成视为逐像素建模的条件概率问题,即每个像素的值依赖于前面所有已生成的像素值,以 CIFAR-10 为例,一张图像是32×32×3 的彩色像素矩阵,每个像素包含 3 个通道(对应红、绿、蓝),每个通道的像素值是 0 到 255 的离散整数,一共 256 种可能值。需要为每个像素值(范围为 0-255)建模其概率分布。使用自回归方法,逐像素生成图像,每次生成一个像素,并基于之前的像素值预测下一个像素。我们可以把这个任务,看作是生成一个长度为32×32×3=3072的句子,而词表的大小是256,接着每一步做三次256分类问题输出每个像素具体的颜色。自回归生成图像模型的研究主要集中在两个方面:
- 如何设计这个生成顺序,因为图像和文字生成不同,文字是一维序列,但是图像是二维的,可以从上到下,从左到右,从中间往四周等等很多方向进行生成。
- 如何加速采样,犹如目前纯文字模型的加速,也是通过并行解码等方式进行加速采样。 不过不管怎么优化,自回归生成图像的方式仍然有个巨大的问题,刚刚我们用CIFAR-10这种小图形数据集为例,是生成序列长度3072的任务。但是如果生成更大的图片,例如长宽128的图像,这个生成序列的长度就爆炸性增长了。
应用场景
图片理解
- 如何将图片数据转为模型输入
- 高分辨率问题
import torch
from PIL import Image
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4v-9b", trust_remote_code=True)
query = '描述这张图片'
image = Image.open("your image").convert('RGB')
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True) # chat mode
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4v-9b",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
curl https://api.openai-hk.com/v1/chat/completions \
-H 'Authorization: Bearer hk-替换为你的key' \
-H "Content-Type: application/json" \
-d '{
"max_tokens": 1200,
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "system",
"content": "You are an expert Tailwind developer\nYou take screenshots of a reference web page from the user, ..."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "将图片生成网页代码"
},
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,${图片链接或者图片base64}"
}
}
]
}
]
}'
文生图
文生图模型发展简史与原理:DALL·E, Imagen, Stable Diffusion 未读。
文生图模型发展简史与原理:DALL·E, Imagen, Stable Diffusion 未读
curl https://api.openai-hk.com/v1/images/generations \
-H 'Authorization: Bearer hk-替换为你的key' \
-H "Content-Type: application/json" \
-d '{
"model": "dall-e-3",
"prompt": "a white siamese cat",
"n": 1,
"size": "1024x1024"
}'
{
"created": 1719924224,
"data": [
{
"revised_prompt": "A close-up image of a Siamese cat with creamy white fur. Its blue almond-shaped eyes are striking, showing curiosity and alertness. Its face has distinct dark brown points on its ears, muzzle, paws, and tail, characteristic of the Siamese breed. It's sitting relaxingly with its tail curled around its body, exuding elegance and tranquility.",
"url": "https://oaidalleapiprodscus.blob.core.windows.net/private/org-kOhHNKvXL29o3pG0HmQBc5Ba/user-KfXfmNUDI7WFshn1EGmdABuT/img-ipwM5u6uaI005p9vACY2MVlG.png?st=2024-07-02T11%3A43%3A44Z&se=2024-07-02T13%3A43%3A44Z&sp=r&sv=2023-11-03&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2024-07-02T01%3A55%3A22Z&ske=2024-07-03T01%3A55%3A22Z&sks=b&skv=2023-11-03&sig=P4QLWf6kAuBiWQJFiLCojKbNkO//qB09PpMnSE3eimM%3D"
}
]
}
文生视频
Sora 的基石:Diffusion Transformer 原理与源码解析 未读
多模态RAG
多模态RAG的想法是允许RAG系统以某种方式将多种形式的信息注入到多模态模型中。因此,多模态RAG系统可能检索基于用户提示的文本、图像、视频和其他不同模态的数据,而不仅仅是检索文本片段。 有三种流行的方法可以实现多模态RAG。
- 对图像和文本直接做Embedding,使用多模态嵌入模型来嵌入图像和文本,然后使用相似性搜索检索两者,最后将原始图像和文本块传递多模态模型以进行答案合成
- 将所有数据模态转换为单一模态,通常是文本。
- 图片 ==> vlm ==> 文本 ==> 文本embedding
- 图片 ==> vemb ==> embedding。 生成时 一般也是将 query + topk emb 图片 + 其它文本 传给vlm 生成答案。
训练VLM(视觉语言模型)的经验 未读。
代码
import requests
from PIL import Image
import torch
from transformers import AutoProcessor, LlavaForConditionalGeneration
model_id = "./model/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(
model_id,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
).to(0)
# 与 Text LLM 加载 tokenizer 处理文本不同,这里 Vision LLM 需要加载生成 processor 处理相关数据。
processor = AutoProcessor.from_pretrained(model_id)
conversation = [
{
"role": "user",
"content": [
{"type": "text", "text": "What are these?"},
{"type": "image"},
],
},
]
prompt = processor.apply_chat_template(conversation, add_generation_prompt=True)
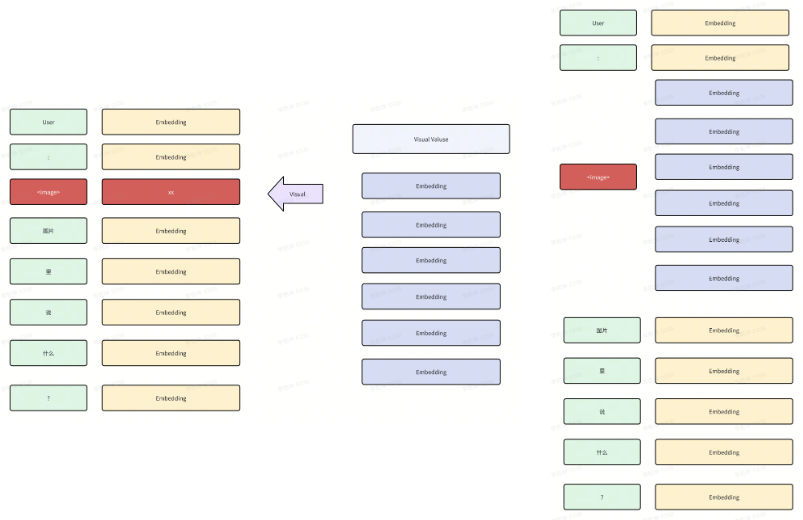
print(prompt)
# USER: <image>
# What are these? ASSISTANT:
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(images=raw_image, text=prompt, return_tensors='pt').to(0, torch.float16)
# <image> 的 token_id = 32000(根据配置文件),事实上这里的 <iamge> 是图像的占位符,因此 32000 也是一个特殊的 token,其目的是标识图像 Embedding 的位置并占位
for key in inputs:
print(key, inputs[key].shape)
留下评论